



了解完嵌入模型、向量数据库相关知识后,在此基础上可以实现一个RAG本地问答系统。
什么RAG?
RAG(Retrieval-Augmented Generation)检索增强生成,即大模型LLM在回答问题或生成文本前,会先从大量的文档中检索出相关信息,然后基于这些检索出的信息进行回答或生成文本,从而可以提高回答的质量,而不是任由LLM来发挥。
使用一个简单的公式来描述RAG:RAG = 检索技术 + LLMs提示
RAG 技术就是给大语言模型新知识,解决大模型的 “AI 幻想症”、“无法获取领域知识”和数据安全性问题!!
RAG架构
Spring AI 官方文档给出的架构图如下; 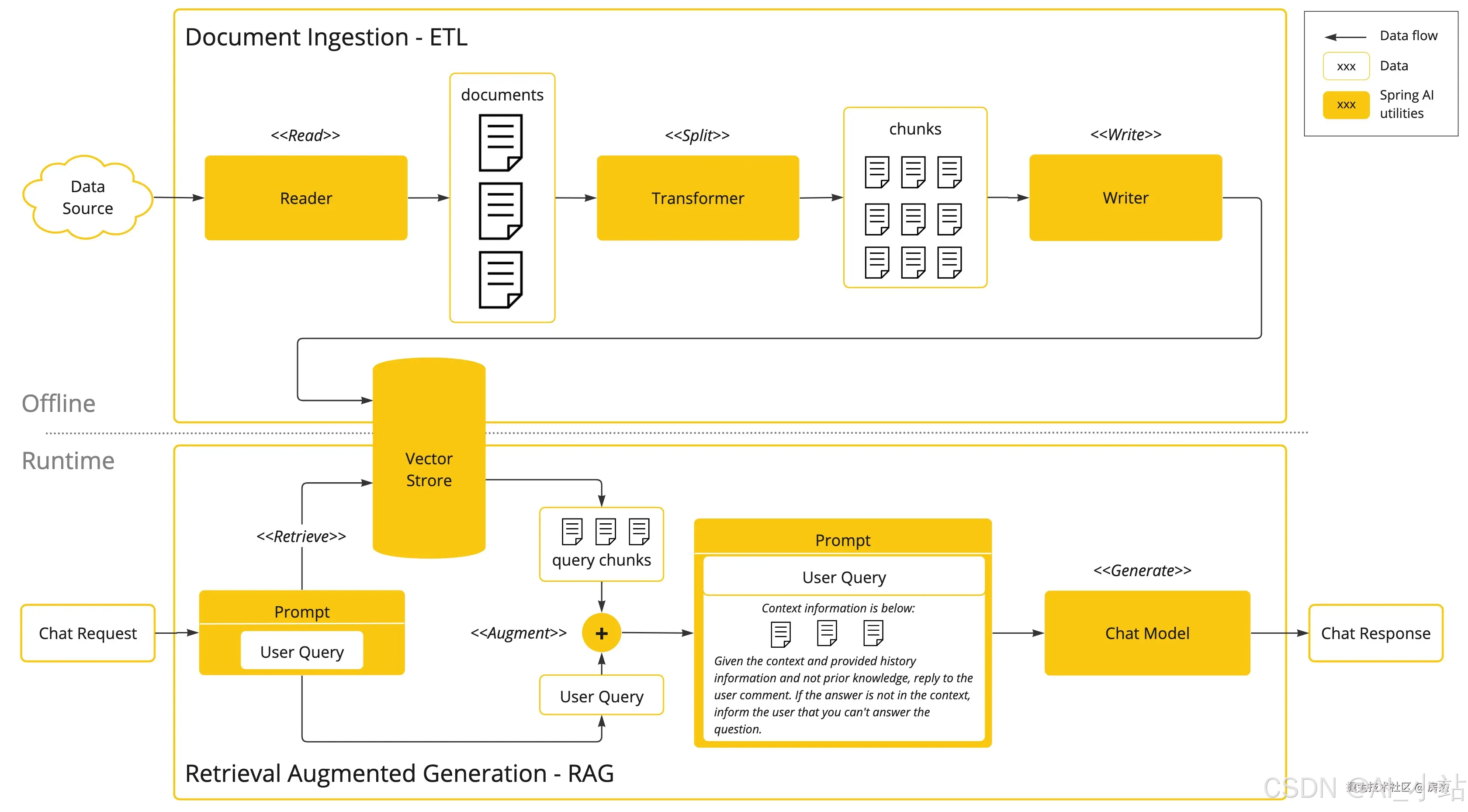
架构由离线部分和在线部分两部分组成;
- 离线部分:数据读取 -> 文档拆分 -> 向量化 -> 数据存储
- 在线部分:用户提问 -> 数据检索(召回) -> prompt拼装 -> LLM生成
该架构为最简单的RAG架构,有关论文介绍了RAG的演化由朴素RAG->高级RAG->模块化RAG,因此简单RAG是后续发展的理论基石,所以先将其掌握,在后续研究高级RAG加入了哪些优化,如何落地的。现在先仅实现一个简单的RAG问答系统。
离线部分 ETL Framework
下图为ETL处理流程及实现架构; 
对于 ETL 主要涉及到文件的读取、拆分、写入三个部分,将详细看下实现源码:
文件读取 DocumentReader
public interface DocumentReader extends Supplier<List<Document>> {
default List<Document> read() {
return get();
}
}
实现类:
- JsonReader:读取解析Json格式的文档
- TextReader:读取解析纯文本格式的文件
- TikaDocumentReader:从多种文档格式读取解析数据,包括像PDF, DOC/DOCX, PPT/PPTX 和 HTML。底层使用Apache tika技术实现。
- PagePdfDocumentReader:以页的方式读取解析PDF文件,底层依赖PdfBox实现。
- ParagraphPdfDocumentReader:以段落的方式读取解析PDF文件,根据TOC目录结构。注意:并不是所有的PDF文件都包含PDF catalog。
文件拆分 DocumentTransformer
public interface DocumentTransformer extends Function<List<Document>, List<Document>> {
default List<Document> transform(List<Document> transform) {
return (List)this.apply(transform);
}
}
其有4个实现类型,根据多种策略实现不同的类;
- TokenTextSplitter:将文档按照Token完整性进行拆分
- ContentFormatTransformer:
- KeywordMetadataEnricher:关键词提取
- SummaryMetadataEnricher:文档摘要
文档的拆分粒度对于相似度搜索至关重要,拆分粒度不合理将会导致相似度搜索问题,比如拆分粒度太大,可能会搜到不相关内容,或者搜索到的上下文过多,导致超出大模型窗口大小,相反粒度太小会丢失上下文信息,使得大模型回到质量受到影响。
分析一下TokenTextSplitter源码
TokenTextSplitter 该类是对读取文档进行拆分,其拆分对于相似度检索影响非常大。比如拆分块的大小;
public class TokenTextSplitter extends TextSplitter {
private final EncodingRegistry registry = Encodings.newLazyEncodingRegistry();
private final Encoding encoding = registry.getEncoding(EncodingType.CL100K_BASE);
// The target size of each text chunk in tokens
// 生成每个块的大小,比如一段文本总的tokens为1600,此时defaultChunkSize=800,
// 那么就将text的tokens拆分成为两个
private int defaultChunkSize = 800;
// The minimum size of each text chunk in characters
// 拆分后的文本块的最小字符数
private int minChunkSizeChars = 350;
// Discard chunks shorter than this
// 丢弃块的最短长度,这个指的是字符,
// 如果字符长度小于该值,则不再嵌入处理直接丢弃
private int minChunkLengthToEmbed = 5;
// The maximum number of chunks to generate from a text
// 一个文本最多生成的块的最大数量
private int maxNumChunks = 10000;
// 是否保留分割符,如果值为true,会执行chunkText.trim()
private boolean keepSeparator = true;
public TokenTextSplitter() {
}
}
当修改defaultChunkSize = 100时,上传文本被拆分为5个数据块。然后在进行测试,效果如下; 
如果defaultChunkSize值设置的不合理,则会导致拆分文本会丢失上下文信息
设置合理的chunk size可以比较精确的查询上下文信息,而且可以控制发送给大模型窗口的大小。

TokenTextSplitter底层使用技术
底层依赖 jtokkit, 一个专为 Java 开发者设计的高效文本分词库。它提供了一种简单易用的接口,使您能够轻松地对输入文本进行编码和解码。有兴趣的可以深入看下。
<dependency>
<groupId>com.knuddels</groupId>
<artifactId>jtokkit</artifactId>
<version>1.0.0</version>
</dependency>
文件写入 DocumentWriter
public interface DocumentWriter extends Consumer<List<Document>> {
default void write(List<Document> documents) {
accept(documents);
}
}
实现类有两个:
- FileDocumentWriter:持久化到文件中
- VectorStore:持久化到向量数据库中,Spring AI 集成10+种。
简单的RAG系统的实现
离线部分
离线部分主要使用 Spring AI ETL FrameWork 完成文件的处理。
package org.ivy.service;
import lombok.RequiredArgsConstructor;
import org.springframework.ai.document.Document;
import org.springframework.ai.document.DocumentTransformer;
import org.springframework.ai.reader.tika.TikaDocumentReader;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.core.io.Resource;
import org.springframework.stereotype.Service;
import org.springframework.web.multipart.MultipartFile;
import java.util.List;
@Service
@RequiredArgsConstructor
public class OfflineService {
private final VectorStore vectorStore;
private final DocumentTransformer transformer;
/**
* 上传文件,并拆分文档,向量化到数据库
*
* @param file 文件
* @return 上传结果
*/
public String upload(MultipartFile file) {
Resource resource = file.getResource();
TikaDocumentReader reader = new TikaDocumentReader(resource);
// 读取文档
List<Document> documents = reader.get();
// 拆分文档
List<Document> transform = transformer.transform(documents);
// 向量化到数据库
vectorStore.accept(transform);
return "ok";
}
}
在线部分
主要是去向量数据库相似度查询,重点看下 SearchRequest 请求对象,其中包含一些请求参数控制;
public class SearchRequest {
// 相似度查询阙值,默认为0.0,为提高相似度准确性,可以提高此值
public static final double SIMILARITY_THRESHOLD_ACCEPT_ALL = 0.0;
// 相似度前k个
public static final int DEFAULT_TOP_K = 4;
// 查询内容
public String query;
// 返回topK个文档
private int topK = DEFAULT_TOP_K;
// 相似度阙值,默认为0.0
private double similarityThreshold = SIMILARITY_THRESHOLD_ACCEPT_ALL;
// 过滤条件,根据元数据进行过滤,可以辅助精确检索
private Filter.Expression filterExpression;
}
在线部分代码实现;
package org.ivy.service;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.chat.prompt.SystemPromptTemplate;
import org.springframework.ai.document.Document;
import org.springframework.ai.ollama.OllamaChatModel;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import reactor.core.publisher.Flux;
import java.util.List;
import java.util.Map;
@Service
public class OnlineService {
@Value("classpath:rag.st")
private org.springframework.core.io.Resource ragTemplate;
@Resource
private OllamaChatModel chatModel;
@Resource
private VectorStore vectorStore;
public Flux<String> simple(String prompt) {
ChatClient client = ChatClient.builder(chatModel).build();
return client.prompt()
.user(prompt)
.stream()
.content();
}
public Flux<String> rag(String prompt) {
// 检索
SearchRequest searchRequest = SearchRequest.query(prompt);
List<Document> documents = vectorStore.similaritySearch(searchRequest);
// 提示词生成
List<String> context = documents.stream().map(Document::getContent).toList();
SystemPromptTemplate promptTemplate = new SystemPromptTemplate(ragTemplate);
Prompt p = promptTemplate.create(Map.of("context", context, "question", prompt));
ChatClient chatClient = ChatClient.builder(chatModel).build();
// 大模型生成内容
return chatClient.prompt(p).stream().content();
}
}
验证效果
验证一:访问无rag实现接口,localhost:8806/simple?prompt=ivy毕业于哪个大学?

由于在大模型中没有这方面的知识,因此大模型无法回答我们提出的问题。
验证二:访问rag实现接口,并且向量数据库没有信息,localhost:8806/rag?prompt=ivy毕业于哪个大学? 
大模型依然不能回答我们提的问题,因为即使我们提供了外部数据,但是外部数据没有数据,不能提供上下文信息。
验证三,先将准备的数据,导入到向量数据库,然后在访问rag接口
-
第一步:导入数据,localhost:8806/upload

-
第二步:访问rag接口,localhost:8806/rag?prompt=ivy毕业于哪个大学?

至此完成了一个基于RAG技术的本地问答系统。
这仅是一个入门版的RAG,要想应用于生产,还是的需要下一番功夫,对其各方面进行优化,比如文档的切分方式、粒度、查询召回率等等。后续会有专栏进行对RAG的技术细节、优化落地进行详细剖析,敬请期待!
示例代码
本文实现了简单的 RAG 应用,并讲解了Spring AI 框架如何支持实现 RAG 应用,并对ETL的每个步骤的源码、类的功能进行分析。
对于相似度查询,重点看下 SearchRequest 请求对象参数控制,这些参数对于查询的影响比较大,也是最后含量一部分内容。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 1639
1639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









