







 超级会员免费看
超级会员免费看
目录
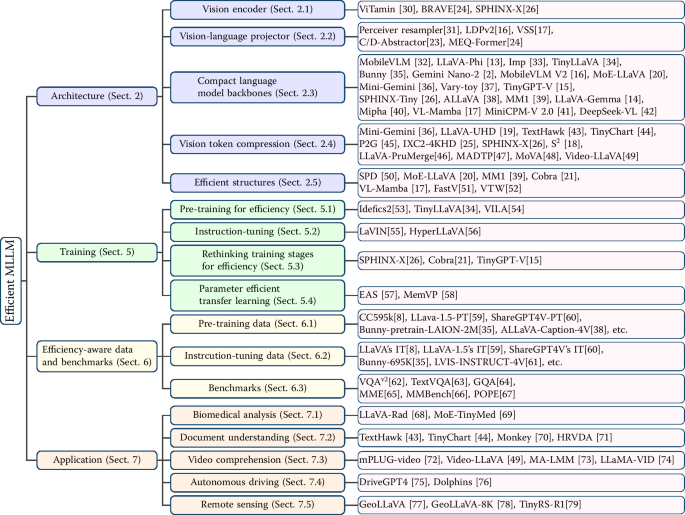
4.4 多尺度重采样:把“局部细节”显式组织进少量 token
5.1 注意力的瓶颈不止是 FLOPs:KV cache 与带宽才是推理痛点
5.2 共享式注意力与 GQA:用更少的 KV 头支撑更多的 Query 头
5.5 Transformer 替代结构:RWKV 与状态空间模型的近线性长序列处理
8.1 文档与图表理解:细粒度视觉与 token 预算矛盾最尖锐
本文内容来源于综述文献Jin, Y., Li, J., Gu, T. et al. Efficient multimodal large language models: a survey. Vis. Intell. 3, 27 (2025). https://doi.org/10.1007/s44267-025-00099-6,进行了系统整理的总结,方便中文母语读者阅读。
1 引言
多模态大语言模型把“看见的内容”和“要说的话”组织到同一套序列建模体系里:图像不再只是分类或检索的对象,而是被编码成一串可被语言模型处理的“视觉 token”;语言不再只是描述的载体,而是承担推理、规划与对话组织的中心计算图。这样的统一带来了能力跃迁,同时也把计算成本推到了一个更尖锐的位置:视觉 token 的数量随分辨率和帧数增长,而语言侧自注意力的主要开销与序列长度强相关;二者相乘,使得“强能力”与“可部署”之间出现了非常具体的张力。所谓“高效”,并不只是把参数做小这么简单,它更像是一套关于信息瓶颈、表示对齐、token 预算、训练配方与推理路径的系统工程:该在哪个模块丢弃冗余、该在何处保留信息、该如何用结构化方式让算力花在最关键的 token 上。
在实践中,效率问题往往首先暴露在视觉侧:同一张图像从 224×224 提升到 1024×1024,若仍使用等间隔 patch 切分,token 数会呈平方级增加;而对语言模型来说,自注意力在训练阶段存在典型的二次复杂度项,推理阶段又要长期维护 KV cache 的显存与带宽压力。于是“把图像做成 token 再喂给语言模型”这条主干路径,天然要求我们在架构上做出更精细的分解与重组:视觉编码器能否更轻、更强、更适配高分辨率;连接器是否可以在不破坏对齐的前提下压缩 token;语言模型能否在更小的参数规模里保持足够的推理与跟随能力;训练阶段如何通过冻结/解冻策略与数据配方降低成本;推理时又如何通过跳算、剪枝、投机解码等方式把延迟压下来。
2 理论知识与技术基础
2.1 多模态表示的“鸿沟”与对齐目标
多模态学习的核心困难不是“看见”与“说出”本身,而是两种模态在统计结构与表达维度上的巨大差异:图像是连续空间信号,局部相关强、全局语义弱;文本是离散符号序列,组合结构强、局部纹理弱。把它们放进同一套语言建模框架,必须先解决一个“接口问题”:视觉特征需要被映射到语言模型可接受的隐藏空间,并在语义上与文本 token 的分布对齐。连接器(projector/adapter/resampler)在这里承担了“桥”的作用,它既是维度变换器,也是信息瓶颈控制器:维度变换保证形状可兼容,信息瓶颈控制 token 数量与可被语言模型吸收的有效信息量。
对齐的目标可以理解为一种条件建模:在给定视觉内容的条件下,模型应输出与图像一致、可执行、可推理的文本。为了让这个条件建模稳定成立,训练配方通常会把“视觉对齐”与“指令跟随”分成阶段,分别控制可训练参数的范围与数据的任务形态:先用图文对或交错图文数据让接口学会把视觉信息以语言模型能理解的方式表达出来,再用指令数据把这种表达嵌入对话结构,让模型在多轮上下文里学会“按指令做事”。这种分阶段策略的理论动机在于:如果在早期就让全部模块大幅更新,容易破坏语言模型已有的语义组织能力;而如果永远只训练连接器,又可能让视觉信息只能以很弱的方式进入语言模型,导致细粒度识别与长链推理不稳定。
2.2 Transformer 自注意力机制与复杂度来源
语言侧计算的主心骨通常仍是 Transformer。其关键算子是自注意力:每个 token 通过与其他 token 的相似性权重来汇聚信息。经典形式可以写成:
$$
\mathrm{Attention}(Q,K,V)=\mathrm{softmax}\left(\frac{QK^\top}{\sqrt{d}}\right)V
$$
其中 Q、K、V 分别来自输入隐藏状态的线性变换;d 是每个 head 的特征维度;softmax 产生归一化权重。这个式子在训练时的主要代价来自的矩阵乘:序列长度为 n 时,时间复杂度与显存读写都与
强相关;在推理时虽然可以缓存历史 token 的 K/V,把每一步的计算降到与当前步线性相关,但 KV cache 会随着上下文长度线性增长,并且 decode 阶段对内存带宽极敏感,因此“长上下文 + 多模态长 token”会把推理成本推高。正因为如此,很多效率改造并不是为了改变 Transformer 的表达能力,而是为了减少 n、减少 KV 头数、或让注意力在结构上更稀疏。
2.3 视觉编码器:从像素到视觉 token 的离散化
视觉侧通常使用 ViT 或 CNN/ConvNeXt 等骨干把图像变成 token 序列。以 ViT 为代表的做法是将图像切成固定大小的 patch,并通过线性投影得到 patch embedding;在 patch 数量上,分辨率越高、patch 越小,token 越多。对多模态模型而言,视觉编码器输出的 token 不是最终任务的 logits,而是将被“当作语言模型输入的一部分”来使用,因此它的输出需要满足两个性质:一是语义可被语言模型吸收(对齐性),二是 token 预算可控(效率性)。高分辨率任务(文档、图表、OCR)之所以难,不是因为模型不会看,而是因为要“看清细字”就得提升分辨率,而提升分辨率会把 token 数暴涨,最终把语言侧推理拖垮。
2.4 连接器:投影层、重采样器与信息瓶颈
连接器的本质是把视觉编码器输出的向量序列映射到语言模型隐藏空间,并在需要时压缩序列长度。最朴素的连接器是线性层或小 MLP,它们在参数上很轻,但对“视觉 token 太长”这一结构性问题帮助有限;更强的连接器会引入查询 token、跨注意力或重采样机制,使输出 token 数可以固定为较小常数,同时尽量保留全图与局部细节的关键线索。连接器既可以被理解为“模态接口”,也可以被理解为“可学习的压缩器”:它决定了视觉信息以何种粒度注入语言模型,以及语言模型需要为视觉信息分配多少上下文预算。
2.5 自回归生成与条件概率分解
多模态对话常用自回归训练目标:把“问题/指令 + 图像 token + 历史回答”拼成一个序列,让模型逐 token 预测后续输出。其理论基础是对条件概率的链式分解:
$$
p(Y_a \mid H_v, H_q)=\prod_{i=1}^{L}p\left(y_i \mid H_v, H_q, y_{<i}\right)
$$
其中 表示注入后的视觉表示,$H_q$ 表示问题/指令表示,
是回答序列,
是已生成的前缀。这个式子强调了一个事实:视觉信息并不是一次性“写入”就结束,而是在整个生成过程中持续作为条件影响每个 token 的分布;因此如果视觉注入过弱,模型在生成中后期更容易“忘图”并出现幻觉;如果视觉 token 太多,模型每一步都要为这些条件付出带宽与注意力计算成本。
2.6 效率度量:参数、token、FLOPs、显存与延迟
讨论效率时必须把“训练效率”和“推理效率”区分开。训练阶段,成本主要由参数更新范围(需要反传的模块)、batch size、序列长度(文本 token + 视觉 token)和优化器状态决定;推理阶段,成本更容易被 token 数和 KV cache 支配,尤其是长上下文对话与高分辨率视觉输入。很多看似“只改一点结构”的方法,本质是在改变 token 预算分配:要么减少视觉 token(压缩/剪枝/重采样),要么减少语言侧 token 的注意力开销(GQA/MQA/近似注意力/跳算),要么让更大的容量以稀疏方式激活(MoE),要么用状态空间模型等结构把长序列处理从“二次相关”拉向“近线性相关”。这些机制共同构成了高效多模态建模的理论地基。
3 高效多模态模型的整体框架结构
3.1 三段式骨架:视觉编码、跨模态连接、语言推理
一种非常稳健的理解方式,是把高效多模态模型看成三段式链路:视觉编码器 g 把原始图像压缩为视觉特征序列,连接器 P 把视觉特征映射到语言隐藏空间并可选地压缩 token,语言模型再在自回归范式下完成对话组织与推理。用最抽象的形式可以写成:
$$
Z_v = g(X_v)
$$
其中是输入图像,
是视觉编码器,
是视觉 token/patch 特征序列。随后通过连接器:
$$
H_v = P(Z_v)
$$
其中是投影器/连接器,
是与语言模型对齐后的视觉表示。最后,语言模型把
与文本指令/问题表示
结合,在自回归分解下生成回答(见上一章的条件概率公式)。这三步看似简单,但几乎所有效率策略都可以定位到其中一段:要么让 g 更轻、更高效地处理高分辨率;要么让 P 更强地压缩并保留信息;要么让语言模型在更小规模或更低计算下仍保持推理能力。
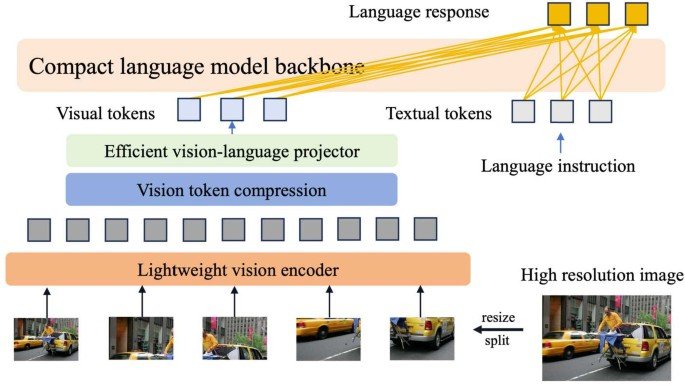
3.2 视觉编码器的多样化:从通用 CLIP 到更强表征
视觉编码器常见选择包括 CLIP、SigLIP、DINOv2、EVA、以及基于 ConvNeXt 的 CLIP 变体等。对高效多模态模型来说,这些选择不仅决定“看得准不准”,更决定“看得贵不贵”:同样的输入分辨率下,不同骨干的吞吐、显存、以及输出 token 的可压缩性会不同;同样的骨干,在更高分辨率下 token 数与注意力计算都更容易成为瓶颈,因此很多方法会将“更强表征”与“更少 token”绑在一起设计。实践上,经常看到的策略是用较强的视觉骨干保证语义质量,同时在连接器阶段进行重采样,以避免把全部 patch token 原封不动送入语言模型。
3.3 连接器设计:既是“桥”,也是“阀门”
连接器最重要的抽象是“阀门”:它控制视觉信息进入语言模型的带宽。线性投影或两层 MLP 是最轻量的阀门,优点是训练稳定、参数少;缺点是对 token 数不敏感,遇到高分辨率容易失控。更“结构化”的阀门会引入局部性增强或重采样机制,使得在不改变语言模型的情况下,视觉 token 可以被压缩到固定长度或接近固定长度,同时保留细节线索。这类结构通常会显著提升高分辨率任务的可用性,因为它把视觉侧“分辨率提升带来的 token 爆炸”转化为连接器内部的局部计算,而不是让语言模型承担全部代价。
3.4 小语言模型:能力边界与“配方”重要性
语言模型通常占据参数量的大头,因此“用更小的语言模型做多模态”天然是效率路线之一。这里的关键并不只是选一个参数更小的骨干,而是要理解“小模型的能力边界从哪里来”:其一,小模型对高质量指令数据更敏感,数据噪声与任务覆盖的缺陷更容易反映到行为上;其二,小模型上下文容量与长链推理能力有限,视觉 token 如果过长会更快压垮它;其三,小模型更依赖连接器把视觉信息组织成“语言模型能用”的形态,否则会出现“看见了但说不清”的现象。正因为如此,常见路线是“小语言模型 + 强视觉表征 + 强连接器 + 精心设计的数据配方”,而不是单纯缩小参数。
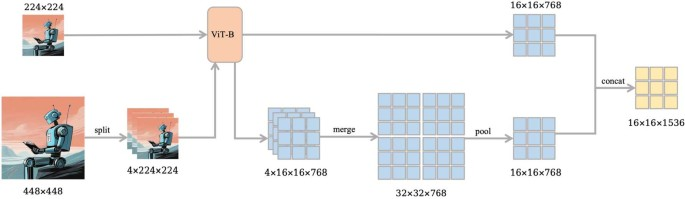
3.5 表格:常见高效多模态模型组件配置对照
下表把若干代表性高效多模态模型的视觉编码器、连接器、语言模型与输入尺寸做了对照,便于从“组件组合”的角度理解效率路线究竟改了哪里。
| 高效多模态模型 | 视觉编码器 | 连接器/投影器 | 语言模型(SLM) | 语言模型参数量 | 输入图像尺寸 |
|---|---|---|---|---|---|
| MobileVLM | CLIP ViT-L/14 | 2-Layers MLP | MobileLLaMA | 2.7B | 224×224 |
| LLaVA-Phi | CLIP ViT-L/14 | Linear | Phi-2 | 2.7B | 336×336 |
| Imp-v1 | SigLIP | Linear | MobileLLaMA | 2.7B | 224×224 |
| TinyLLaVA | CLIP ViT-L/14 | Linear | TinyLLaMA | 1.1B | 336×336 |
| Bunny | SigLIP | MLP | StableLM-2-1.6B | 1.6B | 384×384 |
| MobileVLM-v2 | SigLIP | LDPv2 | MobileLLaMA | 2.7B | 384×384 |
| MoE-LLaVA | - | - | Vicuna | 7B | 336×336 |
| Cobra | DINOv2 | - | Mamba-2.8b-Zephyr | 2.8B | 224×224 |
| Mini-Gemini | SigLIP | Conv+Linear | Gemma | 2B | 384×384 |
| Vary-toy | CLIP ViT-L/14 | Linear | Qwen | 1.8B | 1024×1024 |
| TinyGPT-V | EVA | Q-Former | Phi-2 | 2.7B | 336×336 |
| SPHINX-Tiny | CLIP-ConvNeXt | Linear | TinyLLaMA | 1.1B | 224×224 |
| ALLaVA-Longer | CLIP ViT-L/14 | - | Phi-2 | 2.7B | 336×336 |
| MM1 | SigLIP | Perceiver Resampler | - | 3B | 224×224 |
| LLaVA-Gemma | SigLIP-L | C-Abstractor | Gemma | 2B | 224×224 |
| Mipha | SigLIP | - | Phi-2 | 2.7B | 336×336 |
| VL-Mamba | SigLIP | - | VSS-L2 | 2.8B | 224×224 |
| MiniCPM-V 2.0 | SigLIP | Resampler | MiniCPM | 2.4B | 448×448 |
| DeepSeek-VL | SigLIP-L | - | DeepSeek-LLM | 1.3B | 384×384 |
| KarmaVLM | SigLIP | - | Qwen1.5 | 0.5B | 224×224 |
| moondream2 | SigLIP | - | Phi-1.5 | 1.3B | 384×384 |
| Bunny-v1.1-4B | SigLIP | - | Phi-3-Mini-4K | 3.8B | 384×384 |
| S-Wrapper | CLIP ViT-H/14 | S-Wrapper | Phi-3-mini-4K | 3.8B | 336×336 |
4 视觉侧效率:从高分辨率到视觉 token 压缩
4.1 高分辨率为何天然昂贵:token 数的平方律
视觉 token 的“爆炸”来自一个极朴素的事实:假设 patch 大小固定为 p×p,图像尺寸为 H×W,那么 token 数约为 (H/p)·(W/p),对分辨率是二次关系。更麻烦的是,这些 token 被送入语言模型后,又会与文本 token 混在同一序列里参与注意力计算:训练时有 $O(n^2)$ 的代价,推理时 KV cache 与带宽压力随 n 线性增长。也就是说,高分辨率在视觉侧造成 token 增长,在语言侧放大注意力成本,两者叠加使得“看清楚文档细节”成为多模态模型最先碰到的硬瓶颈。
在这种背景下,视觉侧效率的理论目标就不再是“更小的视觉骨干”这么单一,而是同时追求三个方向的平衡:第一,视觉骨干的表示要足够强,否则压缩后信息不足会导致回答不稳定;第二,视觉 token 必须被压到可控规模,否则语言侧成本会失控;第三,压缩过程要尽量结构化,避免把细粒度信息随机丢掉,尤其是 OCR、图表和局部细节推理。于是“多视角输入”“动态 token 剪枝”“多尺度重采样”“视觉专家路由”等方法,本质上都是在构造一个更合理的视觉信息压缩算子。
4.2 多视角输入:用多张小图逼近一张大图
多视角的思想是把一张高分辨率图拆解为“全局视图 + 若干局部视图”,让模型既能获得全局语义,也能在需要时看清局部细节。这样做的好处是:每张输入图的 token 数较小,语言模型的上下文负担更可控;而局部视图只在必要时引入,从而把 token 预算集中在“真正需要看细节”的区域。这条路线在文档、海报、屏幕截图等任务中尤其自然,因为这些任务的关键信息常常集中在局部文本或结构块里,强行把整张大图按 patch 全喂进去属于典型的算力浪费。
4.3 token 级处理:合并、剪枝与动态选择
当视觉 token 已经产生后,仍可以通过 token 级操作降低后续计算。合并(merging)的直觉是:相邻 patch 的表征高度相关,完全保留会造成冗余;剪枝(pruning)的直觉是:并非所有 patch 都与当前任务相关,尤其在对话场景里,问题往往只指向图像的某些局部。更进一步,动态选择会把“保留哪些 token”变成一个可学习决策:例如根据跨模态对齐分数、注意力权重、或某种显著性指标来筛掉不重要的 token。理论上,好的 token 处理策略应满足两点:一是对任务相关性敏感,能保住关键信息;二是对模型行为稳定性友好,避免因为删 token 导致输出分布剧烈摆动。
4.4 多尺度重采样:把“局部细节”显式组织进少量 token
多尺度方案通常会在连接器层面做文章:让连接器输出一组固定数量的“摘要 token”,同时通过局部窗口、金字塔特征或查询机制把细节信息聚合进这些摘要 token。这样语言模型看到的 token 数可以保持稳定,而细节信息通过可学习聚合被“折叠”进少量 token 里。与简单平均或池化相比,多尺度重采样的关键在于“选择性聚合”:摘要 token 不是被动接收所有 patch 的平均,而是以任务相关或语义相关的方式提取信息。对于高分辨率文档或图表,结构化的多尺度信息(标题-段落-表格单元)也往往比纯 patch 序列更符合语言模型的推理习惯。
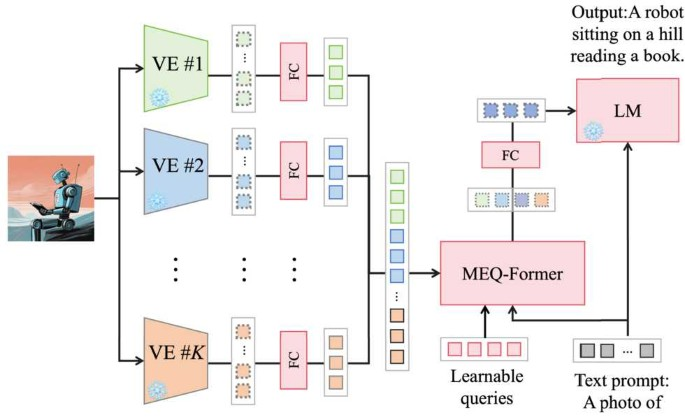
4.5 视觉专家与路由:多编码器/多专家的“稀疏计算”思路
当视觉输入类型多样(自然图像、文档、图表、医学影像)时,用一个统一视觉编码器往往会遇到“既要又要”的困境:对自然图像友好的表征未必对文档 OCR 友好,对医学影像友好的局部纹理表征又可能牺牲自然场景语义。于是视觉专家路由的直觉出现了:用多个视觉专家分别擅长不同领域或尺度,在推理时只激活必要的专家,避免把所有计算都做一遍。这样的设计把“容量”与“计算量”解耦:容量可以通过专家数提升,计算量通过稀疏激活控制。理论上它对应一种条件计算(conditional computation)机制,依赖一个路由器根据输入或任务选择专家子集。
4.6 视觉侧效率策略的归纳表
为了把视觉侧的效率策略从“名字”提升到“可理解的机制”,下表按“作用点—主要目标—代价形态”的方式做了归纳,强调它们到底是在改变 token 数、改变信息组织,还是改变计算路径。
| 作用点 | 机制抽象 | 主要解决的问题 | 典型代价与风险 |
|---|---|---|---|
| 输入层 | 多视角(全局+局部) | 高分辨率下 token 爆炸、细节与全局兼顾 | 需要额外裁剪策略;局部视图选择不当会漏信息 |
| token 层 | 合并/剪枝/动态选择 | 减少冗余 token、把预算聚焦到相关区域 | 剪枝不稳定可能导致回答漂移;需控制行为一致性 |
| 连接器层 | 重采样/多尺度摘要 token | 固定视觉 token 数,同时保留关键细节 | 摘要 token 过少会丢细节;过多则失去效率意义 |
| 架构层 | 视觉专家与路由 | 多领域视觉输入的条件计算 | 路由训练复杂;专家间协同与对齐更难 |
(表格为机制性总结,条目来源于公开方法的共性描述。)
5 语言侧效率:注意力、结构与微调
5.1 注意力的瓶颈不止是 FLOPs:KV cache 与带宽才是推理痛点
很多人谈“注意力昂贵”时只想到训练阶段的 $O(n^2)$,但在多模态对话里,推理阶段往往更接近真实瓶颈:视觉 token 会把上下文拉长,而 decode 阶段每一步都要读取历史 KV;当 KV 头数多、层数深、上下文长时,瓶颈会从算力转向显存与带宽。于是语言侧效率研究的一条主线,就是在不明显损伤建模能力的前提下,减少 KV 的体量或减少读取频率,或者让注意力结构更“共享”。
5.2 共享式注意力与 GQA:用更少的 KV 头支撑更多的 Query 头
Grouped-Query Attention(GQA)可以理解为 multi-head attention 与 multi-query attention 的折中:多个 query 头共享同一组 key/value 头,通过分组共享来降低 KV cache 的存储与读写压力,同时尽量保持多头 query 的表达能力。它的意义在多模态场景尤为突出,因为视觉 token 往往拉长上下文,KV 体量膨胀更快,GQA 这种“从结构上减 KV”的策略会直接影响推理延迟与显存占用。
5.3 近似注意力与特征降维:把“全连接交互”变得可控
当序列极长时,完全的全连接注意力会带来显著的二次代价,因此存在两类方向:一类通过特征降维或 token 层级结构把 n 缩小(例如逐层减少序列长度),另一类通过核技巧、低秩分解等方式近似注意力矩阵,使得计算从显式构造 $n\times n$ 的权重转向更轻量的形式。对多模态来说,近似注意力的吸引力在于它与 token 压缩可以叠加:视觉侧减少 token,语言侧再把注意力计算变得近似线性,二者共同把长上下文推理变成可承受的成本。
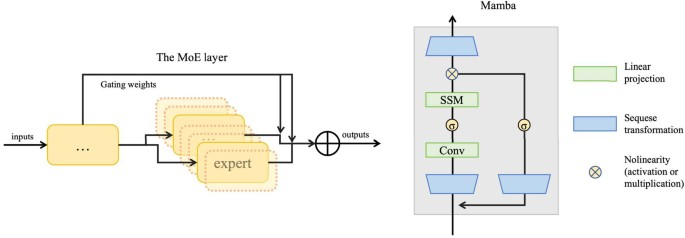
5.4 MoE:用稀疏激活换取更大容量
Mixture of Experts(MoE)的核心在于条件计算:把模型拆成多个专家,每个 token 只路由到少数专家计算,从而在相近计算量下获得更大参数容量。对多模态而言,MoE 的价值不只是“更大”,还在于“更分工”:视觉相关 token、指令 token、推理 token 可能需要不同的知识与表达,稀疏专家给了模型一种结构化的分配方式。与此同时,MoE 的训练与稳定性也更复杂:路由器容易塌缩、专家负载不均会造成训练浪费;因此从理论上看,MoE 是把效率问题从“算子复杂度”转移到“路由与优化稳定性”上。
5.5 Transformer 替代结构:RWKV 与状态空间模型的近线性长序列处理
Transformer 的长序列瓶颈推动了替代结构研究,其中一条线是把注意力重写为更接近 RNN 的形式(例如 RWKV),另一条线是状态空间模型(SSM)。SSM 的连续形式常见写法为:
$$
x'(t)=Ax(t)+Bu(t), \quad y(t)=Cx(t)+Du(t)
$$
其中是输入信号,
是潜状态,
是输出,A、B、C、D 为可学习参数。其直观含义是:用一个动态系统把长序列依赖编码到状态转移里,从而避免显式构造全连接注意力矩阵带来的二次代价。对多模态对话来说,如果语言侧能在长序列上保持近线性复杂度,那么视觉 token 的“长度压力”会明显缓解,尤其是在视频、长文档与多轮对话结合的场景。
5.6 参数高效微调:把“更新谁”变成效率开关
在多模态模型中,微调的代价不仅在于训练轮数,还在于“更新了多少参数”。参数高效微调(PEFT)通过只训练少量适配模块(如 LoRA)来降低反传开销并减少灾难性遗忘风险。在多模态场景里,PEFT 常与“冻结视觉编码器”一起出现:视觉侧保持稳定,连接器与语言侧通过少量参数适配对齐与指令跟随。其理论意义在于:把“对齐”从大规模权重更新转化为低秩扰动或轻量适配,从而让训练更像“校准”而不是“重学”。
6 训练范式的效率化:预训练、指令微调与迁移
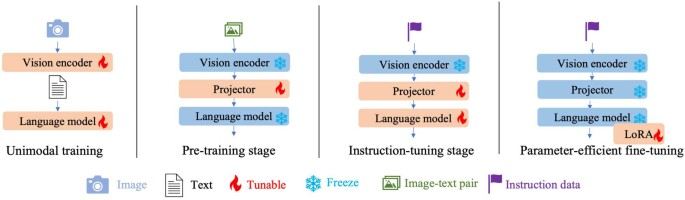
6.1 训练阶段拆解:为什么要分阶段与冻结
多模态训练通常会显式区分单模态预训练、跨模态预训练(对齐)、指令微调以及参数高效微调等阶段。阶段拆解的意义在于把难题拆成可控子问题:先让视觉编码器与语言模型各自有良好表征,再用连接器把两者对齐,最后用指令数据让模型学会在对话场景中稳定地调用视觉信息。冻结策略的核心是控制灾难性遗忘:语言模型原本的语言能力往往来自大规模文本预训练,若在早期对齐阶段全量更新,很容易破坏这种能力;因此一种常见做法是在对齐或指令微调时冻结视觉编码器,只更新连接器与语言模型(或语言模型的一小部分),在预算更紧时进一步只更新 LoRA 等小模块。
6.2 预训练目标:用交叉熵把“图像条件下的文本”学出来
把视觉信息注入语言模型后,预训练阶段常用标准交叉熵/最大似然目标来学习在图像与指令条件下生成文本序列,其形式可写为:
$$
\max_{\theta}\sum_{i=1}^{L}\log p_{\theta}\left(x_i \mid X_v, X_{\text{instruct}}, X_{a,<i}\right)
$$
其中为图像输入,
为指令/提示,
为需要生成的目标文本序列,
为第 i 个 token,
表示前缀,
是可训练参数集合。这个目标强调了两个效率相关的事实:第一,若把可训练参数
主要限制在连接器上,就能以很低的更新成本完成对齐;第二,若视觉 token 太长,条件项会让每个 token 的预测都要“看”很长的历史,从而放大训练与推理成本。
6.3 指令微调:把多模态任务组织成多轮对话序列
指令微调阶段通常将数据组织成多轮对话,把图像与第一轮指令组合在一起,再在后续轮次继续对话。一个常见的组织方式可以写成如下分段形式:
$$
X_{\text{instruct}}^{t}=
\begin{cases}
\text{Randomly choose }[X_q^{1},X_v]\ \text{or}\ [X_v,X_q^{1}], & t=1\
X_q^{t}, & t>1
\end{cases}
$$
其中t为轮次, 为第 t 轮的文本指令/问题,
为图像。该式体现了多模态对话数据的一个关键点:图像通常只在对话开头显式给出,但它的影响需要贯穿后续轮次;这要求模型在长上下文里保持视觉条件的一致性,也意味着视觉 token 的长度会直接影响多轮对话的总体成本。
6.4 更经济的指令微调:多模态适配方案的对比
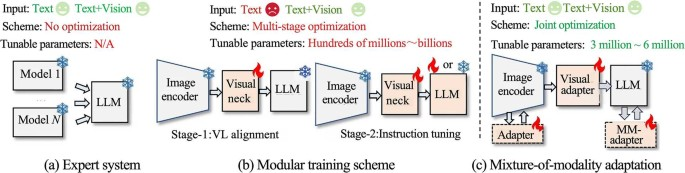
当希望以更低成本完成从语言模型到视觉语言任务的迁移时,可以把“适配方式”理解为一种结构选择:是把视觉模块与语言模块通过一个固定接口连接、还是引入轻量模块在多模态任务上做联合优化、还是仅在语言侧插入少量适配器来吸收视觉信息。不同适配方式在可训练参数量、训练阶段数量、以及对模型行为稳定性的影响上差异显著;理论上,它们对应不同程度的“分布漂移控制”:越少更新原始语言模型参数,就越不容易遗忘,但也越依赖连接器把视觉信息表达得足够好。
6.5 训练策略的“配方化”理解:不只是两阶段或四阶段
训练流程有时会被描述为“两阶段”“三阶段”“四阶段”,但更本质的理解是:每个阶段都在回答“哪些参数需要更新、哪些数据需要看、token 预算如何控制”。例如,多阶段预训练可能先限制分辨率与 batch 以获得更高吞吐,再引入更高分辨率或文档数据补齐能力;单阶段训练则试图把多类数据统一为多轮对话格式,减少人为阶段划分的复杂性。无论哪种方式,其效率本质仍然落在三个变量上:训练中可反传参数的体量、输入序列长度(尤其是视觉 token 数)、以及数据质量对收敛速度的影响。
7 数据与评测:预训练数据、指令数据与基准体系
7.1 预训练数据:规模、噪声与过滤
预训练数据往往承担两件事:一是提供跨模态对齐信号(图文对应关系),二是提供广覆盖的世界知识。大规模图文对来自互联网,规模大但噪声高,因此常见做法是利用相似度过滤、规则清洗或更强模型生成更细粒度描述来提升质量。理论上,数据质量对小模型尤其关键,因为小模型更难“靠参数冗余吞噪声”,训练配方必须把有限算力集中在高信息密度数据上。
下面给出常用预训练数据的规模与代表性使用情况(字段含义:#.X 为 X 的数量,#.T 为文本数量,#.X-T 为图文对数量,X 可以是图像/视频/音频等)。
| 数据集 | 模态 X | #.X | #.T | #.X-T | 代表性使用方向 |
|---|---|---|---|---|---|
| CC3M | Image | 3.3M | 3.3M | 3.3M | TinyGPT-V、MM1 |
| CC12M | Image | 12.4M | 12.4M | 12.4M | MM1 |
| SBU | Image | 1M | 1M | 1M | TinyGPT-V |
| LAION-5B | Image | 5.9B | 5.9B | 5.9B | TinyGPT-V |
| LAION-COCO | Image | 600M | 600M | 600M | Vary-toy |
| COYO | Image | 747M | 747M | 747M | MM1 |
| COCO Caption | Image | 164K | 1M | 1M | Vary-toy |
| CC595k | Image | 595K | 595K | 595K | MobileVLM、LLaVA-Phi、LLaVA-Gemma、Mini-Gemini |
| RefCOCO | Image | 20K | 142K | 142K | Vary-toy |
| DocVQA | Image | 12K | 50K | 50K | Vary-toy |
| LLaVA-1.5-PT | Image | 558K | 558K | 558K | Imp-v1、MoE-LLaVA、Vary-toy、Mipha、VL-Mamba、Tiny-LLaVA |
| ShareGPT4V-PT | Image | 1246K | 1246K | 1246K | Tiny-LLaVA、MobileVLM v2 |
| ShareGPT4 | Image | 100K | 100K | 100K | ALLaVA |
| Bunny-pretrain-LAION-2M | Image | 2M | 2M | 2M | Bunny |
| ALLaVA-Caption-4V | Image | 715K | 715K | 715K | Mini-Gemini、ALLaVA |
| MMC4(Interleaved) | Image | 571M | 43B | 101.2M(Instances) | DeepSeek-VL |
| Obelics(Interleaved) | Image | 353M | 115M | 141M(Instances) | MM1 |
7.2 指令数据:任务覆盖、对话结构与构造方式
指令数据的核心是把任务“对话化”:输入从纯图文对变成“图像 + 指令(可能多轮)”,输出变成“模型需要生成的响应”。这一步不仅改变了数据形式,也改变了模型学习到的行为:它学会把视觉信息嵌入指令约束下的回答,而不是仅生成描述。高质量指令数据可以来自人工标注,也可以来自规则自动构造与半自动校验;当预算有限时,自动构造往往是主流,但需要防止噪声与幻觉把错误行为固化进模型。
下面给出常用指令数据的来源、构造方式与规模信息(字段含义:I→O 表示输入到输出模态形式,SFT 表示监督微调)。
| 数据集 | 类型 | I→O | 来源 | 构造方式 | 样本量 | 代表性使用方向 |
|---|---|---|---|---|---|---|
| LLaVA’s IT | SFT | I+T→T | MS-COCO | Auto. | 150K | MobileVLM、LLaVA-Phi、Mini-Gemini、Vary-toy、TinyGPT-V、Imp-v1、ALLaVA、SPHINX-X、LLaVA-Gemma、MM1 |
| ShareGPT4V’s IT | SFT | I+T→T | LCS/COCO/SAM/TextCaps/WikiArt | Auto.+Manu. | - | Tiny-LLaVA、Mini-Gemini、MM1、DeepSeek-VL、SPHINX-X |
| LLaVA-1.5’s IT | SFT | I+T→T | LLaVA/Visual Genome/VQAv2/ShareGPT/A-OKVQA/TextCaps/GQA/OKVQA/OCRVQA/RefCOCO | Auto.+Manu. | 665K | Tiny-LLaVA、VL-Mamba、Cobra、LLaVA-Gemma、Mipha、MoE-LLaVA |
| LRV-Instruct | SFT | I+T→T | Visual Genome | Auto. | 300K | MoE-LLaVA、Cobra |
| LVIS-INSTRUCT-4V | SFT | I+T→T | LVIS | Auto. | 220K | MoE-LLaVA、SPHINX-X、DeepSeek-VL、Cobra |
| LAION GPT4V | SFT | I+T→T | LAION | Auto. | 12.4K | Mini-Gemini、SPHINX-X、DeepSeek-VL |
| MiniGPT-4’s IT | SFT | I+T→T | CC3M/CC12M | Auto. | 5K | TinyGPT-V |
| SVIT | SFT | I+T→T | MS-COCO/Visual Genome | Auto. | 3.2M | MoE-LLaVA |
| Bunny-695K | SFT | I+T→T | SVIT-mix/WizardLM-evol-instruct | Auto. | 695K | Bunny |
| GQA | SFT | I+T→T | Visual Genome | Auto. | 22M | MM1、SPHINX-X、LLaVA-Gemma |
7.3 基准体系:分数背后的能力维度
多模态基准往往覆盖多种能力维度:通用 VQA、文本识别与阅读、数学/科学推理、综合理解、幻觉评测与对话评测。效率研究之所以需要这些基准,是因为“省算力”不能以牺牲关键能力为代价;但同时也要认识到:分数并不能直接等价于真实部署效果,因为真实部署还受到输入分辨率、响应时延、上下文长度、以及安全性等多因素制约。因此,阅读基准表时应把它当作“能力轮廓”,再结合模型组件配置与 token 预算来理解其效率路径。
下面的对照表给出了若干模型在 14 个基准上的表现(“-”表示未报告),可以用来观察小模型/高效模型与较大模型之间的能力差异。
| 模型 | 语言骨干 | VQAv2 | TextVQA | SciQA | VizWiz | MMMU | MathVista | MME | MMBench | SeedBench | POPE | LLaVA-Bench | MM-Vet |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Flamingo | Chinchilla (70B) | 56.3 | - | - | - | - | - | - | - | - | - | - | - |
| BLIP2 | FlanT5-XXL (11B) | 65.0 | 42.5 | - | 19.6 | - | - | 1293.8 | 32.8 | 46.4 | 85.3 | 38.1 | 22.4 |
| LLaVA-1.5 | Vicuna (7B) | 78.5 | 58.2 | 66.8 | 50.0 | - | - | 1510.7 | 64.3 | 58.6 | 85.9 | - | 30.5 |
| MiniGPT4 | Vicuna (13B) | - | - | - | - | - | - | 1288.2 | 23.6 | - | 88.6 | - | - |
| InstructBLIP | Vicuna (7B) | - | 50.1 | - | 34.5 | - | - | 1212.8 | 36.0 | 53.4 | - | - | - |
| Qwen-VL-Chat | Qwen (7B) | 78.2 | 61.5 | 67.1 | 38.9 | 35.2 | - | 1487.5 | 60.6 | 58.2 | - | - | 28.2 |
| MiniGPT-v2-Chat | Llama2 (7B) | - | - | - | - | - | - | - | 47.9 | - | - | - | - |
| InternVL-Chat | InternLM2 (7B) | - | - | - | - | - | - | 1543.8 | 57.0 | - | - | - | - |
| Emu2-Chat | Llama2 (13B) | - | - | - | - | - | - | - | 54.2 | - | - | - | - |
| Gemini Pro | - | - | 74.6 | 79.1 | 64.0 | 50.0 | 45.2 | - | 73.6 | - | - | - | - |
| GPT4V | - | 77.2 | - | - | - | 53.8 | 49.9 | - | 75.0 | - | - | - | 67.5 |
| MobileVLM | MobileLLaMA (2.7B) | 77.2 | 58.9 | - | - | - | - | 1280.1 | 53.2 | 51.5 | - | - | - |
| LLaVA-Phi | Phi-2 (2.7B) | 73.7 | 48.6 | 68.4 | 35.9 | - | - | 1335.1 | 59.8 | 56.2 | 85.8 | - | 25.7 |
| Imp-v1 | MobileLLaMA (2.7B) | 76.7 | 52.9 | - | - | - | - | 1418.9 | 56.7 | 53.5 | 85.7 | - | - |
| TinyLLaVA | TinyLLaMA (1.1B) | 75.4 | 59.0 | - | - | - | - | 1323.1 | 54.1 | 48.6 | - | - | - |
| Bunny | StableLM-2 (1.6B) | 77.0 | 53.5 | 67.3 | 46.5 | - | - | 1360.0 | 59.2 | - | - | - | - |
| MobileVLM-v2 | MobileLLaMA (2.7B) | 80.2 | 62.0 | 66.7 | - | - | - | 1445.9 | 63.2 | 54.8 | - | - | - |
| MoE-LLaVA | Vicuna (7B) | 79.2 | 58.0 | - | - | - | - | 1512.3 | 64.7 | 59.4 | 86.9 | - | 31.2 |
| Cobra | Mamba-2.8b-Zephyr | 71.5 | - | 66.7 | - | - | - | 1335.8 | 54.2 | - | 87.0 | - | 22.4 |
| Mini-Gemini | Gemma (2B) | 79.1 | 56.2 | 70.7 | 36.8 | - | - | 1447.1 | 65.2 | 55.2 | - | - | 29.7 |
| Vary-toy | Qwen (1.8B) | 74.5 | 37.9 | - | - | - | - | - | 48.6 | - | - | - | - |
| TinyGPT-V | Phi-2 (2.7B) | 80.4 | 54.4 | - | - | - | - | 1451.4 | 64.0 | 52.1 | 86.6 | - | 31.1 |
| SPHINX-Tiny | TinyLLaMA (1.1B) | 74.8 | 59.5 | 68.0 | 33.4 | - | - | 1347.7 | 60.5 | 58.8 | 84.6 | 68.8 | 27.3 |
| ALLaVA | Phi-2 (2.7B) | 80.2 | 54.8 | 72.3 | 46.5 | - | - | 1402.8 | 65.9 | 52.1 | 86.2 | - | 34.4 |
| MM1 | - | 80.8 | 72.2 | 75.8 | 54.7 | 35.9 | 43.7 | 1529.1 | 72.8 | 68.3 | - | 75.7 | 45.3 |
| LLaVA-Gemma | Gemma (2B) | 79.6 | 61.4 | 73.9 | 46.1 | - | - | 1453.3 | 66.3 | - | 86.1 | 71.2 | 38.1 |
| Mipha | Phi-2 (2.7B) | 80.2 | 51.3 | 71.7 | 44.8 | - | - | 1469.6 | 65.2 | 57.5 | 86.7 | - | 30.8 |
| VL-Mamba | - | 70.1 | 43.8 | - | - | - | - | 1256.6 | 53.5 | - | 84.5 | - | 22.0 |
| MiniCPM-V 2.0 | MiniCPM (2.4B) | 81.6 | 74.1 | 75.1 | 56.2 | 38.2 | 51.7 | - | 76.6 | 73.0 | - | 80.6 | 48.0 |
| DeepSeek-VL | DeepSeek-LLM (1.3B) | 80.5 | 64.9 | 72.5 | 43.2 | - | - | 1414.6 | 66.6 | - | 87.2 | - | 34.9 |
| KarmaVLM | Qwen1.5 (0.5B) | 79.3 | 59.0 | - | - | - | - | 1277.1 | 56.0 | - | 83.2 | - | 26.0 |
| moondream2 | Phi-1.5 (1.3B) | 77.9 | 60.8 | 69.7 | 45.4 | - | - | 1280.4 | 65.4 | 53.5 | 84.8 | - | 30.5 |
| Bunny-v1.1-4B | Phi-3-Mini-4K (3.8B) | 78.4 | 64.2 | 76.6 | 52.9 | - | 38.8 | 1432.8 | 67.0 | - | 85.9 | - | 38.2 |
| S-Wrapper | Phi-3-mini-4K (3.8B) | 75.6 | - | 71.0 | - | - | - | 1510.7 | 69.1 | - | 87.0 | 80.8 | 45.0 |
8 典型任务中的效率挑战:理论层面的“困难在哪里”
8.1 文档与图表理解:细粒度视觉与 token 预算矛盾最尖锐
文档、图表、屏幕截图类任务之所以成为效率压力测试,是因为其关键信息往往以小字号文本、密集表格结构或细线条图形存在,模型必须看清细节才能答对;但看清细节通常意味着提升分辨率,而提升分辨率会造成 token 爆炸并拖垮语言侧推理。这类任务逼迫模型在“信息保真”和“token 压缩”之间做结构化权衡,因此更容易催生多尺度重采样、局部视图选择、token 合并等方法。理论上,这等价于在保证任务所需最小充分统计量的前提下,寻找一种更强的压缩映射,使视觉信息以更少 token 的形式进入语言模型。
8.2 医学与高风险场景:小模型的可控性与专家化
当任务领域知识密集且错误代价高时,小模型路线往往需要更谨慎的配方:一方面,小模型参数少,知识覆盖可能不足;另一方面,小模型更容易被高质量数据显著提升,因此通过专家路由、领域数据配方与更强的对齐约束,可以在更可控的成本下获得可用能力。这里的效率不只是算力问题,也包含“可复核、可解释、可校准”的工程需求,因为高风险场景更难容忍幻觉。
8.3 视频理解:时间维度让 token 爆炸更快发生
视频理解相当于在图像 token 之外再乘一个时间维度,若直接把多帧按 patch 全喂给语言模型,token 数会迅速超过可承受范围。理论上,视频效率问题与长上下文问题高度同构:需要帧选择、关键片段摘要、统一表征与稀疏计算,把“长序列”转化为“少量高信息密度 token”。因此语言侧的长序列高效结构(如 SSM)与视觉侧的帧/patch 压缩往往需要联合考虑,否则单独优化一侧只能缓解一部分压力。
9 局限性与实践建议:把效率落到可复现的指标上
效率研究最常见的误区是把“参数量”当作唯一指标,而忽略了 token 与推理路径。实际上,同等参数量下,视觉 token 的长度、连接器输出 token 的数量、是否使用 KV 共享、是否存在跳算与剪枝,都会显著改变端到端延迟;同等延迟下,数据质量、训练阶段冻结策略与指令格式也会显著改变模型行为稳定性。更进一步,多模态模型的“幻觉”不仅是安全问题,也是效率问题:当模型缺乏足够的视觉条件信息或对齐不稳定时,它会倾向于用语言先验填补缺口,这意味着压缩策略必须以“不破坏条件一致性”为硬约束,否则省下来的 token 会以错误回答的形式付出代价。
因此,在工程上更可靠的做法是把效率拆成可测量指标,并把策略与指标一一对应:输入分辨率与视觉 token 数决定视觉侧预算;连接器输出 token 数决定注入带宽;语言侧注意力结构决定 KV cache 体量与带宽;训练阶段冻结/解冻决定反传成本;数据配方决定收敛速度与最终行为。只有当这些变量被显式记录并可复现,所谓“高效”才不是一句泛泛口号,而是一套可迁移的设计规律。
参考文献(精选)
[1] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
[2] Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023.
[3] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems, 35:23716–23736, 2022.
[4] Xiangxiang Chu, Limeng Qiao, Xinyu Zhang, Shuang Xu, Fei Wei, Yang Yang, Xiaofei Sun, Yiming Hu, Xinyang Lin, Bo Zhang, et al. Mobilevlm v2: Faster and stronger baseline for vision language model. arXiv preprint arXiv:2402.03766, 2024.
[5] Yanyuan Qiao, Zheng Yu, Longteng Guo, Sihan Chen, Zijia Zhao, Mingzhen Sun, Qi Wu, and Jing Liu. Vl-mamba: Exploring state space models for multimodal learning. arXiv preprint arXiv:2403.13600, 2024.
[6] Junbum Cha, Wooyoung Kang, Jonghwan Mun, and Byungseok Roh. Honeybee: Locality-enhanced projector for multimodal llm. arXiv preprint arXiv:2312.06742, 2023.
[7] Xiangxiang Chu, Limeng Qiao, Xinyang Lin, Shuang Xu, Yang Yang, Yiming Hu, Fei Wei, Xinyu Zhang, Bo Zhang, Xiaolin Wei, et al. Mobilevlm: A fast, reproducible and strong vision language assistant for mobile devices. arXiv preprint arXiv:2312.16886, 2023.
[8] Yichen Zhu, Minjie Zhu, Ning Liu, Zhicai Ou, Xiaofeng Mou, and Jian Tang. Llava-phi: Efficient multi-modal assistant with small language model. arXiv preprint arXiv:2401.02330, 2024.
[9] Baichuan Zhou, Ying Hu, Xi Weng, Junlong Jia, Jie Luo, Xien Liu, Ji Wu, and Lei Huang. Tinyllava: A framework of small-scale large multimodal models. arXiv preprint arXiv:2402.14289, 2024.
[10] Bin Lin, Zhenyu Tang, Yang Ye, Jiaxi Cui, Bin Zhu, Peng Jin, Junwu Zhang, Munan Ning, and Li Yuan. Moe-llava: Mixture of experts for large vision-language models. arXiv preprint arXiv:2401.15947, 2024.
[11] Yanwei Li, Yuechen Zhang, Chengyao Wang, Zhisheng Zhong, Yixin Chen, Ruihang Chu, Shaoteng Liu, and Jiaya Jia. Mini-gemini: Mining the potential of multi-modality vision language models. arXiv preprint arXiv:2403.18814, 2024.
[12] Zhengqing Yuan, Zhaoxu Li, and Lichao Sun. Tinygpt-v: Efficient multimodal large language model via small backbones. arXiv preprint arXiv:2312.16862, 2023.
[13] Guiming Hardy Chen, Shunian Chen, Ruifei Zhang, Junying Chen, Xiangbo Wu, Zhiyi Zhang, Zhihong Chen, Jianquan Li, Xiang Wan, and Benyou Wang. Allava: Harnessing gpt4v-synthesized data for a lite vision-language model. arXiv preprint arXiv:2402.11684, 2024.
[14] Brandon McKinzie, Zhe Gan, Jean-Philippe Fauconnier, Sam Dodge, Bowen Zhang, Philipp Dufter, Dhruti Shah, Xianzhi Du, Futang Peng, Floris Weers, et al. Mm1: Methods, analysis & insights from multimodal llm pre-training. arXiv preprint arXiv:2403.09611, 2024.
[15] Musashi Hinck, Matthew L Olson, David Cobbley, Shao-Yen Tseng, and Vasudev Lal. Llava-gemma: Accelerating multimodal foundation models with a compact language model. arXiv preprint arXiv:2404.01331, 2024.
[16] Yuan Yao, Tianyu Yu, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Weilin Zhao, Kaihuo Zhang, Yixin Hong, Haoyu Li, Shengding Hu, Zhi Zheng, Jie Zhou, Jie Cai, Chao Jia, Xu Han, Guoyang Zeng, Dahai Li, Zhiyuan Liu, and Maosong Sun. Minicpm-v 2.0: An efficient end-side mllm with strong ocr and understanding capabilities. https://github.com/OpenBMB/MiniCPM-V, 2024.
[17] Shengding Hu, Yuge Tu, Xu Han, Chaoqun He, Ganqu Cui, Xiang Long, Zhi Zheng, Yewei Fang, Yuxiang Huang, Weilin Zhao, et al. Minicpm: Unveiling the potential of small language models with scalable training strategies. arXiv preprint arXiv:2404.06395, 2024.
[18] Karmavlm: A family of high efficiency and powerful visual language model. https://github.com/ thomas-yanxin/KarmaVLM, 2024.
[19] tiny vision language model. https://github.com/vikhyat/moondream, 2024.
[20] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
[21] Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 11975–11986, 2023.
[22] Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023.
[23] Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752, 2023.
[24] Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou, and Tianhang Zhu. Qwen technical report, 2023.
[25] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022.
[26] Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2556–2565, 2018.
[27] Soravit Changpinyo, Piyush Sharma, Nan Ding, and Radu Soricut. Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3558–3568, 2021.
[28] Vicente Ordonez, Girish Kulkarni, and Tamara Berg. Im2text: Describing images using 1 million captioned photographs. Advances in neural information processing systems, 24, 2011.
[29] Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: An open large-scale dataset for training next generation image-text models. Advances in Neural Information Processing Systems, 35:25278–25294, 2022.
[30] Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6700–6709, 2019.
[31] Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8317–8326, 2019.
[32] Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6904–6913, 2017.
[33] Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, Yunsheng Wu, and Rongrong Ji. Mme: A comprehensive evaluation benchmark for multimodal large language models, 2024.
[34] Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? arXiv preprint arXiv:2307.06281, 2023.
[35] Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. arXiv preprint arXiv:2305.10355, 2023.
[36] Junhua Mao, Jonathan Huang, Alexander Toshev, Oana Camburu, Alan L Yuille, and Kevin Murphy. Generation and comprehension of unambiguous object descriptions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 11–20, 2016.
[37] Fuxiao Liu, Kevin Lin, Linjie Li, Jianfeng Wang, Yaser Yacoob, and Lijuan Wang. Mitigating hallucination in large multi-modal models via robust instruction tuning. In The Twelfth International Conference on Learning Representations, 2023.
[38] Agrim Gupta, Piotr Dollar, and Ross Girshick. Lvis: A dataset for large vocabulary instance segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5356–5364, 2019.
[39] LAION. Gpt-4v dataset. https://huggingface.co/datasets/laion/gpt4v-dataset, 2023.
[40] Bo Zhao, Boya Wu, and Tiejun Huang. Svit: Scaling up visual instruction tuning. arXiv preprint arXiv:2307.04087, 2023.
[41] Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, and Daxin Jiang. Wizardlm: Empowering large language models to follow complex instructions. arXiv preprint arXiv:2304.12244, 2023.
[42] Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv preprint arXiv:2308.12966, 2023.
[43] Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering. Advances in Neural Information Processing Systems, 35:2507–2521, 2022.
[44] Danna Gurari, Qing Li, Abigale J Stangl, Anhong Guo, Chi Lin, Kristen Grauman, Jiebo Luo, and Jeffrey P Bigham. Vizwiz grand challenge: Answering visual questions from blind people. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3608–3617, 2018.


















 1090
1090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











