



帕拉丁行为机器人期刊,2016;7:40–54
研究文章 开放获取
通过心理模拟进行情绪估计的人类表情模仿
DOI 10.1515/pjbr‐2016‐0004 收稿日期:2016年8月 1日;接受日期:2016年12月20日
摘要 :人类在交流过程中能够表达自身情感并估计他人的情绪状态。本文提出了一种能够估计他人情绪状态并生成情感自我表达的统一模型。所提出的模型采用多模态受限玻尔兹曼机(RBM)——一种随机神经网络。受限玻尔兹曼机能够从输入信号中抽象出潜在信息,并基于该信息重构信号。我们利用这两个特性来解决以往提出的情感模型中存在的问题:构建用于情感估计与生成的情绪表征,而非依赖启发式特征;并通过心理模拟实现从他人模糊信号中推断其情绪。实验结果表明,所提出的模型能够通过自组织学习提取表征情感类别分布的特征。模仿实验表明,当他人表达中存在情感不一致时,使用本模型的机器人相比直接映射机制能够生成更优的表达。此外,该模型能够通过对有缺陷的多模态信号生成想象的感官信号(即心理模拟),从而提升对他人情绪状态的估计置信度。这些结果表明,所提出的模型的能力有助于在更复杂的情境下促进情感人机交互。
关键词 :情感,人机交互,深度学习,心理模拟,模仿
1 引言
向他人传达情感是在人际交往和人机交互中的重要技能。为了实现情感交流,研究人员已开发出多种共情机器人[1–13]。布雷齐尔等人[1]提出了一种名为莱昂纳多的 creature 机器人,能够模仿人类的面部表情。莱昂纳多通过神经网络学习人面部表情与其自身表情之间的直接映射关系。Andra 和 Robinson[2]开发了一款仿生机器人头部,旨在通过模仿人类面部表情对自闭症儿童进行社会情感干预。该机器人追踪受试者表达情绪状态时的面部特征点,并将其直接转换为相应的控制点,以调整自身的面部表情。然而,人类表情的直接映射可能导致情绪状态的错位。例如,人类在欣喜时哭泣也可能表现出流泪的表情。此外,他们的表情会因情境不同而变化。因此,仅对面部表情(如哭泣)进行映射可能导致情绪状态(如快乐)的误传。因此,机器人系统最好先估计交流对象的情绪状态,并根据所估计的状态生成相应的表情。
目前存在多种共情机器人,它们会根据他人的内部状态来调整自身表达[3–10]。Trovato 等人[3] 和 岸 等人[4] 基于心理学研究为人形机器人 KOBIAN 开发了情感模型。该模型表征了受外部刺激调节的 KOBIAN 内部状态。此外,该模型还包含基于特定情绪状态的面部表情原型,并将面部模式表示为这些原型的组合[14]。另外,一种名为 BARTHOC 的拟人化机器人能够通过语音识别人类的情感,并生成对应于六种基本情绪的面部表情[5]。Kismet[6, 7] 是最著名的社交机器人之一,能够与人类建立情感交流。Kismet 系统提取与三种情感值(即唤醒度、效价和态度)相对应的特征

从人类语音中进行情感识别,然后通过插值预编程表情原型生成面部表情。然而,由于在这些先前的研究中,情感识别系统和情感表达系统是使用不同架构分别开发的,因此可能会出现各个系统无法通过持续与人类互动来共享新获取的知识等问题。
林和奥久野[12, 13]提出了多模态情感智能(MEI),该方法利用集成架构来识别他人的情绪状态并生成自身的情绪表达。他们的模型受到镜像神经元系统(MNS)的启发,MNS是人类认知的基础机制[15, 16]。MNS在执行自身动作以及观察他人执行相同动作时均会被激活。在情感交流的情境中,这种机制使人们能够基于自身表达相应情绪的感觉运动经验,来想象他人的情绪状态[17, 18]。MEI采用高斯混合模型(GMMs),在同一架构中实现情绪的识别与生成。对他人情绪状态的识别通过GMMs对输入特征进行分类来实现,而自身情绪状态的表达则是通过对对应特定状态的选定高斯分布进行特征采样来完成。该模型的一个重要特点是其计算了四种假设在不同模态中普遍存在的特征:速度、强度、不规则性和幅度(SIRE)。因此,在使用SIRE进行语音训练后,MEI不仅能够从音频信号中估计情绪类别,还能从步态信号中进行估计。它还可以为机器人的声音、步态和手势生成SIRE。他们的模型提供了一种受MNS启发的有前景的方法。然而,该系统存在两个局限性:第一,SIRE是由设计者定义的启发式特征;每种模态可能包含特有的用于表达情绪的特征。第二,尽管他们考虑了MNS,但并未考察心理模拟在估计他人情绪中的作用。心理模拟是一种基于自身感觉运动经验生成想象信号的过程,被认为有助于理解他人的情绪状态[17, 18]。
一项关于情感分类的研究已被报道,该研究能够纠正上述第一个问题。金等人[19]提出了深度神经网络,用于从视听信号中学习提取情绪分类的特征。在他们的系统中,使用由受限玻尔兹曼机(RBM)组成的深度置信网络(DBNs)作为无监督学习机制。受限玻尔兹曼机可以抽象输入信号并从中重构信号。在实验中,他们的模型从一般特征中提取了特定于情感的特征,而这些一般特征并不总是对情感分类很重要。他们的结果表明,深度神经网络可以获得用于表示情感的特征。
本文提出了一种统一模型,该模型能够估计人类情绪,并基于对交互伙伴情绪的估计,在人机交互中模仿人类表情生成机器人自身的情感表达。需要注意的是,本文将“模仿”定义为机器人根据交互伙伴的情绪状态生成表情。该模型克服了以往情感模型面临的两个问题:一是利用多模态信号构建情感表征以实现情绪的估计与生成,而非使用启发式特征;二是通过心理模拟从模糊的多模态信号中推断他人情绪。我们采用受限玻尔兹曼机(RBM)来解决这两个问题,因为RBM能够对输入信号进行抽象并从中恢复信号。RBM的抽象能力使我们能够通过降低多模态信号的维度以及关联多模态信号来克服第一个局限性。此外,由RBM构成的本模型通过利用生成感知运动信号的能力实现了心理模拟。这种心理模拟机制使模型能够基于自身经验,从部分多模态表达中估计他人的情绪状态。
我们通过三个实验检验所提出的模型的能力:1)利用受限玻尔兹曼机(RBM)的自组织特征提取能力,从人类多模态表达中构建情感表征,使机器人能够基于对人类情感的估计来模仿其表达;2)在人类表达的模态存在冲突时,通过模仿实验验证统一模型相较于直接映射模型的优势;3)在部分人类表达的模仿交互中,展示心理模拟的优势。最后,我们讨论了我们的模型能力与镜像神经元系统(MNS)之间的关系、该模型的局限性以及有待解决的未来问题。
2 目标任务与一种提出的方法
本节介绍了我们在人机交互中的目标任务以及所提出的模型,使机器人能够根据对他人情绪状态的估计,模仿他人的多模态表达。
2.1 基于情感的模仿的挑战与要求
我们将人类与机器人之间的面对面交互作为本研究的目标场景(图1)。人类和机器人使用多模态信号,如面部表情、手势动作和语音,进行相互交流。该交互的目的是让人类通过多模态信号表达其情感,而机器人则基于对伙伴情感的情绪估计,模仿对方的表达作为自身的多模态表达。为了模仿他人的情感表达,机器人不应直接复制他人的表达,而是需要通过对他人情感的情绪估计生成自身的表达,因为人类的表达有时具有模糊性。例如,人类的多模态表达在不同模态间可能存在情感不一致(即高兴得流泪时的流泪的表情),或机器人在交互中部分未能感知到人类的表达。仅复制他人的表达不足以实现对他人情感表达的有效模仿。
为了实现机器人在这些方面的目标,我们的计算模型需要具备对他人情绪进行估计以及基于情绪生成自身情绪表达的机制。此外,该模型还需要其估计机制能够对模糊观测具有鲁棒性。由受限玻尔兹曼机(RBM)构成的所提出的模型可以通过表示两个过程来解决这些问题:对他人的情绪状态进行估计的过程,以及基于对他的估计情绪生成自身表达的过程。在同一模型中表示这两个过程使我们能够实现心理模拟机制,以更新对他的估计信念。在后续章节中,我们将解释所提出的模型的架构以及情绪估计与生成的方法。
2.2 提出的模型
我们的模型由两部分组成:底层中每种模态对应的堆叠RBM,以及顶层用于整合来自底层RBM信号的受限玻尔兹曼机(图2a)。模型首先在每个模态的RBM处接收来自交互对象的多模态表达作为输入信号,并通过从前向采样从底层到顶层进行情感状态估计(红色箭头)
如图2a所示。在估计之后,模型利用估计出的情感,通过从顶层向底层的后向采样(图2a中的绿色箭头),根据对方的情感生成自身对对方表情的模仿表达。也就是说,本模型的底层表示人类和机器人的多模态信号,而顶层表示这些信号的情感状态。
我们首先在第2.2.1节中详细介绍作为所提出模型组成部分的受限玻尔兹曼机(RBM),并在第2.2.2节中介绍我们称为多模态深度置信网络的模型架构。随后,我们解释情绪的估计与生成机制,以及通过重构他人的模糊信号来更新与情绪估计相关的信念,从而实现心理模拟的方法。
2.2.1 Restricted Boltzmann machine
受限玻尔兹曼机[20, 21]是一种生成模型,用于表示数据分布和潜在表示的生成过程,并能从潜在信号[22–25]生成数据。受限玻尔兹曼机由两种类型的随机神经元组成:可见单元 vi 和隐藏单元 hj,其中 i 和 j 是每个神经元的索引编号。可见单元接收输入信号(例如摄像头图像),而隐藏单元生成从输入信号中抽象出的特征(例如图像的边缘)。每一层与其他类型的层具有完全对称的连接(即连接权重 wij= wji);然而,同一层内部没有连接(图2b)。
可见单元和隐藏单元激活的二进制值(即 vi ∈{0, 1}, hj ∈{0, 1})的概率由以下公式给出
P(vi= 1|h; θ)= σ(∑j hj wij+ ai), (1)
P(hj= 1|v; θ)= σ(∑i viwij+ bj), (2)
其中,ai 和 bj 分别是对应单元 vi 和 hj 的模型参数, σ (x) 是 S形函数 1/(1+exp(−x))。伯努利‐伯努利受限玻尔兹曼机可通过公式 (2) 在隐藏层中获取输入信号 v 的潜在信息 h,并可通过公式 (1) 重构输入信号。可见单元和隐藏单元的联合概率服从由网络能量函数决定的玻尔兹曼分布。伯努利‐伯努利受限玻尔兹曼机的概率分布和能量函数 E(v, h; θ) 定义为
P(v, h; θ)= 1/Z(θ) exp(−E(v, h; θ)), (3)
E(v, h; θ)= −∑i aivi −∑j bj h j −∑i ∑j vihj wij , (4)
其中 Z(θ) 是一个归一化常数,用于将概率值保持在 0 到 1 的范围内,而 θ={a、 b、 w} 是模型参数。
受限玻尔兹曼机通过潜在信号,利用公式(1)和(2)调节参数 θ ,以最小化实际输入信号与重构输入信号之间的重构误差。为了推导模型参数 θ的更新规则,我们对边缘对数似然log∑h exp(−E(v, h))关于传统基于梯度的方法进行求导。更新规则由下式给出
∆wij= ϵw(⟨vihj⟩data −⟨vihj⟩recon), (5)
∆ai= ϵa(⟨vi⟩data −⟨vi⟩recon), (6)
∆bj= ϵb(⟨hj⟩data −⟨hj⟩recon). (7)
这里,角括号 ⟨·⟩data和 ⟨·⟩model表示在输入信号和重构信号下的期望值,而 ϵw、 ϵa和 ϵb是对应模型参数的学习率。我们将这些值添加到相应的参数中(即wt+1 ij=wt ij+∆ wt ij。其中,t为学习步骤)。有关受限玻尔兹曼机学习过程的详细信息,请参见[21]。
为了考虑可见层中实数值的建模(即vi ∈ R)由于连续传感器值的影响,我们用高斯单元vi ∈ R替代二进制单元。每个可见层和隐藏神经元的激活概率由下式给出
p(vi|h)= N(vi|∑j hj wij+ ai, σ²i), (8)
P(hj= 1|v)= σ(∑i (1/σ²i) viwij+ bj), (9)
其中 N(·|μ, σ²) 是均值为 μ、方差为 σ² 的正态分布。此外,高斯‐伯努利受限玻尔兹曼机的能量函数在[26]中定义为
E(v, h; θ)=∑i (vi − ai)² / (2σ²i) −∑j bj hj −∑i ∑j (1/σ²i) vihj wij, (10)
其中 σi是与第i个可见单元相关的标准差。
由于能量函数与伯努利‐伯努利受限玻尔兹曼机不同,因此必须修改更新规则。高斯‐伯努利受限玻尔兹曼机的规则如下所示
∆wij = ϵw(⟨ (1/σ²i) vihj ⟩data − ⟨ (1/σ²i) vihj ⟩recon), (11)
∆ai= ϵa(⟨ (1/σ²i) vi ⟩data − ⟨ (1/σ²i) vi ⟩recon), (12)
∆bj= ϵb(⟨hj⟩data −⟨hj⟩recon). (13)
除了更新这些模型参数外,我们还可以调节另一个模型参数 σi,以通过公式(8)最小化实际感觉信号与重构感觉信号之间的重构误差。我们通过一个新的参数zi= logσ²i来调节每个方差 σi,因为方差必须取正值(σi> 0)。zi的更新规则为
∆zi= ϵz e⁻ᶻⁱ ⟨½(vi − ai)² −∑j vihj wij⟩data − ϵz e⁻ᶻⁱ ⟨½(vi − ai)² −∑j vihj wij⟩recon. (14)
2.2.2 多模态深度置信网络
我们考虑了多模态信号(在我们的实验中即面部表情、手势动作和语音)的关联,以获取人类情感表达的表征。为了建模这种情感表征,我们使用多个受限玻尔兹曼机(RBM),首先从每个感觉信号中提取特征,然后通过一个单一的受限玻尔兹曼机进行整合。首先,堆叠两种不同的受限玻尔兹曼机,从每个感觉信号中抽象出低维特征,其中下层受限玻尔兹曼机为高斯‐伯努利受限玻尔兹曼机,适用于连续感觉信号,上层受限玻尔兹曼机为伯努利‐伯努利受限玻尔兹曼机。在感觉网络的每一层使用不同类型的受限玻尔兹曼机的原因是:若使用伯努利‐伯努利受限玻尔兹曼机直接处理原始感觉信号,会导致信息损失,因为我们必须将连续的感觉值离散化才能编码;另一方面,若对离散值(即通过高斯‐伯努利受限玻尔兹曼机编码后的信号)使用高斯‐伯努利受限玻尔兹曼机,则会导致学习成本增加,并且相比伯努利‐伯努利受限玻尔兹曼机,更多模型参数容易陷入局部解。然后,引入另一个称为关联受限玻尔兹曼机的伯努利‐伯努利受限玻尔兹曼机,将其可见层汇聚各个堆叠受限玻尔兹曼机的顶层,以整合所有模态(见图2a)。该结构被称为多模态DBN[24]。
设hFt,i ∈{0, 1}、hHt,j ∈{0, 1}以及hSt,k ∈{0, 1}分别表示面部表情、手部动作和语音网络的顶层隐藏单元。关联受限玻尔兹曼机第s个隐藏单元的激活概率 hAs ∈{0, 1}由下式给出
p(hAs= 1|hFt, hHt, hSt)= σ(∑i hFt,iwis+∑j hHt,j wjs+∑k hSt,kwks+ bAs), (15)
其中,w·s 是每个感觉受限玻尔兹曼机(RBM)的顶层隐藏单元与关联受限玻尔兹曼机的第 s 个隐藏单元之间的连接权重, bAs 是一个偏置参数。
该模型的每个受限玻尔兹曼机网络均从底层到高层分别进行训练并堆叠。高斯‐伯努利和伯努利‐伯努利受限玻尔兹曼机分别使用公式(5)–公式(7)和公式(11)–公式(14)来训练模型参数。有关训练方法的详细信息,请参见[21]。
2.3 提出的模型中的心理模拟机制
已知镜像神经元系统(MNS)基于自身经验从观察信号生成运动信号[16]。这种被称为心理模拟的MNS模拟机制有助于理解他人的行为。近年来的研究表明,该机制还与理解他人的内部心理状态(包括情感[17, 18])有关。人类不仅通过感知他人的面部表情来估计他人的情绪状态,还依赖于自身对面部表情的经验和知识。奥伯曼等人[27]报告称,当受试者阻止模仿他人的面部表情时,识别他人情绪状态的能力也会受到干扰。该结果表明,利用自我生成的信息能够提高对他人情绪状态估计的准确性。
我们的模型通过多模态深度置信网络的生成能力,展示了心理模拟的这种能力。在人机交互过程中,该模型接收来自伙伴的多模态信号(即视觉信号和听觉信号,如图1所示)。该模型可以通过从前向采样从每个堆叠RBM到关联受限玻尔兹曼机来估计他人的情绪状态(由图2a中的红色箭头表示)。该模型还可以通过从顶层向各个堆叠RBM的可见层进行后向采样,利用相同的网络结构生成自身的多模态表达(由绿色箭头表示)。基于这些机制,该模型能够通过前向和后向采样,从观测到的信号重构出伙伴缺失的多模态表达,形成虚拟观测信号。例如,我们假设面部信号缺失(即 vF= 0)来自交互。该模型通过其他模态(即手势动作和语音)以及对他人不完全估计的状态,重构未观测的面部信号(即 vF= 0 → vF=^vF)。然后,模型能够利用重建信号与观测信号通过重复采样来更新其对他人情感的估计信念。算法1提供了心理模拟的详细过程,其中 vO、 vU 和 ^vU 分别表示网络可见单元(即模型的最底层)的观测信号、未观测信号和重建信号,而 vA 和 hA 表示模型关联受限玻尔兹曼机的可见激活和隐藏激活。从 p(vA= vA|vO, vU= 0) 和 p(hA= hA|vA) 的采样表示在观测模态、未观测模态的受限玻尔兹曼机以及关联受限玻尔兹曼机中的前向采样。这些前向采样生成基于部分多模态表达的对他人情感的初步估计。另一个来自 p(vU=^vU|hA) 的采样表示用于重构未观测信号的后向采样。在信号重构之后,我们的模型重复进行前向采样以更新估计,并重复后向采样以优化重建信号,共进行 N 次。最后,模型获得更新后的估计 ^hA,并基于该估计生成自身的表达以实现模仿。
3 实验与结果
在本节中,我们介绍实验设置并报告实验结果。所提出的模型的主要目标是使机器人通过我们的模型进行模仿,基于对交互伙伴情感的估计,即使在交互伙伴的表情模糊或缺失的情况下,也能表达出交互伙伴的表情。
我们通过三个实验评估了模型在模仿人类情感表达方面的能力:1)从人类的多模态信号中构建情绪表征;2)将通过我们的模型模仿的情绪表达与直接映射方法的结果进行比较;3)在由模糊信号进行人类情感估计时,评估心理模拟能力。在第一个实验中,我们检验了模型的特征提取能力,该能力使机器人能够基于对人类情绪的估计来模仿其情感表达。在第二个实验中,当人类情感表达在不同模态之间存在冲突时,我们比较了我们的模型与直接映射系统之间的模仿能力。在第三个实验中,我们在模仿任务中考察了基于对人类情感表达的部分观测来更新情感估计的心理模拟能力。
我们首先介绍实验中使用的数据集及其多模态特征,以及在所提出的模型上的参数设置。随后,我们报告了三个实验的结果。
3.1 实验设置
3.1.1 使用IEMOCAP数据集作为交互数据
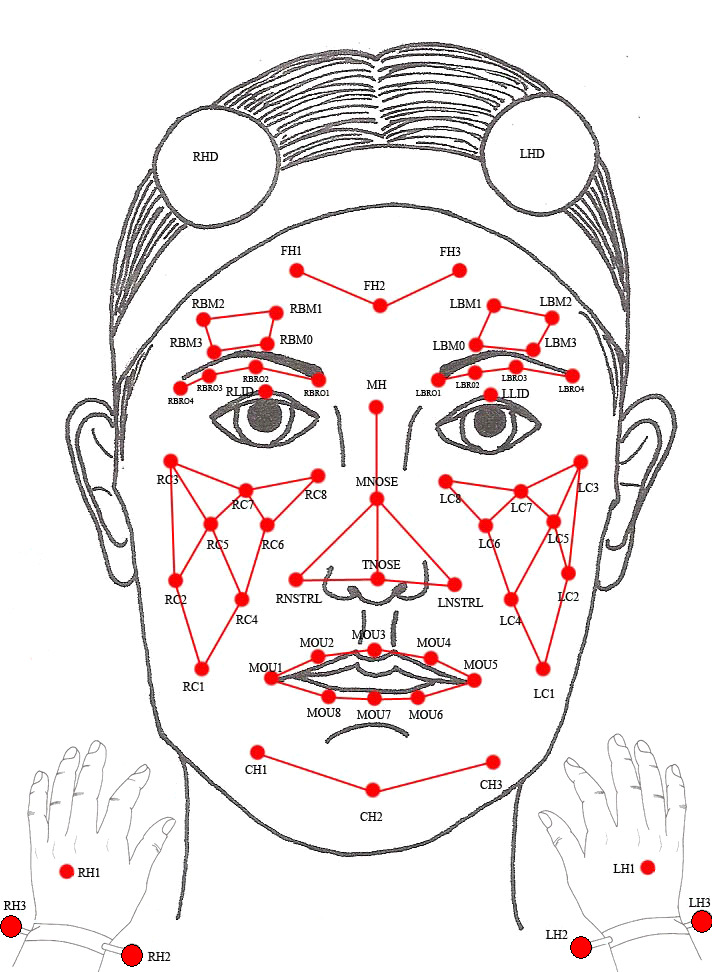
我们使用交互式情感双人动作捕捉(IEMOCAP)数据库[28]作为实验的交互数据。IEMOCAP数据库包含了来自10名演员在剧本和即兴场景中的视听数据。面部表情和手势动作通过动作捕捉系统进行记录。图3展示了动作捕捉标记点的一个示例。受试者在面部安装了53个标记,在手上安装了6个标记。对话还通过摄像机进行了录制。
所有记录的数据均使用分类标签和连续三维值进行评估。每次互动的每条话语均由三名以上的评估者进行标注。我们采用了与[19, 29]相同的方法,选取了四种特定情绪对应的数据:快乐、中性、愤怒和悲伤。当评估者之间的标注不一致时,我们仅选择多数投票情绪类别作为每条话语的真实值。例如,对于某条特定话语,如果有两名评估者选择悲伤类别,而一名评估者选择中性类别,则我们将该话语的情感类别真实值设为悲伤。我们选取了三名演员的数据作为训练数据

数据集和一位演员的数据作为测试数据集。训练数据集的总数为634(快乐:106,中性:171,愤怒:164,悲伤:193),测试数据集的总数为202(快乐:31,中性:70,愤怒:40,悲伤:61)。
3.1.2 从IEMOCAP数据集进行特征提取
我们从IEMOCAP数据库中计算了用于实验的基本音视频特征,分为两个步骤。首先,我们提取了模态依赖特征。面部特征包括34个标记之间的距离以及这些距离相对于前一个时间步的变化。图3中的每条绿色线条对应一个特征。由于标记在y坐标方向上变化不明显,因此每个距离在二维空间(即x,z)中表示。音频特征包括音高、强度、13维梅尔频率滤波器组(MFBs),以及它们相对于前一个时间步的变化。
此外,我们使用手势动作作为特征,与先前的研究[19, 29]相比,这是因为在交互对象的表情发生冲突时,人类会更多地考虑视觉表达而非音频表达[30]。我们假设手势动作也能表示情绪状态,例如,非常快速的手势动作可能代表强烈的愤怒或高兴状态。手势动作特征由四个标记(图3中的LH2、LH3、RH2和RH3)的速度及其在时间步上与前一时刻的差值构成。每个速度在三个维度上表示(即 x、y 和 z)。
其次,我们从每个话语中的所有模态依赖特征中计算了统计特征。这些统计量包括均值、方差、范围、最大值和最小值。所有特征均使用z‐归一化进行归一化处理。归一化的均值和标准差基于全部训练数据计算得出,并使用相同的均值和标准差值对训练数据集和测试数据集进行归一化。最终获得的面部表情特征、手势动作特征和音频特征分别为680、120和150维度,提取的特征总数为950维。
3.1.3 所提出模型的参数设置
我们的模型结构已在图2a中展示,并在第2.2.2节中进行了描述。每个模态网络包含三层,一个受限玻尔兹曼机将所有模态网络结合起来。对于面部表情网络,我们设置了可见单元、第一隐藏层和第二隐藏层的单元数分别设置为680、300和100。手势动作和音频网络的可见单元数分别设置为120和150。我们把手势动作和音频网络的第一隐藏层和第二隐藏层的单元数均设为100。最高层RBM的可见节点和隐藏节点数量分别为300和50。模型训练的参数 ϵw、 ϵa、 ϵb和 ϵz在高斯‐伯努利RBM中设为0.001,而在伯努利‐伯努利RBM中,除 ϵz外的所有参数均设为0.01。
3.2 实验一:通过自组织构建多模态信号的情绪表征
为了基于对他人情绪状态的估计来模仿他人的情感表达,从高维多模态信号中提取低维特征至关重要。我们假设每种模态信号都包含与情感相对应的独特特征,并且人类的情绪状态可以通过这些独特特征的组合来表示。为了检验受限玻尔兹曼机(RBM)从多模态信号中提取相关特征的能力,我们考察了模型中获得的情感表征。
首先,每个模态特定网络被单独训练。随后,它们的输出被连接起来作为关联受限玻尔兹曼机的输入数据,并对其进行训练。所有受限玻尔兹曼机(RBM)的最大训练步数为10,000。在完成所有受限玻尔兹曼机(RBM)的训练后,我们计算了关联受限玻尔兹曼机隐藏层中的激活通过使用训练数据集对受限玻尔兹曼机进行前向采样(图2a中的红色箭头),并执行主成分分析以在低维空间中可视化激活。
 标记的颜色和形状分别表示交互数据的情感状态;(b) 空间中的每个标记对应表达数据的人类。)
标记的颜色和形状分别表示交互数据的情感状态;(b) 空间中的每个标记对应表达数据的人类。)
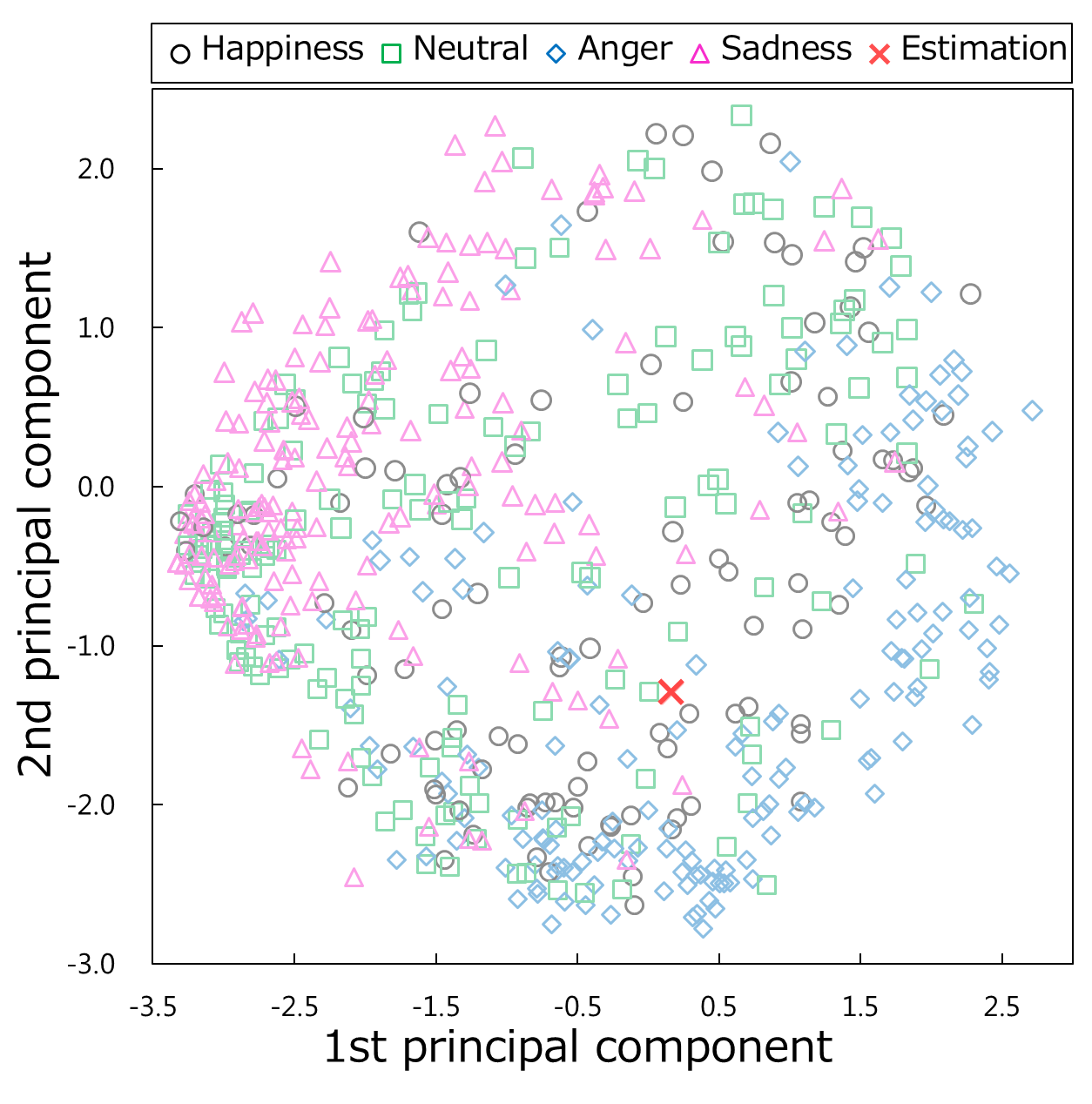
图4展示了(a)我们模型最高层的第一和第二主成分空间,以及(b)第一和第三主成分空间。各成分的贡献率分别为25.0%、13.2%和9.37%。图4a中标记的颜色和形状表示根据训练数据计算出的每次激活对应的情绪状态。需要注意的是,模型在训练过程中并未使用这些数据的情绪类别。各类情绪数据的分布存在相互重叠。特别是中性和快乐数据遍布整个主成分空间;然而,愤怒和悲伤数据在此空间中形成了相应的情绪聚类,且快乐数据的分布偏向于与愤怒相关的数据。我们确认了情绪表征的分布在从左上角(即悲伤,通常强度较低)到右下角(即愤怒,通常包含高强度特征)的方向上呈现出与情绪状态强度相关的渐变变化。在图4b中,颜色和形状对应于个体数据。该图表明,个人的表情在第三主成分上被明显区分开来。这一特征有助于在情绪估计中考虑社会特征(例如文化差异以及体现情绪表达的个性)。
这些结果表明,所提出的模型能够以无监督方式从高维多模态信号(共950维)中提取出多模态情感表达在最高层的低维表示(50维)。情绪表征的两个主要成分(即第一和第二主成分)显示,愤怒和悲伤表情的数据彼此集中并形成聚类。这两个聚类的分布代表了相关情绪强度的变化。此外,第三主成分代表了多模态表达的个性特征。所获得表征的这些特征有助于根据对其情感状态的估计来模仿伙伴的情感表达。
3.3 实验二:通过我们的模型将模仿表达与直接映射方法进行比较
在本实验中,我们研究了所提出的模型模仿他人情感表达的能力,并将其与直接映射系统进行了比较,该系统直接将他人的表情复制到机器人。本实验的动机是考察当同一人来自不同模态的表情存在冲突时,这种能力的表现。这两个系统之间的区别在于,所提出的模型通过估计他人的情感状态来生成自身的表达。
 图中,人类在交互过程中表达了愤怒的情感。注意,该模型并未学习人类的表情。)
图中,人类在交互过程中表达了愤怒的情感。注意,该模型并未学习人类的表情。)
我们的模型首先通过前向采样(图2a中的红色箭头),利用他人的多模态表达作为输入信号,在顶层估计他人的情绪状态。然后,模型通过后向采样(图2a中的绿色箭头)生成多模态信号,以模仿基于所估计情感的他人表达。由于多模态信号通过关联受限玻尔兹曼机的采样与其他模态相互作用,因此无法保证模型生成的多模态表达与相应的人类表达完全相同。然而,生成的多模态表达基于相同的emotion state,即由模型估计出的情绪状态,即使在人类表达不同时也如此。
情感在模态上存在不一致。相比之下,直接映射系统只是复制他人的多模态表达作为自身的表情。由于该系统对多模态信号进行特定操作,机器人在所有模态中的多模态表达始终与人类相同。
我们在此实验中使用人形机器人iCub来表达情感多模态信号。通过后向采样重构的多模态信号被转换为iCub的表达。在面部表情方面,iCub有两个部分用于表达情绪状态:眉毛和嘴巴。通过组合四种眉毛模式和五种嘴巴表情模式,可以表达20种不同的模式。每种表情模式均根据相应的特征值进行选择。由于iCub只能表达离散模式,因此面部特征通过阈值进行量化。例如,张嘴或闭嘴模式的选择依据是上唇中心标记(MOU3)与下唇中心标记(MOU7)之间的距离,而嘴部角度则由嘴角标记(MOU5)与脸颊相邻标记(LC1)之间的角度决定,如图3所示。对于手势动作和音频表达,我们为其准备了原型模式(例如说“hello”并以循环方式移动手),仅调节其参数以模仿他人。例如,我们使用听觉特征中的音高和强度的均值来调整iCub语音的韵律。iCub手势动作的速度则通过相应手势动作特征的平均速度进行调节。在使用我们模型的模仿实验中,iCub将通过后向采样生成的感觉特征作为自身的表达。另一方面,iCub使用提取的感觉特征将其他人的表情目录中的特征作为直接映射系统实验中的自身表情。
图5展示了使用测试数据集的实验结果的一个示例。图5a是来自IEMOCAP数据集的人类情感表达的截图。该话语在交互中的受试者表情在数据集中被标注为愤怒状态。然而,仅从这张图中识别出受试者的情绪状态为愤怒是困难的。如果只考虑视觉图像,由于其面部表情,该状态似乎更像是惊讶或快乐。图5b显示了直接映射系统的最终表达结果。iCub呈现出一张张开嘴巴的惊讶面孔,而不是愤怒的表情。由于直接映射方法无法考虑模态之间的一致性,因此iCub的表达与其实际情绪状态之间存在不匹配。相比之下,图5c展示了通过所提出的模型对他人情绪估计实现的模仿结果。在这张图中,尽管输入信号相同,iCub表现出与直接映射实验不同的面部表情。他人多模态表达在PC1‐2空间中的估计状态在图6中以十字标记表示。该图显示,通过综合考虑多模态表达,估计结果足够接近愤怒分布。这些结果表明,即使他人的表达在感觉信号之间存在不一致,所提出的模型也能够模仿与他人情绪状态相对应的多模态表达。
3.4 实验III:基于伙伴部分多模态信号的情绪估计中心理模拟能力的评估
我们进行了第三次实验,以检验我们的模型在仅通过部分观察他人多模态表达时进行模仿的心理模拟能力。实验设置和所用数据与之前实验相似;然而,输入信号缺少了部分模态信息。例如,由于机器人关注的是其他人或物体,因此无法感知同伴的面部表情和/或手势动作来进行情绪估计。我们假设模型未接收到缺失模态的任何信号,并将这些模态的信号设置为零向量0。

3.4.1 不通过心理模拟的情绪估计
我们首先比较了模型最高层在完整信号下的激活与在部分多模态表达下的激活,以检验每种模态信号对情感估计的影响。在本实验中,我们将基于前向采样所用的相同完整信号计算出的100个激活数据项的均值定义为真实值,因为激活有时会根据其概率发生变化。真实值与部分信号激活之间的距离被计算为估计的错误。我们从测试数据集中移除每种模态信号后输入到模型中。例如,面部‐手势条件表示模型接收来自数据集的面部表情和手势动作,而听觉信号条件表示模型仅接收音频特征。
图7显示了每种条件下的错误情况。由于各条件之间没有显著差异,我们讨论这些结果的趋势。双模态条件(即面部‐手势条件、手势‐音频条件和面部‐听觉条件)的错误少于单模态条件(即面部、手势和听觉条件)。在单模态条件下,音频信号的错误最少。随后,错误从面部条件到手势条件逐渐增加。这一结果表明,在本实验中,听觉信号包含与情感更相关的信息。从这些结果中我们注意到,手势信号并未直接对应情绪状态,因为它与交互情境相关(例如传递物体)。在IEMOCAP数据集中,一些交互模拟了办公室日常情景,这也是为什么它们在之前的研究中被省略的原因[19, 29]。面部信号也与情景相关,与手势信号相比,听觉信号的交互较少。嘴部运动受到讲话内容的强烈影响。在双模态条件下,手部‐听觉和面部‐听觉条件下的错误值相近,且小于面部‐手势条件的错误值。这些结果与先前的结果[29]并不矛盾。由于缺乏听觉信号导致估计噪声更大,因为面部和手势特征在情绪估计中具有较大的方差。这些结果表明,在这些设置下,听觉信号在情绪估计中的贡献优于其他模态。
3.4.2 基于心理模拟的情绪估计
接着,我们研究了所提出的模型中如何通过心理模拟更新估计。我们的模型首先通过前向采样对部分完成信号的情绪状态进行估计。然后,模型通过后向采样从第一次估计中重构缺失的信号,并在下一步估计中将重构的信号与观测信号结合使用。心理模拟的示例和机制已在第2.3节和算法1中描述。该模型重复前向‐后向采样序列20次(即,N= 20在算法1中),以基于自身经验更新对同伴情绪状态的估计信念。

图8显示了在每种条件下,通过心理模拟,真实值与相应输入信号生成的激活之间的距离均值的变化。如何在模型中采用心理模拟得到的更新估计是一个问题,因为模型并不知道估计的真实值。为此选择,我们采用了一种启发式方法。我们选取了在心理模拟过程中,在PC1‐2空间中初始点与最远点之间距离变化大于1.0的数据进行评估。我们假设人类在进行心理模拟时,若更新估计发生显著变化,也会采用该更新估计,因为他们认为更新后的估计相比之前包含了更高的信息增益。我们的启发式方法并不能保证一定比初始估计更优;然而,我们基于此方法对实验结果进行了评估。该方法的替代方案将在后续章节中讨论。
表1列出了初始估计与第20步之间的距离以及初始估计与真实值最近点之间的距离的平均变化率。比较两种模态条件下的详细情况
| 条件 | 面部‐手势 | 手势‐听觉 | 面部 | 听觉 |
|---|---|---|---|---|
| 步骤 20[%] | 53.9 | 66.8 | 48.0 | 1.13 |
| 最小值[%] | 57.7 | 76.1 | 48.6 | 33.6 |
表1 :真实值与心理模拟中第20个或最近点之间的距离变化率。
在手势‐音频条件下,变化率小于面部‐手势条件。在单模态条件下,从表1可以看出,面部条件下的心理模拟效应大于听觉条件下的效应。在面部条件下,模型应从面部特征重构手部和听觉特征。先前实验的结果(图7)显示,在单模态条件下,听觉特征在情绪状态估计中产生的错误较小;因此,由于重构的音频特征减少了估计差异,心理模拟的执行带来了更优的估计。相比之下,在听觉条件下,心理模拟的执行对信念更新没有显著影响,因为重建的面部和手部特征包含的错误大于音频特征(图7)。我们无法展示面部‐听觉条件和手势条件的结果,因为我们的方法未选择到相关数据;然而,可以认为在从手部特征重构手部及其他特征时,发生了与听觉条件相同的现象。
我们展示了在手势‐音频条件下通过心理模拟进行估计变化的一个示例。图9显示了通过心理模拟在20步内的估计轨迹。在心理模拟过程中,与真实值之间的距离变化(图9)是…


样本数据的原始情感标签为愤怒;然而,第一步中的估计结果(即不进行心理模拟时)远离真实值,属于中性分布。通过20次心理模拟后,估计结果更接近愤怒状态区域及其自身的真实值。

图11展示了通过心理模拟在每一步骤中重建的面部表情。它显示了对应于图9和图10的初始、第五、第七和第15步的表情。在此交互过程中,受试者表现出非常强烈的愤怒表情和大声说话;因此,他的嘴巴大部分是张开的(图11a)。我们的模型在第一步时根据音频和手势信号重构出一种看似轻微愤怒的表情,然后通过心理模拟,在第五步时模型重构出了愤怒的面部表情。通过后续步骤的额外的心理模拟,面部表情变成了张开嘴巴的愤怒表情,情绪估计结果也更接近真实值。在第15步时,嘴巴比第7步重建的结果张得更大,估计的表情也更接近真实值。这些结果表明,即使他人表情的部分信息缺失,我们的模型仍可通过基于心理模拟不断更新对他人的情绪估计,从而模仿他人的表情。
4 讨论
4.1 获取多模态表达的情绪表征
所提出的模型能够利用受限玻尔兹曼机(RBM)的能力,从多模态通用特征中提取一组特征。这与Lim的模型[12]使用特定特征的方法形成对比。已知人脑中的颞上沟(STS)——属于镜像神经元系统(MNS)的一个区域——负责特征选择和多模态整合以实现情绪分类[31–33]。我们在模型中并未考虑其确切的结构和机制;然而,我们的模型能够基于受限玻尔兹曼机(RBM)的能力再现类似的功能。
另一方面,尽管PC1‐2空间表示情感分布的渐变,但其中的情感类别之间并未相互区分。在一项心理学研究中,Russell[34]提出了情感的环形模型,该模型将情绪状态表示为二维空间,包含正/负轴和唤醒/睡眠轴。这种在低维空间中表示情感的方式不仅有助于人类情绪的分析,也有助于为HRI建模机器人的情绪状态。我们模型中的渐变与PC1‐2空间中情感的强度相关(见第3.2节和图4a)。我们的模型似乎以无监督方式在主成分空间中获得了Russell模型的唤醒/睡眠轴。为了获得Russell模型的另一轴——正/负轴,我们需要考虑交互中情绪效价的评估。我们之前的研究[35]表明,通过考虑基于交互中触觉刺激的情绪效价,所提出的模型能够获得一个特征空间,从而隔离类似Russell情感模型的情绪状态。该模型将情绪效价作为低阶情绪标签(即正、中性、负面)进行分类。在真实人机交互的训练过程中,将感官信号的信息与当前特征相结合,有助于我们的模型获得更清晰的多模态表达的情绪表征,从而提升估计和生成机制的性能。
4.2 我们模型中心理模拟机制的局限性
实验III的结果表明,心理模拟机制并不总是能够准确估计他人情绪。在该实验中,我们选取了在心理模拟过程中,初始估计与最远估计之间的距离在PC1‐2空间中变化大于1.0的数据进行分析。该方法不仅选择了接近真实值的移动,也包含了远离真实值的移动。这似乎是一种启发式算法;然而,当人类通过模拟使估计信念发生显著变化时,也会执行心理模拟。如果观察到的信号足以进行估计,人类则不会使用心理模拟。另一方面,信念的增强并不直接等同于准确估计,反而可能引发错误估计,例如偏见。
研究文章模型和人类都无法确定他人的真实情绪,因此在人与人或人机交互中并不存在真实的情绪真实值。这意味着模型需要另一个标准来评估心理模拟的必要性,而无需评估距离变化。我们计划使用激活的网络能量来判断是否接受模拟信号。如公式(4)或(10)所述,当激活状态接近训练后的状态时,网络能量会变小。该模型通过比较当前估计和通过心理模拟更新后的估计之间的能量来实现这一判断。然后,如果能量比当前值降低,则模型会接受新的估计。该规则对应于基于自身经验(例如偏见)的邻近性选择规则。通过这一机制改进心理模拟方法,可能使我们能够避免无效的采样,并加速信念更新。
5 结论
本文提出了一种统一模型,用于估计交互伙伴的情绪状态,并生成自身的情绪表达以回应伙伴。这些能力解决了以往情感模型面临的两个问题:1)获取多模态表达的情感表征,用于情绪估计与生成;2)通过心理模拟从模糊信号中更新对伙伴情绪的估计信念。所提出的模型由一种称为受限玻尔兹曼机的随机神经网络构成,受限玻尔兹曼机(RBM)的以下特性有助于我们应对上述两个问题。
第一个实验的结果表明,我们的模型通过自组织学习获得了多模态表达的低维情感表征,并且该情感表征使机器人能够根据他人的情绪状态来模仿其表达。在模仿实验中,与直接映射系统相比,我们的模型通过考虑每对模态信号之间的相互作用,生成了正确的表达,这些表达符合他人的情绪状态,而不论他人模态之间的情感是否一致。我们第三个实验的结果表明,我们的模型可以从交互伙伴的情绪状态中更新估计的信念,基于心理模拟机制的模糊表达。
我们得出结论,所提出的模型的能力使机器人能够基于对他人情绪状态的估计以及通过心理模拟进行重新估计来模仿他人的多模态表达,从而改善人机交互中的情感交流。

















 753
753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









