



【#】文章目录
【1】前置准备
【2】原始模型直接推理
【3】自定义数据集构建
【4】基于LoRA的sft指令微调
【5】动态合并LoRA的推理
【6】批量预测和训练效果评估
【7】LoRA模型合并导出
【8】一站式webui board的使用
【9】API Server的启动与调用
【10】进阶-大模型主流评测 benchmark
【11】进阶-导出GGUF,部署Ollama
【1】前置准备
训练顺利运行需要包含4个必备条件:
1.机器本身的硬件和驱动支持(包含显卡驱动,网络环境等)
2.本项目及相关依赖的python库的正确安装(包含CUDA, Pytorch等)
3.目标训练模型文件的正确下载
4.训练数据集的正确构造和配置
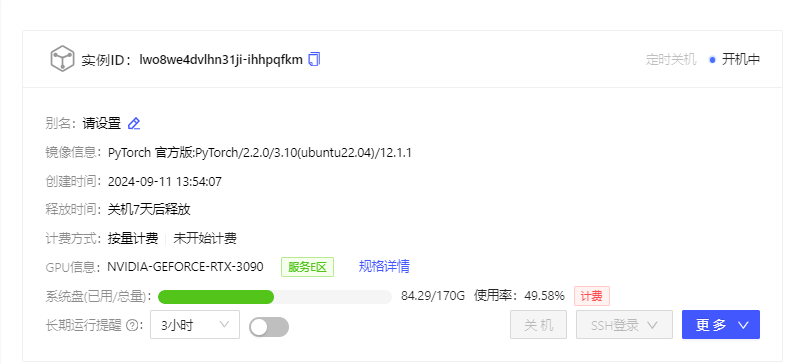
1.机器本身的硬件和驱动支持(包含显卡驱动,网络环境等)
这里采用GPU:1*RTX-3090 -24G
2.本项目及相关依赖的python库的正确安装(包含CUDA, Pytorch等)
环境:PyTorch2.2.0/Python3.10(ubuntu22.04)/cuda12.1.1【重要】
CUDA和Pytorch环境校验
在服务器新建终端:
git clone https://github.com/hiyouga/LLaMA-Factory.git
conda create -n llama_factory python=3.10
conda activate llama_factory
cd LLaMA-Factory
pip install -e '.[torch,metrics]'
查看torch和cuda版本
import torch
torch.cuda.current_device()
torch.cuda.get_device_name(0)
torch.__version__

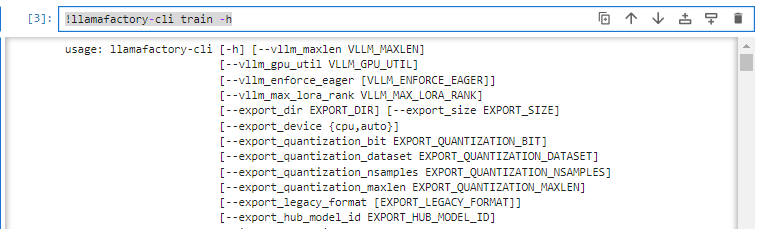
查看llamafactory是否安装成功
!llamafactory-cli train -h
3.目标训练模型文件的正确下载
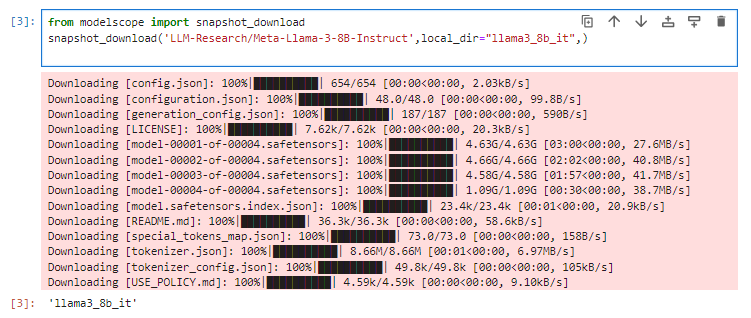
模型下载与可用性校验
!pip install modelscope
from modelscope import snapshot_download
snapshot_download('LLM-Research/Meta-Llama-3-8B-Instruct',local_dir="llama3_8b_it",)
下载llama3_8b_it到本地目录
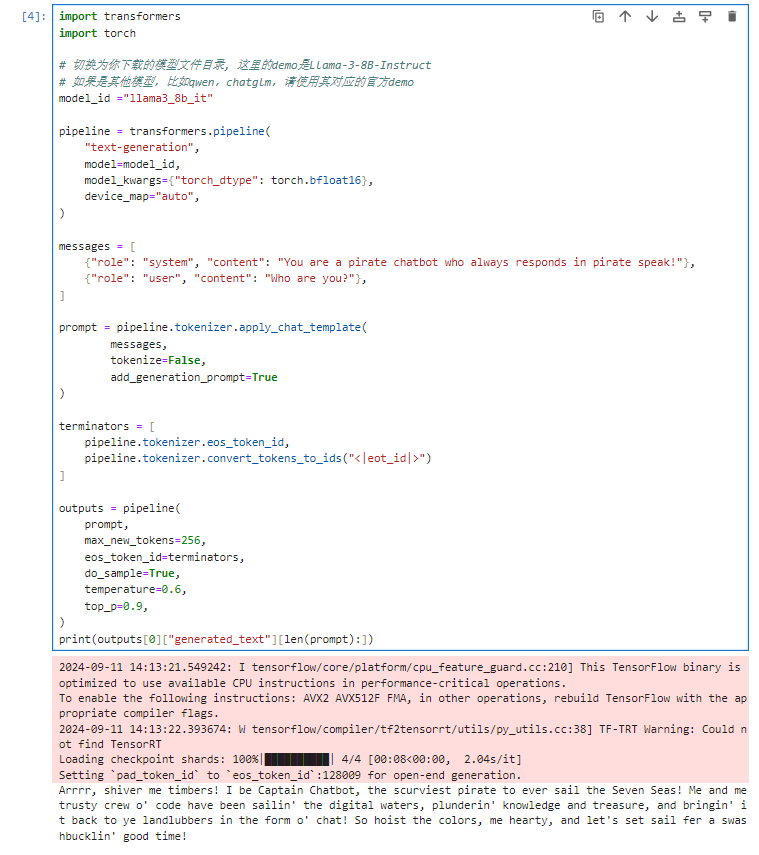
import transformers
import torch
# 切换为你下载的模型文件目录, 这里的demo是Llama-3-8B-Instruct
# 如果是其他模型,比如qwen,chatglm,请使用其对应的官方demo
model_id ="llama3_8b_it"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):]
#原模型推理
4.训练数据集的正确构造和配置
#见下面自定义数据集构建
【2】原始模型直接推理
启动推理
!CUDA_VISIBLE_DEVICES=0 llamafactory-cli webchat \
--model_name_or_path llama3_8b_it \
--template llama3
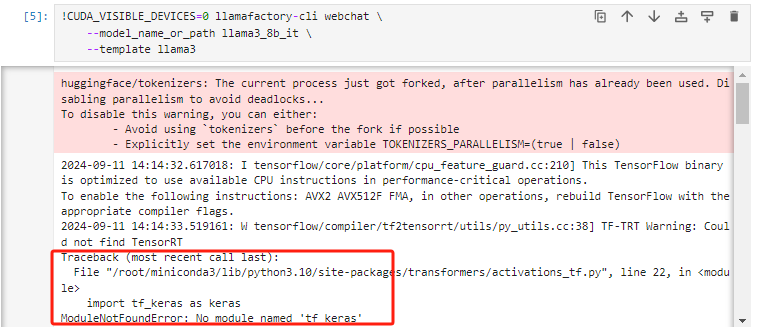
tf-keras模块缺失,直接安装
!pip install tf-keras
重新启动推理
!CUDA_VISIBLE_DEVICES=0 llamafactory-cli webchat \
--model_name_or_path llama3_8b_it \
--template llama3
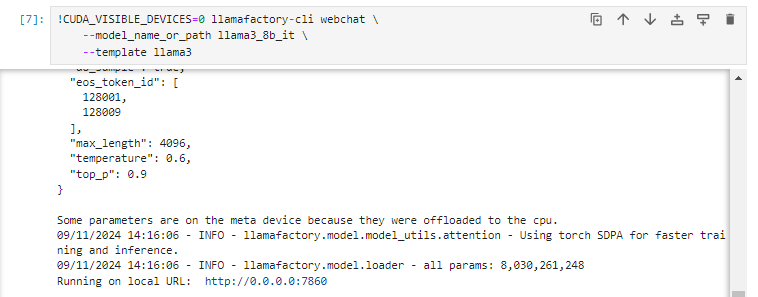
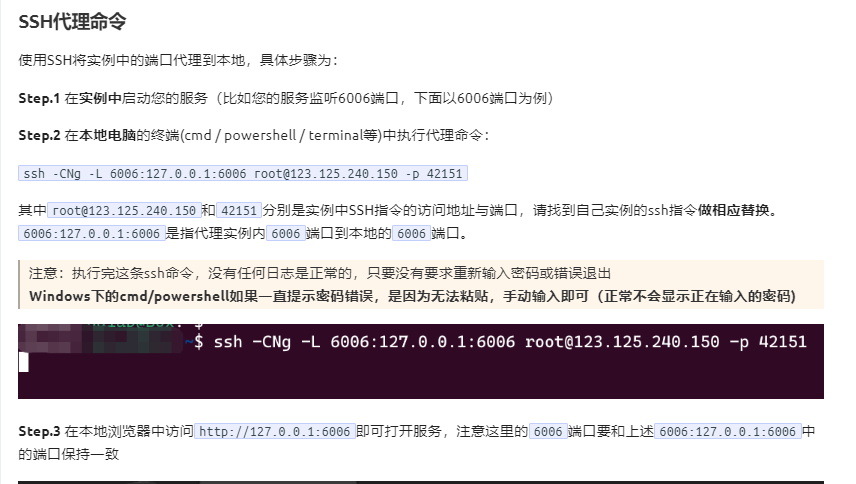
本地电脑打开cmd 连接到服务器
ssh -CNg -L 7860:0.0.0.0:7860 root@proxy-ai.onethingai.com -p 13299
#输入密码 e/eVpDXwD/ia
在本地电脑打开 127.0.0.1:7860
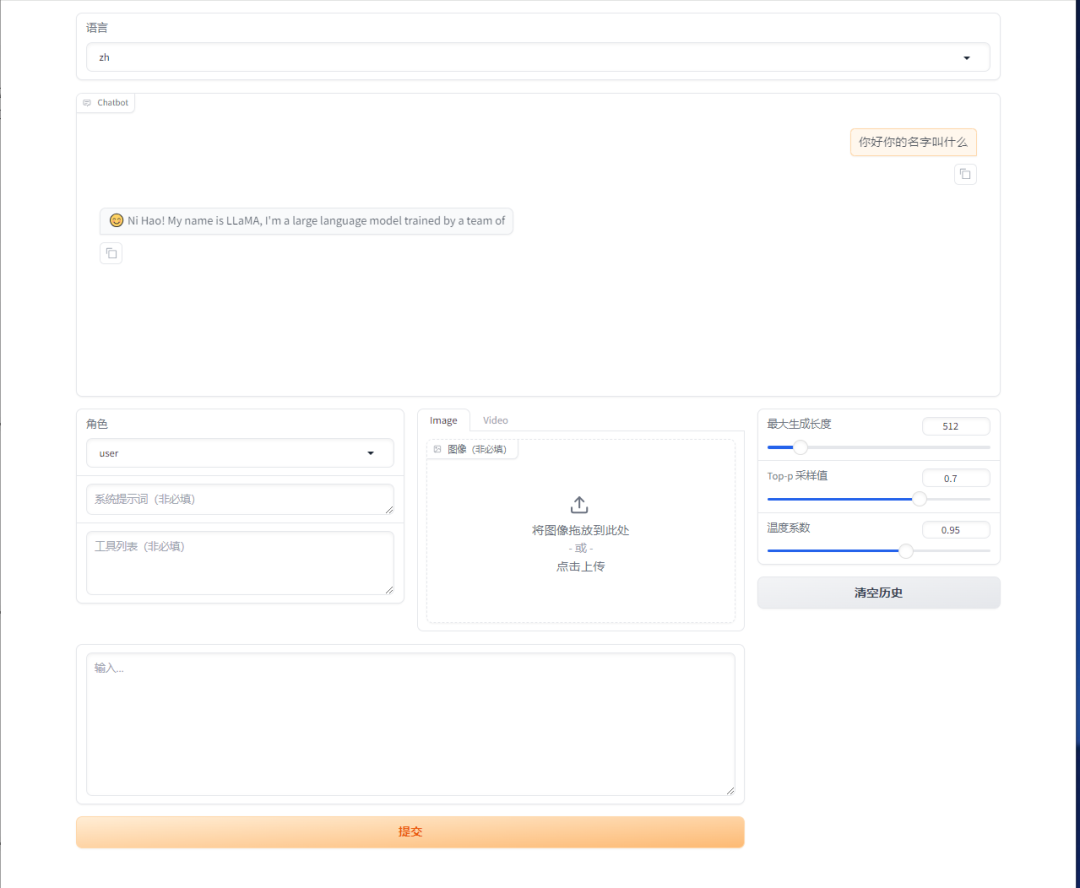
【补充】SSH隧道:https://www.autodl.com/docs/ssh_proxy/
【3】自定义数据集构建
系统目前支持 alpaca 和sharegpt两种数据格式,以alpaca为例,整个数据集是一个json对象的list,具体数据格式为
[
{
"instruction": "用户指令(必填)",
"input": "用户输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]
本文以系统自带的identity数据集和将自定义的一个商品文案生成数据集进行微调。
第一个是系统自带的identity.json数据集(已默认在data/dataset_info.json 注册为identity),对应文件已经在data目录下,我们通过操作系统的文本编辑器的替换功能,可以替换其中的NAME 和 AUTHOR ,换成我们需要的内容。如果是linux系统,可以使用sed 完成快速替换。比如助手的名称修改为PonyBot, 由 LLaMA Factory 开发
!sed -i 's/{{name}}/PonyBot/g' data/identity.json
!sed -i 's/{{author}}/LLaMA Factory/g' data/identity.json
替换前和替换后的数据集:
#替换前
{
"instruction": "Who are you?",
"input": "",
"output": "Hello! I am {{name}}, an AI assistant developedby {{author}}. How can I assist you today?"
}
#替换后
{
"instruction": "Who are you?",
"input": "",
"output": "I am PonyBot, an AI assistant developed by LLaMA Factory. How can I assist you today?"
}
第二个是一个商品文案生成数据集,链接为 https://cloud.tsinghua.edu.cn/f/b3f119a008264b1cabd1/?dl=1。原始格式如下,很明显,训练目标是输入content (也就是prompt), 输出 summary (对应response)
{
"content": "类型#裤*版型#宽松*风格#性感*图案#线条*裤型#阔腿裤",
"summary": "宽松的阔腿裤这两年真的吸粉不少,明星时尚达人的心头爱。毕竟好穿时尚,谁都能穿出腿长2米的效果宽松的裤腿,当然是遮肉小能手啊。上身随性自然不拘束,面料亲肤舒适贴身体验感棒棒哒。系带部分增加设计看点,还让单品的设计感更强。腿部线条若隐若现的,性感撩人。颜色敲温柔的,与裤子本身所呈现的风格有点反差萌。"
}
想将该自定义数据集放到我们的系统中使用,则需要进行如下两步操作:复制该数据集到 data目录下。修改 data/dataset_info.json 新加内容完成注册, 该注册同时完成了3件事。自定义数据集的名称为adgen_local,后续训练的时候就使用这个名称来找到该数据集,指定了数据集具体文件位置。定义了原数据集的输入输出和我们所需要的格式之间的映射关系。
【4】基于LoRA的sft指令微调
执行Lora指令微调
!CUDA_VISIBLE_DEVICES=0 llamafactory-cli train \
--stage sft \
--do_train \
--model_name_or_path llama3_8b_it \
--dataset alpaca_gpt4_zh,identity,adgen_local \
--dataset_dir ./data \
--template llama3 \
--finetuning_type lora \
--output_dir ./saves/llama3_8b/lora/sft \
--overwrite_cache \
--overwrite_output_dir \
--cutoff_len 300 \
--preprocessing_num_workers 16 \
--per_device_train_batch_size 2 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--logging_steps 50 \
--warmup_steps 20 \
--save_steps 100 \
--eval_steps 50 \
--evaluation_strategy steps \
--load_best_model_at_end \
--learning_rate 5e-5 \
--num_train_epochs 5.0 \
--max_samples 1000 \
--val_size 0.1 \
--plot_loss \
--fp16
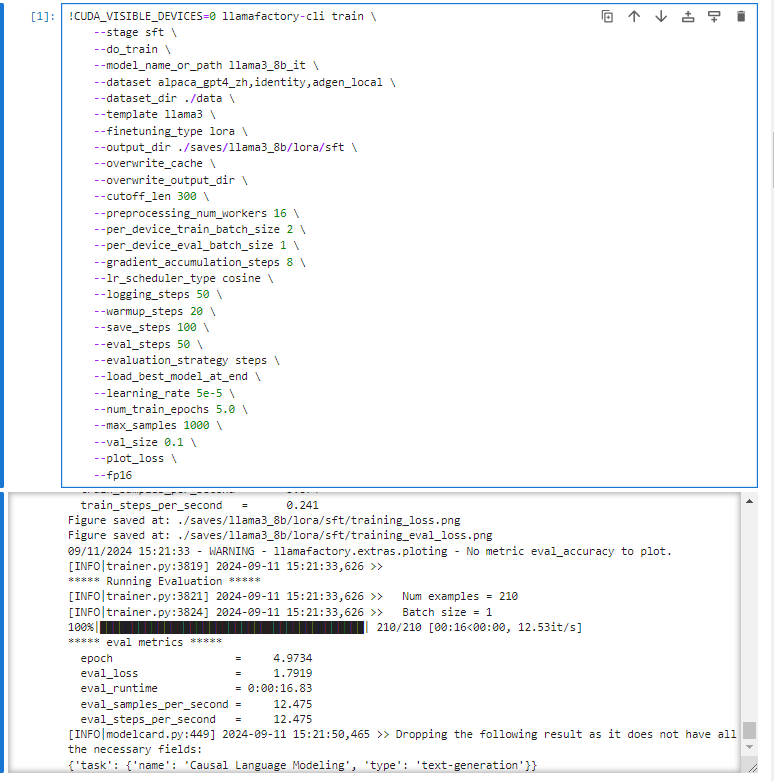
指令微调后新增文件目录
超出显存
1.清空torch.cuda.OutOfMemoryError: CUDA out of memory.
import torch, gc
gc.collect()
torch.cuda.empty_cache()
2.修改cutoff_len 从512 到300
【5】动态合并LoRA的推理
执行web端推理
!CUDA_VISIBLE_DEVICES=0 llamafactory-cli webchat \
--model_name_or_path llama3_8b_it \
--adapter_name_or_path ./saves/llama3_8b/lora/sft \
--template llama3 \
--finetuning_type lora
运行日志
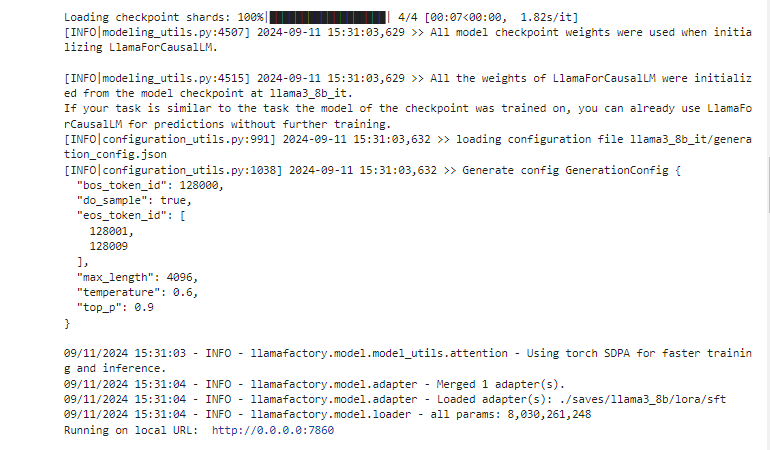
【6】批量预测和训练效果评估
安装相关包文件:
!pip install jieba
!pip install rouge-chinese
!pip install nltk
执行批量预测:
!CUDA_VISIBLE_DEVICES=0 llamafactory-cli train \
--stage sft \
--do_predict \
--model_name_or_path llama3_8b_it \
--adapter_name_or_path ./saves/llama3_8b/lora/sft \
--eval_dataset alpaca_gpt4_zh,identity,adgen_local \
--dataset_dir ./data \
--template llama3 \
--finetuning_type lora \
--output_dir ./saves/llama3_8b/lora/predict \
--overwrite_cache \
--overwrite_output_dir \
--cutoff_len 1024 \
--preprocessing_num_workers 16 \
--per_device_eval_batch_size 1 \
--max_samples 20 \
--predict_with_generate
运行日志
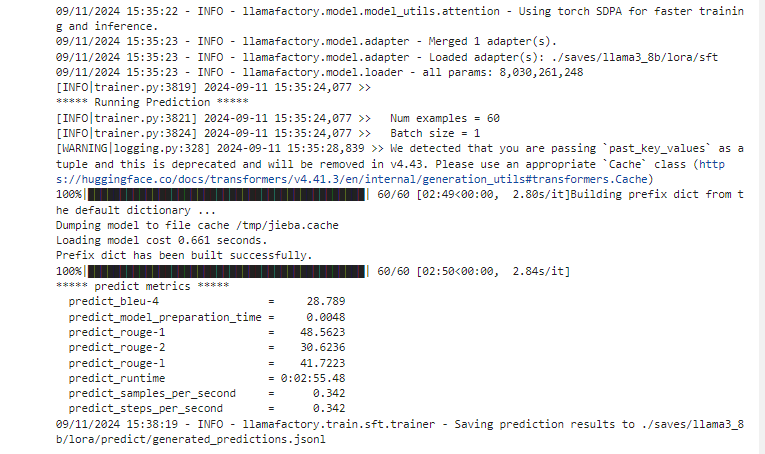
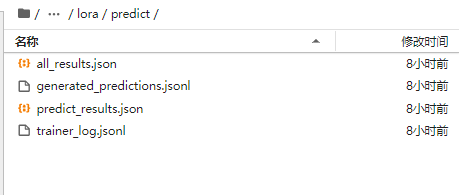
批量预测后得到结果:
【7】LoRA模型合并导出
执行Lora模型合并导出:
!CUDA_VISIBLE_DEVICES=0 llamafactory-cli export \
--model_name_or_path llama3_8b_it \
--adapter_name_or_path ./saves/llama3_8b/lora/sft \
--template llama3 \
--finetuning_type lora \
--export_dir megred-model-path \
--export_size 2 \
--export_device cpu \
--export_legacy_format False
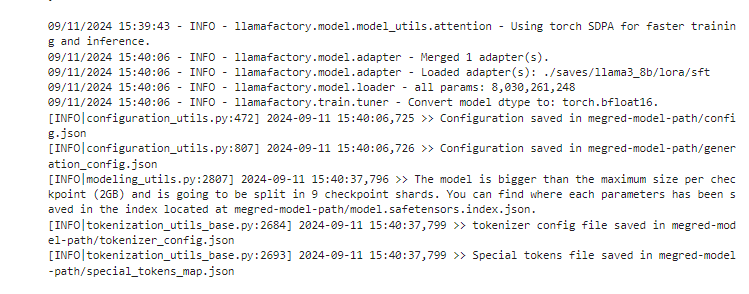
运行日志:
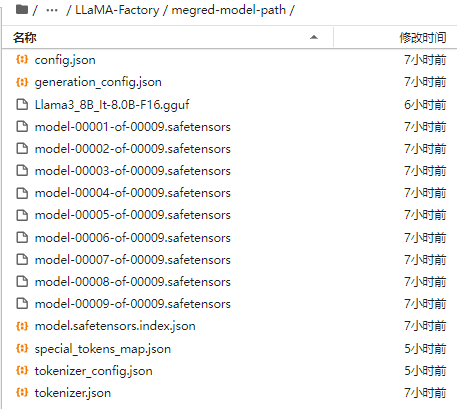
合并得到的微调后新模型:
【8】一站式webui board的使用
启动代码:
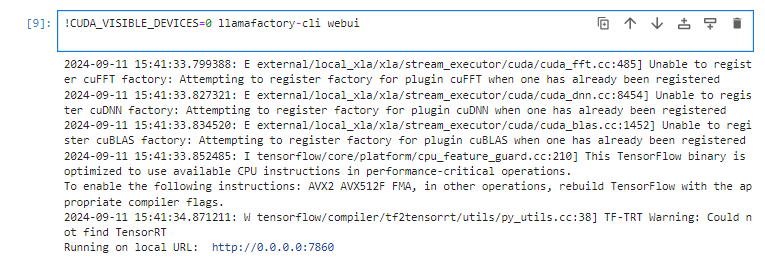
`!CUDA_VISIBLE_DEVICES=0 llamafactory-cli webui `
运行日志:
【9】API Server的启动与调用
训练好后,可能部分同学会想将模型的能力形成一个可访问的网络接口,通过API 来调用,接入到langchian或者其他下游业务中,项目也自带了这部分能力。
API 实现的标准是参考了OpenAI的相关接口协议,基于uvicorn服务框架进行开发, 使用如下的方式启动:
!CUDA_VISIBLE_DEVICES=0 API_PORT=8000 llamafactory-cli api \
--model_name_or_path llama3_8b_it \
--adapter_name_or_path ./saves/llama3_8b/lora/sft \
--template llama3 \
--finetuning_type lora
打开本地电脑cmd
ssh -CNg -L 8080:0.0.0.0:8080 root@proxy-ai.onethingai.com -p 13299
输入密码
基于vllm 的推理后端
项目也支持了基于vllm 的推理后端,但是这里由于一些限制,需要提前将LoRA 模型进行merge,使用merge后的完整版模型目录或者训练前的模型原始目录都可。
import os
from openai import OpenAI
from transformers.utils.versions import require_version
require_version("openai>=1.5.0", "To fix: pip install openai>=1.5.0")
if __name__ == '__main__':
# change to your custom port
port = 8000
client = OpenAI(
api_key="0",
base_url="http://localhost:8000/v1".format(os.environ.get("API_PORT", 8000)),
)
messages = []
messages.append({"role": "user", "content": "hello, where is USA"})
result = client.chat.completions.create(messages=messages, model="test")
print(result.choices[0].message)
!pip install openai
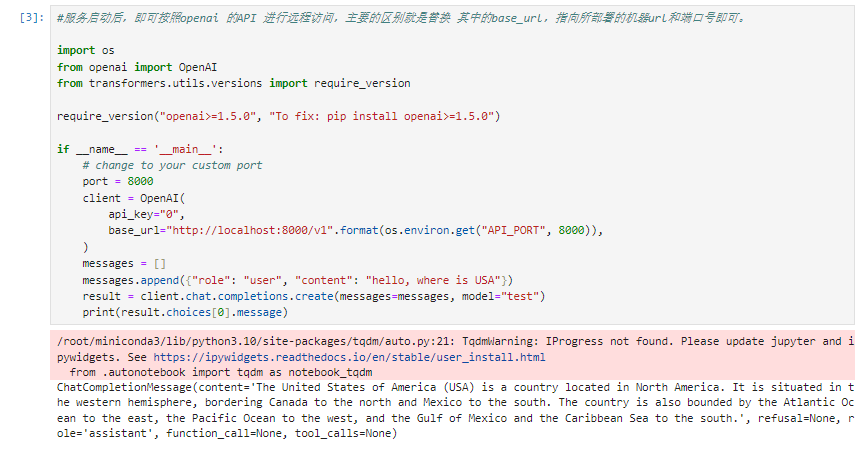
新建终端,服务启动后,即可按照openai 的API 进行远程访问,主要的区别就是替换 其中的base_url,指向所部署的机器url和端口号即可。
import os
from openai import OpenAI
from transformers.utils.versions import require_version
require_version("openai>=1.5.0", "To fix: pip install openai>=1.5.0")
if __name__ == '__main__':
# change to your custom port
port = 8000
client = OpenAI(
api_key="0",
base_url="http://localhost:8000/v1".format(os.environ.get("API_PORT", 8000)),
)
messages = []
messages.append({"role": "user", "content": "hello, where is USA"})
result = client.chat.completions.create(messages=messages, model="test")
print(result.choices[0].message)
测试结果:
【10】进阶-大模型主流评测 benchmark
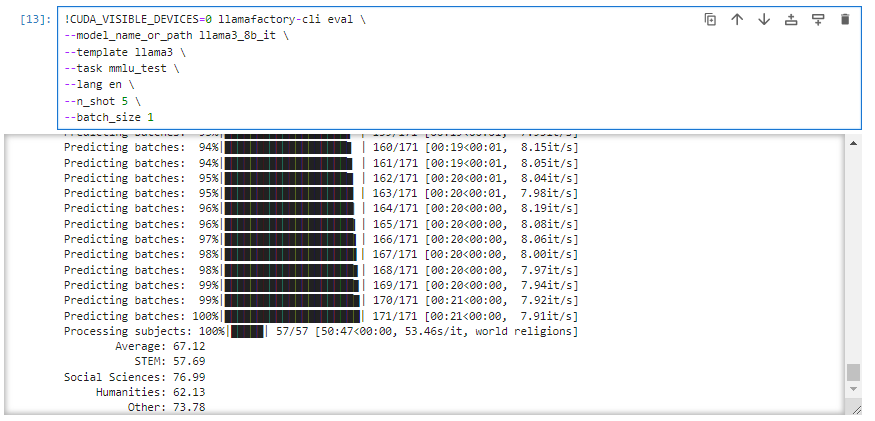
执行mmlu评测:
!CUDA_VISIBLE_DEVICES=0 llamafactory-cli eval \
--model_name_or_path llama3_8b_it \
--template llama3 \
--task mmlu_test \
--lang en \
--n_shot 5 \
--batch_size 1
生成mmlu评估结果:
【11】进阶-导出GGUF,部署Ollama
GGUF 是 lllama.cpp 设计的大模型存储格式,可以对模型进行高效的压缩,减少模型的大小与内存占用,从而提升模型的推理速度和效率。Ollama框架可以帮助用户快速使用本地的大型语言模型,那如何将LLaMA-Factory项目的训练结果 导出到Ollama中部署呢?
需要经过如下几个步骤
1.将lora模型合并 2.安装gguf库 3.使用llama.cpp的转换脚本将训练后的完整模型转换为gguf格式
4.安装Ollama软件 5.注册要部署的模型文件 6.启动Ollama
1-3 步是准备好 gguf格式的文件,这也是Ollama所需要的标准格式。
4-6 步就是如何在Ollama环境中启动训练后的模型。
1.lora模型合并
合并后的完整模型目录的绝对位置假设为LLaMA-Factory/megred-model-path
2. 安装gguf库
#!git clone https://github.com/ggerganov/llama.cpp.git
#Cloning into 'llama.cpp'...
#error: RPC failed; curl 56 GnuTLS recv error (-12): A TLS fatal alert has been received.
#fatal: error reading section header 'shallow-info'
git clone --depth 1 https://github.com/ggerganov/llama.cpp.git
!cd llama.cpp/gguf-py
!pip install --editable .
3. 格式转换
cd ..
python convert_hf_to_gguf.py ../megred-model-path.
#生成guff格式模型文件
4. Ollama安装
curl -fsSL https://ollama.com/install.sh | sh
5. 注册要部署的模型文件
#Ollama 对于要部署的模型需要提前完成本地的配置和注册, 和 Docker的配置很像
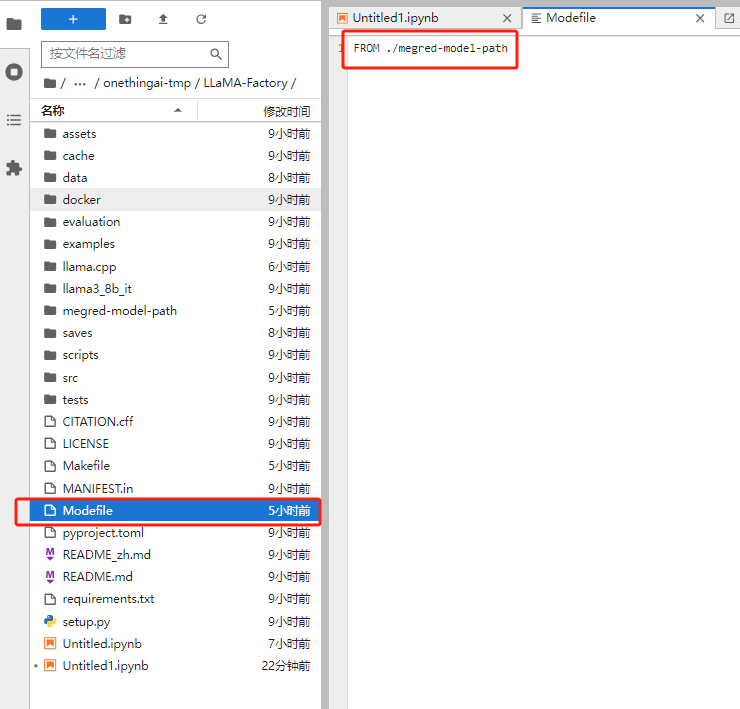
编写一个文件名为 Modelfile 的文件, 内容如下
FROM ./megred-model-path
!ollama create llama3-chat-merged -f Modelfile
6. 启动Ollama
上面注册好后,即可通过ollma 命令 + 模型名称的方式,完成服务的启动
ollama run llama3-chat-merged
注意:这里笔者往下遇到了Ollama 推理会无法停止, 或者重复输出,胡言乱语的问题,排查主要是二次训练保存后, tokenizer 的EOS编码和template有变化,如果也遇到了类似的问题,可以尝试将合并后的目录下的 tokenizer_config.json 和 special_tokens_map.json 两个文件删除,从 LLaMA3 原始的模型文件中将两者copy和覆盖过来,然后再继续后面的流程
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
下面这些都是我当初辛苦整理和花钱购买的资料,现在我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









