



目录
2.4 工作流与控制流:为什么2025更像“图结构”而不是“长提示词”
3 通用ChatGPT Agent的分层架构:2025年的“参考实现”
3.2 Agent Loop:观察—推理—行动—反思的工程化闭环
3.3 运行对象:任务、会话、状态、轨迹与“可解释的中间层”
4.1 工具分类:托管工具、函数工具、Agent工具、MCP服务器
4.4 File Search与向量存储:知识外部化的主通道
5.2 Toolformer:让模型学会“何时用工具”的数据路径
5.4 Voyager:技能库、自动课程与“可迁移的工具链”
7.2 Agents as Tools:子Agent工具化的工程意义
7.3 Agent Builder:节点化编排、版本化发布与可调试运行
8.1 Tracing与Trace Grading:把每一步变成可审计事件
8.2 学术基准:WebArena、VisualWebArena、OSWorld、GAIA等
9.1 Prompt Injection:从文本攻击到工具劫持
9.2 用户确认与watch mode:把高风险动作变成“可逆决策”
11 2025生态与标准化:MCP、连接器与“可组合工具链”
1 引言
如果把传统聊天模型看作“只会说话的系统”,那么2025年兴起并快速落地的ChatGPT Agent更像“会做事的系统”:它不仅能生成文本,还能在任务的上下文中自行搜索、读取文件、调用外部工具、甚至通过可视化浏览器界面执行点击与输入,从而把“回答问题”扩展为“完成目标”。这种变化并不是简单的能力叠加,而是架构层面的范式转移:系统需要有明确的任务边界、可回溯的执行轨迹、可控的权限与确认机制,以及能把外部世界变化反馈回模型的闭环。以OpenAI在2025年7月发布的ChatGPT agent系统卡所描述的能力形态来看,一个通用Agent往往将深度研究式的多步检索与综合写作能力、可视化远程浏览器的任务执行能力、受限网络的终端/代码环境、以及通过连接器访问外部数据源等能力整合为一个统一体,并且将安全作为系统设计的固有部分而不是外挂功能。
从工程实现角度看,2025年的“通用ChatGPTAgent架构”已经逐步形成可复用的标准构件:以Responses API为核心的工具调用接口与长任务执行方式,以Agents SDK为代表的轻量编排与可观测机制,以AgentKit/Agent Builder/ChatKit为代表的可视化工作流与部署组件,以及以MCP(Model Context Protocol)为代表的工具与上下文标准化接入方式。尤其值得注意的是,OpenAI在2025年5月对Responses API的更新中强调了远程MCP服务器支持、后台模式(background mode)、推理摘要(reasoning summaries)与加密推理项(encrypted reasoning items)等特性,指向了一个更“可运营”的Agent平台:不仅能做事,还要能在真实业务中长期稳定运行、可审计、可优化。
本文将围绕“2025通用ChatGPT Agent架构”进行综述性梳理:从理论抽象与技术基础出发,逐层拆解Agent的分层架构、工具系统、规划与推理范式、记忆与知识外部化、多Agent协作与工作流编排、评测与可观测性、安全与权限控制、以及成本与运维约束。
2 理论知识与技术基础
2.1 从对话模型到Agent:最小闭环到底是什么
讨论“Agent架构”之前,先把“Agent”与“聊天”区分清楚。聊天系统的核心闭环往往是“输入→生成→输出”,即使加入了少量工具(例如单次检索),本质上仍是“为了一次回答服务”。而通用Agent的闭环更接近“观察—推理—行动—再观察”的反复迭代,它必须把外部世界当成状态机/环境来处理:网页会变化、文件会更新、工具会失败、权限会不足、用户会改变目标,系统不能只追求一次性输出的“看起来正确”,而要在执行过程中持续校正。OpenAI在Agents SDK中把这种闭环直接做成内建的“agent loop”,强调其负责工具调用、回传结果、持续循环直到模型停止。
当系统具备网页搜索、文件检索、GUI操作、代码执行、连接器访问等能力时,闭环的“行动”空间会变得非常大,这带来两个直接后果:一是模型输出不再只是自然语言,还会产生结构化的工具调用参数;二是系统必须把“行动结果”作为下一步推理的输入,保证状态一致性。Computer use工具的官方说明明确把它描述为一个连续循环:模型提出如click(x,y)、type(text)等动作,你的代码在真实浏览器/虚拟机环境执行,然后把截图回传给模型继续决策。 这意味着Agent系统的工程核心,已经从“生成一段话”转向“维护一个可交互环境中的闭环控制”。
2.2 形式化视角:把Agent看成带工具的POMDP
为了更系统地理解“通用ChatGPT Agent架构”,一个常用的理论抽象是把Agent视作部分可观测马尔可夫决策过程(POMDP)中的策略执行者:环境有真实状态s,但Agent只能通过观测o(例如网页DOM、可访问性树、截图、文件片段、工具返回值)来近似推断状态;Agent在每一步选择行动a(自然语言输出或工具调用),获得奖励/代价信号r,同时环境转移到新状态。Agent的目标并不一定是传统强化学习里严格的长期回报最大化,但把“成功完成任务”形式化为奖励函数,有助于解释许多工程设计选择,比如为什么要引入工具调用成本、为什么要限制某些权限、为什么要做用户确认与“watch mode”。
一个简化的目标函数可以写成“带成本的期望回报最大化”:
$$
\pi^*=\arg\max_{\pi}\ \mathbb{E}\left[\sum_{t=0}^{T}\gamma^{t}\left(r_t-\lambda c_t\right)\right]
$$
其中,π表示策略(可由LLM+编排器共同实现),γ为折扣因子,r_t是每步对“任务进展”的奖励刻画,c_t是工具调用/时间/风险等成本,λ是成本权重。这个公式在工程上对应着非常具体的现象:当工具调用昂贵、或具有潜在风险(如计算机操作可能误点、终端可能泄露环境变量)时,系统会偏向先用推理压缩搜索空间,再谨慎调用工具,并在关键步骤插入用户确认与安全检查。OpenAI在计算机使用工具文档中也明确提醒其仍处于beta阶段,不建议在完全登录/高风险环境中无监督信任。
POMDP形式化还解释了“记忆”的必要性:因为观测并不等于状态,Agent需要维护信念状态b_t(belief),以便在部分信息下决策。在经典POMDP里,belief更新可写为:
$$
b_{t+1}(s')=\eta\ O(o_{t+1}\mid s')\sum_{s}T(s'\mid s,a_t)\ b_t(s)
$$
这里T是状态转移概率,O是观测概率,η是归一化常数。对LLM Agent而言,我们通常不会显式计算这些概率,但会用“上下文窗口里的历史消息、工具回执、检索片段、结构化状态对象”来近似承载b_t。Agents SDK把“Sessions”作为一等公民,强调其自动维护对话历史以支撑跨次运行的状态管理。
2.3 检索增强与工具增强:上下文构建的两条路径
在2025年的通用Agent实践中,“让模型知道更多”通常走两条路径:第一条是检索增强(RAG/向量检索/文件检索),第二条是工具增强(调用外部系统获取实时信息,或直接操作环境完成任务)。二者看似类似,实则对架构的要求不同。检索增强更强调“把外部知识压缩成可输入上下文的片段”,需要向量化、召回、重排、切片与过滤;工具增强更强调“把外部系统当成行动空间的一部分”,需要工具定义、参数校验、权限、失败重试、以及执行环境的安全隔离。
用一个简化的检索流程表达式,可以把“查询q构建上下文C(q)”写成:
![]()
这里D是文档片段集合,e(·)是向量编码器,sim是相似度函数,TopK产生排序索引π,Concat把前k个片段拼接为上下文。这个公式背后的工程问题在于:k如何选、片段如何切、过滤条件如何表达、以及召回后如何让模型“信任并引用”这些片段。OpenAI在Agents SDK与平台文档里把“file search”作为托管工具之一,并强调其可查询OpenAI托管的向量存储(vector stores),同时支持多向量库搜索与属性过滤等能力。
工具增强则更像把Agent嵌入到一个“可执行的工作流”:模型不需要把所有知识压进上下文,只需要知道“该去哪个工具问什么问题、拿到什么结果再怎么推理”。OpenAI在web search工具文档中甚至把“深度研究(deep research)”单独作为一种更长程、更迭代的检索方式,强调它可能调用大量来源并适合配合后台模式运行。 这也意味着,通用Agent架构必须同时支持“检索片段注入”和“工具循环控制”,而且两者在可观测性与安全策略上会有明显差异。
2.4 工作流与控制流:为什么2025更像“图结构”而不是“长提示词”
早期许多LLM应用用“一段超长提示词+少量函数调用”就能跑起来,但当任务变成多步、多工具、多角色协作时,控制流会迅速变得复杂:你需要条件分支、错误回退、循环、并行检查、不同角色的handoff、以及对每一步输入输出进行类型约束。这些需求推动了工作流图结构在2025年的主流化。OpenAI的Agent Builder把“workflow”定义为agents、tools与control-flow logic的组合,并强调节点连接形成“typed edge”,即每条边有明确的数据契约,便于调试与防止下游节点收到不符合预期的数据。
这种“图化”并不只是界面上的便利,而是Agent可靠性工程的核心:当你能把每一步的输入输出类型化,就能把很多原本会在模型里以隐式方式发生的问题(比如某个工具参数缺失、某个字段类型错误、某次检索没召回)前移到编排层做校验与补救。2025年Agents SDK强调“少量原语”即可表达复杂关系:agents、handoffs、guardrails、sessions,再加上内建tracing,这种设计取向与“图工作流”是一致的——把控制流显式化,把安全与校验显式化,把执行轨迹显式化。
3 通用ChatGPT Agent的分层架构:2025年的“参考实现”
3.1 整体框架结构:从模型到执行环境的五层视图
把2025年的通用ChatGPT Agent拆开看,最清晰的一种方式是分层:最底层是执行环境(浏览器、虚拟机、沙盒、外部系统API),其上是工具层(web search、file search、computer use、code interpreter、连接器、MCP服务器等),再上是编排层(agent loop、工作流图、handoffs、重试、缓存、并行guardrails),再上是模型层(具备推理与工具调用能力的LLM/推理模型),最上是产品层(交互UI、会话、权限、可观测与审计、企业治理)。OpenAI对ChatGPT agent的描述基本覆盖了这些要素:它结合深度研究与Operator,通过远程可视浏览器执行任务,提供受限网络的终端工具进行数据分析与生成幻灯片/表格,并可通过第一方连接器访问外部数据源(如Google Drive)。
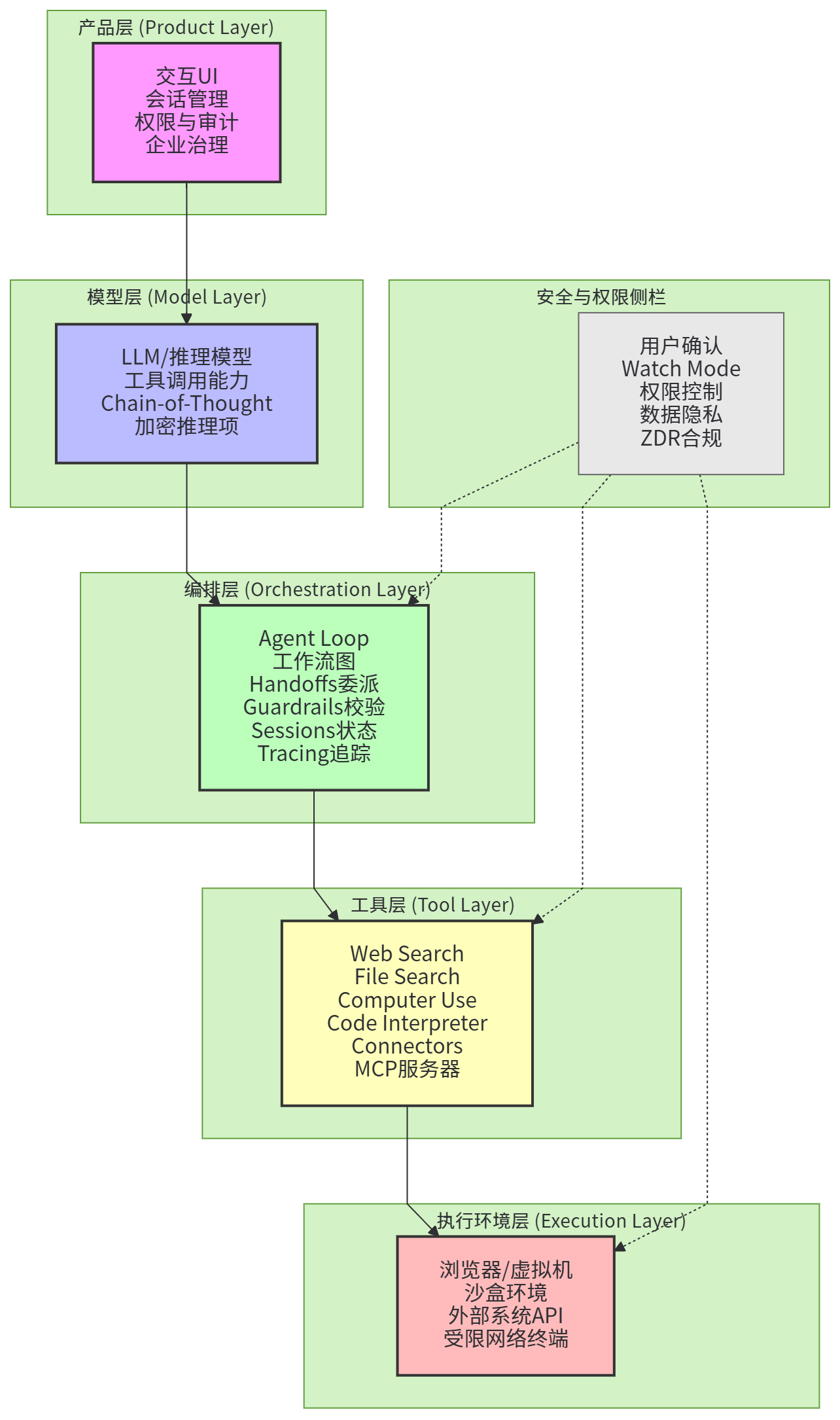
图1:2025通用ChatGPT Agent分层架构框架图
在这个分层框架中,最容易被低估但最关键的是“编排层”。很多人会把Agent理解为“更强的模型+更多工具”,但真正让系统可用的是编排层如何在工具之间组织信息、在失败时恢复、在风险动作前让用户确认、在输出前做安全检查、并记录完整轨迹以便复盘。Agents SDK把“agent loop”做成内建能力,并把guardrails、sessions、tracing作为核心原语,这反映的就是一种“编排优先”的设计哲学:把模型当成决策器,把工具当成行动空间,把编排当成控制系统。
3.2 Agent Loop:观察—推理—行动—反思的工程化闭环
通用Agent的最小运行单元可以抽象为一个循环:接收目标与上下文→生成下一步行动(可能是语言、也可能是工具调用)→执行行动→把结果纳入上下文→判断是否结束。这个闭环在2025年被进一步标准化:工具调用不再是“开发者强制指定”,而是模型在推理过程中主动决定是否调用,并可在多次调用后再产出最终答案。OpenAI在Responses API更新中强调o3和o4-mini等推理模型能够在Responses API里“直接在chain-of-thought中调用工具和函数”,并且可以在跨请求与工具调用中保留推理token,从而提升智能并降低成本与延迟。
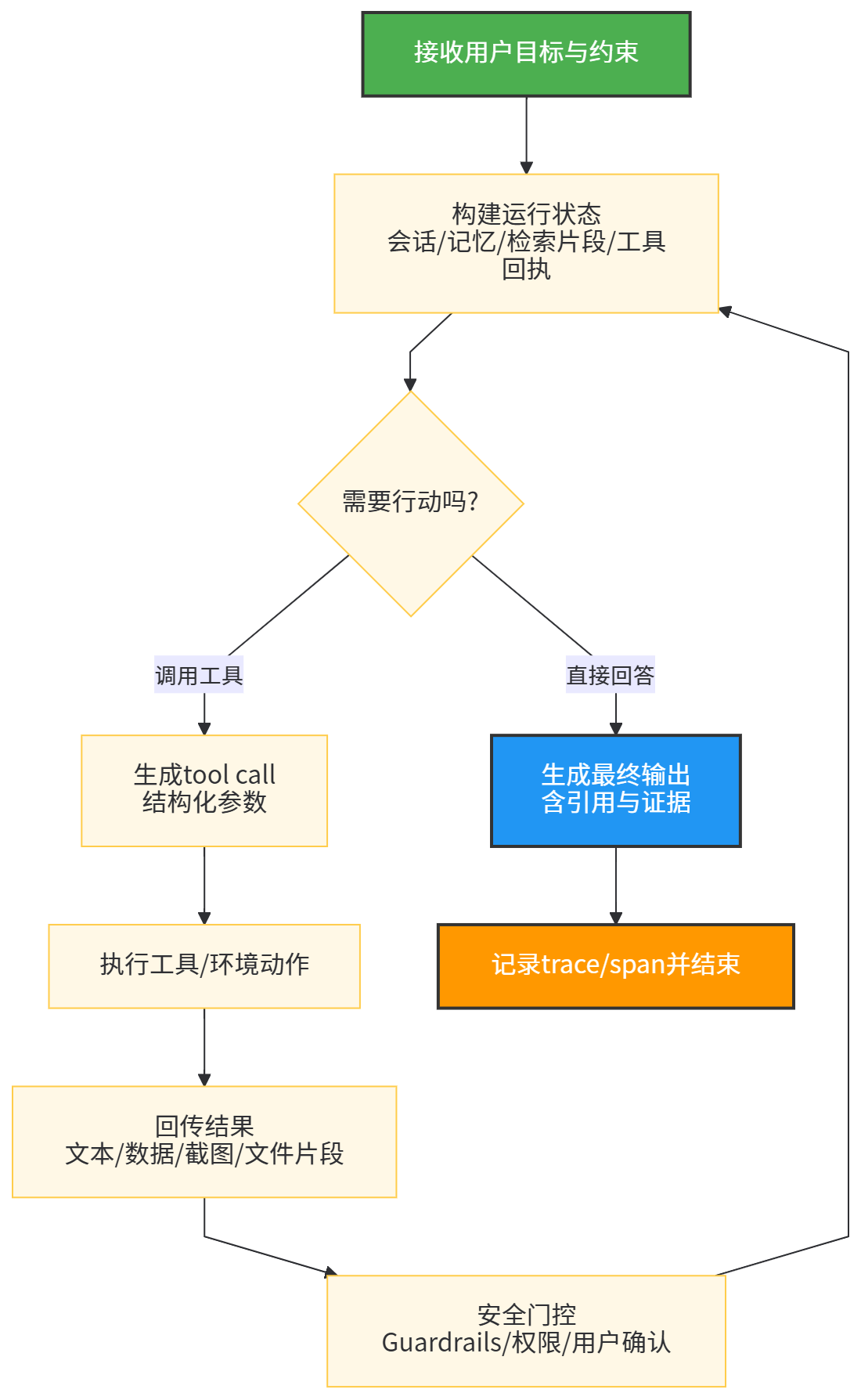
图2:Agent运行主循环
这张流程图背后其实是“Agent loop的职责边界”问题:哪些环节交给模型,哪些必须由系统强制执行。以computer use为例,模型可以提出点击坐标或输入文本,但真正执行动作的是你的代码/沙盒环境;模型可以提出“继续下一步”,但系统应在敏感动作前插入用户确认,或在检测到潜在prompt injection时强制进入watch mode。ChatGPT agent系统卡的风险缓解摘要中明确提到prompt injection场景下的多层缓解手段,包括自动监控与过滤、用户确认、敏感上下文下的watch mode、终端网络限制以及关闭记忆等。
3.3 运行对象:任务、会话、状态、轨迹与“可解释的中间层”
为了把Agent从“看起来很聪明”变成“可运营”,架构里必须有一套能被工程系统理解的运行对象。2025年OpenAI平台文档中,“会话”“工作流ID与版本”“工具调用对象”“trace与grader”等概念都被提升为平台级能力:Agent Builder发布工作流时会生成可版本化的工作流对象;ChatKit在前端嵌入聊天体验时会创建会话并以workflow作为后端;Responses API通过工具调用对象返回web_search_call、open_page、find_in_page等动作以及引用注释;Agents SDK内建tracing用来可视化与调试agentic flows。
一个很现实的经验是:如果你不显式维护这些对象,Agent系统就会退化成“巨大且不可控的提示词工程”。例如当用户说“帮我做个报表并发邮件”,系统至少需要区分“任务状态”(已找到数据/已生成表格/已确认收件人/已发送)、“权限状态”(是否登录/是否授权连接器/是否允许发送)、“工具状态”(某次调用失败原因、重试次数)、以及“证据状态”(哪些数据源被使用、是否带引用)。这些对象如果只存在于模型的隐式上下文里,就很难做可靠性治理;而当它们存在于编排层,就能与guardrails、重试策略、缓存、审计系统对接,从而形成真正的生产级Agent。
4 工具调用系统:从函数到“可见世界”的操作
4.1 工具分类:托管工具、函数工具、Agent工具、MCP服务器
2025年的Agent工具体系已经明显分层。OpenAI Agents SDK(JS/TS文档)把工具分成四类:托管工具(Hosted tools)、函数工具(Function tools)、Agent作为工具(Agents as tools)、本地MCP服务器(Local MCP servers)。托管工具运行在OpenAI服务器侧,典型包括web search、file search、computer use、code interpreter、image generation等;函数工具则是把本地函数包装成带JSON schema的可调用接口;Agent作为工具则把一个子Agent整体暴露为工具;MCP服务器工具则允许把运行在本机或远程的MCP server接入模型调用。
表1给出Agents SDK最小原语与其在架构中的位置,这些原语决定了很多工程系统的“天然边界”,例如handoff通常是多Agent协作的显式切换点,guardrails通常是成本控制与安全门控的插入点,sessions则是跨次运行的状态载体。
表1 Agents SDK核心原语与架构含义
| 原语 | 直观定义 | 架构作用 | 常见落点 |
|---|---|---|---|
| Agent | 带指令与工具的LLM | 决策器/策略执行者 | 领域专家Agent、路由Agent、总结Agent |
| Handoffs | Agent间委派机制 | 角色切换/分工协作 | “转人工/转专科”或多角色流水线 |
| Guardrails | 输入/输出校验与拦截 | 安全门控与质量保障 | PII遮罩、越狱检测、格式验证、风险动作拦截 |
| Sessions | 自动维护历史上下文 | 状态与记忆载体 | 多轮任务、长任务续跑、断点恢复 |
| Tracing | 内建可视化追踪 | 可观测与调试基础 | trace/span、评测、后续优化与审计 |
在工具层面,托管工具与本地工具的区别尤其关键:托管工具通常带有平台侧安全策略与统一计费,而本地工具意味着你需要承担更多安全责任,比如把浏览器或虚拟机沙盒化、避免泄露环境变量、限制文件系统访问等。computer use工具文档就明确建议使用沙盒环境,并列出降低风险的设置方法,例如在本地浏览器自动化时避免暴露宿主环境变量、禁用扩展与文件系统等。
4.2 托管工具清单:从搜索到终端的“可组合行动空间”
托管工具的价值不在于“种类多”,而在于它们为模型提供了稳定的行动原语,并将很多低层细节(如检索、引用、文件切片、沙盒执行)封装为可调用接口。Agents SDK文档列出的托管工具类型非常直观:web search、file search、computer use、shell、apply patch、code interpreter、image generation等,并指出这些参数集与Responses API保持一致。
表2 OpenAI托管工具类型与用途
| 工具类型(type string) | 典型用途 | 输出形态(常见) | 关键工程关注点 |
|---|---|---|---|
| web_search | 互联网实时检索并给出引用 | 搜索结果+引用注释 | 域名过滤、引用可追溯、上下文窗口约束 |
| file_search | 查询OpenAI托管向量库 | 命中文档片段 | 切片策略、过滤条件、多向量库搜索 |
| computer | GUI自动化(点击/输入/滚动) | 动作建议+截图回传 | 沙盒化、权限确认、误操作风险 |
| code_interpreter | 沙盒中运行代码做分析 | 计算结果/文件产物 | 资源限制、依赖管理、成本计费 |
| shell / local shell | 执行命令行操作 | stdout/stderr | 环境隔离、网络限制、敏感信息泄露 |
| apply_patch | 以diff形式修改文件 | patch应用结果 | 变更可审计、回滚策略 |
| image_generation | 生成或编辑图像 | 图像 | 内容安全、成本与速率限制 |
把这些工具组合起来,Agent系统就可以覆盖从“信息获取→信息处理→行动执行→结果交付”的完整链路:web_search负责面向开放互联网的最新信息,file_search负责面向企业或个人知识库的内部文档,computer use负责在GUI上完成跨站点的操作,code interpreter负责把数据加工成可复用产物(表格、图、报告)。这与ChatGPT agent系统卡中的能力描述是对应的:远程可视浏览器环境用于执行任务,终端工具用于数据分析与生成幻灯片/表格,连接器用于访问外部数据源。
4.3 Web Search:三种模式与“深度研究”化
在Agent架构中,web search不是“把搜索结果贴给模型”这么简单。OpenAI的web search工具指南明确区分了三种模式:非推理web search(模型不做内部规划,直接传递工具返回,速度快适合快速查找)、推理模型的agentic search(模型主动管理搜索过程、可多轮搜索与分析)、以及deep research(面向长程深入调查,可能访问数百来源,适合配合后台模式运行)。 这种分层意味着:同样是“搜索”,架构上需要支持不同的控制策略与预算模型。例如快速查找更像一次性工具调用,而深度研究更像一个独立的子工作流,需要有持续的状态、允许更长的执行时间,并且要把引用结构化返回以便产品层展示。
对于通用Agent而言,web search的“引用”能力是可信输出的关键组成部分。web search文档强调:当模型使用该工具时,输出会包含web_search_call项以及包含引用注释的message项,并要求在面向终端用户展示时必须让引用清晰可见且可点击。 这对应着一个重要的架构决策:把“证据链”作为输出的一部分,使得Agent不仅输出结论,还输出可追溯证据,从而降低幻觉风险并增强审计性。后文在“幻觉评测”章节会看到,通用Agent在启用浏览能力后,其准确率与幻觉率的关系会呈现更复杂的变化,这也提示了“引用机制+评测机制”必须共同设计,而不是单纯依赖模型自觉。
4.4 File Search与向量存储:知识外部化的主通道
与web search面向开放互联网不同,file search更像企业/个人知识系统的内循环。OpenAI在Responses API更新中指出file search使开发者可以基于用户查询把文档相关片段拉入上下文,并且还引入了跨多个向量存储搜索与支持属性过滤数组等更新;同时给出了明确的计费模型:向量存储按$0.10/GB/天计费,工具调用按$2.50/1000次计费。 这种计费方式会直接影响架构:你会更倾向于在编排层做“召回预算管理”,比如限制每次召回片段数量、对热门文档做缓存、把低价值文件从向量库中移除或降频更新。
在通用Agent架构里,file search不仅是“补充知识”,还是“长期记忆的外部化形态”。因为把记忆写进模型上下文有窗口限制,写进模型参数又不可控且成本巨大,因此把“可检索的记忆”写入向量库成为主流方案:会话摘要、关键事实、用户偏好、项目上下文都可以以结构化文档形式进入向量库,然后通过file search按需召回。值得注意的是,ChatGPT agent系统卡在风险缓解摘要中明确提到“ChatGPT的记忆被禁用”,这提示了一个非常现实的安全考量:当Agent具备连接器与多工具访问能力时,长期记忆可能带来敏感信息滞留与被攻击利用的风险,因此在某些产品形态下宁可牺牲记忆便利,也要优先降低风险面。
4.5 Computer Use:GUI行动空间与闭环反馈
Computer use把Agent能力从“调用API”扩展到了“操作真实软件界面”。OpenAI的Computer use指南把它定义为一个连续循环:模型提出动作(点击、输入等),你的代码执行动作并回传截图,模型据此继续提出下一步动作。 这种设计在理论上对应“观测o是截图/DOM,行动a是GUI操作”,在工程上则意味着你必须提供一个可截图、可执行动作、且最好沙盒化的环境(本地浏览器自动化或本地虚拟机)。更关键的是,GUI操作空间往往是高风险空间:误点“提交订单”、误触“删除文件”、或被网页中的prompt injection诱导执行非预期动作,都可能造成真实损失。因此系统必须引入权限控制与用户确认机制。
computer use工具文档中给出了一个非常具体的可靠性信号:computer-use-preview模型在OSWorld上的表现“目前为38.1%”,并提示这表明其对OS级任务自动化仍不够可靠。 这类数据对架构设计很重要,因为它提醒我们:当成功率远未达到接近100%的水平时,系统就必须假设“失败是常态”,因此要有可回退、可纠错、可中止的机制,例如在关键步骤要求用户确认、在失败后自动重试或切换策略、在长链路任务中分段提交中间产物等。
同时,computer-use-preview模型的计费与性能特征也会反过来塑造系统形态:官方模型页给出其输入输出价格分别为$3/$12(每百万token),上下文窗口8192,最大输出1024,并给出可锁定的snapshot版本(如computer-use-preview-2025-03-11)。 这意味着如果你的Agent大量依赖截图与多轮交互,token成本会显著上升,并且你需要通过“减少无效循环、压缩观测表示、在编排层做动作批处理或提前规划”来控制成本与延迟。
5 规划与推理:2025 Agent的核心算法栈
5.1 ReAct范式:推理痕迹与行动交织
2025年通用Agent的规划范式中,ReAct几乎是绕不开的基石之一。ReAct提出将“推理(Reasoning)”与“行动(Acting)”在同一条轨迹中交错:模型一边以自然语言进行逐步推理,一边调用工具获取新的信息,随后在新信息基础上继续推理与行动。其价值不只在于“能调用工具”,而在于把工具调用纳入推理链条,使得模型能够显式地表达“为什么需要调用某个工具、期待得到什么信息、得到信息后如何更新计划”。这正是Agent loop在工程上能稳定运行的原因之一:模型不再把工具当作外部黑箱,而是把工具结果当作推理中的证据。
在实际架构中,ReAct式轨迹往往会被编排层结构化:例如把“想法/行动/观察”分成不同字段或不同消息类型,把“行动”限定为tool call,把“观察”限定为tool result,把“想法”在需要时以推理摘要形式返回给开发者用于调试。OpenAI在Responses API更新中引入“reasoning summaries”,正是把这种“可解释的中间层”产品化的一种方式:开发者不必直接看到完整chain-of-thought,但可以得到可读的摘要来理解Agent为什么这样走。
5.2 Toolformer:让模型学会“何时用工具”的数据路径
如果说ReAct强调的是“推理与行动如何交错”,那么Toolformer关注的是“模型如何学会在合适的地方插入工具调用”。Toolformer提出一种自监督式方法:模型在文本中插入API调用、执行API获得结果,然后用结果增强文本并评估其对语言建模损失的改善,从而筛选出高价值的工具调用样本用于训练。其核心意义在于把“工具使用”从纯提示工程推进到“可学习的能力”,让模型不仅会格式化调用,还能在语义上判断调用是否值得。
对2025通用Agent架构而言,这类思想的影响是深远的:它促使我们把“工具使用能力”分成两部分,一部分是模型内化的策略(何时调用、调用什么、如何解释结果),另一部分是编排层提供的安全与结构(schema校验、权限门控、失败处理)。Agents SDK的function tools强调自动schema生成与验证,而Toolformer式训练则为“生成更靠谱的调用意图”提供了数据基础,这两者一内一外共同构成了工具调用可靠性的支柱。
5.3 Reflexion:把失败经验写回策略的迭代机制
在多步任务中,失败往往不是“模型不懂”,而是“模型在某一步做了不合适的假设或行动”。Reflexion提出通过语言形式的反思来进行“口头强化学习”:Agent在任务失败后生成对失败原因的反思,并把反思作为记忆写入下一次尝试,从而提升后续成功率。 这类机制对通用Agent架构的启示是:记忆不应只是事实缓存,也可以是策略层的“失败模式库”,例如“某网站按钮经常被误识别,需要先放大缩小再点击”“某类搜索结果容易出现SEO垃圾,需要加域名过滤”等。
不过,把Reflexion思路落地到2025的生产Agent时,必须与安全与隐私约束结合。ChatGPT agent系统卡提到“记忆被禁用”作为风险缓解手段之一,意味着在某些产品形态里,直接把反思写入长期记忆可能不被允许。 因此工程上的折中通常是“短期反思、任务级反思、或匿名化反思”:只在单次任务会话内保留反思;或把反思写成不包含敏感数据的抽象规则;或把反思交给开发者端的策略库而不是写回用户侧记忆。这样既能利用反思的迭代优势,又能控制风险面。
5.4 Voyager:技能库、自动课程与“可迁移的工具链”
Voyager展示了另一种更接近“长期成长”的Agent路线:在Minecraft环境中,Agent通过LLM驱动的规划与代码生成,不断探索、学习新技能,并把技能以可复用代码的形式写入技能库,同时自动生成新的探索目标形成课程。 虽然这类工作常被讨论为“未来应用”,但从架构角度看,它提供了一个非常实用的启示:当任务空间足够大时,Agent必须具备“把一次性轨迹压缩成可复用模块”的机制,否则每次都从零开始,成本与失败率都会难以接受。
把Voyager思想映射到2025的通用ChatGPT Agent架构里,这个“技能库”往往会以三种形态出现:第一种是工具封装层,把常用动作序列封装成高层工具(例如“登录并下载报表”作为一个函数工具);第二种是子Agent,把某类任务交给专门Agent并通过handoff或agents-as-tools调用;第三种是工作流模板,在Agent Builder中沉淀成可复用的节点图并版本化发布。Agent Builder支持从模板开始、拖拽节点、预览与版本化发布,这为“技能沉淀”提供了平台级承载。
5.5 规划的工程化折中:局部最优、可解释与可恢复
理论上你可以追求更全局的规划(例如把整个任务当作长程规划问题),但2025的生产经验往往更偏向“局部可解释、可恢复”的策略:把任务拆成若干可验证的里程碑,每一步都能产出可检查的中间结果,并在失败时能退回上一步重试。其原因很现实:工具调用成本存在、环境不确定性存在、模型成功率远非100%、而且安全门控要求在关键步骤停下来让用户确认。于是,架构上常见的折中是“计划—执行—校验”的循环,而不是“一次性全局计划再盲目执行”。这也解释了为什么Agent Builder强调typed edge、preview与inline eval,以及为什么Agents SDK强调tracing与guardrails:它们都是为“可恢复、可调试”的局部循环服务的。
6 记忆与知识:从短期上下文到长期外部化
6.1 会话记忆与长期记忆:生产系统更偏好“外部化”
在LLM Agent系统里,“记忆”常被误解为“把更多历史塞进上下文”。但2025年通用Agent的实践显示,真正稳定的方案往往是把长期记忆外部化:事实与文档进向量库,过程与轨迹进tracing系统,偏好与权限进产品配置或数据库,模型上下文只保留任务当前必需的信息。Agents SDK把sessions作为自动维护历史的机制,解决的是“会话内状态一致性”;而长期记忆则更适合用file search、vector store与外部数据库来承载。
ChatGPT agent系统卡提到“记忆被禁用”,从另一个侧面强化了外部化趋势:当Agent能访问连接器与多工具时,把敏感信息写入持久记忆会增加被攻击或误用的风险,尤其是prompt injection可能诱导Agent从记忆中泄露敏感数据。 因此生产架构更倾向于把“能否记住”从模型能力问题转化为“数据治理问题”:哪些信息可存、存在哪里、谁能读、何时过期、如何审计。
6.2 外部记忆的三件套:向量库、引用与可追溯证据
外部化记忆要真正发挥作用,至少需要三件套:第一是向量库/检索工具,保证“存进去能找出来”;第二是引用/证据机制,保证“找出来能被正确使用并可追溯”;第三是评测与监控,保证“长期使用不会逐渐偏离或被污染”。在OpenAI平台中,file search与web search分别覆盖内部知识与外部知识,且web search天然带引用注释要求;Responses API更新也强调了这些工具的可用性与企业级特性。
很多团队在落地时会发现:检索召回“相关”并不等于“可信”。因此引用机制与评测机制必须配套:引用让开发者与用户看到证据来源,评测让系统持续校正“引用是否真的支持结论”。这与ChatGPT agent系统卡中对幻觉评测的讨论相呼应:当Agent具备浏览能力时,它可能因为更“谨慎且深入”而在某些评分体系下得分更低(例如对评分基准本身提出质疑),这提醒我们评测指标与证据体系要一起设计。
6.3 记忆写入的安全边界:PII、越狱与数据泄露
通用Agent一旦开始“写记忆”,你就必须假设攻击者会尝试诱导它读出记忆或把记忆写成恶意指令。prompt injection风险在Agent场景被放大,因为Agent会主动访问网页、文件、连接器等外部内容,这些内容可能携带攻击指令。ChatGPT agent系统卡把prompt injection列为重点风险,并在风险缓解摘要中列出多层缓解策略,包括自动监控与过滤、用户确认、敏感上下文的watch mode、终端网络限制以及关闭记忆等。 这些措施共同指向一个原则:记忆与外部上下文不是“越多越好”,而是必须在安全边界内可控增长。
7 多Agent与工作流编排:从“一个大脑”到“团队协作”
7.1 Handoffs:委派机制与角色分工
多Agent并不是为了“看起来更智能”,而是为了解决两个结构性问题:第一是上下文与能力的分割,把不同领域的指令、工具与知识隔离,降低提示词互相污染;第二是控制流的可解释性,让系统能够明确记录“是谁做了哪一步决策”。Agents SDK把handoffs作为核心原语之一,并解释其用于让一个Agent把任务委派给另一个Agent,适合不同Agent分别处理订单、退款、FAQ等不同职责。
从架构角度看,handoff是一个天然的“审计点”:你可以在handoff前后插入安全检查、权限确认、或成本预算判断;你也可以在handoff时把输入输出结构化,避免把所有上下文无差别传给下游Agent。更进一步,handoff也可以与“agents as tools”结合:当你不希望完全转移控制权,而只是希望某个子Agent提供局部能力时,把子Agent当成工具调用会更合适。Agents SDK工具指南明确支持“Agents as tools”,并解释其底层会创建一个带单一input参数的function tool,调用时运行子Agent并返回其输出。
7.2 Agents as Tools:子Agent工具化的工程意义
“把子Agent当工具”本质上是在架构上引入一种可组合的函数式接口:主Agent不必知道子Agent的全部提示词与工具细节,只需要知道“调用它能得到某种结构化产出”。这种设计在2025年很常见,因为它兼顾了模块化与控制权:主Agent仍掌握主循环,子Agent只在被调用时运行。对于复杂任务,这有助于把系统拆成可测试的小模块,并用独立eval与grader分别评估每个模块的质量。
在实践中,agents-as-tools还有一个常被忽视的优势:它天然适配“typed edge”和“schema验证”。当子Agent工具被包装成带参数与输出格式的工具时,编排层就可以像对待普通函数工具一样做参数校验与错误处理。相比之下,如果你只是把子Agent当作“另一个聊天窗口”,则容易陷入上下文漂移与格式不稳定的问题。Agent Builder的节点化编排也在推动这种模式:节点之间的数据契约越明确,工作流越稳定。
7.3 Agent Builder:节点化编排、版本化发布与可调试运行
2025年Agent Builder把“工作流”概念平台化:你在画布里拖拽节点、连接节点、为每一步配置输入输出与工具,并可用Preview进行实时运行测试,最终发布为带ID与版本的工作流对象,然后在产品里部署。官方文档强调其三步流程:设计工作流、发布工作流(获得ID与版本化对象)、部署工作流(通过ChatKit或下载SDK代码自建)。 这种“版本化”对于生产系统极其关键:它允许你锁定某次上线的工作流形态,进行回溯与对照实验,也允许你在发现问题时快速回滚到旧版本。
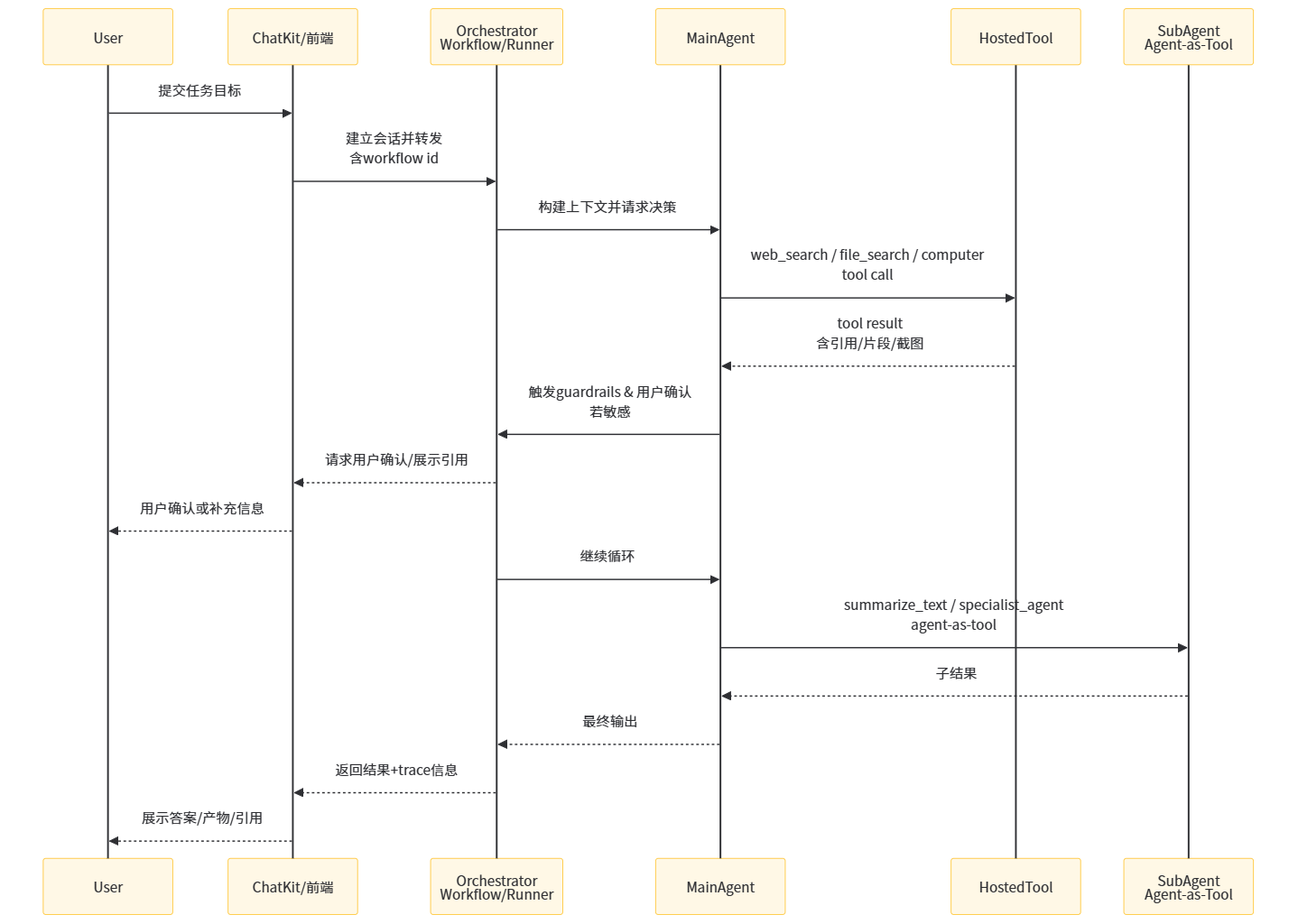
图3:工具调用与多Agent委派的时序图
7.4 ChatKit:托管后端与自托管后端的两种部署形态
Agent系统的强调点往往在后端,但2025年的平台化趋势让“前端部署形态”也成为架构的一部分。ChatKit文档把它定位为构建agentic chat体验的最佳方式之一,强调其提供可嵌入UI组件、工具调用可视化、文件附件、以及chain-of-thought可视化等能力,并给出两种实现方式:推荐方式是前端嵌入ChatKit并让OpenAI托管并扩展Agent Builder构建的后端;高级方式是你在自有基础设施上运行ChatKit并连接任意agentic后端。
表3 ChatKit托管后端 vs 自托管后端
| 维度 | OpenAI托管后端(Agent Builder工作流) | 自托管后端(自建Agents SDK或其他编排) |
|---|---|---|
| 适用场景 | 最快上线、减少基础设施运维 | 最大控制权、定制工作流与数据路径 |
| 聊天服务端运行者 | OpenAI | 你 |
| 消息与附件存储 | OpenAI | 你 |
| 推理流水线 | Agent Builder发布的workflow | Agents SDK或自研 |
| 认证方式 | 你先完成认证,再铸造短时client secret | 你可自定义fetch注入认证头等机制 |
| UI定制/附件/历史/小组件 | 支持 | 支持 |
| 额外能力(如Composer、响应取消等) | 文档列出差异项 | 取决于你实现与集成 |
这张表的意义在于,它把“Agent是产品”这个事实拉到台前:你不只是在调一个模型接口,而是在建设一个带会话、权限、数据存储、UI与审计能力的应用。对于企业场景,选择托管还是自托管,往往取决于数据治理与合规要求;而对于个人或中小团队,托管后端能显著降低从原型到上线的摩擦。OpenAI在AgentKit发布中也强调Agent Builder、Connector Registry与ChatKit等组件的组合,目的是减少碎片化工具带来的复杂度。
8 可观测性与评测:从“能跑”到“可衡量”
8.1 Tracing与Trace Grading:把每一步变成可审计事件
当Agent系统开始做多步执行,你很快会遇到一个现实问题:它失败时,你不知道到底是哪一步出错;它成功时,你也不知道为什么成功。这就是可观测性的价值。Agents SDK把tracing作为内建能力,强调可视化与调试agentic flows,并可用于评估与模型优化。 更进一步,Agent Builder文档提到可以在Agent Builder内部运行trace graders进行工作流评测,把评测与调试集成到同一个界面里。
这种设计在架构上意味着:Agent的“中间态”必须被结构化记录,包括每次工具调用参数、工具返回值摘要、guardrails判定结果、用户确认点、以及最终输出与引用。只有当这些事件能被串成可视化的trace,才可能做系统性优化,例如定位某类失败集中发生在“检索召回不足”还是“GUI误点”,或发现某个guardrail过于严格导致过度拒答等。ChatGPT agent系统卡中的评测讨论就提供了一个典型例子:在某些评测中出现“错误的拒答”会被计为错误,从而影响准确率,这种现象如果没有trace很难定位其触发条件。
8.2 学术基准:WebArena、VisualWebArena、OSWorld、GAIA等
通用Agent的评测越来越强调“交互环境”而不是静态问答。WebArena提供一个更真实的网页环境,用于评估自主Web代理的能力,包含812个任务。 VisualWebArena进一步面向多模态网页任务,包含910个视觉复杂的web任务。 OSWorld面向操作系统层面的真实桌面环境任务,包含369个真实计算机任务,并报告当时最强模型在完整任务上的成功率约12.24%。 GAIA(General AI Assistants)强调现实世界助手任务的综合能力,包含466个问题,并在论文中报告在不受限设置下最佳模型可达92%成功率,而“GPT-4 with plugins”约15%。 这些基准共同推动了2025年Agent架构向“可交互环境闭环”演进:不仅要会推理,还要会行动与纠错。
表4 代表性Agent评测基准的规模与特点(真实数据汇总)
| 基准 | 环境类型 | 任务/问题数量(论文披露) | 核心评估点 | 典型观测/行动 |
|---|---|---|---|---|
| WebArena | 真实Web环境 | 812 | 多步网页导航与信息获取 | DOM/文本;点击/输入/导航 |
| VisualWebArena | 多模态Web环境 | 910 | 视觉界面理解与网页操作 | 截图+结构;点击/输入/滚动 |
| OSWorld | 操作系统桌面环境 | 369 | OS级任务自动化与鲁棒性 | 截图/窗口状态;鼠标键盘操作 |
| GAIA | 现实世界助手任务 | 466 | 跨域推理、检索、工具使用 | 文本+外部工具;多步推理 |

图4:基准规模对比柱状图
这些基准的共同点是“任务链路长、环境噪声大、失败模式多”,因此也更能暴露Agent系统工程问题。例如OSWorld论文指出最强模型在完整任务上的成功率只有12.24%,这意味着“失败是常态”,必须设计重试与恢复。 而OpenAI的computer use文档给出的38.1% OSWorld表现,则体现了专门化模型与工程优化带来的提升空间,但也同样提醒我们距离“可无人值守执行OS任务”仍有明显差距。
8.3 用真实数据理解“可靠性”:幻觉、语言覆盖与偏差
学术基准主要衡量任务成功率,但生产级Agent还必须面对安全、幻觉、语言覆盖与公平性等指标。ChatGPT agent系统卡在这方面提供了大量可量化数据,例如在生产安全基准(Production Benchmarks)中,用not_unsafe作为指标,分别在非暴力仇恨、隐私、威胁骚扰、性/非法内容、未成年人性内容、极端主义、自伤等类别给出ChatGPT agent与OpenAI o3的对比。
表5 生产安全基准:not_unsafe指标对比
| 类别 | 指标 | ChatGPT agent | OpenAI o3 |
|---|---|---|---|
| 非暴力仇恨 | not_unsafe | 0.926 | 0.840 |
| 个人数据(所有隐私类别) | not_unsafe | 0.932 | 0.925 |
| 骚扰/威胁 | not_unsafe | 0.803 | 0.672 |
| 性/非法 | not_unsafe | 0.891 | 0.833 |
| 未成年人性内容 | not_unsafe | 0.854 | 0.779 |
| 极端主义 | not_unsafe | 0.989 | 0.920 |
| 仇恨/威胁 | not_unsafe | 0.891 | 0.746 |
| 非暴力非法 | not_unsafe | 0.826 | 0.739 |
| 暴力非法 | not_unsafe | 0.933 | 0.838 |
| 自伤意图 | not_unsafe | 0.908 | 0.866 |
| 自伤指令 | not_unsafe | 0.947 | 0.894 |
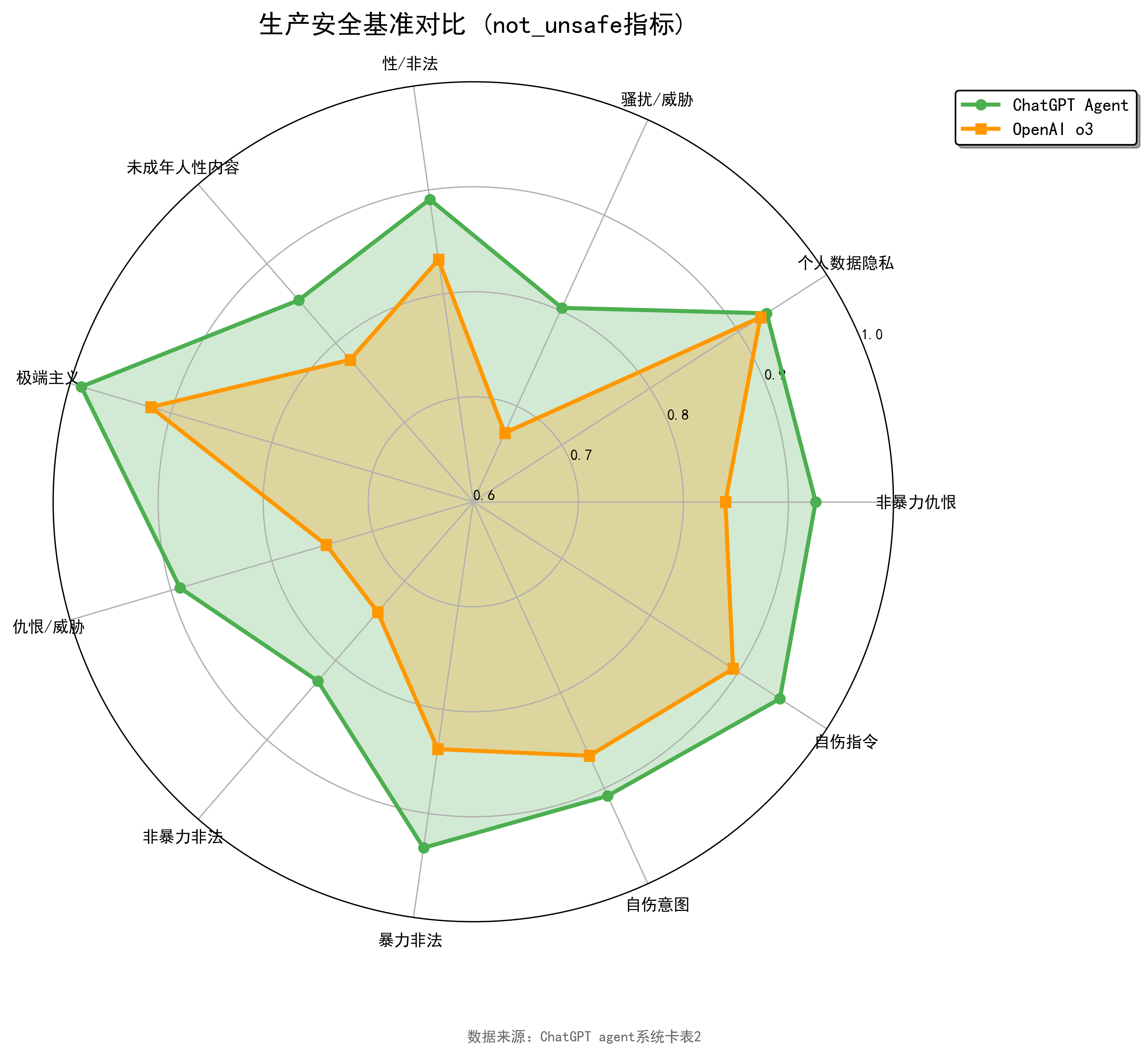
图5:生产安全基准雷达图
在幻觉方面,系统卡用SimpleQA与PersonQA给出准确率与幻觉率的对比,并指出由于ChatGPT agent总能浏览互联网,因此比较对象是“启用浏览的o3”。
表6 幻觉评测:准确率与幻觉率
| 评测 | 指标 | ChatGPT agent | OpenAI o3(启用浏览) |
|---|---|---|---|
| SimpleQA | 准确率(越高越好) | 0.914 | 0.954 |
| SimpleQA | 幻觉率(越低越好) | 0.079 | 0.046 |
| PersonQA | 准确率(越高越好) | 0.943 | 0.966 |
| PersonQA | 幻觉率(越低越好) | 0.043 | 0.024 |
在多语言覆盖方面,系统卡给出ChatGPT agent与deep research在多种语言上的通过率/准确率数据,这些数据非常适合用来讨论“多语言下性能退化是否显著”以及“工具增强是否影响语言差异”。
表7 多语言表现
| 语言 | ChatGPT agent | Deep research |
|---|---|---|
| English | 0.572 | 0.580 |
| Arabic | 0.568 | 0.550 |
| Bengali | 0.567 | 0.547 |
| Chinese | 0.575 | 0.545 |
| French | 0.579 | 0.566 |
| German | 0.590 | 0.585 |
| Hindi | 0.581 | 0.582 |
| Indonesian | 0.585 | 0.564 |
| Italian | 0.588 | 0.554 |
| Japanese | 0.566 | 0.556 |
| Korean | 0.560 | 0.566 |
| Portuguese | 0.588 | 0.575 |
| Russian | 0.599 | 0.542 |
| Spanish | 0.575 | 0.583 |
| Swahili | 0.578 | 0.550 |
| Turkish | 0.564 | 0.546 |
| Vietnamese | 0.584 | 0.571 |
| Yoruba | 0.473 | 0.426 |
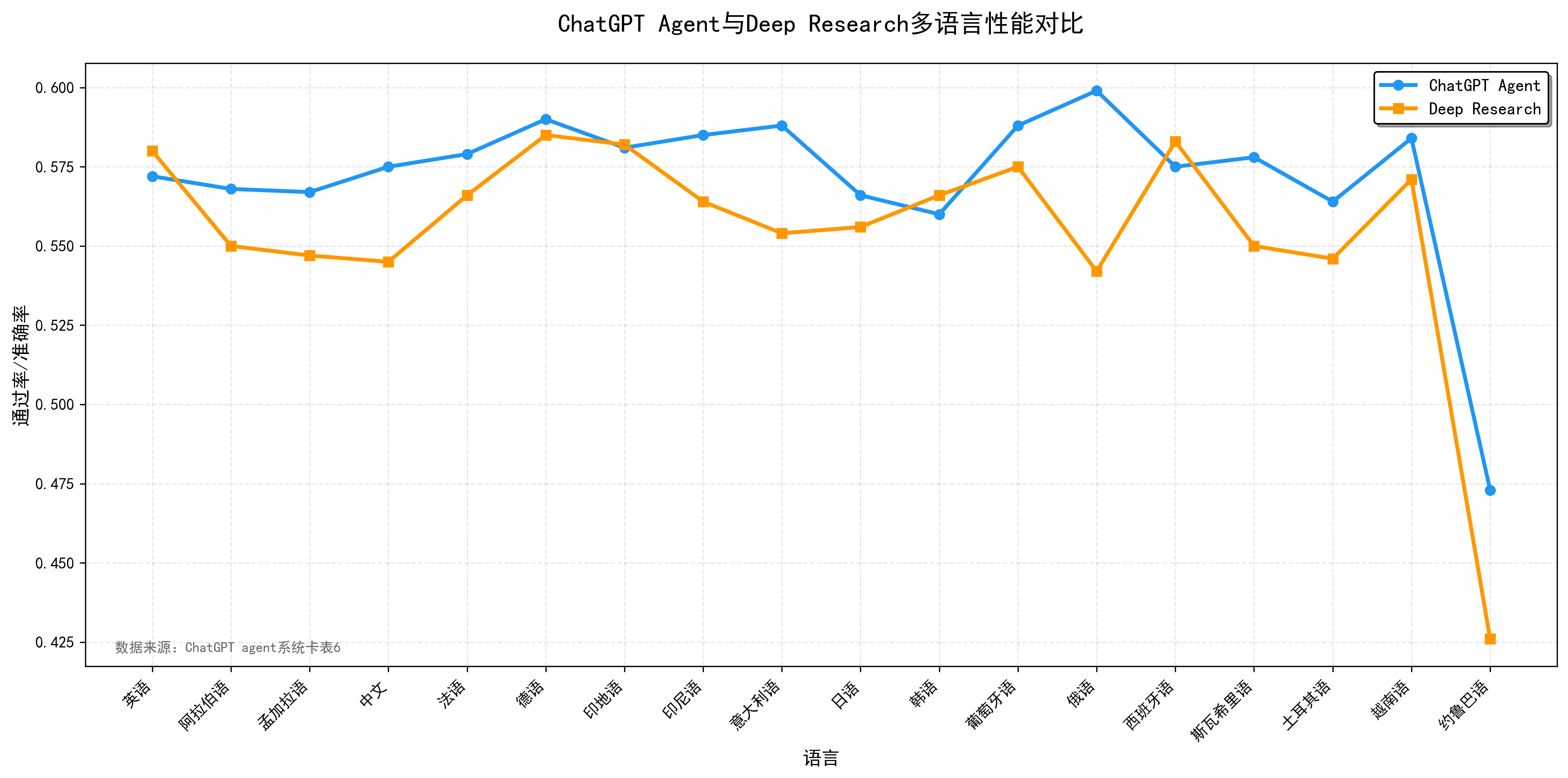
图6:多语言表现折线图
这些真实数据对“通用Agent架构”的意义在于,它们把架构讨论从抽象概念拉回可量化指标:你不仅要设计工具系统与工作流,还要能用指标解释“为什么某次迭代更安全、更少幻觉、更公平、更能覆盖多语言”,并且能通过trace把变化定位到具体节点或具体工具调用策略上。
9 安全、权限与抗攻击:Agent能力放大后的系统工程
9.1 Prompt Injection:从文本攻击到工具劫持
Prompt injection在Agent时代的破坏力远超过传统聊天:攻击不再只是诱导模型“说错话”,而可能诱导模型“做错事”。当Agent会浏览网页、读取文件、连接企业系统时,网页内容或文件内容中嵌入的恶意指令可能试图覆盖系统目标,导致数据外泄、误操作或错误结论。ChatGPT agent系统卡明确把prompt injection作为重点风险,并指出其影响可能更高,因为Agent可同时访问更多工具。 这也是为什么通用Agent架构必须把“输入可信度”当成系统级问题,而不是只靠模型“更聪明”来解决。
在架构上,prompt injection防护通常分成三层:第一层是模型层的安全训练与对抗鲁棒性;第二层是编排层的自动监控与过滤、对敏感工具调用做门控;第三层是产品层的用户确认与可视化监督。系统卡的风险缓解摘要恰好覆盖了这三层,并且提到在敏感上下文下启用“watch mode”,以及对终端工具实施网络限制。 这为“通用Agent架构”提供了一个非常清晰的安全设计模板:你必须假设模型会被诱导,因此要在系统里预留“强制中断与人工介入”的机制。
9.2 用户确认与watch mode:把高风险动作变成“可逆决策”
在GUI操作、连接器访问、或任何可能造成不可逆后果的动作前,用户确认是最简单也最有效的风险缓解方式之一。其价值在于把“不可逆动作”变成“可逆决策”:模型可以提出行动计划,但最终执行权交给用户确认。系统卡把用户确认与watch mode列为prompt injection缓解的重要组成部分,同时也用于防止Agent犯错或在该确认时未确认。 在架构上,这意味着Agent loop必须支持“暂停—等待确认—恢复”的状态机,不能把执行当成一条不可打断的流水线。
9.3 终端网络限制、加密推理项与企业隐私
当Agent拥有终端/代码环境时,风险面进一步扩大:终端可能访问网络、读取本地文件、暴露环境变量,甚至被用来执行非预期操作。系统卡提到“终端网络限制”作为风险缓解措施之一。 同时Responses API更新引入“加密推理项”,并说明符合零数据保留(ZDR)的客户可以在不把推理项存储在OpenAI服务器的情况下复用推理项,从而提升智能并减少成本与延迟。 这类能力背后的架构意义是:企业级Agent不仅要“能做事”,还要在数据治理上提供可配置的隐私边界,并支持在隐私约束下仍能获得足够的推理连续性。
9.4 安全评测:从越狱到指令层级
安全不是口号,而需要评测。系统卡在越狱鲁棒性方面给出了StrongReject评测对比,并显示ChatGPT agent与o3在多类越狱提示上的not_unsafe都接近1.0。 同时还评估了“指令层级”相关能力,例如系统与用户消息冲突下是否能坚持系统指令、是否会泄露系统提示等。 这些评测直接对应到通用Agent架构中的“指令治理”层:你需要明确系统/开发者/用户/工具输出的优先级,并用机制防止网页内容等外部输入越权。
10 成本、延迟与资源治理:把“智能”落在可运营的约束里
10.1 Token成本、工具成本与计费模型
通用Agent的成本模型比传统聊天复杂得多:不仅有模型token成本,还有工具调用成本、向量存储成本、代码沙盒容器成本等。Responses API更新给出了多项工具成本:code interpreter $0.03/容器,file search $0.10/GB/天 + $2.50/1000次工具调用,图像生成按token与图像token计费,并指出调用远程MCP server工具本身无额外费用(主要计输出token)。 computer-use-preview模型页则给出其token价格(输入$3、输出$12/百万token)。
表8 2025年OpenAI通用Agent常见成本项
| 成本项 | 计费方式(文档披露) | 典型影响 | 架构应对方向 |
|---|---|---|---|
| computer-use-preview | $3/$12(每百万token输入/输出) | 多轮截图交互成本高 | 降低无效循环、压缩观测、拆分任务 |
| Code Interpreter | $0.03/容器 | 频繁开容器会累积 | 复用容器、把计算集中处理 |
| File search | $0.10/GB/天(存储) + $2.50/1000次调用 | 大规模知识库持续成本 | 分层存储、冷热分离、缓存召回 |
| Image generation(工具) | 文档给出按token/图像token计费 | 生成与编辑成本差异大 | 只在必要时调用、控制分辨率与轮次 |
| 远程MCP server工具 | 无额外工具费(主要计输出token) | 连接外部系统更便利 | 工具输出结构化、减少冗余返回 |
成本治理与架构设计高度耦合:如果你的Agent loop没有“预算意识”,系统就会在不知不觉中产生大量工具调用与token消耗。Responses API更新提到推理模型在工具调用中保留推理token可以降低成本与延迟,这实际上是在平台层面提供一种“跨步推理缓存”,使得多步工具链不必每次从零开始推理。
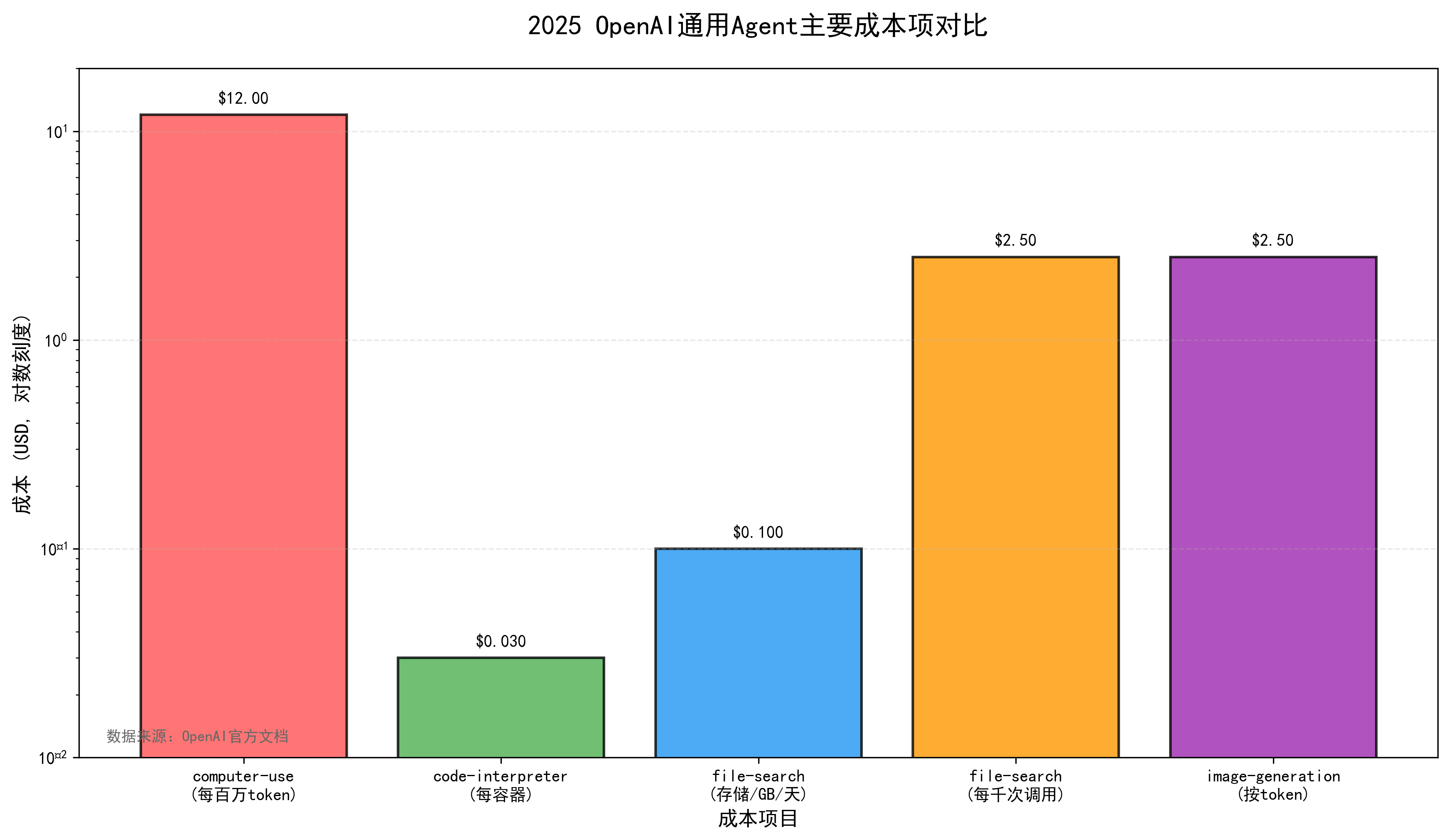
10.2 背景模式:长任务的可靠执行方式
通用Agent最典型的失败不是“答错”,而是“超时”或“中途断线”。OpenAI在Responses API更新中引入background mode,明确其适用于推理模型需要数分钟才能完成的复杂任务,并允许开发者异步执行、轮询或流式追踪进度。 这对架构的意义是:Agent系统需要支持“可中断、可续跑”的任务对象,并把中间状态写入可持久化的会话/工作流状态,而不是仅靠一次HTTP请求完成全部任务。
11 2025生态与标准化:MCP、连接器与“可组合工具链”
11.1 MCP:上下文与工具接入的标准化接口
当Agent要连接越来越多的外部系统时,如果每个系统都用私有协议,生态就会碎片化。Responses API更新明确宣布支持所有远程MCP服务器,并把MCP描述为“标准化应用向LLM提供上下文的开放协议”;同时表示OpenAI加入MCP的steering committee。 这意味着2025年的通用Agent架构正在走向“工具即接口、接口即生态”:开发者不必为每个SaaS写一套定制function schema,而可以通过MCP服务器统一暴露工具能力,并在Agent编排层以一致方式调用。
从架构角度看,MCP的价值在于把“工具定义、权限、上下文注入”从应用内代码迁移到一个可治理的中间层:企业可以用Connector Registry统一管理哪些数据源能被Agent访问,管理员可以集中控制连接器与第三方MCP的接入策略。AgentKit发布文档提到Connector Registry作为中央管理面板,覆盖ChatGPT与API,并包含Dropbox、Google Drive、SharePoint、Microsoft Teams以及第三方MCP等。
11.2 AgentKit:从SDK到可视化平台的闭环
2025年10月OpenAI发布AgentKit,将Agent Builder、Connector Registry与ChatKit组合成“构建—部署—优化”的完整工具链,并强调它是为了解决过去构建Agent需要编排、连接器、手工评测与前端开发等碎片化问题。 平台文档也把AgentKit定义为模块化工具包,覆盖构建、部署与优化,强调评测、trace grading、prompt optimizer等能力。 对通用Agent架构而言,这意味着最佳实践正在平台化:不只是给你一个模型,而是给你一套从工作流设计到上线运维的基础设施。

图7:Agent Builder工作流与Trace/Grader闭环示意图
12 结语:通用Agent架构的稳定内核
回看2025年的通用ChatGPT Agent架构,不难发现其“稳定内核”并不神秘:它是一套把LLM从语言生成器升级为决策器的系统工程方法。底层是可交互环境与工具集合,中间是显式编排与状态管理,上层是可观测、可评测、可治理的产品化闭环。工具调用让Agent获得行动能力,工作流图让复杂控制流显式化,可观测与评测让系统具备持续优化的可能,而安全与权限机制则为能力放大设置了必要的边界。OpenAI在2025年一系列文档与系统卡中给出的数据与机制(如生产安全基准、幻觉评测、多语言表现、prompt injection缓解、后台模式、加密推理项、MCP支持等)共同勾勒出一个清晰方向:通用Agent的竞争,不再只是“模型更强”,而是“系统更稳、更可控、更可运营”。
参考资料(精选)
-
OpenAI. ChatGPT agent System Card(2025-07-17).
-
OpenAI. New tools and features in the Responses API(2025-05-21).
-
OpenAI. OpenAI Agents SDK(Python)文档:核心原语与内建agent loop/tracing.
-
OpenAI. Agents SDK Tools(JS/TS)文档:工具四分类与托管工具清单.
-
OpenAI. Web search tool guide:非推理检索/agentic search/deep research三种模式与引用机制.
-
OpenAI. Computer use tool guide:循环执行机制与安全建议,OSWorld表现提示.
-
OpenAI. computer-use-preview model page:价格、上下文窗口、snapshot版本信息.
-
OpenAI. Introducing AgentKit(2025-10-06).
-
OpenAI. Agents / Agent Builder / ChatKit 平台文档(工作流、部署与优化).
-
Yao et al. ReAct: Synergizing Reasoning and Acting in Language Models(arXiv, 2022).
-
Schick et al. Toolformer: Language Models Can Teach Themselves to Use Tools(arXiv, 2023).
-
Shinn et al. Reflexion: Language Agents with Verbal Reinforcement Learning(arXiv, 2023).
-
Park et al. Generative Agents: Interactive Simulacra of Human Behavior(arXiv, 2023).
-
Wang et al. Voyager: An Open-Ended Embodied Agent with Large Language Models(arXiv, 2023).
-
WebArena: A Realistic Web Environment for Building Autonomous Agents(任务812,arXiv).
-
VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks(任务910,arXiv/项目页).
-
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments(任务369,最佳模型成功率12.24%等,arXiv).
-
GAIA: a benchmark for General AI Assistants(问题466,成功率对比等,arXiv).
-
AgentBench: Evaluating LLMs as Agents(arXiv).
-
StableToolBench: Towards Stable Large-Scale Benchmarking on Tool Learning(Findings of ACL 2024).
-
Tool Learning with Large Language Models: A Survey(arXiv, 2024).


















 1042
1042

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











