




论文地址:https://arxiv.org/abs/2305.04926
项目地址:https://github.com/amyxlase/relpose-plus-plus
---------------------------------------------------------------------------------------------------------------------------------
任务:
从稀疏视图图像集(2-8张图像)估计6D相机姿势的任务
挑战:
这项任务是几乎所有当代(神经)重建算法的重要预处理阶段,但在稀疏视图的情况下仍然具有挑战性,特别是对于具有视觉对称性和无纹理表面的对象。
动机:
虽然几种稀疏视图重建方法已经显示出有希望的结果,但它们严重依赖于已知的(精确或近似)6D相机姿势来进行这种3D推理,并回避了如何首先获得这些6D姿势的问题。
提出:
开发了一个系统,可以帮助弥合这一差距,并在给定通用对象(例如 Fetch 机器人)的稀疏图像集的情况下稳健地推断(粗略)6D 姿势,即RelPose++,该方法建立在RelPose基础之上。
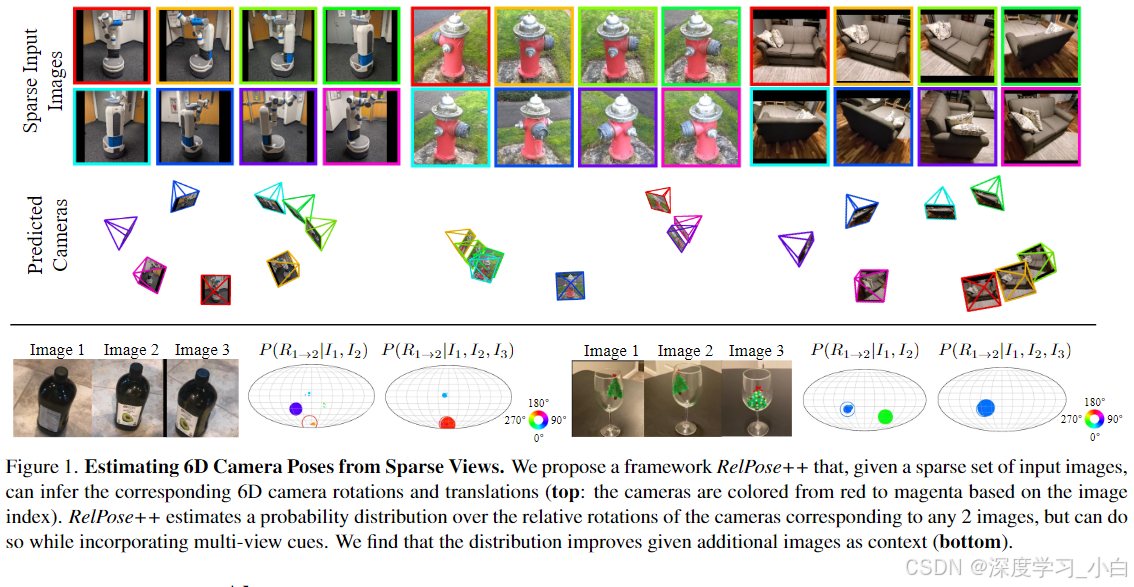
大致过程:
首先使用ResNet 50提取全局图像特征。作者对图像索引进行位置编码,并将边界框参数连接为Transformer的输入。
在对所有图像特征进行联合处理后,分别对旋转和平移进行估计。
为了处理姿态的模糊性,作者使用基于能量的公式(RelPose)对旋转分布进行建模。因为在最接近所有光轴的唯一世界坐标上预测原点,所以可以直接从学习到的特征中回归相机平移。
贡献:
本文基于RelPose框架改造,在此基础上添加了两个关键扩展:
首先,使用注意力transformer层来联合处理多个图像,因为对象的额外视图可能会解决任何给定图像对中的对称性歧义(例如,一个杯子的把手在第三个视图中变得可见)。
其次,通过定义一个适当的坐标系统来扩展这个网络,以报告相机的平移,从而解耦旋转估计中的歧义与平移预测。
结果:
1. 在CO3D 数据集的 41 个类别进行训练,并且能够仅从几张图像中恢复对象的 6D 相机姿势
2. 评估了可见类别、不可见类别甚至新数据集(以零样本方式),将旋转预测提高了 10% 以上现有技术。
3. 通过测量预测相机中心的准确性来评估完整的6D相机姿势(同时考虑相似性变换模糊性),并展示了我们提出的坐标系的好处。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9419
9419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









