




文章目录
分块策略详解
文档拆分策略有多种,每种策略都有其自身的优势。
但是粗略来说我们1~5的分块策略是由差到好的,具体可以根据项目多方面测试下
1. 固定长度拆分(简单粗暴)
最直观的策略是根据固定长度进行拆分。
就像用刀切面包一样,每100个字符就切一刀,不管切到哪里。
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0, separator="")
document="""One of the most important things I didn't understand about the world when I was a child is the degree to which the returns for performance are superlinear.
Teachers and coaches implicitly told us the returns were linear. "You get out," I heard a thousand times, "what you put in." They meant well, but this is rarely true. If your product is only half as good as your competitor's, you don't get half as many customers. You get no customers, and you go out of business.
It's obviously true that the returns for performance are superlinear in business. Some think this is a flaw of capitalism, and that if we changed the rules it would stop being true. But superlinear returns for performance are a feature of the world, not an artifact of rules we've invented. We see the same pattern in fame, power, military victories, knowledge, and even benefit to humanity. In all of these, the rich get richer. [1]
You can't understand the world without understanding the concept of superlinear returns. And if you're ambitious you definitely should, because this will be the wave you surf on.
It may seem as if there are a lot of different situations with superlinear returns, but as far as I can tell they reduce to two fundamental causes: exponential growth and thresholds.
The most obvious case of superlinear returns is when you're working on something that grows exponentially. For example, growing bacterial cultures. When they grow at all, they grow exponentially. But they're tricky to grow. Which means the difference in outcome between someone who's adept at it and someone who's not is very great.
Startups can also grow exponentially, and we see the same pattern there. Some manage to achieve high growth rates. Most don't. And as a result you get qualitatively different outcomes: the companies with high growth rates tend to become immensely valuable, while the ones with lower growth rates may not even survive.
Y Combinator encourages founders to focus on growth rate rather than absolute numbers. It prevents them from being discouraged early on, when the absolute numbers are still low. It also helps them decide what to focus on: you can use growth rate as a compass to tell you how to evolve the company. But the main advantage is that by focusing on growth rate you tend to get something that grows exponentially.
YC doesn't explicitly tell founders that with growth rate "you get out what you put in," but it's not far from the truth. And if growth rate were proportional to performance, then the reward for performance p over time t would be proportional to pt.
Even after decades of thinking about this, I find that sentence startling."""
texts = text_splitter.split_text(document)
total_characters = len(document)
num_chunks = len(texts)
average_chunk_size = total_characters/len(texts)
print(f"Total Characters: {total_characters}")
print(f"Number of chunks: {num_chunks}")
print(f"Average chunk size: {average_chunk_size:.1f}")
print(f"\nFirst few chunks:")
for i, chunk in enumerate(texts[:3]):
print(f"Chunk {i+1} ({len(chunk)} chars): {chunk[:100]}...")
控制台会输出:
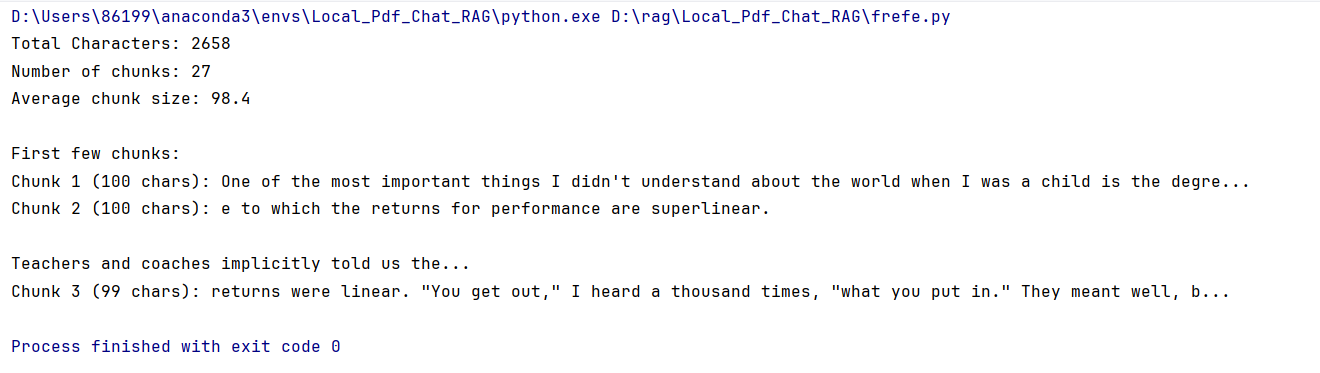
以上结果我们可以在https://chunkviz.up.railway.app/ 看到,如下图:

一般实战中我们会设置约10%-20%做重叠窗口,这样可以使得模型分块之后可以具备连续上下文逻辑。
2. 递归字符拆分(智能切割)
最直观的策略是根据固定长度进行拆分。这种简单而有效的方法可以确保每个块不超过指定的大小限制。
就像用刀切面包一样,每100个字符就切一刀,不管切到哪里。
1. 首先尝试按最大单位切割(段落)
# 就像先按整个萝卜来分
段落1 = "这是第一段内容..."
段落2 = "这是第二段内容..."
段落3 = "这是第三段内容..."
2. 如果段落太大,就切成句子
# 萝卜太大了,按句子切
句子1 = "这是第一个句子。"
句子2 = "这是第二个句子。"
句子3 = "这是第三个句子。"
3. 如果句子还是太大,就切成单词
# 句子还是太长,按单词切
单词1 = "这是"
单词2 = "第一个"
单词3 = "很长的"
单词4 = "句子"
4. 最后实在没办法,才按字符切
# 实在没办法了,按字符切
字符1 = "这"
字符2 = "是"
字符3 = "一"
字符4 = "个"
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
document="""One of the most important things I didn't understand about the world when I was a child is the degree to which the returns for performance are superlinear.
Teachers and coaches implicitly told us the returns were linear. "You get out," I heard a thousand times, "what you put in." They meant well, but this is rarely true. If your product is only half as good as your competitor's, you don't get half as many customers. You get no customers, and you go out of business.
It's obviously true that the returns for performance are superlinear in business. Some think this is a flaw of capitalism, and that if we changed the rules it would stop being true. But superlinear returns for performance are a feature of the world, not an artifact of rules we've invented. We see the same pattern in fame, power, military victories, knowledge, and even benefit to humanity. In all of these, the rich get richer. [1]
You can't understand the world without understanding the concept of superlinear returns. And if you're ambitious you definitely should, because this will be the wave you surf on.
It may seem as if there are a lot of different situations with superlinear returns, but as far as I can tell they reduce to two fundamental causes: exponential growth and thresholds.
The most obvious case of superlinear returns is when you're working on something that grows exponentially. For example, growing bacterial cultures. When they grow at all, they grow exponentially. But they're tricky to grow. Which means the difference in outcome between someone who's adept at it and someone who's not is very great.
Startups can also grow exponentially, and we see the same pattern there. Some manage to achieve high growth rates. Most don't. And as a result you get qualitatively different outcomes: the companies with high growth rates tend to become immensely valuable, while the ones with lower growth rates may not even survive.
Y Combinator encourages founders to focus on growth rate rather than absolute numbers. It prevents them from being discouraged early on, when the absolute numbers are still low. It also helps them decide what to focus on: you can use growth rate as a compass to tell you how to evolve the company. But the main advantage is that by focusing on growth rate you tend to get something that grows exponentially.
YC doesn't explicitly tell founders that with growth rate "you get out what you put in," but it's not far from the truth. And if growth rate were proportional to performance, then the reward for performance p over time t would be proportional to pt.
Even after decades of thinking about this, I find that sentence startling."""
texts = text_splitter.split_text(document)
total_characters = len(document)
num_chunks = len(texts)
average_chunk_size = total_characters/len(texts)
print(f"Total Characters: {
total_characters}")
print(f"Number of chunks: {
num_chunks}")
print(f"Average chunk size: {
average_chunk_size:.1f}")
print(f"\nFirst few chunks:")
for i, chunk in enumerate(texts[:3]):
print(f"Chunk {
i+1} ({
len(chunk)}字符): {
chunk}")
控制台会输出:

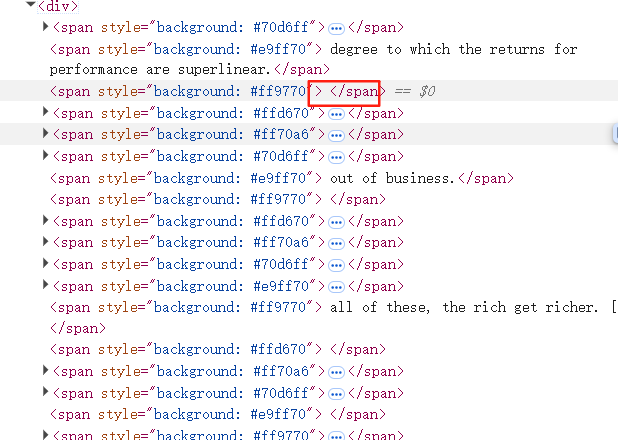
以上结果我们可以在https://chunkviz.up.railway.app/ 看到,如下图:

这个网站开发者将空格也视为了分割块,可忽略它的span数计算总数与我们不一样(它的bug):
该方法是dify的默认方法。我们可以修改分割符从而快速简单达到效果,比如
separators 分隔符设置:
默认的separators 是"\n\n"(即回车)。比如:
- 中文文档:应增加中文标点符号(如"。“、”,")作为分隔符
- Markdown文档:可使用标题标记(#、##)、代码块标记(```)等作为分隔符
3. 特殊格式拆分(定向打击)
某些文档具有固有的结构,例如 HTML、Markdown 或 JSON 文件。
这里我就先介绍下Markdown ,其他我遇到了再跟大家补充。
Markdown分块
MarkdownHeaderTextSplitter是对RecursiveCharacterTextSplitter用了多个不同符号使得其能适应格式。
包含了以下符号作为分隔符:
-
#到###### -
````lang` - 三个反引号开始的代码块
-
~~~lang- 三个波浪号开始的代码块 -
***- 星号分割线(3个或更多) -
---- 短横线分割线(3个或更多) -
___- 下划线分割线(3个或更多)
4. 语义分割(更智能切割)
递归文本分块基于预定义规则工作,虽然简单高效,但可能无法准确捕捉语义变化。
基于语义的分块策略则直接分析文本内容,根据语义相似度判断分块位置。
基于Embedding的语义分块
但从概念上讲,该方法是在文本含义发生显著变化时对文本进行拆分。例如,我们可以使用滑动窗口方法生成嵌入向量,并比较嵌入以发现显著差异:
1. 句子分割 首先将整个文本按句子分割(默认按句号、问号、感叹号分割)。
2. 创建语义窗口 为了获得更稳定的语义表示,不是单独分析每个句子,而是创建"滑动窗口"。默认情况下,每个窗口包含3个句子:当前句子加上前后各一个句子。这样做可以减少单个短句造成的噪音。
3. 生成嵌入向量 对每个滑动窗口的组合句子生成嵌入向量,这些向量能够捕获文本的语义含义。
4. 计算语义距离 计算相邻窗口之间的余弦距离。余弦距离越大,说明两个窗口的语义差异越大。
5. 确定断点阈值 系统提供4种方法来确定什么程度的语义距离算作"断点":
- 百分位数法:找出距离最大的前5%作为断点
- 标准差法:超过平均值加3倍标准差的距离作为断点
- 四分位数法:基于四分位距离的统计方法
- 梯度法:分析距离变化的梯度来找断点
6. 执行分割 在语义距离超过阈值的位置进行分割,形成最终的语义块。
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
model_name  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 1853
1853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











