







 超级会员免费看
超级会员免费看
检索增强生成(Retrieval Augmented Generation,RAG)是通过整合来自外部知识源的额外信息来改进大语言模型(Large Language Models,LLMs)应用能力的一种技术。这种技术能够帮助 LLMs 产生更精确和更能感知上下文的回复,同时也能减轻幻觉现象。
自 2023 年以来,RAG 已成为基于 LLM 的软件系统中最受欢迎的架构。许多产品的功能都严重依赖 RAG 。因此,优化 RAG 的性能,使检索过程更快、结果更准确,已成为一个关键问题。
这一系列文章将重点介绍 RAG 优化技术,帮助读者提升 RAG 生成结果的整体质量。
01 简单介绍 Naive(未经过优化的)RAG
如图 1 所示,未经优化的 RAG 工作流程如下:
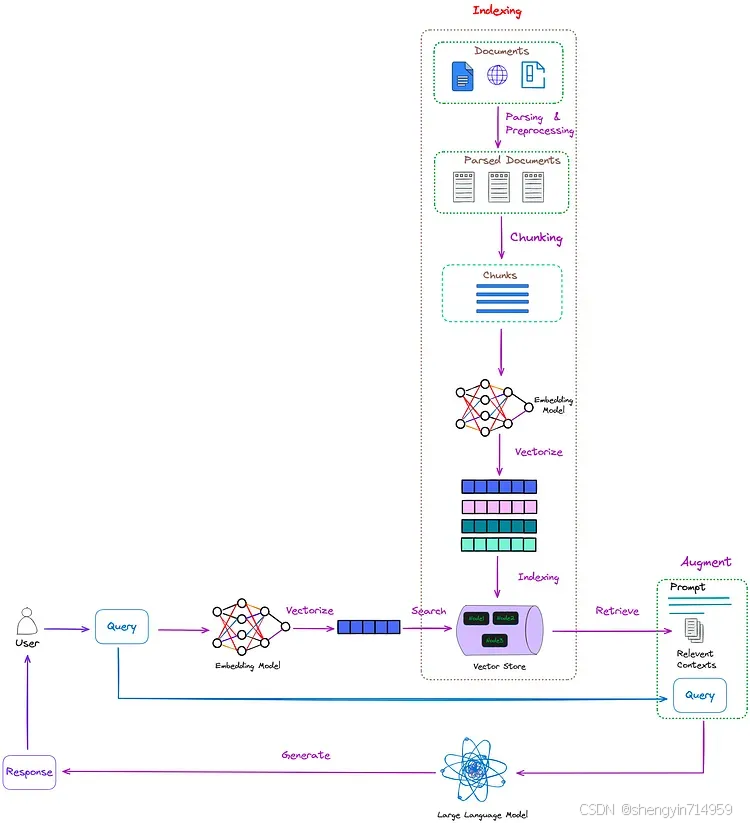
图 1:未经优化的 RAG 经典工作流程。Image by author。
如图 1 所示,RAG 的经典工作流程主要包括以下三个步骤:
编制索引(Indexing) :索引的编制过程是该流程中最先执行的、较为关键的步骤,这个步骤是在离线状态下执行的。首先,对原始数据进行清理和提取,将 PDF、HTML 和 Word 等各种文件格式转换为标准化的纯文本。为了适应语言模型的上下文限制,这些文本被分成更小、更易于管理的块,这一过程被称为分块(chunking)。随后,使用嵌入模型(embedding models)将这些块转换为向量表征(vector represen

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 577
577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









