 Mamba模型详解
Mamba模型详解





问题
Transformer模型基于矩阵乘法,注意力机制中Q、K、V(N×d)会进行大量运算。
如:使用Q、K运算得到score的过程中,将Q每一行与K每一列进行运算,需要N^2次点积,每次点积包含d次乘法。即最终的复杂度为O()。考虑到序列长度(L)、batch大小(B)、多层Transformer块的堆叠(M),计算量为
,参考。
RNN存在梯度消失的问题,且训练时间长。
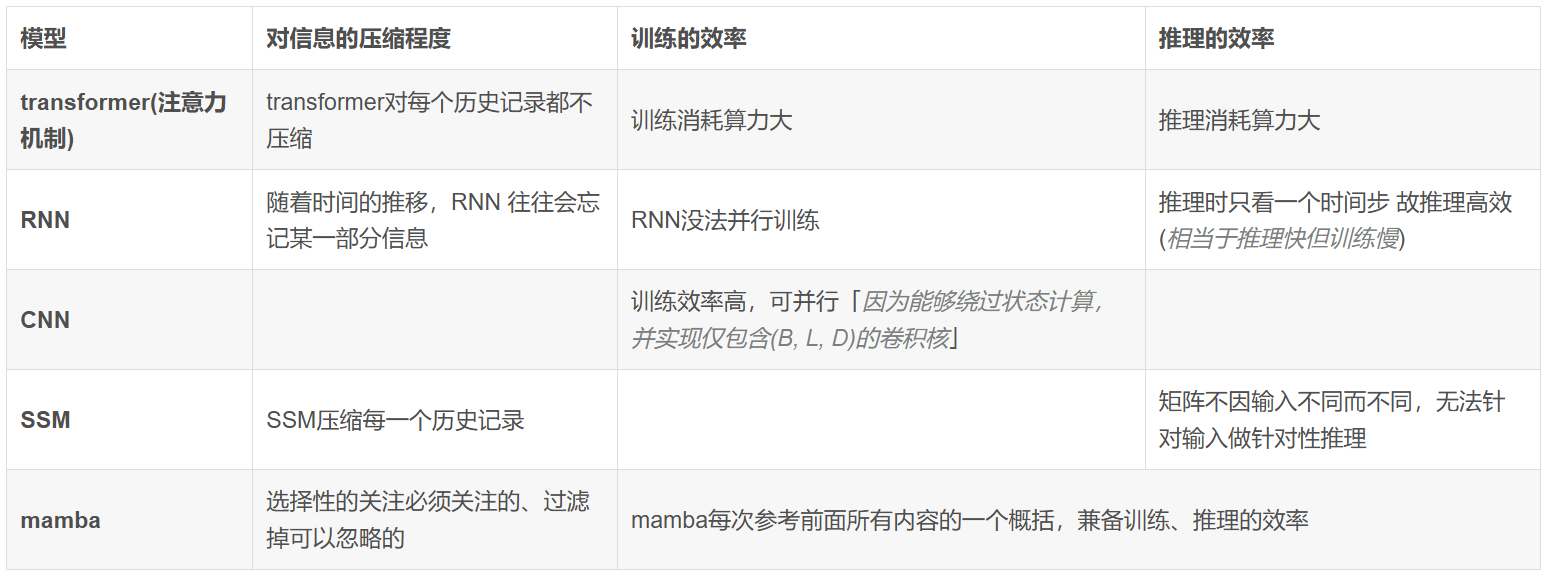
状态空间模型
Mamba中的状态空间模型(SSM)的灵感来源于传统的状态空间模型,公式描述如下:
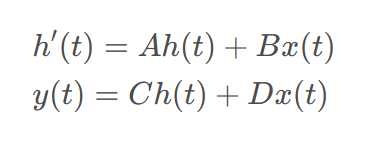
其中,h ( t ) h(t)h(t)是当前的状态量,A AA
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1722
1722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









