






《人工智能AI之计算机视觉:从像素到智能》专栏 模块一:视觉之门——从经典特征到CNN革命 ·
在上一篇,我们聊了AI之眼的“终极目标”——它不是在“看”,而是在“计算”。我们知道了它有四大核心任务:分类、检测、分割和识别。
这留下了一个关键问题:AI到底在“计算”什么?
我们每天用手机“扫一扫”,为什么有时候一扫即开,有时候却对不上焦?我们向银行或保险APP上传身份证、保单的照片,为什么有时候秒级识别,有时候却反复提示“照片模糊,请重新上传”?
你可能会说:“那还用问,当然是照片不够清晰。”
这个答案只对了一半。“清晰”是一个非常人类的词。对机器来说,这里面隐藏着一连串的“技术细节”。
作为一个在IT领域(特别是电信、银行、保险行业)摸爬滚打了30多年的从业者,我见过太多“昂贵”的教训。一个耗资数百万的AI智能定损、票据识别项目,在实验室里跑得风生水起,一到真实场景就“水土不服”。追查到底,发现罪魁祸首往往不是AI模型不够先进,而是我们从源头——那张“平平无奇”的数字图像——上就“翻了车”。
在AI的世界里,有一条铁律:Garbage In, Garbage Out (垃圾进,垃圾出)。
在启动那个昂贵的AI引擎(算法)之前,我们必须先当一次“侦探”,搞清楚它吃的“燃料”(数据)到底是什么。
今天,我们就来做一次“像素级”的解剖。让我们忘掉高大上的AI,回到原点,看看机器“看见”的那个世界——数字图像,究竟是如何从“前世”(物理世界的光)转变为“今生”(计算机里的信息)的。
一、 “伟大的妥协”:从模拟光波到数字矩阵
我们先来建立一个核心认知:我们(人类)看到的,是一个连续的、模拟的世界。 光线像一条无限平滑的河流,流淌着无穷无尽的色彩和细节。
而机器呢?它无法处理“无限”。它的世界是离散的、数字的。
要让机器“看见”,就必须先把这条“模拟的河流”,强行装进一个个“数字的桶”里。这个过程,就是“数字化”,它充满了妥协与牺牲。
1.1 像素 (Pixel):世界的基本“原子”
我们最熟悉的词——像素 (Pixel, Picture Element),就是这第一个妥协。
我们妥协了“空间上的无限”。我们不能记录真实世界中的每一个点,所以我们强行在现实世界上盖上了一层“网格”(Grid)。
- 熟悉元素:你手机里的“1080p”(1920x1080)或“4K”分辨率。
- 认知:这意味着什么?一张1080p的照片,就是把你的视野强行切割成了200万个(1920 * 1080)小方块。每一个方块内,所有的细节都会被“平均”掉,只剩下一个颜色值。
这就是为什么你把照片无限放大,最终看到的不是更丰富的细节,而是一个个马赛克方块。
- 人类视觉:模拟的,连续的。
- 机器视觉:数字的,离散的。
这是AI之眼与人类之眼的第一个、也是最根本的区别。

从现实到像素的妥协
1.2 采样 (Sampling):“网格”的诅咒
用“网格”来捕捉“河流”,必然会出问题。
我们妥协的第二个产物,叫“混叠”(Aliasing),俗称“摩尔纹”(Moiré pattern)。
- 熟悉元素:你用手机拍摄电脑屏幕或细条纹衬衫时,照片上出现的那些“诡异”的、五颜六色的波纹。
- 洞察:这“波纹”是怎么来的?
- 比喻:想象一下,你试图用一张“粗孔的渔网”(你的像素网格)去捞“一群小鱼”(你的细条纹衬衫)。
- 结果呢?有些鱼从网孔里漏掉了,有些被卡住了。这个“漏掉”和“卡住”的随机模式,叠加在你的图像上,就成了“混叠”。
- 为什么AI“怕”这个?
- 在工业质检中,AI要检测的是产品上“微米级”的细微划痕。如果你的摄像头分辨率(采样网格)和产品的纹理(比如拉丝金属表面)产生了“混叠”,AI看到的将全是虚假的波纹。它会把这些“波纹”误报为“划痕”,导致产线大面积停摆。
1.3 量化 (Quantization):色彩的“阶梯”
我们妥协了“空间”(采样),接着就要妥协“色彩”。
真实世界的光,其“亮度”也是连续的。从“最暗”到“最亮”,中间有无数个层级。机器同样无法存储“无数”。
于是,我们发明了量化 (Quantization),也叫“色彩深度”(Bit Depth)。
- 熟悉元素:你最熟悉的“8-bit 色彩”(或 24-bit 真彩色)。
- 这意味着什么?它把R、G、B(红绿蓝)每条通道的“亮度河流”,都强行切割成了256级台阶(从0到255)。
- 256(红)x 256(绿)x 256(蓝) = 1670万色。这听起来很多,对吗?
- 陷阱:在“极限”情况下,这远远不够。
- 比喻:人类视觉是“平滑的斜坡”,而8-bit量化是“台阶”。在光线充足的白天,台阶很密,你感觉不到。但在黄昏或黑夜的场景中,光线很暗,可能90%的细节都挤在0到20这几级“台阶”上。
- 此时,你看到的不再是平滑的夜空,而是“色彩断层”(Color Banding)——一层黑、一层深灰、一层浅灰,像等高线地图一样。
- 为什么AI“怕”这个?
- 这在电信、安防行业是“致命伤”。假设我们要用AI在夜间监控某个通信基站,任务是“识别是否有人影入侵”。
- 在人眼看来,月光下依稀有个“轮廓”。
- 但在8-bit的AI看来,由于量化精度太低,那个“人影”的像素值(可能是10)和它背后“墙影”的像素值(可能是8),被“四舍五入”到了同一个“台阶”(比如10)上。
- 结果:AI“看”到的,是一片漆黑。 这就是为什么专业AI(如医疗影像、安防、工业)坚持使用10-bit、12-bit甚至16-bit的RAW格式数据。
思考小札
我们看到,AI的“视觉基础”是建立在“妥协”之上的。它拿到的“今生”(数字图像),从一开始就“背叛”了“前世”(物理真实)。
它在“空间”上是不连续的(采样),在“色彩”上也是不连续的(量化)。
作为AI的“教练”,我们的第一个职责,不是教它跑得多快,而是要弄清楚它“天生”就有的“缺陷”。一个AI项目经理,首先应该问的,不是“你用什么模型”,而是“你的数据是几bit的?”
二、 色彩的“语言”:为什么RGB不是唯一的答案?
好,现在我们有了一个个“数字桶”(像素),每个桶里装着“台阶”分好的水(量化)。那我们该如何“描述”这些水呢?这就是色彩空间 (Color Space)。
2.1 RGB:为“机器”(屏幕)而生
RGB(Red, Green, Blue)是我们最熟悉的。它是一种“加色”模型。
- 比喻:它就像三个手电筒(红、绿、蓝)。三个都关掉(0, 0, 0)就是黑色。三个都开到最亮(255, 255, 255)就是白色。
- 优点:非常直观,且完美对应了我们的硬件——显示器(Monitor)和摄像头(Sensor)。你的屏幕就是由R/G/B三种颜色的发光体组成的。
- 缺点:它极度“反”人类直觉。
- 问题:我给你一个颜色(R=150, G=100, B=50)。你能立刻说出它“更偏红还是更偏绿”吗?它“更亮还是更暗”吗?很难。
- 更糟糕的是,“亮度”和“颜色”是耦合在一起的。如果我想让这个颜色“变亮一点”,同时“保持颜色不变”,我该怎么调R/G/B三个值?——答案是:极其复杂。
2.2 HSV:为“人类”(艺术家)而生
HSV(Hue, Saturation, Value)就是为了解决这个问题。
- H - 色相(Hue):这是“什么颜色”(比如红色、黄色、蓝色)。
- S - 饱和度(Saturation):这是“颜色有多鲜艳”(从“鲜红”到“灰色”)。
- V - 明度(Value):这是“有多亮”(从“明亮”到“黑暗”)。
- 优点:解耦合(Decoupling)。
- 为什么AI“喜欢”这个?
- 熟悉元素:你用“美图秀秀”调照片,你调的往往是“饱和度”、“亮度”,而不是R/G/B。
- 意外创新(应用):假设AI要在一个“光线忽明忽暗”的马路上识别“红灯”。
- 如果用RGB:早上的“亮红”(R=255, G=0, B=0)和傍晚的“暗红”(R=100, G=0, B=0),在AI看来是两个完全不同的颜色,模型很容易混淆。
- 如果用HSV:无论是“亮红”还是“暗红”,它们的H(色相)值是几乎一样的。AI只需要学会“H值在某个范围内的就是红灯”,它就“免疫”了光照变化。
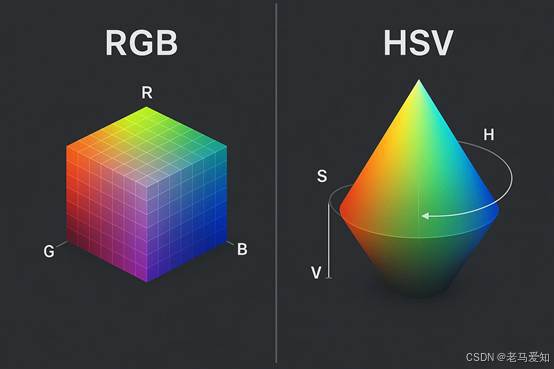
RGB与HSV的直观对比
2.3 YUV/YCbCr:为“压缩”(广播电视)而生
还有一种“语言”,你可能没听过,但你每天都在用它——YUV。
- Y = Luma(亮度)
- U/V (或 Cb/Cr) = Chroma(色度)
它的逻辑和HSV类似,也是“亮度”与“颜色”分离。但它的目的是为了压缩。
- 洞察:人类的眼睛对“亮度”(Y)极其敏感,但对“颜色”(UV)非常迟钝。
- 应用:广播电视和视频流(如H.264)利用了这一点。它们在传输时,会完整地保留“亮度”信息,但会“偷工减料”地压缩“颜色”信息(比如每4个像素只存一组UV值,这叫“4:2:0”采样)。
- AI的陷阱:这对人类“看电影”没问题,但对AI“做质检”可能是灾难。如果AI的任务是识别“红色的药丸”和“蓝色的药丸”,而视频流为了压缩,已经把这些关键的“颜色”信息给“模糊”掉了,AI自然会“失明”。
三、 终极“背叛”:JPEG压缩如何“谋杀”AI的线索
到目前为止,我们谈论的“妥协”(采样、量化)还算是“阳谋”。但接下来这个,几乎是所有AI新手的“噩梦”——有损压缩(Lossy Compression)。
我们必须搞清楚:PNG / BMP 这类格式,是无损压缩(Lossless)。 而 JPEG / JPG 格式,是有损压缩(Lossy)。
- 熟悉元素:你发微信、发朋友圈的照片,几乎都是JPEG。它能把一张10MB的照片压缩到1MB。
- 它是如何做到的?:JPEG的哲学是:“既然人眼看不见,那就扔掉好了。”
- 比喻:JPEG就像一个“差劲的”图书管理员。他拿到一本1000页的精装书(原始图像),为了省空间,他做了两件事:
- 把书撕成一页一页,每8页(8x8像素块)订在一起。
- 他觉得“精美的插画”和“复杂的形容词”(高频细节)太占地方,人看不看无所谓,于是把它们大量删掉了。
- 最后,他把这本“删减版”的书(JPEG)交给了你。
- 致命问题:人类读者(人眼)看这本“删减版”的书,还能猜出“故事大意”。 但是,AI要找的“线索”恰恰就在被删掉的那些“高频细节”里!
- AI质检:要找的是产品表面的“微小裂纹”。(高频细节 -> 被JPEG扔掉了)
- AI医疗:要找的是肿瘤边缘的“毛刺”。(高频细节 -> 被JPEG扔掉了)
- AI OCR:要找的是文字边缘的“锐利笔锋”。(高频细节 -> 被JPEG扔掉了)
思考小札:“翻车”实录
多年前,我们为一个大型银行开发“移动端支票识别”SaaS服务。我们在实验室里用几万张“原始扫描件”(PNG格式)训练模型,识别率达到了99.5%,项目完美交付。
一周后,客户投诉,线上识别率惨不忍睹,只有70%左右。
我们紧急排查,最后定位到问题:客户的“手机APP”在用户拍照上传时,为了节省流量,在用户“无感知”的情况下,自动把照片“压缩”成了一个“高压缩率”的JPEG!
那些对AI识别金额数字至关重要的“文字边缘”,全都在压缩中被“污染”或“抹平”了。
AI模型本身没有任何问题。但“Garbage In, Garbage Out”。这个教训我记到今天:在AI项目中,图像的“压缩格式”和“压缩率”,是和“算法模型”本身一样重要的超参数!

高画质PNG vs 低画质JPEG
四、 一切的源头:传感器上的“Bayer滤镜”
如果说JPEG是“后天”的背叛,那在“先天”出生时,图像就已经“不纯粹”了。
这是一个更深度的、来自硬件的“妥协”:Bayer 滤光阵列 (Bayer Filter)。
- 洞察:绝大多数消费级摄像头(包括你的手机)的传感器(Sensor),它本身是“色盲”的。每一个感光单元(Photosite)只能测量“有多亮”,而不知道“是什么颜色”。
- 怎么办? 工程师在传感器前面盖上了一层“滤镜”,就像给它们戴上了“红、绿、蓝”三种颜色的眼镜。
- Bayer 阵列:这个滤镜的排列方式是“绿、红、绿、蓝”(GRGB)。绿色最多,因为人眼对绿色最敏感。
- 这意味着什么?
- 摄像头“拍”到的第一张原始(RAW)图像,根本不是彩色的!
- 它是一张“马赛克”图:这个像素只知道“红色”值,它旁边的像素只知道“绿色”值。
- 我们看到的“彩色照片”,是相机芯片通过一个叫“去马赛克 (Demosaicing)”的算法,“猜”出来的。
- 芯片会看着那个“只有红色”的像素,然后“猜”它旁边的“绿色”和“蓝色”大概是多少。
- AI的陷阱:
- 这个“猜”的过程,专业术语叫“插值”(Interpolation)。
- 如果这个“猜”的算法(每家相机厂商都不同)比较“激进”,它为了让画面更“平滑”,可能会“抹平”掉那些细微的噪点——而那可能恰恰是AI要找的“特征”!
- (经历):我们曾遇到一个银行的“柜台高拍仪”OCR项目。同样是500万像素,A型号的摄像头识别率95%,B型号的只有80%。查了半天,就是因为B型号的“去马赛克”算法太“智能”了,它把文字的笔锋“平滑”掉了。
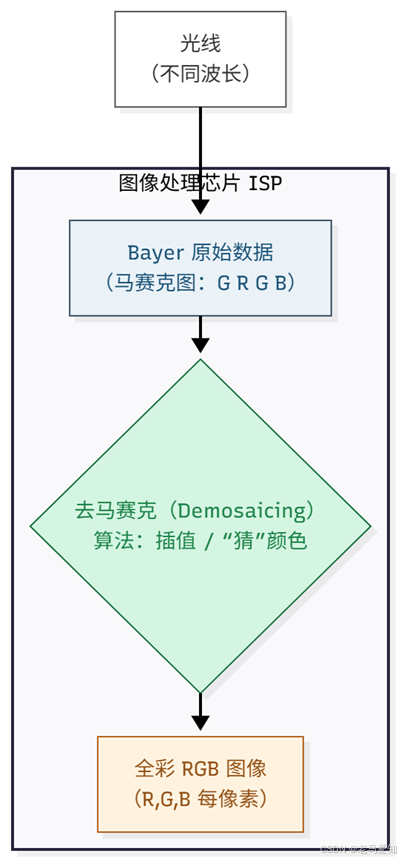
Bayer滤镜如何“猜”出颜色
五、 结语与下一站:戴着“镣铐”的舞蹈
今天,我们没有谈论任何高深的AI模型,我们只做了一件事:审视AI的“食物”。
我们一路追溯,从“今生”的数字图像,回到了“前世”的物理光波。我们发现,一张看似简单的照片,其实是“现实世界”经历四重“妥协”或“背叛”后的产物:
- 采样 (Sampling):背叛了“空间”,带来了“混叠”风险。
- 量化 (Quantization):背叛了“色彩”,带来了“断层”风险。
- 色彩空间 (Color Space):背叛了“感知”,带来了“信息失衡”风险(如YUV)。
- 压缩 (Compression):背叛了“细节”,带来了“特征丢失”风险(如JPEG)。
认知突破
- 我们常犯的错误,是把“数字图像”等同于“我们眼中的世界”。
- 不是的。 数字图像不是现实的“复制品”,而是现实的“编码摘要”。
- AI不是在“看”世界,它是在“解码”这个摘要。
- 一个顶尖的AI模型,配上一个糟糕的“摘要”(比如一张被过度压缩、光线极差的8-bit JPEG图像),就像让一个最优秀的神探,去破解一份“被烧毁的、字迹模糊的”密报。
- 他“解”不出来,不是因为他“不聪明”,而是因为“信息”已经丢失了。
那么,下一站呢?
我们知道了AI的“食物”(数字图像)是如此的“粗糙”且“充满陷阱”。在那个没有“自动挡”引擎(CNN)的年代,先辈们是如何“戴着镣铐跳舞”,从这些“像素矩阵”中,“手动”提取出有意义的“线索”的?
下一篇,我们将进入专栏的第3篇:《CNN诞生前的“蛮荒时代”:SIFT与HOG的故事》。我们将去领略那个“手工特征”时代的智慧与匠心,看看那些天才们是如何在“像素的荒漠”中,“手动”搭建起“视觉的灯塔”的。
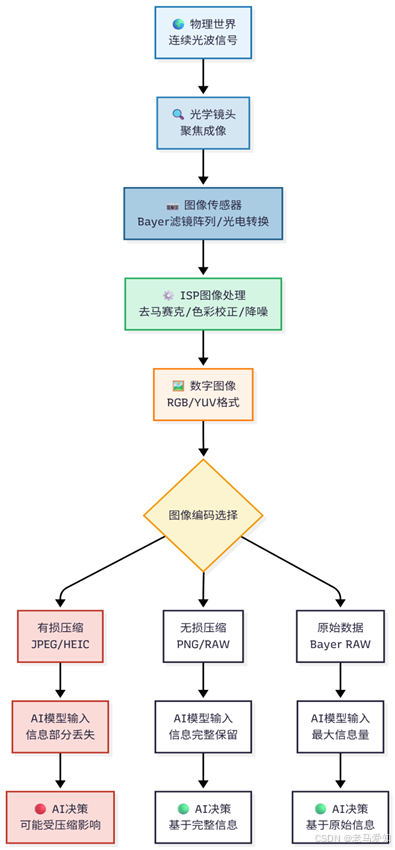
从光波到AI决策的全链路(总结图)


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











