




论文地址:https://arxiv.org/abs/2202.07925
项目地址:GitHub - happyharrycn/actionformer_release: Code release for ActionFormer (ECCV 2022)
---------------------------------------------------------------------------------------------------------------------------------
动机:
基于自注意力机制的Transformer模型在图像分类和目标检测方面展示了令人印象深刻的成果,并且最近在视频理解方面也取得了成功。
提出:
ActionFormer——一种简单但功能强大的模型,用于单次识别时间上的动作并识别其类别,而无需使用动作提议或依赖预定义的锚窗口。ActionFormer结合了多尺度特征表示与局部自注意力,并使用轻量级解码器对每一时刻进行分类并估计相应的动作边界。

大致过程:
ActionFormer是一种单阶段、无锚的TAL模型,集成了局部自注意力来从输入视频中提取特征金字塔。输出金字塔中的每个位置代表视频中的一个时刻,并被视为一个动作候选。一个轻量级卷积解码器进一步应用于特征金字塔,以将这些候选分类为前景动作类别,并回归前景候选与其动作起始和结束之间的距离。结果可以轻松解码为带有标签和时间边界的动作。
贡献:
最早提出基于Transformer的单阶段无锚TAL模型的研究之一
开发TAL的Transformer模型的关键设计选择,并展示了一个效果出乎意料好的简单模型
在主要基准上实现了state-of-the-art结果,并提供了一个坚实的TAL基线
结果:
在THUMOS14、ActivityNet 1.3和EPIC-Kitchens 100数据集取得显著提升。
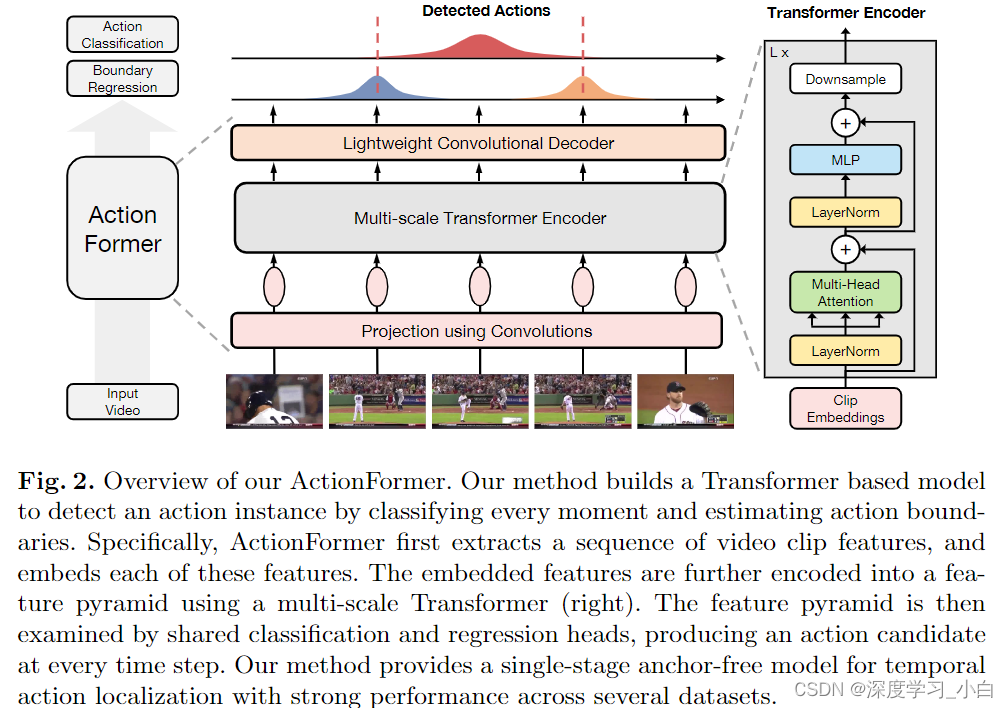
方法细节:
问题定义:
输入视频特征:,其中
,
是从3D卷积提取出的t时刻视频片段特征
目标:
预测动作标签
其中,为动作实例,N在不同视频中也不同;
:动作开始时间
:动作结束时间
:动作标签,
,C为预定类别
TAL任务: 具有挑战性的结构化输出预测问题。
动作定位的简单表示:
作者的方法建立在动作定位的无锚表示的基础上
关键思想:
将每个时刻分类为动作类别或背景
并进一步优化时间步与动作的起始和偏移的距离
将结构化输出预测问题转化为序列标签问题
其中,, t 时刻预测结果。
1)由C个值组成(C表示动作类别),每个值对应该类别的概率
2)表示t时刻,动作开始(结束)的偏移距离,若t时刻标签为背景,
无意义
Encode Videos with Transformer
编码器将输入视频
编码为多尺度特征表示
编码器 g :
(1) 一个使用卷积网络的投影函数,将每个特征嵌入到一个 D 维空间中
(2) 一个Transformer网络,将嵌入的特征映射到输出特征金字塔 Z。
投影:
投影 E 是一个浅层卷积网络,以ReLU作为激活函数
其中, 是
的嵌入特征。
在Transformer网络之前添加卷积有助于更好地结合时间序列数据的局部上下文,并稳定视觉Transformer的训练,并且不再按照Transformer的形式添加位置编码,这样会降低模型性能。
局部自注意力:
Transformer的核心是自注意力,将作为输入,具有T 个时间步骤和 D 维特征。 自注意力计算特征的加权平均,权重与输入特征对之间的相似度得分成正比
自注意力的输出为:
其中, ,softmax按行执行。多头自注意(MSA)进一步并行地增加了几个自注意操作
MSA的主要优势是能够整合整个序列的时间上下文,但这种优势是以计算成本为代价的,在内存和时间上的复杂度为,这对长视频来说效率极低。
本文设计:
通过限制注意力在一个局部窗口内来适应的局部自注意力,因为超过一定范围的时间上下文对动作定位帮助不大。
局部自注意力与多尺度特征表示结合使用,在每个金字塔层级上使用相同的窗口大小。通过这种设计,在一个下采样的特征图(16x)上使用一个小窗口大小(19)将覆盖一个大的时间范围(304)。
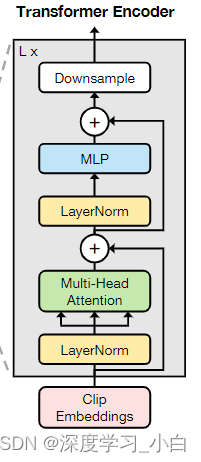
Multiscale Transformer
Transformer有 L 个Transformer层,每层由交替的局部多头自注意力(MSA)和MLP块组成,在每个MSA或MLP块之前应用LayerNorm(LN),在每个块之后添加残差连接。MLP使用GELU激活函数。为了捕捉不同时间尺度的动作,可以选择性地附加一个下采样操作符↓(·)
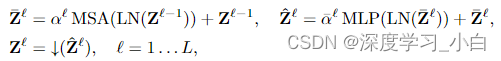
是下采样比率。
和
是每通道可学习的缩放因子
下采样操作符 ↓ 使用一个跨步的深度卷积1D卷积实现,因为它效率很高。作者为模型使用了2倍下采样。
Decoding Actions in Time
使用编码器 g 的特征金字塔 Z 解码为序列标签
解码器 h 是一个轻量级的卷积网络,具有分类头和回归头.
Classification Head(预测动作标签)
给定特征金字塔 Z,我们的分类头会检查金字塔上所有 L 层的每个时刻 t,并预测每个时刻 t 的动作概率 。
组成:
分类网络使用 3 层 1D 卷积实现,卷积核大小为 3,前两层采用层归一化和 ReLU 激活函数。每个输出维度都附加一个 sigmoid 函数来预测 C 个动作类别的概率。该网络附加在每个金字塔层上,并且其参数在所有层之间共享。
Regression Head(预测动作开始和结束位置)
与分类头类似,回归头会检查金字塔上所有 L 层的每个时刻 t,但仅在当前时间步 t 位于动作中时,预测到动作开始和结束的距离 。每个金字塔层都预先指定了一个输出回归范围。
组成:
与分类头相似,同样使用 1D 卷积网络实现,只是最后附加了一个 ReLU 用于距离估计。
ActionFormer: Model Design
ActionFormer 概念上非常简单:
特征金字塔 Z 上的每个特征都输出一个动作评分 和相应的时间边界
,这些结果随后被用来解码一个动作候选。
Design of the Feature Pyramid
关键组件是时间特征金字塔 的设计。
- 金字塔中的层数;
- 连续特征图之间的下采样比率;
- 每个金字塔层的输出回归范围。
通过对特征图使用 2 倍下采样并相应地将输出回归范围大致扩大 2 倍来简化我们的设计选择。
Loss Function
模型在每个时刻 t 输出 ,包括动作类别的概率
和到动作边界的距离
。损失函数同样遵循简约设计,仅包含两个项:
:用于 C 类二元分类的 Focal Loss;
:用于距离回归的 DIoU Loss。
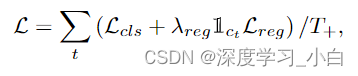
其中,为阳性样本总数。
是指示函数,表示时间步长t是否在动作范围内,即正样本。
损失函数应用于输出金字塔的所有层,并在训练期间对所有视频样本进行平均。
是平衡分类损失和回归损失的系数。默认
.
值得注意的是:
-
-
Center Sampling
在确定正样本时,只有在动作中心周围的区间内的时间步才被认为是正样本,其中区间的持续时间与当前金字塔层 的特征步幅成正比。
详细设计:
给定一个以 c 为中心的动作,在金字塔层 上,任意时间步
被视为正样本,其中
。中心采样不会影响模型推理,但鼓励在动作中心周围获得更高的分数。
Implementation Details
Training
- 使用 Adam 优化器并进行预热训练。预热阶段对模型收敛和良好性能至关重要。
- 在使用可变长度输入进行训练时,固定最大输入序列长度,按照需要填充或裁剪输入序列,并为模型中的操作添加适当的掩码。改变最大输入序列长度对性能影响很小
Inference
- 将完整序列输入模型,因为模型中不使用位置嵌入
- 模型接受输入视频 X,并在所有金字塔层上的每个时间步 t 输出
。每个时间步 t 进一步解码一个动作实例
。
和
分别是动作的开始和结束时间,
是动作的置信度得分。通过 Soft-NMS 处理结果动作候选,以移除高度重叠的实例,生成最终的动作输出。
Network Architecture
使用了 2 个卷积层进行投影,7 个 Transformer 块作为编码器(全部使用局部注意力,最后 5 个块进行 2 倍下采样),并使用独立的分类和回归头作为解码器。每个金字塔层的回归范围通过特征步幅进行归一化

















 3572
3572





 到【灌水乐园】发言
到【灌水乐园】发言







