




详细拆解 "智能视频监控与分析智能体" 的具体实现过程。这将是一个从数据到部署的完整技术流水线。
目录
目录
智能视频监控分析智能体实现方案
一、 系统架构总览
该系统采用经典的 "端-边-云" 协同架构,以实现效率与性能的最佳平衡。
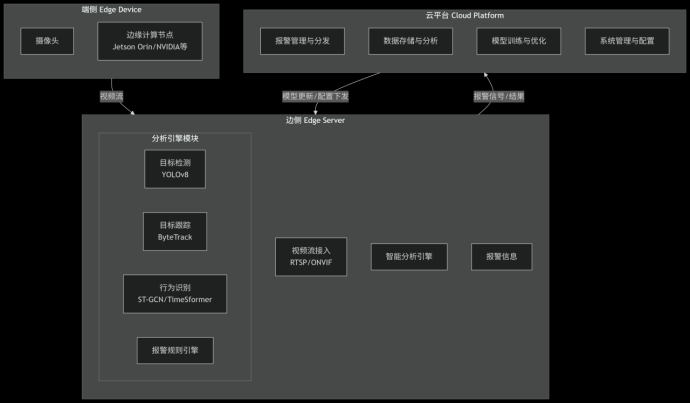
编辑```mermaid
flowchart TD
subgraph A[端侧 Edge Device]
A1[摄像头]
A2[边缘计算节点<br>Jetson Orin/NVIDIA等]
end
subgraph B[边侧 Edge Server]
B1[视频流接入<br>RTSP/ONVIF]
B2[智能分析引擎]
subgraph B2_Sub[分析引擎模块]
B2_1[目标检测<br>YOLOv8]
B2_2[目标跟踪<br>ByteTrack]
B2_3[行为识别<br>ST-GCN/TimeSformer]
B2_4[报警规则引擎]
end
B3[报警信息]
end
subgraph C[云平台 Cloud Platform]
C1[报警管理与分发]
C2[数据存储与分析]
C3[模型训练与优化]
C4[系统管理与配置]
end
A -- 视频流 --> B
B -- 报警信号/结果 --> C
C -- 模型更新/配置下发 --> B
```
---
二、 分场景具体实现过程
场景一:轨行区人员/异物入侵检测
1. 技术选型:
- 核心模型:YOLOv8s (精度与速度的平衡)
- 跟踪算法:ByteTrack (高性能多目标跟踪)
- 推理框架:TensorRT (NVIDIA GPU加速)
2. 实现步骤:
步骤 1: 定义ROI (Region of Interest)
- 在视频帧中精确划定轨行区多边形区域,排除其他区域的干扰。
- 使用OpenCV的`cv2.pointPolygonTest()`函数判断检测到的目标中心点是否在ROI内。
```python
伪代码:ROI区域入侵判断
import cv2
import numpy as np
1. 定义轨行区ROI多边形顶点(归一化坐标或像素坐标)
roi_points = np.array([[x1, y1], [x2, y2], [x3, y3], [x4, y4]], np.int32)
2. 对每个检测到的目标
for detection in detections:
x_center, y_center = detection['center']
3. 判断目标中心点是否在ROI多边形内
is_inside = cv2.pointPolygonTest(roi_points, (x_center, y_center), False) >= 0
if is_inside:
4. 触发入侵报警
trigger_intrusion_alert(detection)
```
步骤 2: 模型推理与跟踪
- 使用YOLOv8进行实时目标检测,获取人员、车辆、异物等目标的坐标和置信度。
- 使用ByteTrack为每个目标分配唯一ID,实现跨帧跟踪,避免重复报警。
步骤 3: 报警过滤逻辑
- 防误报机制:目标必须在ROI内持续存在N帧(如5帧,约0.2秒)才触发报警,避免因检测抖动误报。
- 报警信息:包含目标截图、目标类型、位置、时间、跟踪ID等信息。
---
场景二:站台乘客异常行为识别
这是一个更复杂的时序行为识别问题。
1. 技术选型:
- 姿态估计:YOLOv8-Pose (检测人体17个关键点)
- 行为识别:基于规则 + 时序卷积网络 (ST-GCN)
2. 实现步骤:
步骤 1: 关键点检测
- 使用YOLOv8-Pose模型获取乘客的骨骼关键点坐标(鼻子、肩膀、手肘、膝盖等)。
步骤 2: 定义异常行为规则
- 摔倒检测:计算人体的高宽比和肩膀线与地面的角度。
- `if (身高/宽度 > 阈值) and (肩膀角度 < 阈值): then 判定为摔倒`
- 跨越黄线:判断脚部关键点与预设黄线区域的位置关系。
- 奔跑:计算连续帧之间人体关键点的位移速度。
```python
伪代码:基于姿态关键点的摔倒检测
def detect_fall(keypoints):
"""
根据人体关键点判断是否摔倒
keypoints: 包含17个关键点坐标的数组
"""
1. 获取肩膀、臀部、脚踝等关键点
left_shoulder = keypoints[5]
right_shoulder = keypoints[6]
mid_hip = (keypoints[11] + keypoints[12]) / 2
2. 计算肩膀连线的角度(与水平线的夹角)
shoulder_vector = right_shoulder - left_shoulder
angle = np.degrees(np.arctan2(shoulder_vector[1], shoulder_vector[0]))
if angle < 0:
angle += 180
3. 计算人体的高宽比
height = np.linalg.norm(mid_hip - (left_shoulder + right_shoulder)/2)
width = np.linalg.norm(right_shoulder - left_shoulder)
ratio = height / width if width > 0 else 0
4. 应用阈值规则
if angle > 45 and angle < 135 and ratio < 1.5:
return True 疑似摔倒
else:
return False
```
步骤 3: 高级行为识别(可选)
- 对于更复杂的行为(如打架、争执),使用ST-GCN(时空图卷积网络)。
- 将连续多帧的人体关键点构造成图结构,同时学习空间(关节间)和时间(帧间)的特征。
---
场景三:设备状态监控
1. 技术选型:
- 异常检测:Unsupervised Anomaly Detection (如SPADE, PatchCore)
- 分类模型:ResNet / EfficientNet (用于破损、漏水等具体缺陷分类)
2. 实现步骤:
步骤 1: 数据收集与预处理
- 收集正常状态的设备图像(如正常的闸机、扶梯、墙面)。
- 收集各种缺陷的图像(如屏幕破损、漏水痕迹、烟雾)。
步骤 2: 模型训练
- 方案A(有监督):如果缺陷数据充足,训练一个EfficientNet分类模型,识别各种缺陷类型。
- 方案B(无监督):如果缺陷样本稀少,采用异常检测思路。模型只学习“正常”是什么样子,任何偏离“正常”的模式都会被标记为异常。
步骤 3: 实时监控与报警
- 定时截取设备图像送入模型。
- 输出异常分数和异常区域的热力图,便于运维人员定位问题。
```python
伪代码:基于无监督异常的漏水检测
def detect_water_leak(image):
"""
使用无监督异常检测模型检测图像中的异常区域
"""
1. 图像预处理
processed_image = preprocess(image)
2. 模型推理(异常检测模型,如PaDim/PatchCore)
anomaly_score, anomaly_map = anomaly_model.predict(processed_image)
3. 后处理
if anomaly_score > threshold:
找到异常区域轮廓
contours = find_contours(anomaly_map)
判断异常区域形状和位置是否符合漏水特征
if is_leak_pattern(contours):
return True, anomaly_map
return False, None
```
---
三、 技术实现流水线
![]()
编辑
```mermaid
graph LR
A[原始视频流] --> B[数据采集与标注]
B --> C[模型选择与训练]
C --> D[模型优化与部署]
D --> E[实时分析与推理]
E --> F[业务逻辑与报警]
F --> G[报警分发与呈现]
subgraph B
B1[使用LabelImg标注目标]
B2[使用CVAT标注行为]
end
subgraph C
C1[YOLOv8目标检测模型]
C2[ST-GCN行为识别模型]
C3[Anomaly异常检测模型]
end
subgraph D
D1[TensorRT模型转换]
D2[TensorRT模型量化]
D3[模型量化INT8]
end
subgraph E
E1[OpenCV/TensorRT推理]
E2[DeepStream优化]
end
subgraph F
F1[报警规则引擎]
F2[防误报逻辑]
end
subgraph G
G1[消息队列Kafka]
G2[平台界面展示]
G3[短信/邮件通知]
end
```
四、 核心代码模块示例
主分析循环 (main_loop.py):
```python
import cv2
from yolov8 import YOLOv8Detector
from byte_tracker import ByteTracker
from behavior_analyzer import BehaviorAnalyzer
初始化模型和跟踪器
detector = YOLOv8Detector(model_path="weights/yolov8s.pt")
tracker = ByteTracker()
behavior_analyzer = BehaviorAnalyzer()
cap = cv2.VideoCapture("rtsp://camera_stream_url")
fps = cap.get(cv2.CAP_PROP_FPS)
frame_count = 0
while True:
ret, frame = cap.read()
if not ret:
break
1. 目标检测
detections = detector.detect(frame)
2. 目标跟踪
tracks = tracker.update(detections)
3. 应用特定场景分析
场景1: 入侵检测
for track in tracks:
if is_in_roi(track.center, roi_points): 检查是否在ROI内
trigger_alert("Intrusion", track.id, frame)
场景2: 行为识别 (每5帧分析一次行为)
if frame_count % 5 == 0:
keypoints = detector.detect_pose(frame) 姿态估计
behavior = behavior_analyzer.analyze(keypoints) 行为分析
if behavior == "fall_down":
trigger_alert("FallDown", None, frame)
frame_count += 1
cap.release()
```
五、 挑战与解决方案
| 挑战 | 解决方案 |
| :--- | :--- |
| 光照变化、天气影响 | 使用数据增强训练模型、采用红外热成像摄像头作为补充 |
| 实时性要求高 | 模型量化(TensorRT INT8)、硬件加速(NVIDIA Jetson) |
| 误报率控制 | 多帧验证、多算法融合、设置合理的报警阈值 |
| 系统稳定性 | 设计看门狗机制,进程崩溃后自动重启 |
这个实现方案平衡了技术先进性和工程落地性,可以根据具体地铁线的需求和预算进行裁剪和扩展。建议从入侵检测这个单一场景开始试点,成功后再逐步扩展其他功能。


















 46
46

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











