



 注意力机制借鉴了人类视觉注意力,用于神经网络中资源分配,解决信息超载问题。软性注意力通过加权平均选择信息,而硬性注意力则进行选择或随机采样。点积模型在计算效率上有优势。在Encoder-Decoder框架中,注意力机制常用于机器翻译等任务。
注意力机制借鉴了人类视觉注意力,用于神经网络中资源分配,解决信息超载问题。软性注意力通过加权平均选择信息,而硬性注意力则进行选择或随机采样。点积模型在计算效率上有优势。在Encoder-Decoder框架中,注意力机制常用于机器翻译等任务。
一、注意力机制的介绍及用途
注意力机制对人类的视觉注意力机制进行了借鉴
神经网络中的注意力机制(Attention Mechanism)是在计算能力有限的情况下,将计算资源分配给更重要的任务(非常适用于嵌入式应用场景,如解决NILM问题时),同时解决信息超载问题的一种资源分配方案
软性注意力(Soft Attention)机制是指在选择信息的时候,不是从N个信息中只选择1个,而是计算N个输入信息的加权平均,再输入到神经网络中计算。
硬性注意力(Hard Attention)是指选择输入序列某一个位置上的信息,比如随机选择一个信息或者选择概率最高的信息。
二、软性注意力机制
对于输入的X=,为了节省资源,只从其中选择部分相关的信息进行计算。
注意力机制的计算可以分为两步:
一、在所有输入信息上计算注意力分布:
任务为从N个输入向量中选择出与某一特定任务相关的信息。此处引入一个和任务相关的表示,称为查询向量( Query)。而后通过一个打分函数来计算每个输入向量和查询向量之间的相关性。使用注意力变量来表示被选变量的索引位置。
计算给定q和X下的注意力分布(Attention Distribution) :
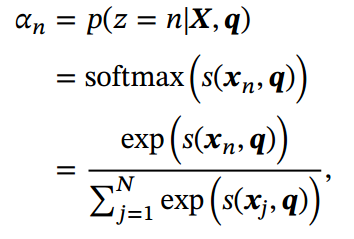
其中𝑠(𝒙, 𝒒) 为注意力打分函数,可以使用以下几种方式来计算:
加性模型:
![]()
点积模型:
![]()
缩放点积模型:
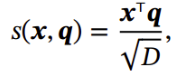
双线性模型:
![]()
点积模型在实现上可以更好地利用矩阵乘积, 从而计算效率更高
二、根据注意力分布来计算输入信息的加权平均:
使用选择机制对输入信息进行汇总:
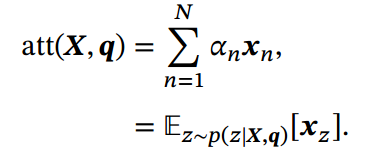
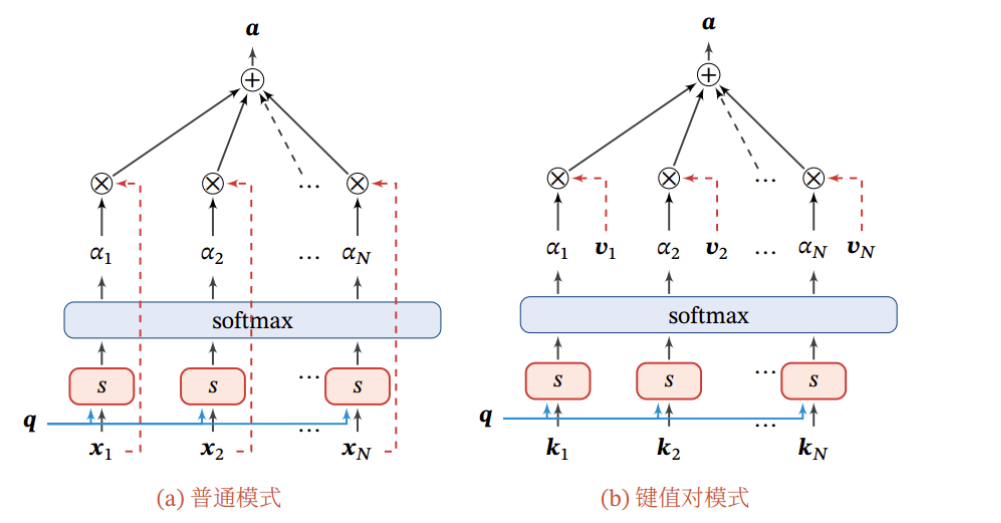
注意力机制可以单独使用, 但更多地用作神经网络中的一个组件
三、硬性注意力
硬性注意力有两种实现方式:
(1)选取最高概率的一个输入向量, 即
![]()
其中为概率最大的输入向量的下标, 即
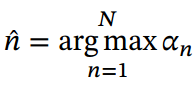
(2)通过在注意力分布式上随机采样的方式实现.
硬性注意力的一个缺点是基于最大采样或随机采样的方式来选择信息,使得最终的损失函数与注意力分布之间的函数关系不可导,无法使用反向传播算法进行训练.因此,硬性注意力通常需要使用强化学习来进行训练.为了使用反向传播算法 一般使用软性注意力来代替硬性注意力.
四、注意力机制的变体
多头注意力、结构化注意力、指针网络
四、软性注意力机制与Encoder-Decoder框架(常用于机器翻译、文本处理、语言识别和图像处理等领域)
以RNN作为编码器和解码器的Encoder-Decoder框架也叫做异步的序列到序列(seq 2 seq)模型
目前大多数注意力模型附着在Encoder-Decoder框架下。当然,其实注意力模型可以看作一种通用的思想,本身并不依赖于特定框架
加入注意力机制的RNN Encoder-Decoder(异步的seq 2 seq)
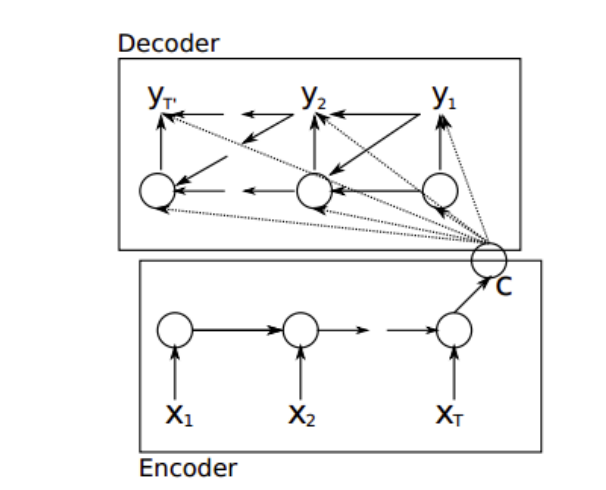
还未加入注意力机制的RNN Encoder-Decoder:
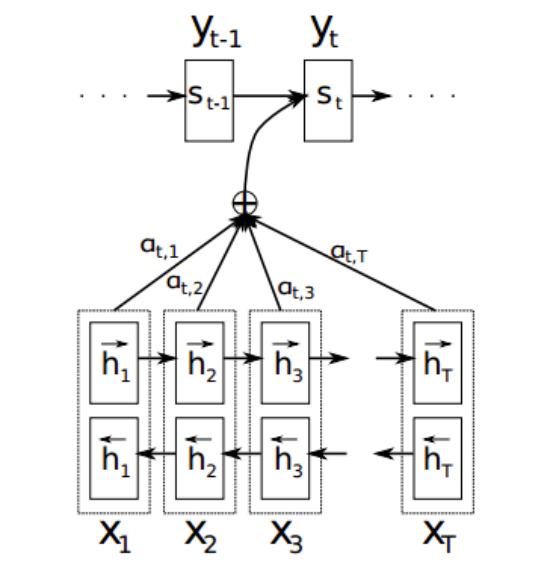
加入后的:
参考:


















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









