




最近在研究大模型优化的时候,深入了解了Flash Attention这个技术。说实话,刚开始听到这个名字的时候,我还以为是某种新的注意力机制,后来才发现这其实是一个非常巧妙的硬件优化方案。今天想和大家分享一下我对Flash Attention的理解。
为什么需要Flash Attention?
要理解Flash Attention,首先得明白传统Attention计算的瓶颈在哪里。
我在二、大模型原理:图文解析Transformer原理与代码这篇文章中有提到,注意力的计算量非常大,我们需要计算Q×K^T,这会产生一个N×N的矩阵(N是序列长度)
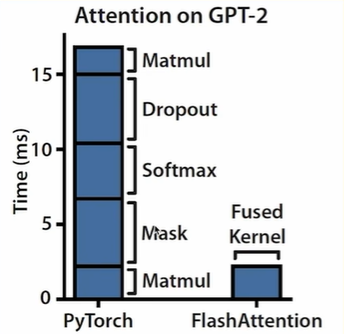
问题不仅仅是矩阵大,更关键的是后续的softmax、dropout等操作都属于内存密集型运算,而不是计算密集型。这意味着大量时间都花在了内存读写上,而不是实际的数学运算上。
注意力机制的耗时最多的是在
GPU内存层次结构
要理解Flash Attention的工作原理,需要先了解GPU的内存架构:
HBM(High Bandwidth Memory):这是GPU的主内存,容量大(比如A100有40G或80G),但相对较慢,传输速度约1.5TB/s。我们平时说的"显存不够了"指的就是这块内存。
SRAM(Static RAM):这是GPU芯片上的缓存,速度极快(约19TB/s)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 69
69

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











