



基于鼠标移动数据的支持向量机分类器用户认证
1 引言
信息安全领域的初步任务之一是确保访问可能包含敏感和机密信息系统的人员是合法用户。为此,可通过用户认证方法将人员分类为合法用户或入侵者,该方法通常分为两类:(1)通过某人所拥有的物品进行认证,例如令牌、身份证;(2)通过某人所知的信息进行认证,例如密码或PIN码。然而,这些传统方法存在局限性。例如,令牌或身份证可能丢失、被盗或misplaced,而个人可能忘记其PIN码或密码。此外,入侵者还可能使用自动化密码破解工具获取他人的密码。为解决这些问题,
生物识别技术[1]通过使用个人所具有的独特生理或行为特征来识别身份。
尽管指纹、视网膜和虹膜扫描等物理生物特征识别系统提供了更强的安全性,但也需要昂贵的硬件来记录用户的生物特征数据。另一方面,网络行为生物特征(如击键或鼠标动态)是在用户与网络空间交互时自然产生的,具有以下优势:(1)不需要专用硬件,因此成本低廉;(2)非侵入性。由于这些原因,近年来对这些领域的研究正日益受到关注。
在本研究工作中,我们关注的是鼠标动态(mousedynamics),即通过分析鼠标等指向设备的操作所收集到的用户特征。该系统仅需配备鼠标即可运行。根据用户的鼠标操作,为每个用户配置文件提取并存储若干特征。当用户再次使用系统时,系统将其操作与其用户配置文件进行比对,判断其为合法用户还是入侵者。
论文贡献如下:
- 提出了48个新特征,并为实验定义和处理了74个总特征。这一丰富的特征集,结合我们采用的数据处理和分类方法,是实现低误拒率(1.1594%)和误识率(1.9053%)的关键。
- 性能比较(见第3节)表明,我们的方法与其他现有方法相比具有明显优势。
本文的其余部分组织如下:第2节描述了所提出的系统。第3节展示了所提出系统的实验结果,第4节描述了贡献、局限性以及未来的改进计划。
2 系统设计方案描述
所提出的系统分为三个主要部分。这些部分包括:(I)数据采集、处理与分割,(II)特征提取与归一化,以及(III)训练与分类。
2.1 数据采集、处理与分割
使用一种名为记录用户输入(RUI)的公开日志工具收集鼠标数据,该工具对23名志愿者的不同鼠标操作进行观察和记录。该数据集包含284小时的原始鼠标数据,平均每名用户有45个会话。志愿者可自行选择操作系统环境和应用程序,并被要求以正常、日常的方式使用他们的计算机和鼠标。
对于每个动作(如下所列),数据格式为经过时间(毫秒)、动作类型、X坐标和Y坐标。经过时间表示从开始监控系统到特定动作发生后的时间差(毫秒)。动作类型包括:
(I) 鼠标移动,(II) 按下左键,(III) 释放左键,(IV) 按下右键 和 (V) 释放右键。X坐标和Y坐标分别是屏幕上鼠标x和y坐标的像素位置值。表1显示了工具RUI记录的四个样本操作。原始鼠标数据随后被处理为三种高层级鼠标操作:鼠标移动、左键或右键的指点点击以及拖放。
在分割步骤中,根据鼠标操作次数将处理后的数据划分为不同的块大小。一个块由一组上述鼠标操作组成。使用的块大小为350、400、450、500、550和600。从每个块中提取一组特征。
| 经过时间(单位:ms) | 操作 | X坐标(单位:像素) | Y坐标(单位:像素) |
|---|---|---|---|
| 0.33 | 移动 | 204 | 492 |
| 0.338 | 移动 | 206 | 479 |
| 0.354 | 按下左键 | 206 | 479 |
| 0.394 | 释放左键 | 206 | 479 |
2.2 特征提取与归一化
在此步骤中,从预处理数据集中提取特征。特征的选择方式使得系统紧凑、高效,同时包含个体的一些独特特征。
对于每种动作类型,从每个块中计算出二十二个特征。这些特征包括:在块中执行特定类型操作所用时间(毫秒)的均值和标准差,在块中执行特定类型操作的移动距离(像素)的均值和标准差,块中特定类型的鼠标操作次数(N),以及鼠标操作次数(N)与总动作数之比。
提出的特定方向平均时间(XK tj)是指在K方向上执行某类动作的总时间与在整个块中执行同类动作的总时间之比。
$$
XK\ tj = \frac{\sum_{j=1}^{M} X\ K\ tj}{\sum_{i=1}^{N} Xt_i}
$$
其中,$XK\ tj$ 是执行 $j$ 个样本在 $K$ 个方向上的操作所需的时间;$Xt_i$ 是执行 $i$ 个样本的操作所需的时间。
提出了一种特定方向平均鼠标移动距离,用于在块(XK dj)中执行某一类型操作,其为在K方向上执行该类型操作的总移动距离与在整个块中执行相同类型操作的总移动距离之比。
$$
XK\ dj = \frac{\sum_{j=1}^{M} X\ K\ dj}{\sum_{i=1}^{N} Xd_i}
$$
其中,$XK\ dj$ 是 $j$ 个样本在 $K$ 个方向上的鼠标移动距离,$Xd_i$ 是 $i$ 个样本的鼠标移动距离。
另外八个特征 $\sum_{j=1}^{M} X\ K\ dj$ 也被计算出来,它们分别是每个方向上的总鼠标移动距离,XK dj 表示J的鼠标移动距离;M个样本在K个方向上。因此,特征总数为74,其中针对三种鼠标操作类型提出的特征总数为48。
| 特征 | 特征数量 |
|---|---|
| 时间均值 | 3 |
| 时间标准差 | 3 |
| 移动距离均值 | 3 |
| 移动距离标准差 | 3 |
| 鼠标操作次数 | 3 |
| 鼠标操作与总操作次数的比率 | 3 |
| 特定方向平均时间 | 24 |
| 特定方向平均鼠标移动距离 | 24 |
| 每个方向的总的鼠标移动距离 | 8 |
| 总特征 | 74 |
每个用户的特征向量。每个特征向量的维度是选定的特征数量,即74。在分类之前,特征向量的数据会在一个尺度上进行归一化。这有助于避免数值范围较大的属性掩盖数值范围较小的属性。通过这种方式,训练数据和测试数据将处于相同的尺度。在本系统中,使用最小‐最大归一化将数据归一化到0到1的范围内。
2.3 训练与分类
为了分析分类器如何验证合法用户,首先使用数据集中为选定用户随机选择的一组数据来训练分类器。训练数据模式包含该合法用户的操作模式。分类器同时还使用标记为合法模式的冒充者模式进行训练。然后将数据集的其他部分作为测试模式输入到该分类器中。测试完成后,通过检查预测标签来分析系统对合法用户数据的分类情况。
在本系统中,采用支持向量机(SVM)[3]分类器进行训练和测试。我们选择SVM分类器,因为它已被广泛应用于目标识别、语音识别、生物识别技术、图像检索、图像回归等领域。该分类器因其性能良好而被广泛接受,有时其表现甚至优于神经网络等其他分类器。
对于支持向量机(SVM),应用了两种技术。一种是使用原始特征向量(包含74个特征),另一种是通过主成分分析(PCA)[4]得到降维后的特征向量。主成分分析(PCA)是一种用于匹配高维数据中模式的数学技术。它有助于降低数据的维度,因此当数据集较大时,PCA通过降低维度并选择子集起到重要作用。
为了实现基于支持向量机分类器的系统,使用了开源软件包LIBSVM[5]。常用的核函数是高斯径向基函数(RBF)。核参数通过应用五折交叉验证技术获得。该系统在原始特征空间以及使用主成分分析(PCA)得到的降维特征空间上均应用了支持向量机。
3 实验结果与讨论
所提出的系统在配备 1.70 GHz Intel Core i3 4005U 处理器和 4.00 GB 内存的 Windows 7 系统上实现。系统的其他部分,如处理、分割、缩放和分类,均使用 MATLAB R2013a 完成。
所提出的系统通过使用公开基准数据 [6, 7] 进行测试。在该公开基准数据集中,定义了四种类型的操作:(1)鼠标移动(MM),表示正常的鼠标移动;(2)静止,表示鼠标未移动的时间;(3)指向并点击(PC),表示鼠标移动后伴随鼠标按钮按下和释放的操作;(4)拖放(DD),表示与鼠标操作组合相关的操作,例如鼠标移动、鼠标按钮按下然后依次释放。在实验前,静默操作的数据已从基准数据集中剔除。请注意,从这四种操作中派生出三个高层操作,如第2.1节所述。
通过计算误受率(FAR)和误拒率(FRR)来衡量性能。
3.1 分类结果
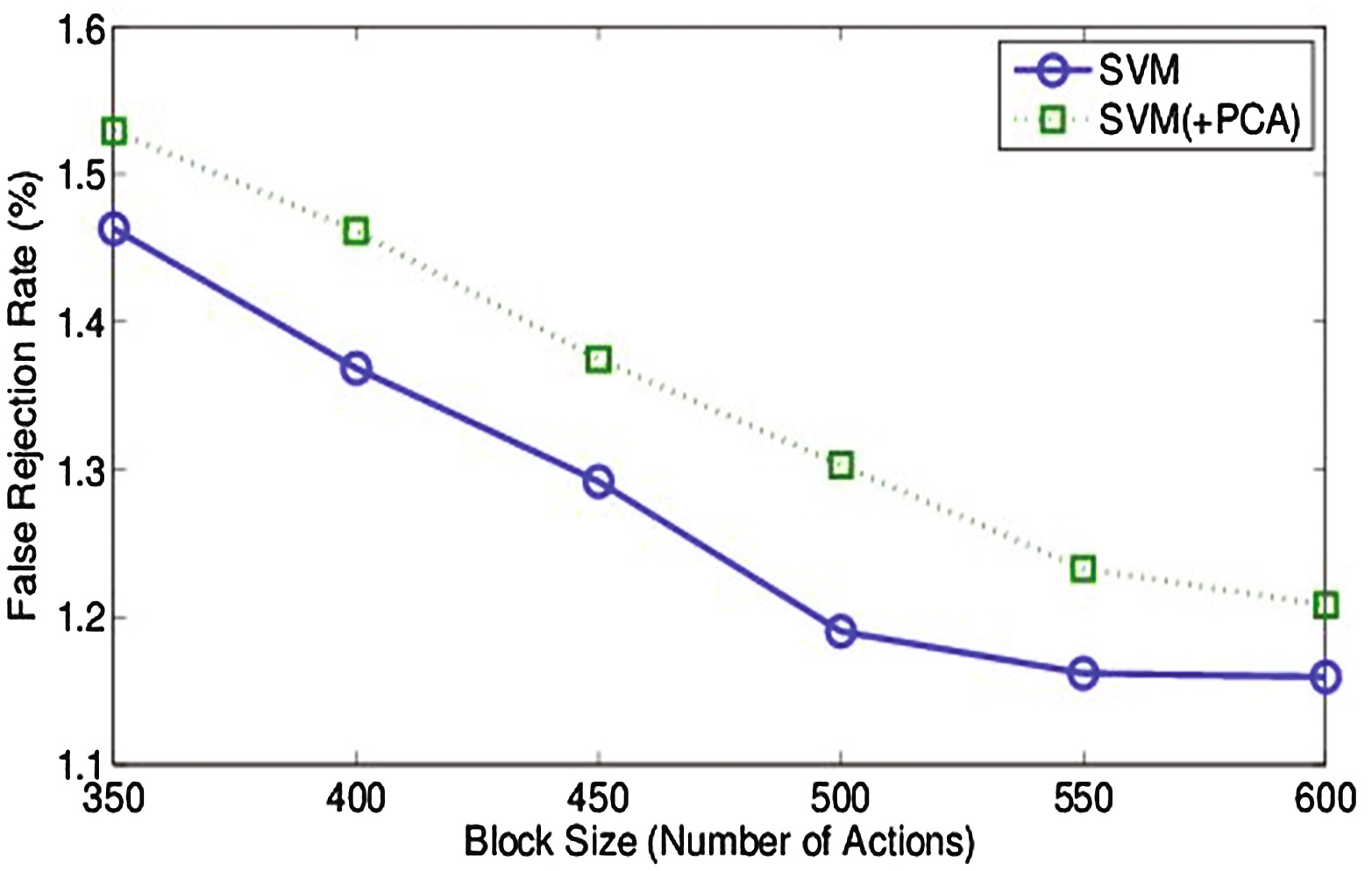
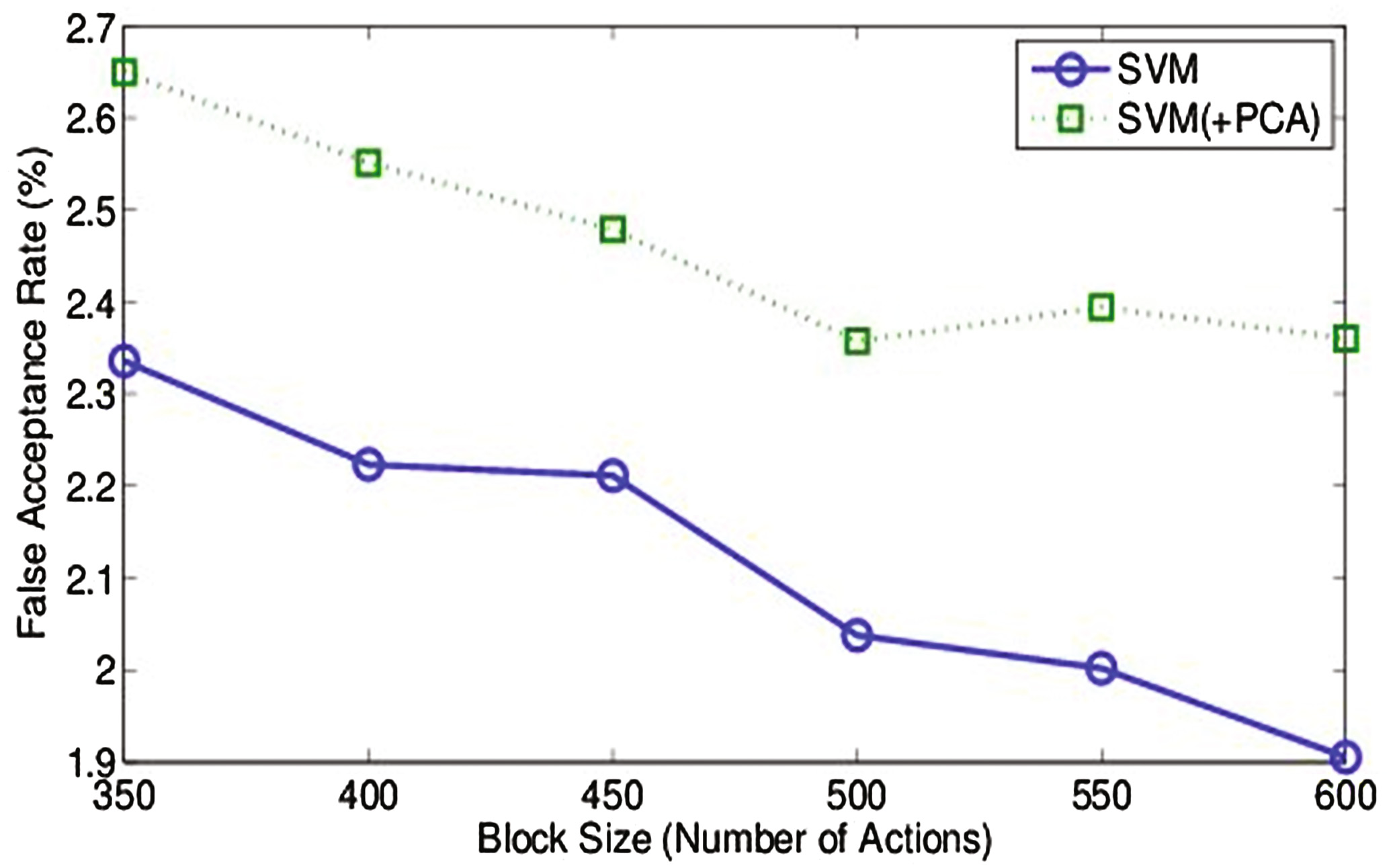
在不同大小的块(350、400、450、500、550 和 600个动作)上进行了实验,每个块包含从公开数据集中提取的74个特征。表3显示,在不同大小的动作块中,600个动作的块大小提供了更好的结果。对于600个动作的块大小,支持向量机和支持向量机(+PCA)的误拒率分别为1.1594%和1.2081%。同样,对于600个动作的块大小,支持向量机和支持向量机(+PCA)的误识率分别为1.9053%和2.3604%。
| 块大小(动作数量) | SVM 误拒率(%) | SVM 误识率(%) | SVM (+PCA) 误拒率(%) | SVM (+PCA) 误识率(%) |
|---|---|---|---|---|
| 350 | 1.4631 | 2.3358 | 1.5291 | 2.6496 |
| 400 | 1.3685 | 2.2234 | 1.4616 | 2.5512 |
| 450 | 1.2917 | 2.2114 | 1.3746 | 2.4789 |
| 500 | 1.1902 | 2.0379 | 1.3030 | 2.3574 |
| 550 | 1.1619 | 2.0020 | 1.2327 | 2.3941 |
| 600 | 1.1594 | 1.9053 | 1.2081 | 2.3604 |
 分类器比较)
分类器比较)
 分类器比较)
分类器比较)
在研究了不同分类技术的性能结果后,观察到使用原始特征空间的支持向量机具有更好的性能表现。
3.2 与相关工作的比较
在我们的实验中发现的结果与艾哈迈德等人在[7]中的发现进行了比较,该研究在鼠标动态领域被视为基准。从公开基准数据集中提取了艾哈迈德等人现有系统[7]的特征,并将其应用于所提出的系统。这些特征包括移动速度与移动距离(MSD)曲线、按移动方向划分的平均移动速度(MDA)、移动方向直方图(MDH)、按动作类型划分的平均移动速度(ATA)、动作类型直方图(ATH)、移动距离直方图(TDH)和移动耗时直方图(MTH)。通过对 MSD曲线进行周期性采样计算出12个点。对于TDH,使用0–100像素和100–200像素范围内的值。对于MTH,收集0.0–0.5秒、0.5–1.0秒以及1.0–1.5秒范围内的值。总共特征数量为39个。
对于600个动作的块大小,使用文献[7]中提出的现有特征集,SVM和 SVM(+PCA)分别提供的误拒率为1.6001%和1.7851%,高于我们提出的系统在相同数据集和块大小下的误拒率。同样,对于600个动作的块大小,使用文献 [7]中的现有特征,SVM和SVM(+PCA)分别提供的误识率为2.9798%和 2.9042%,也高于我们的结果。这明显表明了我们新提出特征的优势。
近年来,其他几项研究也取得了令人印象深刻的结果。下面我们提及一些重要的研究成果,并将其结果与我们的进行比较。
(1) 艾哈迈德等人[7]的研究中,他们实现了2.4614%的误拒率和2.4649%的误识率。为达到此性能,所需操作次数为2000次,这些操作包括指向并点击、拖放、鼠标移动和静止。(2) 纳卡比等人[6]在相同数量的鼠标操作下,展示了 0.36%的误拒率和0%的误识率。然而,所需的鼠标操作次数较多,实际应用中并不总是可行,例如通过玩拼图游戏来使用该系统。(3) 普萨拉和博德利[8]提出了一种基于网页的认证系统,其中使用决策树作为分类器。该系统表现出良好效果,假阴性率为1.75%,假阳性率为0.43%。但该研究仅涉及十一名用户。(4) 穆图玛丽等人[9]在其研究中,采用学习向量量化(LVQ)方法,实现了 6.25%的误拒率和7.25%的误识率。(5) 在他们的另一项工作[10]中,使用核主成分分析(KPCA)方法降低特征向量的维度,并采用一类支持向量机作为分类器,实现了8.25%的误拒率和8.98%的误识率。(6) 拉克希米普里亚等人 [11]的方法中使用了整体特征和过程特征,并应用最近邻算法提取特征,实现了7.70%的误拒率和8.75%的误识率。(7) 拉赫曼等人[12]的方法采用了基于统计正态分布的相似度评分方法,测得等错误率(EER)为6.7%。
与上述现有方法相比,我们的方法即使处理更少的操作次数(例如最多 600次),也表现出显著更低的错误率。那些错误率低于我们的研究,要么受限于不足的样本数量(如[8]中所示),要么由于测试环境受限而不切实际(见[6])。
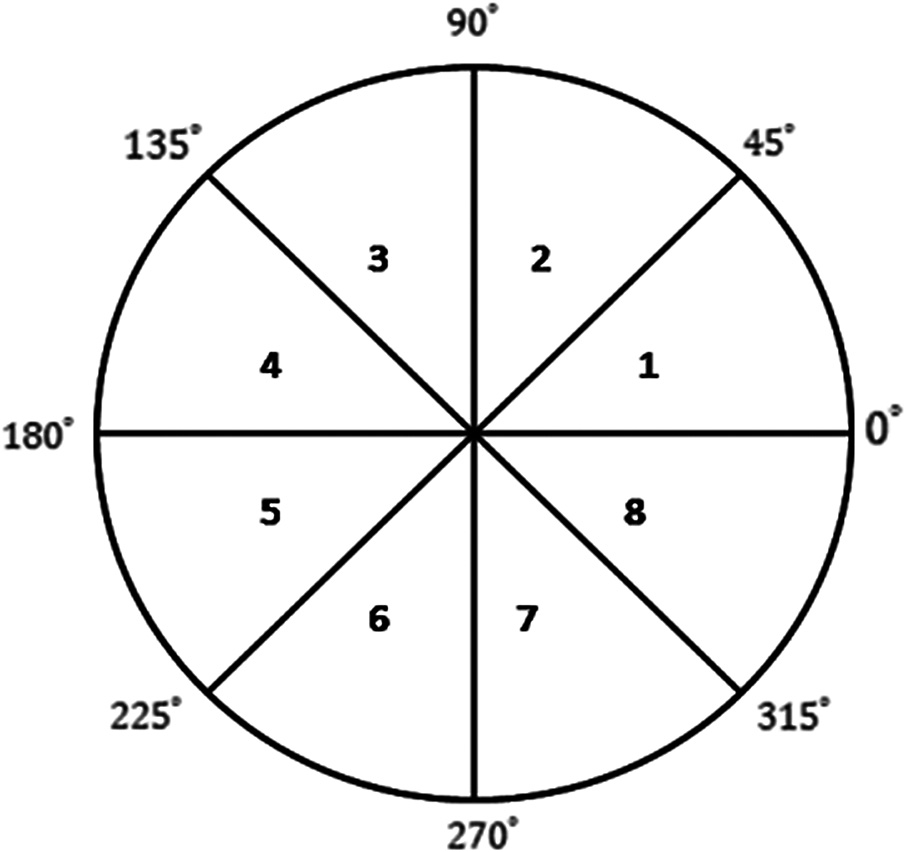
4 结论
在本系统中,获取了三种类型的鼠标操作:鼠标移动、左右键的指点点击以及拖放。处理后的数据被划分为块,其中块表示一组特定数量的鼠标操作。从每个块中提取74个特征以形成特征向量,其中新特征的数量为48个。针对每种类型的鼠标操作,特征均基于执行操作时的移动距离的均值和标准差、经过时间的均值和标准差、鼠标操作次数的均值、提出的操作特定方向平均时间以及方向特定平均移动距离进行计算。鼠标的移动方向由45°间隔的八分仪描述。利用这些特征,一个人执行某项操作的鼠标移动距离和总时间通过八个值来描述,而不是单一的方向。特征向量的数据被归一化到0至1的范围。归一化后,特征向量被输入分类器。系统中使用了基于原始特征空间的支持向量机(SVM)以及基于主成分分析(PCA)降维特征空间的支持向量机(SVM)。为测试该系统,采用了公开基准数据集。针对六种不同的块大小,对系统性能进行了测量和分析。之后实验观察到,系统在块大小为600时性能更优。实验结果表明,在原始特征空间中,支持向量机提供1.1594%的误拒率和1.9053%的误识率;在通过主成分分析降维后的特征空间中,支持向量机分类器提供1.2081%的误拒率和2.3604%的误识率。
由于基准数据集的不足,该系统未考虑某些操作。未来将考虑更多类型的操作,例如双击、鼠标滚轮等。预计将收集更大的数据集并针对我们的系统进行测试。基于一些令人鼓舞的初步结果,我们相信该系统可以与其他传统认证系统结合使用,以构建多模态认证系统。

















 45
45

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









