



1、简介
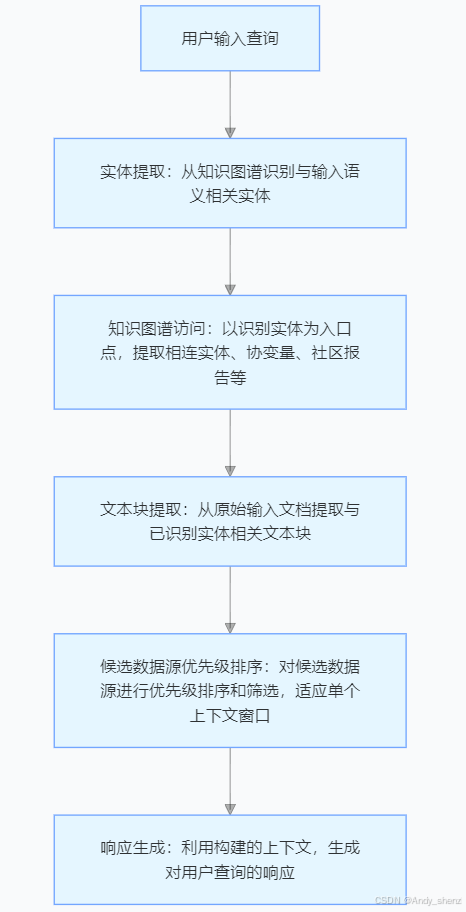
在GraphRAG的查询阶段,核心任务是基于构建好的知识图谱来检索相关信息并生成回答。具体来说,查询阶段会利用之前在 索引阶段 构建的所有实体、关系和社区报告等信息,结合用户的查询请求,自动选择最相关的上下文,并通过大语言模型(如GPT等)生成智能化的回答。
GraphRAG检索方式有两种,本地搜索和全局搜索
- 本地搜索:主要聚焦于回答与特定实体相关的问题,适用于需要理解输入文档中提到的特定实体细节的场景,比如查询 “洋甘菊的治疗特性是什么”,旨在从文档中提取与该特定实体紧密相关的信息。
- 全局搜索:主要用于处理需要对整个数据集进行分析和总结的查询,例如 “数据中的主要主题是什么”“对 x 最重要的影响是什么” 这类需要跨数据集聚合信息的问题,关注的是整个数据集的结构和主题。
查询阶段的执行流程
- 用户输入查询(User Query): 用户通过输入一个自然语言查询,表达他们需要的信息。例如:“告诉我大数据时代的背景是什么?”
- 创建查询上下文(Build Query Context):GraphRAG会根据查询的内容,从知识图谱中提取相关的信息并构建查询上下文。这个上下文包括了与查询相关的:
- 文本单元(Text Units):即与查询相关的文档片段或文本段。
- 实体(Entities):与查询相关的实体,如“维克托·迈尔-舍恩伯格”、“数据分析”等。
- 关系(Relationships):涉及到查询中的实体之间的关系,如“维克托·迈尔-舍恩伯格”与“《大数据时代》”之间的关系。
- 上下文构建的过程中,GraphRAG会根据预设的参数(如文本单元占比、实体数量等)来选择最相关的文本片段、实体、关系等,以便提供一个完整的上下文。
- 文本切分和嵌入(Text Splitting and Embedding):
- 对于文本,GraphRAG会按照预设的规则进行切分。例如,以每50个token为单位,将文本分割成多个文本单元。
- 接着,使用预训练的文本嵌入模型(如OpenAI的Embedding模型),将每个文本单元转化为一个向量表示,便于计算相似度。
- 对于实体和关系,也会计算其嵌入(Embedding),通常基于实体的描述、关系的文本等。
- 构建查询上下文(Local Context): 使用 LocalSearchMixedContext 类,GraphRAG将结合以下因素构建查询上下文:
- 查询相关的文本单元(即与查询最相关的文本片段);
- 查询相关的实体(从实体表中选取相关的实体);
- 查询相关的关系(从关系表中选取与查询相关的关系);
- 社区报告(有时也会包含相关的社区报告信息,帮助理解文本和实体的聚合关系)。
- 这些信息会被组合在一起,形成一个“上下文窗口”,为后续的查询提供支持。
- 检索并选择相关信息(Retrieve Relevant Information): 通过构建好的查询上下文,GraphRAG会检索并从中选择最相关的文本单元、实体和关系。这个过程的目的是通过“局部搜索”算法找到与用户查询最相关的信息,并确定哪些是能够提供解答的关键内容。
- 大语言模型生成答案(Answer Generation by LLM): 结合检索到的上下文信息,GraphRAG使用一个大型语言模型(如GPT)来生成最终的回答。模型会根据检索到的上下文生成自然语言的回应,并根据查询的需要决定回答的格式和内容。
- 生成的答案可以根据查询的复杂度有所不同,通常会包含多段文字、按优先级排序的答案等。
- 返回查询结果(Return Results): 最终,GraphRAG将生成的答案返回给用户。如果设置了“返回候选上下文”(return_candidate_context=True),则还会返回所有相关候选的实体、关系和文本单元,供用户参考。
2、本地搜索
在这里插入图片描述
- 读取相应的文件,创建本地查询的入参
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
text_unit_df = pd.read_parquet("./sushi2/output/create_final_text_units.parquet")
text_units = read_indexer_text_units(text_unit_df)
nodes_df = pd.read_parquet("./sushi2/output/create_final_nodes.parquet")
entitys_df = pd.read_parquet("./sushi2/output/create_final_entities.parquet")
entities = read_indexer_entities(nodes_df, entitys_df,None)
description_embedding_store = LanceDBVectorStore(
collection_name="default-entity-description",
)
description_embedding_store.connect(db_uri="./sushi2/output/lancedb/")
relationship_df = pd.read_parquet("./sushi2/output/create_final_relationships.parquet")
relationships = read_indexer_relationships(relationship_df)
report_df = pd.read_parquet("./sushi2/output/create_final_community_reports.parquet")
reports = read_indexer_reports(report_df, nodes_df, None)
- 创建大语言模型及词嵌入模型相关的参数
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
llm = ChatOpenAI(
api_key=os.getenv("openai_api_key", None),
model="gpt-4o",
api_base=os.getenv("base_url", None),
api_type=OpenaiApiType.OpenAI,
max_retries=20,
)
token_encoder = tiktoken.get_encoding("cl100k_base")
text_embedder = OpenAIEmbedding(
api_key=os.getenv("openai_api_key", None),
api_base=os.getenv("base_url", None),
api_type=OpenaiApiType.OpenAI,
model="text-embedding-3-large",
deployment_name="text-embedding-3-large",
max_retries=20,
)
- 创建上下文构建器
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
context_builder = LocalSearchMixedContext(
community_reports=reports,
text_units=text_units,
entities=entities,
relationships=relationships,
covariates=None,
entity_text_embeddings=description_embedding_store,
embedding_vectorstore_key=EntityVectorStoreKey.ID,
text_embedder=text_embedder,
token_encoder=token_encoder,
)
- 创建本地查询的超参数
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
local_context_params = {
"text_unit_prop": 0.5,
"community_prop": 0.1,
"conversation_history_max_turns": 5,
"conversation_history_user_turns_only": True,
"top_k_mapped_entities": 10,
"top_k_relationships": 10,
"include_entity_rank": True,
"include_relationship_weight": True,
"include_community_rank": True,
"return_candidate_context": True,
"embedding_vectorstore_key": EntityVectorStoreKey.ID,
"max_tokens": 12_000,
}
llm_params = {
"max_tokens": 2_000,
"temperature": 0.0,
}
- 查询
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
search_engine = LocalSearch(
llm=llm,
context_builder=context_builder,
token_encoder=token_encoder,
llm_params=llm_params,
context_builder_params=local_context_params,
response_type="multiple paragraphs",
)
result = await search_engine.asearch("请帮我介绍下苏轼")
from IPython.display import Markdown, display
display(Markdown(result.response))
苏轼(1037-1101),字子瞻,号东坡居士,是北宋时期著名的文学家、政治家、书法家和画家。他出身名门,是初唐大臣苏味道的后裔[Data: Entities (0, 15)]. 苏轼的父亲苏洵和母亲程氏都对他的成长产生了深远的影响,尤其是父亲在文学上的熏陶,使苏轼从小就展现出非凡的文学才华[Data: Reports (0); Entities (3); Relationships (0, 1, 6)].
## 文学成就
苏轼的文学才华在当时和后世都享有极高的声誉。他擅长诗、词、文章和书法,其作品涵盖社会现实、人生思考、自然景观等诸多方面。苏轼的代表作包括《赤壁赋》、《后赤壁赋》和《念奴娇·赤壁怀古》,这些作品通过描写自然景色,表达了他对人生的哲思和感悟[Data: Entities (0, 99); Reports (0, 3); Relationships (39, 98, 17, 99, 100, +more)].
此外,苏轼还以诗歌中的批判精神和社会洞察力著称。他通过诗歌表达了对社会现实的深刻洞察和批判,并在作品中常常蕴含着对人生和自然的深刻感悟[Data: Entities (0), Reports (5)].
## 政治生涯
虽然苏轼在文学上有极高的成就,但他的政治生涯却充满波折。他曾在多个地方和机构任职,包括河南府福昌县、大理评事、凤翔府签书判官和杭州知州。他在这些地方推行了许多有益于民生的工程,尤其是在杭州修建了著名的苏公堤[Data: Reports (0); Entities (22, 24, 25, 31, 62, 65); Relationships (20, 21, 22, 51, 53, 54, 61, +more)].
然而,苏轼的政治生涯并非一帆风顺。他曾因“乌台诗案”被贬至黄州,后来又被多次贬谪至惠州和海南岛等地。在这些贬谪地,苏轼依然积极生活和创作,广受当地百姓的爱戴[Data: Reports (0); Entities (44, 79, 81, 98); Relationships (39, 40, 48, 50, +more)].
## 家庭与人际关系
苏轼出生在一个书香门第的家庭,父亲苏洵和弟弟苏辙都是著名的文学家。他的父亲对苏轼的成长产生了深远影响,他的弟弟苏辙也在他们母亲去世后,一同守丧回乡[Data: Reports (0); Entities (3, 6, 15); Relationships (0, 1, 3)].
此外,苏轼与北宋多位重要人物有密切的联系。例如,欧阳修是苏轼科举考试的主考官,对其才情非常肯定,并在仕途上给予了极大的支持。苏轼在仕途和学术上的朋友如梅尧臣、司马光等,也对他的生平和事业提供了重要影响[Data: Reports (0); Entities (12, 13); Relationships (6, 7)].
## 对后世的影响
苏轼不仅为北宋的文学留下了宝贵遗产,还对后世的文学和文化发展产生了深远的影响。他创造的经典美食如东坡肉、东坡饼至今仍为人们所喜爱[Data: Reports (0); Relationships (4, 5)].
苏轼的一生充满了坎坷与传奇。他的文学成就和人格魅力永远地留在人们的心中,成为后世文人们景仰的对象[Data: Sources (5)].
### 结语
苏轼的个人经历和作品对中国文化产生了深远的影响。他不仅是一位伟大的文学家,也是一个为百姓服务的忠诚政治家。他的一生体现了他对文学、政治和生活的热爱与奉献。无论是他的诗篇,还是他的社会贡献,苏轼都为后人留下了一笔不可磨灭的文化财富。
3、global查询
代码流程与本地类似
- 读取本地结果创建参数
在前面已经创建的参数,在这里继续使用
ounter(lineounter(lineounter(line
community_df = pd.read_parquet("./sushi2/output/create_final_communities.parquet")
communities = read_indexer_communities(community_df, nodes_df, report_df)
- 上下文构建器
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
context_builder = GlobalCommunityContext(
community_reports=reports,
communities=communities,
entities=entities,
token_encoder=token_encoder,
)
- 超参数
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
context_builder_params = {
"use_community_summary": False,
"shuffle_data": True,
"include_community_rank": True,
"min_community_rank": 0,
"community_rank_name": "rank",
"include_community_weight": True,
"community_weight_name": "occurrence weight",
"normalize_community_weight": True,
"max_tokens": 12_000,
"context_name": "Reports",
}
map_llm_params = {
"max_tokens": 1000,
"temperature": 0.0,
"response_format": {"type": "json_object"},
}
reduce_llm_params = {
"max_tokens": 2000,
"temperature": 0.0,
}
- 查询
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
search_engine = GlobalSearch(
llm=llm,
context_builder=context_builder,
token_encoder=token_encoder,
max_data_tokens=12_000,
map_llm_params=map_llm_params,
reduce_llm_params=reduce_llm_params,
allow_general_knowledge=False,
json_mode=True,
context_builder_params=context_builder_params,
concurrent_coroutines=32,
response_type="multiple paragraphs",
)
result = await search_engine.asearch("请帮我介绍下苏轼")
display(Markdown(result.response))
### 苏轼简介
苏轼(1037—1101年),字子瞻,号东坡居士,是北宋时期著名的文学家、政治家和思想家。他以其在诗歌、散文、书法和绘画上的卓越成就,成为中国文化历史上耀眼的代表人物。他的文学作品包括《赤壁赋》《后赤壁赋》和《念奴娇·赤壁怀古》等名篇,这些不朽之作不仅展现了他的创作天赋,还深刻反映了他乐观豁达的生活态度和对人生的哲学思考 [Data: Reports (0, 3, 5, 6, 4, +more)]。
---
### 政治生涯与功绩
苏轼在政治生涯中历任多个地方和中央职位,包括杭州、大理、翰林院等地的重要职务。在杭州任职期间,他主持修建了著名的“苏堤”,既为百姓的生活提供便利,又成为后世闻名的景观,充分体现了他的务实与民本思想 [Data: Reports (0, 5)]。然而,苏轼的政治生涯并非一帆风顺。因乌台诗案等事件,他多次被贬谪至黄州、惠州和海南岛等偏远之地。但在这些逆境中,他依然保持积极生活态度,并创作了大量文学作品,融入了对自然与人生的深刻感悟,也赢得了当地百姓的爱戴 [Data: Reports (0, 3)]。
---
### 家庭背景与教育
苏轼出身于书香门第,其父苏洵是北宋著名的文学家,弟弟苏辙亦在文学上有较大成就,被后人并称为“三苏”。在父亲的精心教育下,苏轼和弟弟勤奋学习,最终通过科举考试脱颖而出,奠定了他们在北宋文坛的重要地位 [Data: Reports (0, 4)]。
---
### 文化遗产与后世影响
苏轼不仅以文学成就载入史册,他亲自创制的美食“东坡肉”等也成为中国传统饮食文化的一部分,反映出他对生活细节的热爱和创意。他的名字几乎与中国文化遗产画上了等号,对后世产生了深远影响,成为中国文人精神的象征 [Data: Reports (0, 6)]。
---
综上,苏轼以其多方面的才华和人格魅力,在北宋及后世树立了难以替代的文化地位。他兼具文学、政治与人生态度的高度统一,为后来的人们留下了极为丰富的精神财富。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:

- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

















 1399
1399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









