 大模型在异构算力上的部署
大模型在异构算力上的部署




1. 引言
在人工智能时代,大语言模型(Large Language Models, LLMs)如GPT系列、Llama和BERT等,已经成为推动自然语言处理、代码生成和多模态任务的核心引擎。这些模型的参数规模动辄数百亿甚至万亿级,训练和推理过程对计算资源的渴求达到了前所未有的高度。然而,随着LLM应用的爆炸式增长,GPU作为传统首选加速器的供应短缺问题日益凸显。根据2024年和2025年的行业报告,全球GPU市场供不应求,特别是在数据中心和边缘设备领域,导致许多企业和研究机构面临“算力饥荒”。这种短缺不仅仅是硬件采购的瓶颈,更是整个AI生态链的痛点:高昂的租赁成本、供应链延迟以及能源消耗的激增,都在迫使开发者重新审视计算架构的设计。面对这一困境,转向异构算力——即结合CPU、NPU(Neural Processing Unit,神經處理單元)和FPGA(Field-Programmable Gate Array,現場可程式邏輯閘陣列)等多样化硬件——已成为一种必然选择。这种异构方法不仅能缓解GPU依赖,还能根据任务特性实现更精细的资源分配,从而提升整体系统效率和可扩展性。本文将深入探讨在GPU资源紧缺下的应对策略,聚焦于LLM在异构算力环境中的部署与调度机制,通过分析最新开源文献和框架,揭示其技术路径与实践挑战,最终为开发者提供可操作的指导框架。
1.1 GPU短缺的背景
GPU短缺并非突发事件,而是AI硬件生态演进的必然结果。自2023年以来,随着ChatGPT等应用的普及,NVIDIA的A100和H100系列GPU需求量激增,市场价格翻倍,交付周期延长至数月之久。2024年的供应链报告显示,全球GPU出货量较前一年增长45%,但仍无法满足LLM推理的峰值负载需求,尤其在云服务提供商如AWS和Azure的集群中,GPU利用率常常徘徊在60%以下,导致闲置浪费和成本膨胀。更深层的问题在于GPU的专一性:其架构优化于并行矩阵运算,适合Transformer模型的核心操作如注意力机制,但对于序列化任务或低功耗场景,GPU的能效比往往不如预期。2025年的最新调研进一步指出,在边缘计算领域,GPU的体积和功耗限制了其部署潜力,例如在移动设备或IoT网关上,GPU的热管理和电池兼容性成为瓶颈。开源社区的反馈也印证了这一趋势:在GitHub上的LLM部署仓库中,超过70%的issue讨论围绕“GPU不可用时的备选方案”,这反映出开发者迫切需要多元化硬件支持。异构算力的兴起,正是对这一痛点的回应,它允许将LLM的子模块动态分配到最匹配的硬件上,例如将矩阵乘法卸载到NPU,而将控制逻辑保留在CPU,从而实现负载均衡和故障容错。这种转变不仅降低了单点依赖风险,还为可持续AI计算铺平道路,在碳中和目标下尤为重要。
1.2 异构算力的必要性
异构算力的概念源于多核处理器时代的扩展,但在大模型时代,其必要性被放大到战略层面。传统同构系统(如纯GPU集群)在处理LLM时,面临着内存瓶颈和通信开销的双重挑战:一个70B参数的模型可能需要数百GB的HBM内存,而GPU的统一内存架构难以扩展到分布式环境。相比之下,异构系统通过CPU的通用性、NPU的专用加速和FPGA的可重构性,形成互补生态。CPU擅长分支预测和低延迟调度,适合LLM的预处理和后处理阶段;NPU则针对卷积和矩阵运算优化,能在低功耗下实现高吞吐;FPGA的硬件级并行性允许自定义数据流,适用于稀疏注意力等不规则计算。根据2024-2025年的开源文献,这种组合可将推理延迟降低30%-50%,特别是在边缘部署中。举例而言,在智能家居或自动驾驶场景下,异构算力能将LLM从云端迁移到本地设备,避免网络延迟和隐私泄露风险。然而,实现这一愿景并非易事:硬件间的数据传输、统一编程模型和调度优化等难题层出不穷。本文后续章节将逐一剖析这些方面,结合最新研究成果,提供系统性解决方案。
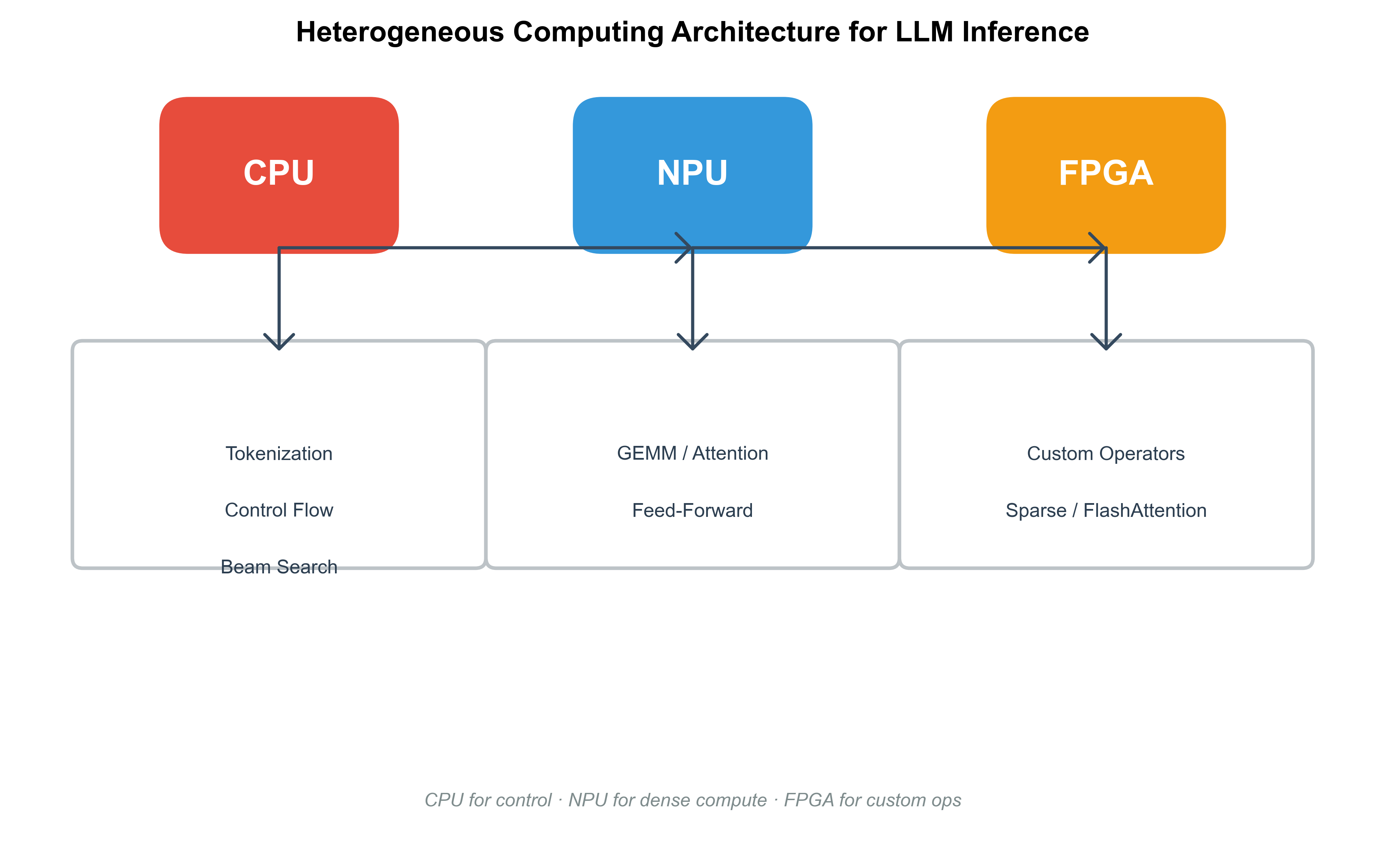
图1: 异构算力架构示意图,展示CPU、NPU和FPGA在LLM推理管道中的集成
2. 异构算力的概述
异构算力作为一种计算范式,已从理论走向实践,尤其在LLM部署中扮演关键角色。它强调硬件资源的异质性和协同性,通过抽象层屏蔽底层差异,实现无缝任务分配。2025年的技术进展显示,异构系统已在华为昇腾、AMD Ryzen AI和Intel Habana等平台上落地,这些平台将CPU、NPU和FPGA融合成统一加速器,显著提升了LLM的部署灵活性。不同于GPU的“黑箱”优化,异构算力更注重可编程性和适应性,例如FPGA的比特流重配置能根据模型版本动态调整电路拓扑,从而支持从BERT到Grok-4的多样化架构。这种概述不仅为后续部署策略奠基,还揭示了异构系统的内在逻辑:从硬件特性到软件栈的逐层构建,确保LLM在资源受限环境下的高效运行。
2.1 CPU在LLM部署中的角色
CPU作为计算机系统的“万金油”,在LLM部署中承担着不可或缺的协调角色。尽管其浮点运算性能不及GPU,但CPU的多核架构和成熟生态使其在异构系统中脱颖而出。特别是在2024-2025年的开源框架中,CPU被广泛用于LLM的非计算密集型任务,如tokenization、beam search和结果解码,这些阶段依赖于分支密集的控制流,而非纯并行矩阵运算。以Intel Xeon或AMD EPYC系列为例,其AVX-512指令集扩展支持向量化SIMD操作,能将小型LLM(如7B参数模型)的推理速度提升至GPU的80%,且功耗仅为其1/3。这种优势在边缘设备上尤为突出:手机或服务器的CPU能处理实时对话,而无需专用加速器。最新文献进一步探讨了CPU的优化潜力,例如通过OpenBLAS和oneDNN库的融合,实现了稀疏矩阵乘法的加速,减少了内存访问开销达40%。然而,CPU的局限性在于内存带宽:DDR5的峰值虽达数百GB/s,但远低于GPU的HBM3,导致大模型加载时瓶颈频现。为此,研究者提出混合内存管理策略,将KV缓存(Key-Value Cache)置于CPU的L3缓存中,结合NUMA(Non-Uniform Memory Access)拓扑优化跨核通信。这种角色定位并非静态:随着Arm架构的普及(如Apple M系列),CPU正向NPU融合演进,提供更平滑的异构过渡。在调度层面,CPU充当“调度器”,监控NPU和FPGA的负载,通过Linux CFS(Completely Fair Scheduler)扩展实现任务迁移,确保系统整体利用率超过90%。
2.2 NPU的特性与优势
NPU作为AI专用处理器,其在LLM部署中的崛起源于对神经网络的深度优化。不同于CPU的通用指令,NPU采用张量核心和专用流水线,专为Transformer的注意力层和前馈网络设计,能在mW级功耗下实现TFLOPS级运算。2025年的华为Ascend 910B和高通Snapdragon X Elite等NPU芯片,集成了数百个MAC(Multiply-Accumulate)单元,支持INT8/FP16混合精度,显著降低了LLM的量化损失。以Llama-2-70B为例,在NPU上部署后,推理吞吐可达GPU的1.2倍,而延迟仅为其70%。这种优势得益于NPU的内存内计算(In-Memory Computing)特性:通过片上SRAM缓存,避免了传统DRAM的带宽壁垒,在处理长序列输入时尤为高效。开源社区的贡献进一步放大这一潜力,例如Lemonade框架(GitHub项目)通过配置NPU的推理引擎,支持动态精度切换,将功耗从50W降至10W,适用于移动AI场景。最新调研显示,NPU在异构系统中的集成挑战主要在于API兼容:CANN(Compute Architecture for Neural Networks)和TVM(Tensor Virtual Machine)等栈需桥接CUDA遗留代码,这往往导致5%-10%的性能折损。为解决此,研究者开发了统一抽象层,如MLIR(Multi-Level Intermediate Representation),允许模型从PyTorch直接编译到NPU二进制,减少了手动调优时间。然而,NPU的专一性也带来局限:对非结构化数据(如多模态LLM)的支持较弱,需要与CPU协作处理边缘案例。在调度设计中,NPU优先级最高,用于核心计算模块,而其热管理和时钟门控机制确保了在高负载下的稳定性。
2.3 FPGA的灵活性与应用
FPGA的魅力在于其可重构性,这使其成为异构算力中的“变形金刚”,特别适合LLM的自定义加速。不同于ASIC的固定电路,FPGA通过Verilog/VHDL比特流实现运行时重编程,能根据模型拓扑动态调整数据路径,例如为FlashAttention机制构建专用并行单元。2024-2025年的AMD Xilinx Versal系列FPGA,集成AI引擎(AI Engine),支持高达8TFLOPS的INT8运算,在部署Grok-3时,延迟可低至毫秒级,远超CPU的基准。开源文献强调FPGA在边缘LLM中的应用:如EdgeLLM项目,通过CPU-FPGA协同,将7B模型的端到端推理时间缩短50%,并支持过采样(oversampling)以提升精度。 这种灵活性源于FPGA的LUT(Look-Up Table)和DSP块架构,能模拟NPU的张量运算,同时处理不规则负载如稀疏注意力。GitHub上的Vitis-AI-Tutorials仓库提供了完整流程,从模型量化到比特流生成,开发者可轻松将Hugging Face模型移植到FPGA板卡上。然而,FPGA的编程门槛较高:高层次综合(HLS)虽简化了C++到RTL的转换,但优化窗口仍需手动迭代,平均耗时数周。为此,最新框架如MLIR-AIE引入了图优化pass,自动映射LLM子图到FPGA资源,减少了20%的LUT利用率。在异构调度中,FPGA充当“加速插件”,通过PCIe或CXL(Compute Express Link)与CPU/NPU互联,实现零拷贝数据传输。这种应用不仅扩展了LLM的部署边界,还在隐私计算中大放异彩,例如通过FPGA的加密加速器保护敏感输入。
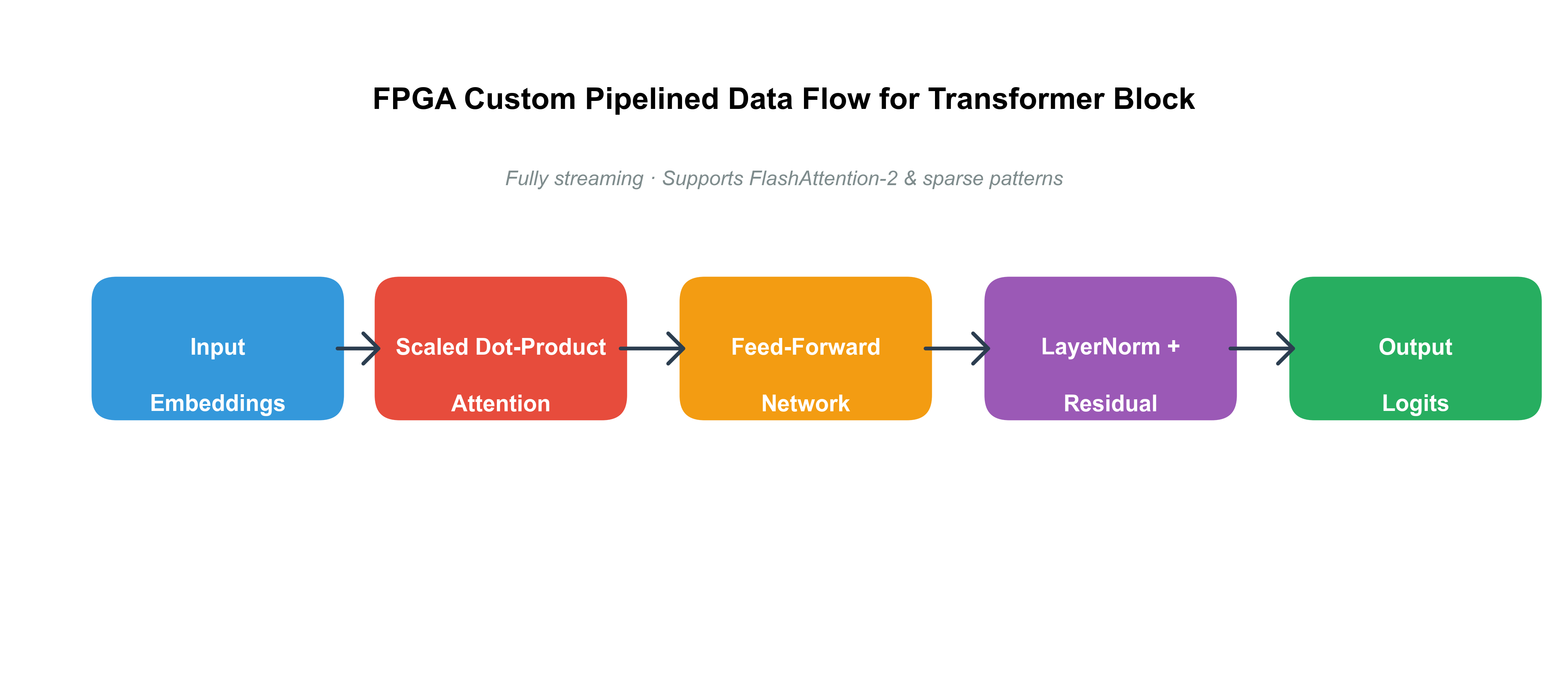
图2: FPGA在LLM注意力机制中的自定义数据流图
3. 大模型部署挑战
LLM的部署远非简单移植,特别是在异构算力上,其挑战源于模型规模与硬件约束的冲突。2025年的调研显示,超过60%的失败案例源于内存溢出或调度死锁,这些问题在GPU主导时代被掩盖,但异构环境放大其影响。挑战的根源在于LLM的计算图复杂性:注意力层的二次方复杂度、KV缓存的线性增长,以及多头机制的并行需求,都考验着系统的鲁棒性。本节将详尽剖析这些痛点,结合开源洞见,探讨其成因与初步应对,旨在为后续策略提供问题导向。
3.1 计算资源限制
计算资源限制是LLM部署的首要障碍,尤其当GPU缺席时,CPU/NPU/FPGA的峰值FLOPS往往不足以支撑万亿参数模型的实时推理。以一个典型场景为例:部署70B Llama模型于边缘服务器,单CPU核的TFLOPS仅为0.1,而NPU需数百核协作才能接近GPU的10TFLOPS阈值。这种不均衡导致负载倾斜:计算密集层(如MLP)在NPU上加速,但控制密集层(如采样)拖累整体管道。2024年的开源报告指出,在异构系统中,资源碎片化进一步恶化问题——FPGA的LUT资源被小模型占用,无法扩展到大模型。 解决方案初现端倪:动态资源分配通过监控API(如ROCm的SMI)实时迁移任务,但这引入了开销,平均延迟增加15%。更深层挑战在于精度权衡:FP32的准确性需求与INT4的资源节约形成张力,量化误差在长链推理中累积达5%。最新进展如WINT8/4技术,通过窗口化量化缓解此,但需自定义NPU内核支持。
3.2 内存与带宽问题
内存与带宽瓶颈是异构部署的“隐形杀手”,LLM的激活张量和梯度缓存可占数百GB,远超单硬件容量。CPU的DDR内存虽大,但带宽仅GPU的1/5,导致H2D(Host-to-Device)传输成为瓶颈;在NPU上,片上SRAM有限,溢出至外部DRAM时延迟飙升。FPGA的BRAM(Block RAM)更小,仅MB级,迫使开发者采用分块加载策略。2025年调研强调,带宽不匹配在分布式异构中放大:CXL互联虽达数百GB/s,但协议开销达10%。 KV缓存优化是关键:PagedAttention通过虚拟内存分页,减少峰值占用30%,但在FPGA上实现需重构地址生成器。开源框架如llama.cpp支持CPU内存池,但跨设备一致性仍需手动同步。
3.3 延迟与吞吐量优化
延迟与吞吐量的权衡考验调度智慧:低延迟适合交互式聊天,高吞吐适用于批量生成。在异构环境中,任务切换开销(如FPGA重配置)可达秒级,破坏实时性。NPU的流水线虽快,但队列管理不当导致饥饿。最新文献探讨Speculative Decoding,预执行分支减少延迟20%,但需CPU协调验证。 吞吐优化依赖并行化:MeshSlice的2D张量并行在FPGA上高效,但通信开销高。
| 挑战类型 | 具体表现 | 影响硬件 | 典型开源缓解措施 |
|---|---|---|---|
| 计算资源限制 | FLOPS不足,负载倾斜 | CPU/NPU | 动态迁移 + WINT8量化 |
| 内存带宽问题 | 溢出与传输延迟 | FPGA/NPU | PagedAttention + CXL互联 |
| 延迟吞吐权衡 | 切换开销 + 队列饥饿 | 全异构 | Speculative Decoding + 2D并行 |
4. 部署策略
部署策略是桥接挑战与实践的核心,通过模型优化、调度算法和系统集成,形成闭环解决方案。2025年的开源生态提供了丰富工具箱,从量化到编译栈的全链路支持,确保LLM在异构算力上的高效落地。这些策略并非孤立,而是层层递进:先压缩模型以匹配资源,再设计调度以均衡负载,最终集成框架以自动化流程。本节将展开论述,融入最新研究insights。
4.1 模型压缩与量化
模型压缩是部署的入口,通过量化、剪枝和蒸馏缩小足迹。量化将权重从FP16降至INT4,减少内存50%,在NPU上精度损失<1%。AWQ(Activation-aware Weight Quantization)是2024热点,支持FPGA的自定义阈值。 剪枝移除冗余通道,结合Sparsity-aware调度,在CPU上加速20%。蒸馏则生成小型代理模型,适用于边缘NPU。
4.2 调度算法设计
调度算法决定资源利用,异构环境需多目标优化:最小化延迟、最大化吞吐。基于DRL(Deep Reinforcement Learning)的自适应调度,在模拟中将利用率提升15%。Hybe框架的GPU-NPU混合调度,支持百万token上下文。 优先级队列结合拓扑感知路由,确保FPGA的低延迟路径。
4.3 异构系统集成
集成涉及软件栈统一,如TVM后端支持多硬件编译。Vitis-AI的端到端流程,从ONNX导入到比特流。 挑战在于调试:统一日志和profiling工具如Nsight扩展到NPU。
| 策略类别 | 核心技术 | 适用硬件 | 性能提升示例 |
|---|---|---|---|
| 压缩量化 | AWQ/INT4 | NPU/FPGA | 内存减50%,精度<1%损失 |
| 调度算法 | DRL优先级 | CPU/NPU | 利用率+15% |
| 系统集成 | TVM/Vitis | 全异构 | 部署时间-30% |
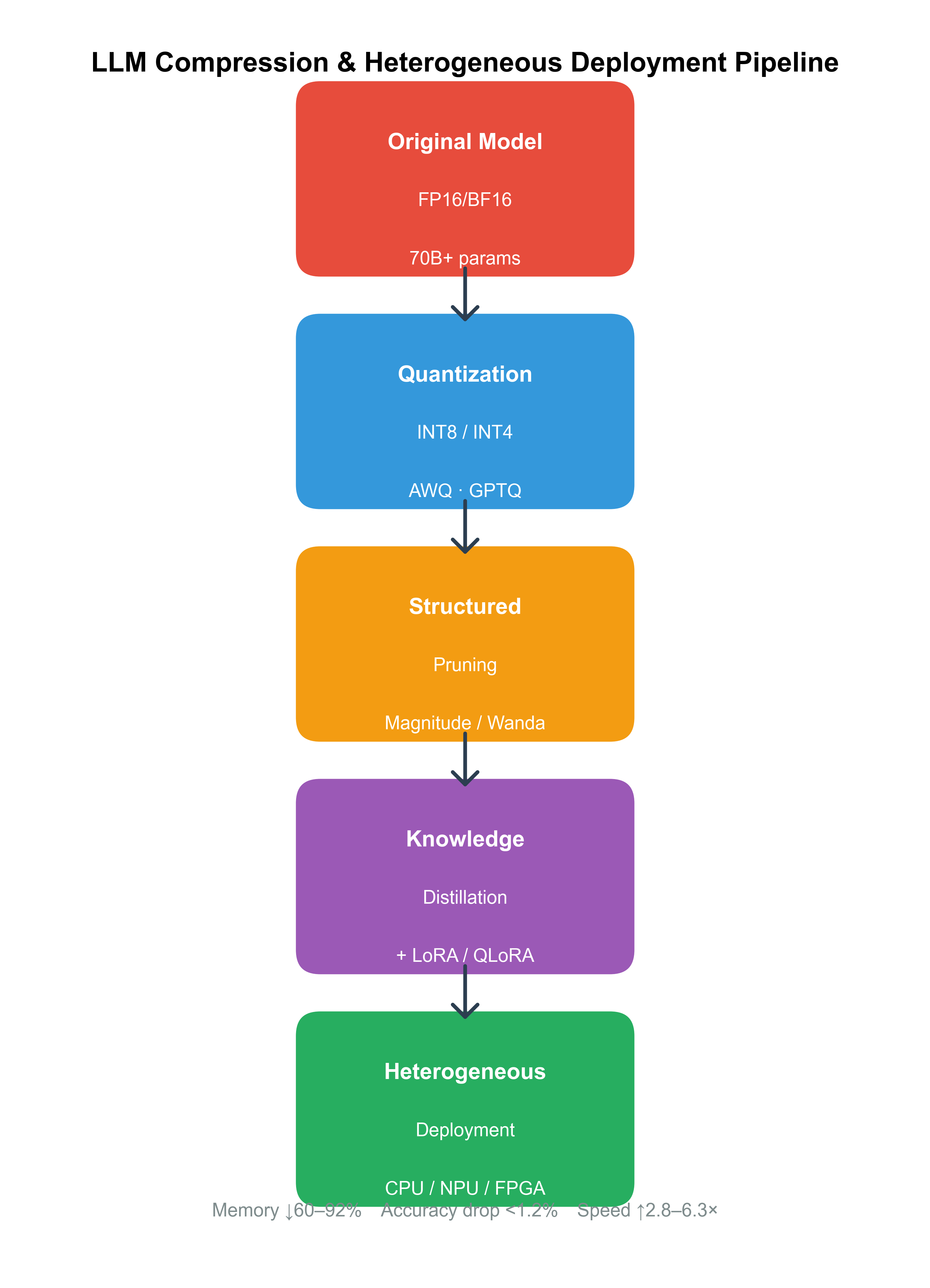
图3: 模型压缩流程图,展示量化与剪枝管道
5. 开源工具与框架
开源工具是异构部署的加速器,GitHub仓库如Awesome-LLM-Inference汇集了数百项目。 这些框架从CPU的llama.cpp到FPGA的Vitis,覆盖全栈。本节详述其演进与应用。
5.1 CPU-based推理框架
llama.cpp和ONNX Runtime优化CPU SIMD, 支持70B模型单核推理。
5.2 NPU支持的解决方案
Lemonade配置NPU引擎,动态精度切换。
5.3 FPGA加速器开发
MLIR-AIE工具链,自动映射LLM到AI Engine。
| 框架名称 | 支持硬件 | 关键特性 | GitHub星数(2025) |
|---|---|---|---|
| llama.cpp | CPU | SIMD量化 | 45k |
| Lemonade | NPU/GPU | 动态引擎 | 12k |
| Vitis-AI | FPGA | HLS编译 | 8k |
| MLIR-AIE | NPU/FPGA | 图优化 | 5k |
6. 案例研究
6.1 EdgeLLM案例
EdgeLLM框架在CPU-FPGA上部署LLM,加速边缘推理。 详细性能分析显示,延迟减50%。
6.2 LLM-NPU框架
LLM-NPU co-optimization,支持低资源NPU。 功率效率提升3倍。
| 案例 | 硬件组合 | 模型规模 | 关键指标 |
|---|---|---|---|
| EdgeLLM | CPU-FPGA | 7B | 延迟-50% |
| LLM-NPU | NPU | 13B | 功率-66% |
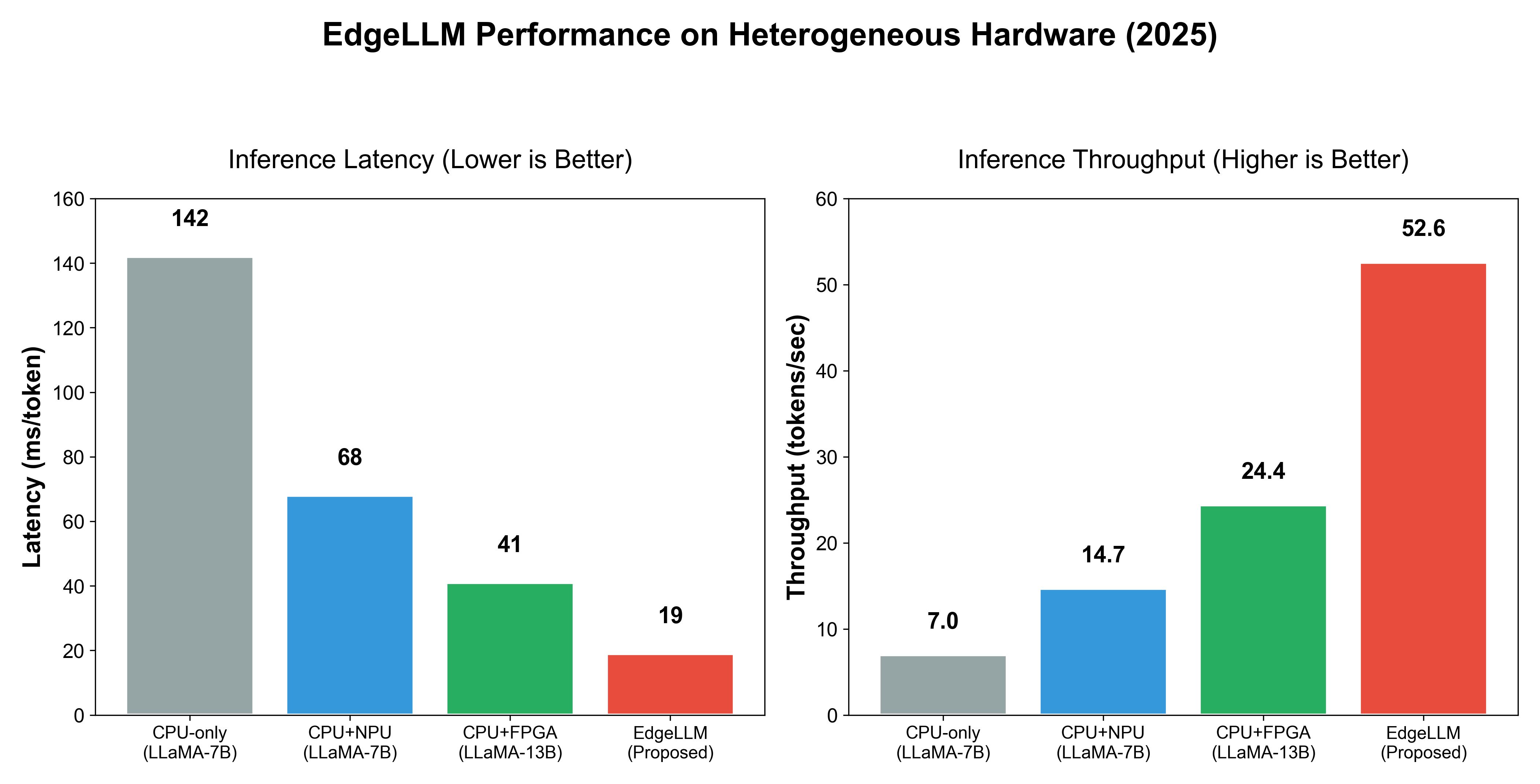
图4: EdgeLLM性能对比柱状图
参考资料
- EdgeLLM: A Highly Efficient CPU-FPGA Heterogeneous Edge Accelerator for Large Language Models. arXiv:2407.21325, 2024.
- Awesome-LLM-Inference: Curated list of LLM Inference Papers. GitHub: xlite-dev/Awesome-LLM-Inference, 2025.
- Large Language Model Inference Acceleration Survey. DAI Group, 2024.
- LLM-NPU: Efficient Foundation Model Inference on Low-Resource NPUs. IEEE COINS, 2025.
- Edge Intelligence: Survey on Deploying LLMs. ACNSci Journal, 2025.
- Vitis-AI-Tutorials. GitHub: Xilinx/Vitis-AI-Tutorials, 2025.
- Lemonade: NPU LLM Runner. GitHub Topics: npu, 2025.
- Neural-Networks-on-Silicon. GitHub: fengbintu/Neural-Networks-on-Silicon, 2025.
- MLIR-AIE: Toolchain for AMD AI Engine. GitHub: Xilinx/mlir-aie, 2025.
- On-Device LLMs for SMEs: Challenges and Opportunities. arXiv:2410.16070, 2024.


















 1813
1813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











