




论文地址:https://arxiv.org/pdf/2211.09788
---------------------------------------------------------------------------------------------------------------------------------
动机和背景:
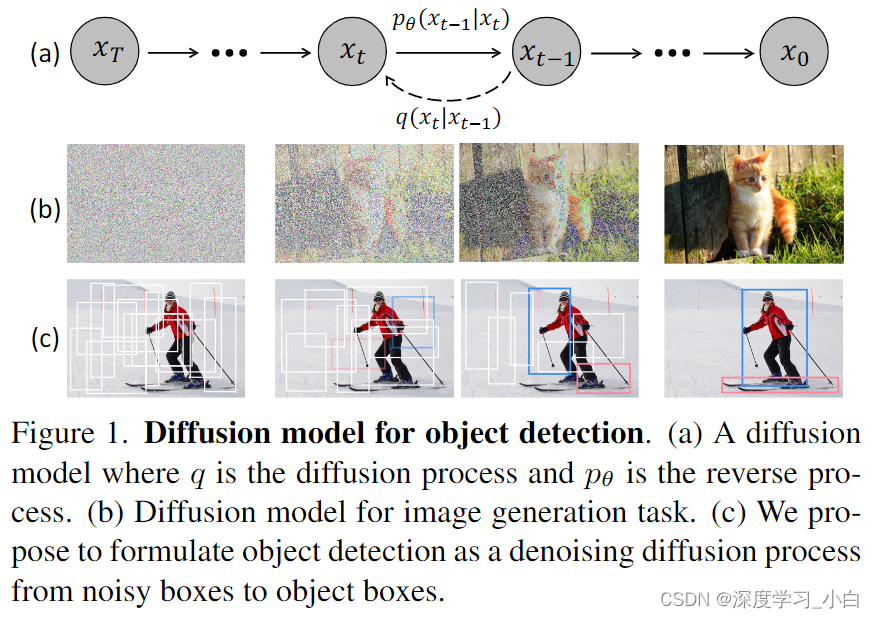
动机展示如图。作者认为噪声到框的范式哲学类似于去噪扩散模型中的噪声到图像过程,这类模型通过学习去噪模型逐渐去除图像中的噪声来生成图像。 扩散模型在许多生成任务中取得了巨大成功,开始在感知任务如图像分割中进行探索。然而,据作者所知,尚无成功将其应用于目标检测的先例。
Is there a simpler approach that does not even need the surrogate of learnable queries?
作者提出了DiffusionDet,这是一种新框架,它将目标检测表述为从噪声框到目标框的去噪扩散过程。
大致过程:
从纯随机框开始,这些框不包含需要在训练阶段优化的可学习参数。作者期望逐渐细化这些框的位置和大小,直到它们完美覆盖目标物体。 这种噪声到目标框的方法既不需要启发式的目标先验,也不需要可学习的查询,进一步简化了目标候选框,并推动了检测流程的发展。
方法细节:
Preliminaries:
学习目标:
&nbs
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4371
4371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









