





一、微调数据集的常见分类

从最上层的预训练模型开始,我们先划分出是否为多模态(例如让模型具备对图片、语音、视频的理解和生成能力)微调,还是纯文本微调(仅让模型具备生成文字的能力)。
在文本微调中,监督微调是目前应用最广泛也是最常用的微调技术,当然目前我们普通人想在特定行业里去微调自己的大模型,最常用的也是监督微调,所以监督微调的数据集格式是我们后续重点学习的内容。
然后其他微调技术还包括无监督、自监督微调,强化学习微调等等,这些我们只做简单了解,不用过多深入。最后还有因为最近 DeepSeek 爆火而带火的知识蒸馏技术,我也把它当作特殊微调任务的一种,这个我们后面再具体讲解。
1.1 预训练
从零开始训练一个模型,一般这个流程叫做预训练,这个过程的目的就是让模型掌握语言的通用规律,以及基本的语言理解能力。
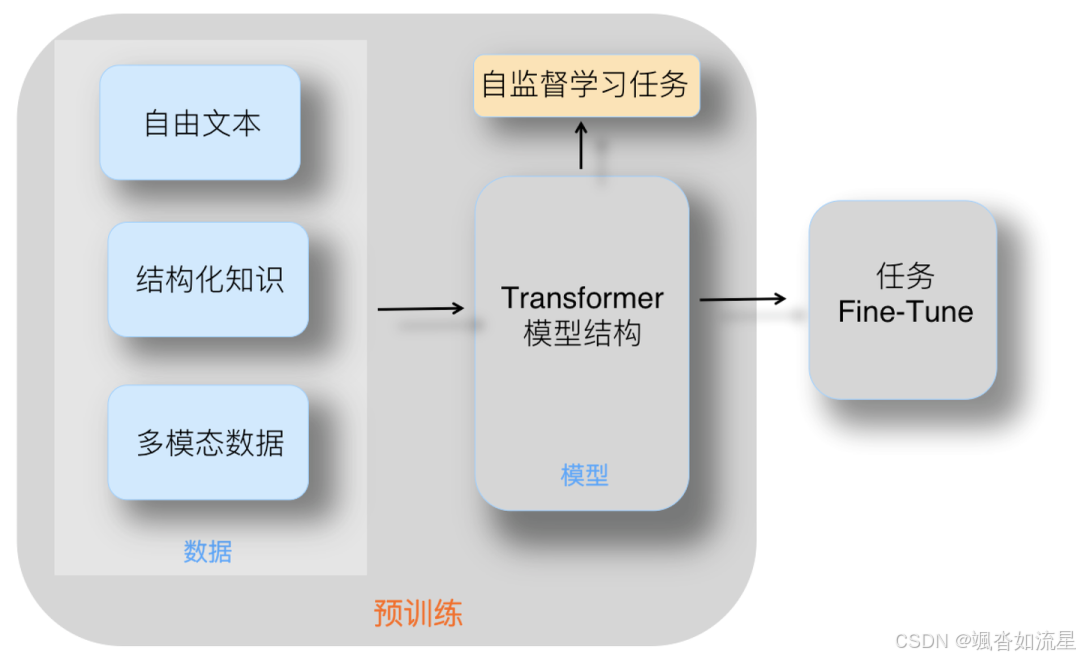
目前我们市面上主流的大模型,比如 ChatGPT、DeepDeek 等等,都属于 “自回归模型”,而 “自回归模型” 的本质就是:用过去的自己来预测未来的自己。
二、微调数据集的常用格式
模型微调已经不是什么新技术了,只是最近由于 DeepSeek 的横空出世,导致逐步开始被各领域更广泛的应用,在这之前,哪些数据集格式效果好,哪些容易整理,已经总结了很多经验,比如目前广泛被大家使用的有两种数据集格式,Alpaca 和 ShareGPT。
2.1 Alpaca 格式
Alpaca 最初是斯坦福大学于 2023 年发布的 52k 条指令微调数据集,由 OpenAI 的 text-davinci-003 模型生成,旨在通过指令跟随(Instruction Following)任务优化大语言模型(如 LLaMA)的性能。
后续随着社区的发展,Alpaca 的 JSON 结构逐渐被抽象为一种 通用数据格式,并且扩展了一些字段如 system(系统提示)和 history(历史对话),支持多轮交互任务。适用于多种微调场景,很多主流框架(如 LLaMA-Factory、DeepSpeed)都可以直接加载 Alpaca 格式的数据集。
核心结构
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5728
5728

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









