




大家好,我终于毕业回来了,虽然暂时还是无业游民一只,在找工作中不断焦虑着,但是终于有了大把的时间干点想干的事情了。最近看了一个关于RAG+langchain 的教程,计划使用3-5篇文章来梳理整个课程的内容,在整个过程中,补充一些相关的内容,插入一些个人的看法。本篇将主要介绍RAG解决了什么问题,基本的RAG包括哪些内容,以及高级RAG的第一个阶段-Query Translation。
课程原链接
https://www.youtube.com/watch?v=wd7TZ4w1mSw&list=PLfaIDFEXuae2LXbO1_PKyVJiQ23ZztA0x&ab_channel=LangChain
大模型遇到的挑战
大语言模型(LLM)虽然展现出惊人的能力,但是也面对一些问题
- 知识时效性:模型的训练数据存在截止日期,因此它无法回答最近(也就是LLM发布之后)发生的事情。
- 无法访问私有数据, 世界上大多数据都是私有数据,无法将其用于公开LLM的训练。
这些挑战引发了一个思考:如何将LLM与外部数据库进行连接?早在2020年, 研究人员就提出了**检索增强生成(Retrieval-Augmented Generation, RAG)技术框架,将语言模型与外部知识源连接起来。随着ChatGPT等现代大型语言模型的普及,RAG技术获得了爆发性应用增长。
基本 RAG
2020年,Facebook AI(现Meta AI)团队在论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》中首次提出RAG(Retrieval-Augmented Generation)架构。 作为连接语言模型与外部知识的桥梁,基础RAG架构如下图所示,由三个核心技术阶段组成:
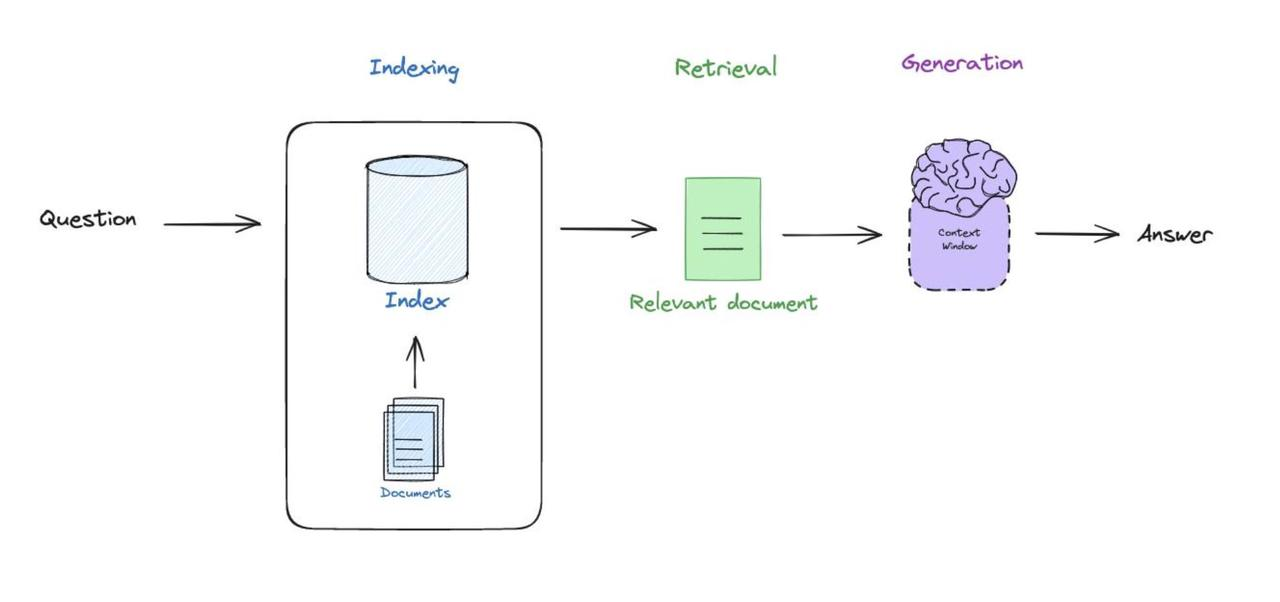
- 索引 (Indexing):这一阶段构建知识库,将非结构化文本转化为可检索的向量表示。
- 检索(Retrieval): 当用户提问时,检索与问题相关的文档。
- 生成(Generation): 将检索到的相关文档与原始问题合成提示,输入到模型中,生成最终回答。
接下来,我们将深入基本RAG的每个阶段。
索引 (Indexing)
整个索引阶段围绕一个叫做 Retriever(检索器 )的组件展开,我们有一些外部的文档要加载到系统中, Retriever 接收用户输入的问题 query ,目的是检索与输入问题相关的文档 documents 。
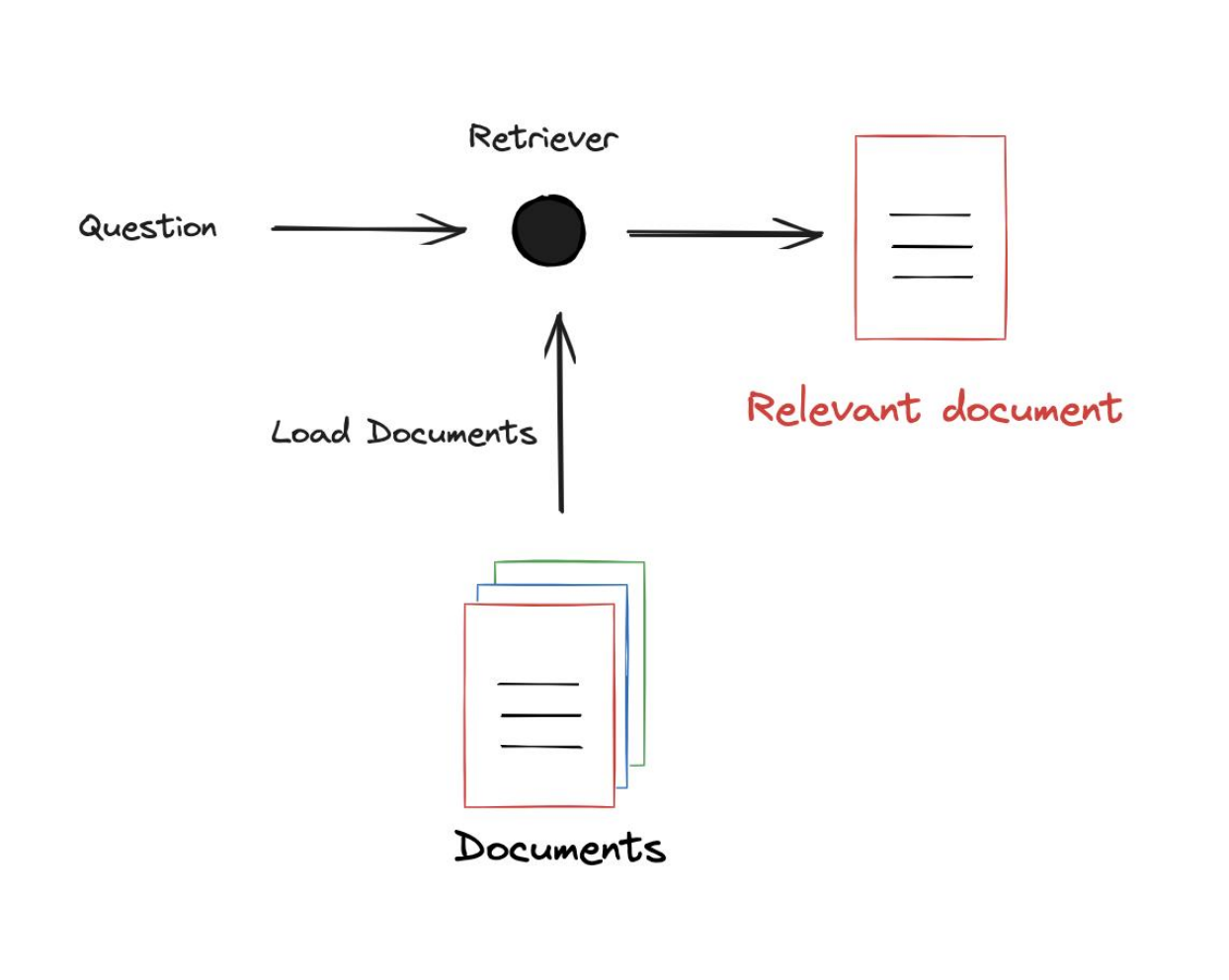
这个过程中,自然会引发一个思考,如何建立 question 与 documents 之间的关联?通常是使用数字表示,将query和documents 都表示为一个数值向量,这样可以便于在大量示例中快速检索。
为什么要将文档转换为数字表示?
文本是离散的符号序列,相对于原始的文本,通常将文档转换为数字表示,比较数值向量之间的相似性要容易得多。
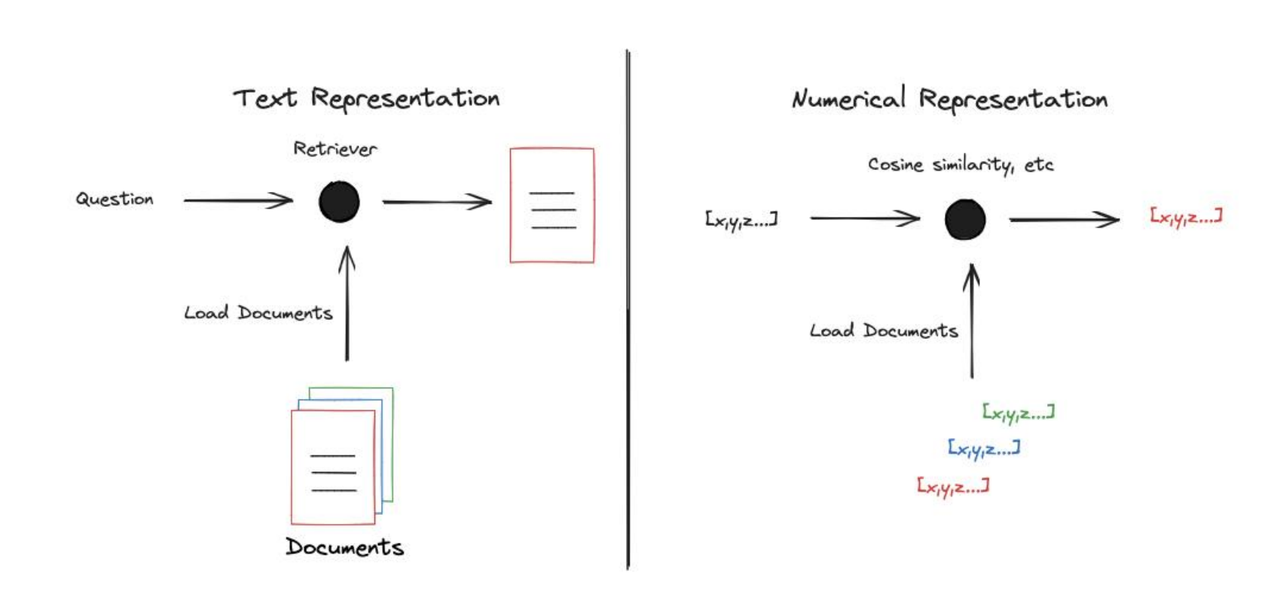
近些年来,已经有大量方法可以实现从文本到数值向量的转换。典型方法包括:
- 基于统计的方法 :比如TF-IDF,词袋模型等方法,会将文档表示为一个稀疏向量。
- 基于机器学习的方法,word2vec,glove,BERT等方法,会将文本表示为一个稠密向量。
这里不对文本转换向量的方法做过多赘述,如果想要了解更多可以参考这里。
加入将文本转换为数值向量这一步之后,整个 Indexing 阶段的流程应该包括以下步骤:
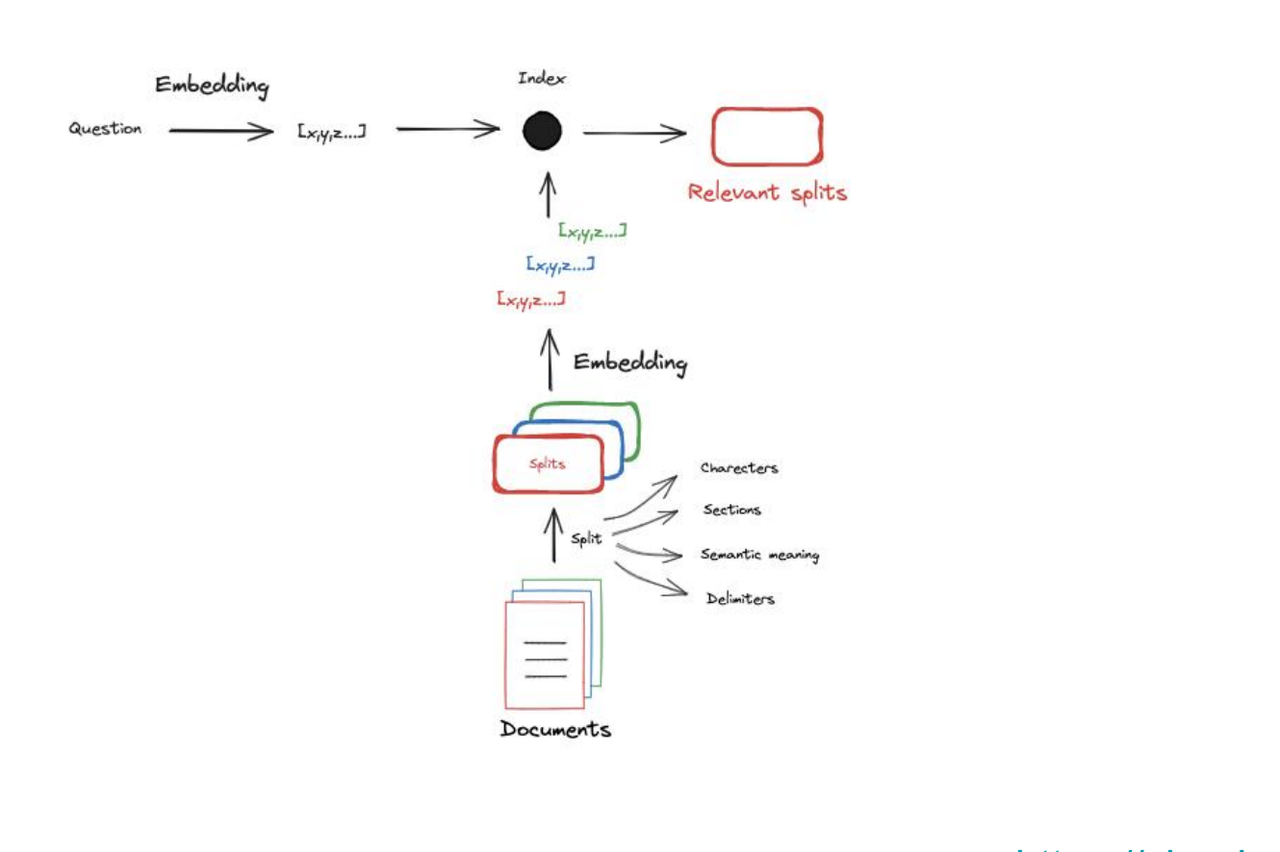
- 文档加载, 文档的加载涉及将原始文档导入到系统的过程中,是整个indexing 的起点。
# Documents question = "What kinds of pets do I like?" document = "My favorite pet is a cat." - 分块,由于文档最终要作为额外的上下文喂入LLM,要将文档长度其限制在LLM的下文窗口之内。因此,要对文档进行分块,也就是将大的文档切片为小的文本块。
- 嵌入, 前面已经说过,为了建立输入问题与文档之间的关系,要将其转换为数值向量。这一过程称为嵌入。
- 检索,在得到问题与文档的嵌入之后,可以使用不同的衡量向量相关性的方法,用于检索相关文档。检索这一过程将在下一节详述。
到现在为止,Indexing 过程中的基本理论已经掌握了,我们将使用langchain 实现这一过程。
首先需要安装环境
! pip install langchain_community tiktoken langchain-openai langchainhub chromadb langchain
接下来需要配置环境,这里使用langsmith 做debug,如果不需要的话,可以将 langchain 有关的配置信息直接注释掉即可。如果需要开启,需要到平台申请账号,并生成api_key。
# 可选的平台配置
import os
os.environ['LANGCHAIN_TRACING_V2'] = 'true'
os.environ['LANGCHAIN_ENDPOINT'] = 'https://api.smith.langchain.com'
os.environ['LANGCHAIN_API_KEY'] = <your-api-key>
# 配置OPEN_AI
os.environ['OPENAI_API_KEY'] = <your-api-key>
然后加载外部文档,需要借助 langchain 的document_loaders, 这里加载了一个外部网页作为文档。
import bs4
from langchain_community.document_loaders import WebBaseLoader
# 1. 加载外部文档
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
blog_docs = loader.load()
由于嵌入模型的上下文窗口有限,因此要对文档进行分块,这一过程借助text_splitters, 在这个库里包含多种可以切块的方法,这里采用一种基本的作为示例。
# 2. 分块,
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=300,
chunk_overlap=50)
# Make splits
splits = text_splitter.split_documents(blog_docs)
接下来将切块后的chunks转换为向量表示,并存储到 Chroma 中,然后创建了一个检索器,以便后续可以基于语义相似性搜索这些文档。
Chroma 是一个开源的向量数据库(vector database),用于存储和检索文本的向量嵌入(vector embeddings),更多内容可参考这里。
# Index
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=splits,
embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()
整个索引阶段到这里就结束了,目的就是让文档易于搜索。
检索 (Retrival)
回顾前面的 Indexing 阶段,就是将文档加载进来,分成小块,转换为易于搜索的数值向量形式,将其存储在向量数据库中。当给定一个输入的 query 时,我们会使用同样的嵌入方法 query 转换为向量,向量数据库会执行相似性搜索并返回与该问题相关的documents。
如果深入了解该过程,直觉就像是寻找某个点的邻居。
举个例子,假设文档获得的嵌入只有3个维度,每个文档都会成为3D空间中的一个点。点的位置是根据 document 的语义或者内容决定的。也就是说,位置相近的documents 拥有相似的语义或内容。我们将 query 做同样的嵌入,然后在 query 周围的空间去搜索。直观上来理解,就是哪些 documents 距离query 近, 这些documents与query具有相似的语义。
这部分我的理解就像是 word2vec 中提到的分布假说,拥有相似上下文的词在语义上相近。根据这个假说,提出了Word2Vec。按照假设语义空间只有3个维度的情况延伸,语义空间中相近的点,也拥有相似的语义。
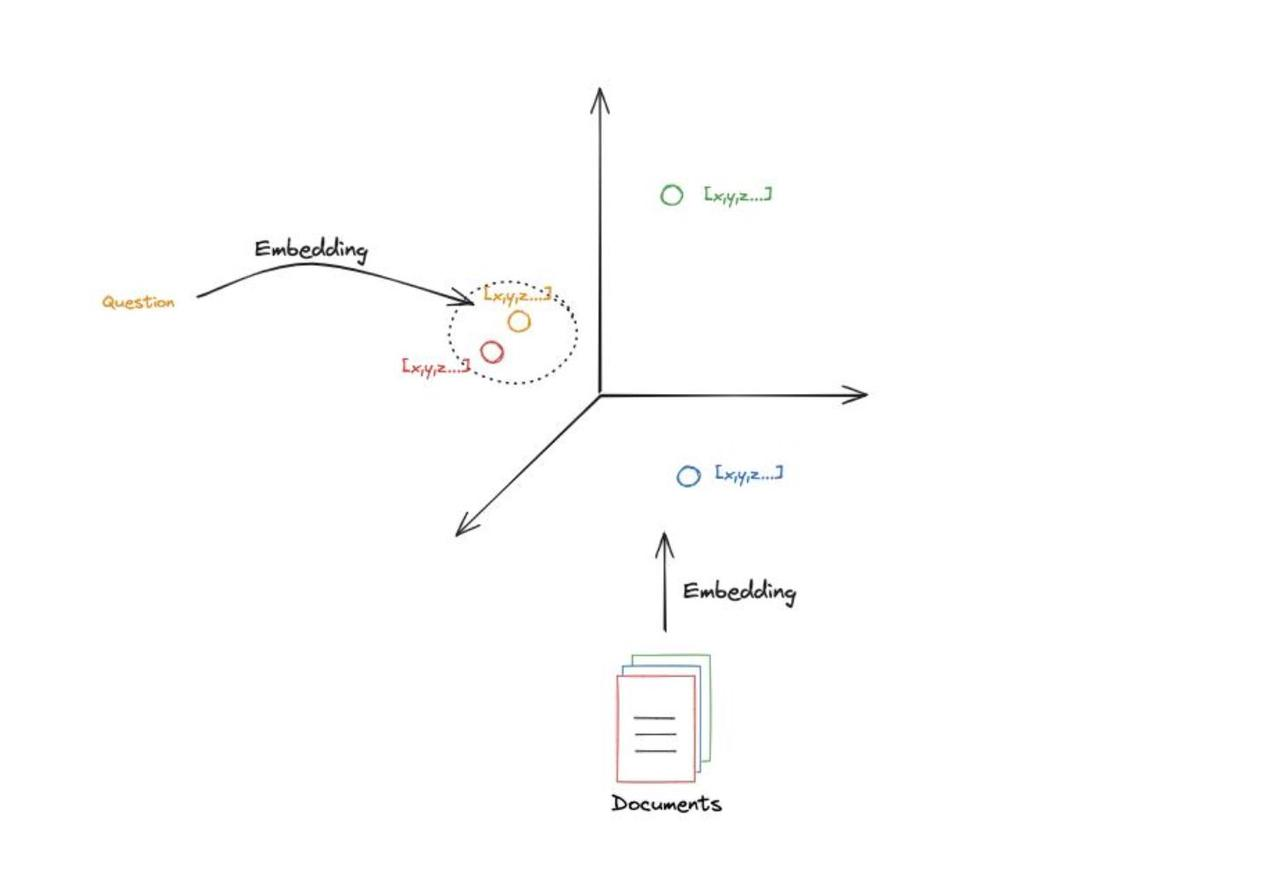
现在有很多现成的实现,比如上一节说过的langchain。在上一小节的代码中,已经实现了检索器Retriver,接下来只需要调用检索器的方法就可以拿到与问题相关的文档。
docs = retriever.get_relevant_documents("What is Task Decomposition?")
生成(Generation)
拿到了与query 相关的文档之后, 接下来要做的就是“生成”, 将检索到的文档填充到LLM的上下文窗口中去,让LLM根据上下文生成最终的答案。
如何将检索与LLM连接起来呢?答案是prompt。 某种程度上,可以直接将prompt理解为具有占位符的一个模板,其中包含一些keys, 每个key 都是可以被填充的。
我们接下来要做的是
- 将 query 和 检索到的组成字典
- 用字典的值填充prompt 模板
- 得到prompt string 后,输入到LLM,得到最终答案,
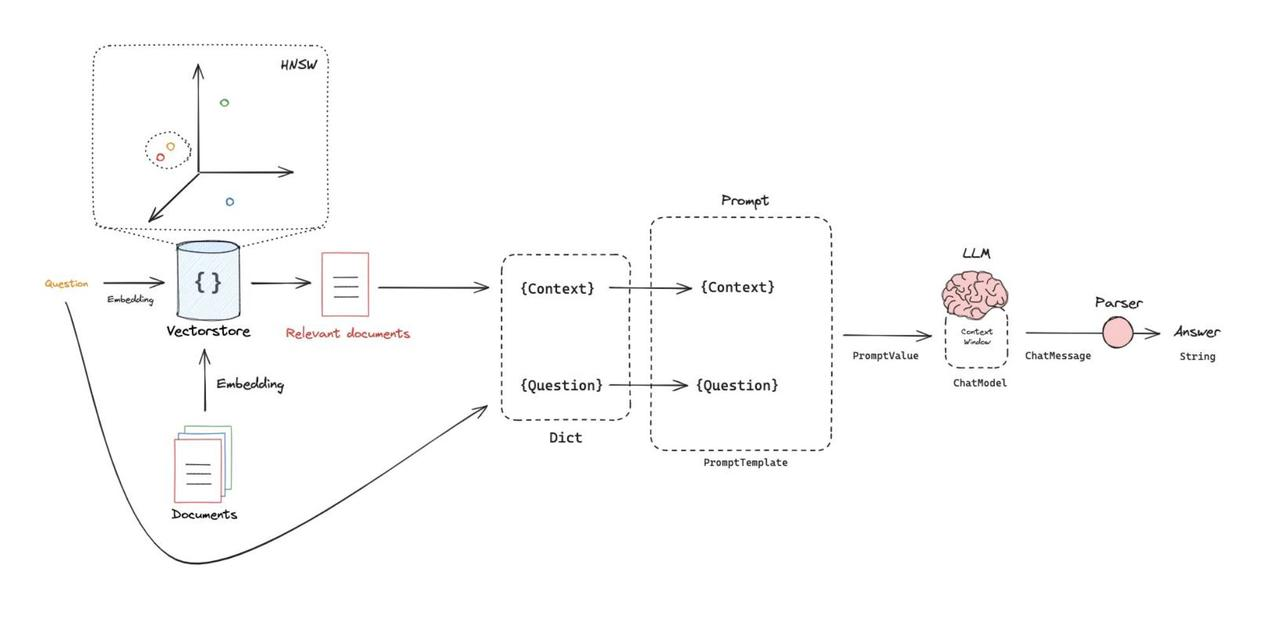
以上过程可以实现为
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
# Prompt
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
# 定义 prompt 模板
prompt = ChatPromptTemplate.from_template(template)
# 定义 LLM
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# 定义Chain
# 在LangChain 中,有一个名为LCEL的表达式语言,它允许您以一种简洁的方式定义数据处理流程。
chain = prompt | llm
# 调用
chain.invoke({
"context":docs,"question":"What is Task Decomposition?"})
这里我们自定义了一个prompt 模板,让LLM根据给定的上下文来回答问题。实际上,在langchain hub 中,有很多已经定义好的prompt可以使用。
from langchain import hub
prompt_hub_rag = hub.pull("rlm/rag-prompt")
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
rag_chain = (
{
"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
rag_chain.invoke("What is Task Decomposition?")
迈向高级RAG的第一步—— Query Translation
在理解基本RAG的流程后,我们会发现一个关键事实:RAG的最终效果取决于流程中每个环节的协同优化。任何一个环节的误差都会沿着管道向下传递,模糊的查询会导致检索偏差,低质的索引会污染上下文,未经校准的生成可能放大错误。因此,高级RAG技术本质上是一套分阶段误差控制系统,我们将其拆解为四个优化方向:
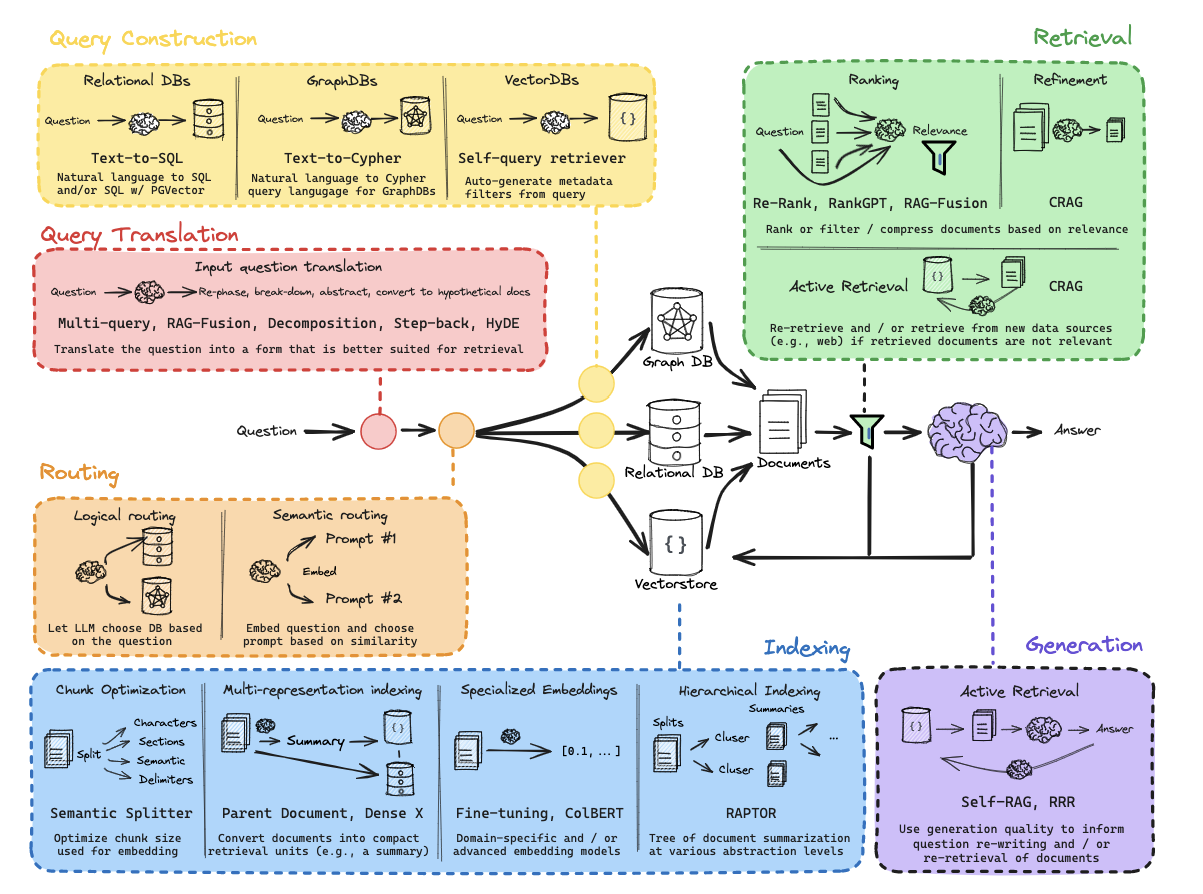
- 检索前优化:让问题更"容易被正确回答"(例如提问方式修正)
- Query Translation, 通过对原始问题进行翻译提高检索效率。
- Query 构建,将自然语言问题转换为结构化查询。
- 路由决策, 根据原始问题导向不同的数据源
- 检索优化:让数据更"容易被准确找到"(例如索引结构增强)
- 检索后优化:让证据更"容易被有效利用"(例如上下文净化)
- 生成优化:让答案更"容易被安全信赖"(例如结果验证)
接下来,我们将沿着这个"问题→数据→证据→答案"的优化链路,揭示每个环节的核心技术逻辑。
Query Translation
问题的陈述至关重要,如果用户输入的问题是含糊不清的话,那么只能得到一个含糊的答案。 因此,研究人员提出对原始的用户输入进行优化。这就是Query Translation, 是高级RAG的第一个阶段,目的是通过对用户输入进行翻译来提高检索效率。
从更高维的角度来看对 query的优化,可以朝着3个方向进行
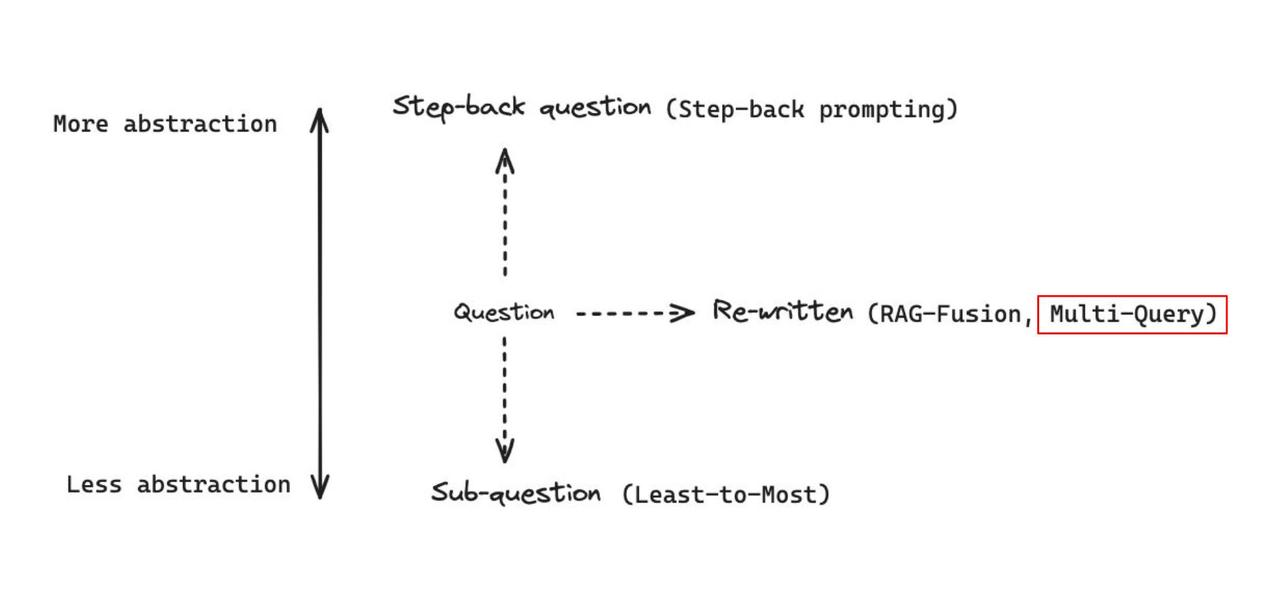
- 抽象化: 通过将具体问题抽象化,揭示问题的本质,也就是从更高的维度来看待问题。
- 具象化: 通过拆解复杂问题,让问题变得更具体。典型方法是将原始问题分解为多个有序的子问题,逐步解决,最终达成解决原始问题的任务。
- 重写: 从多个视角看待问题,同一个问题可能有100中写法,用不同的措辞来表达同一个问题。
Multi-Query(多重查询)
原理解析
Multi-Query 的基本思想是:针对不同的角度看待一个问题,从不同的视角,可以生成多个不同表述的 query,分别去做检索,将检索到的所有文档汇总后,输入到LLM中。
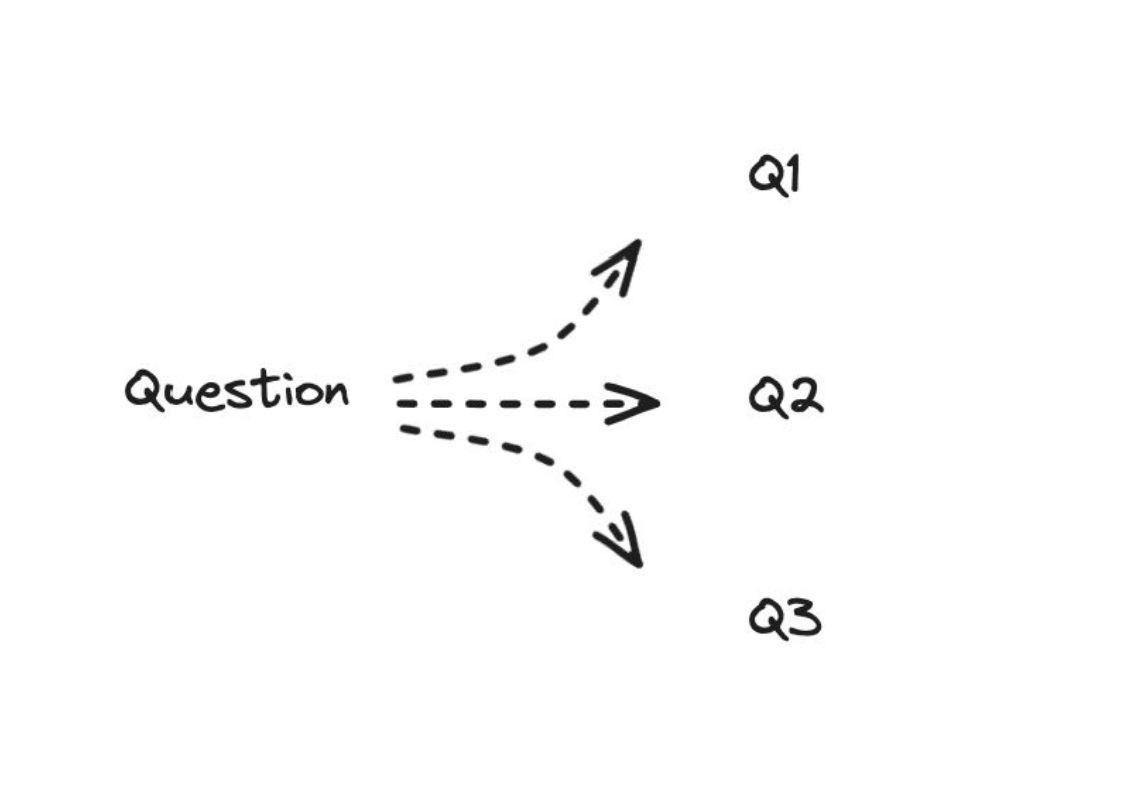
其背后的直觉是,根据原始question去检索,可能无法命中相关的文档。但是形成多个query之后,某一个query可能距离需要的文档很近。
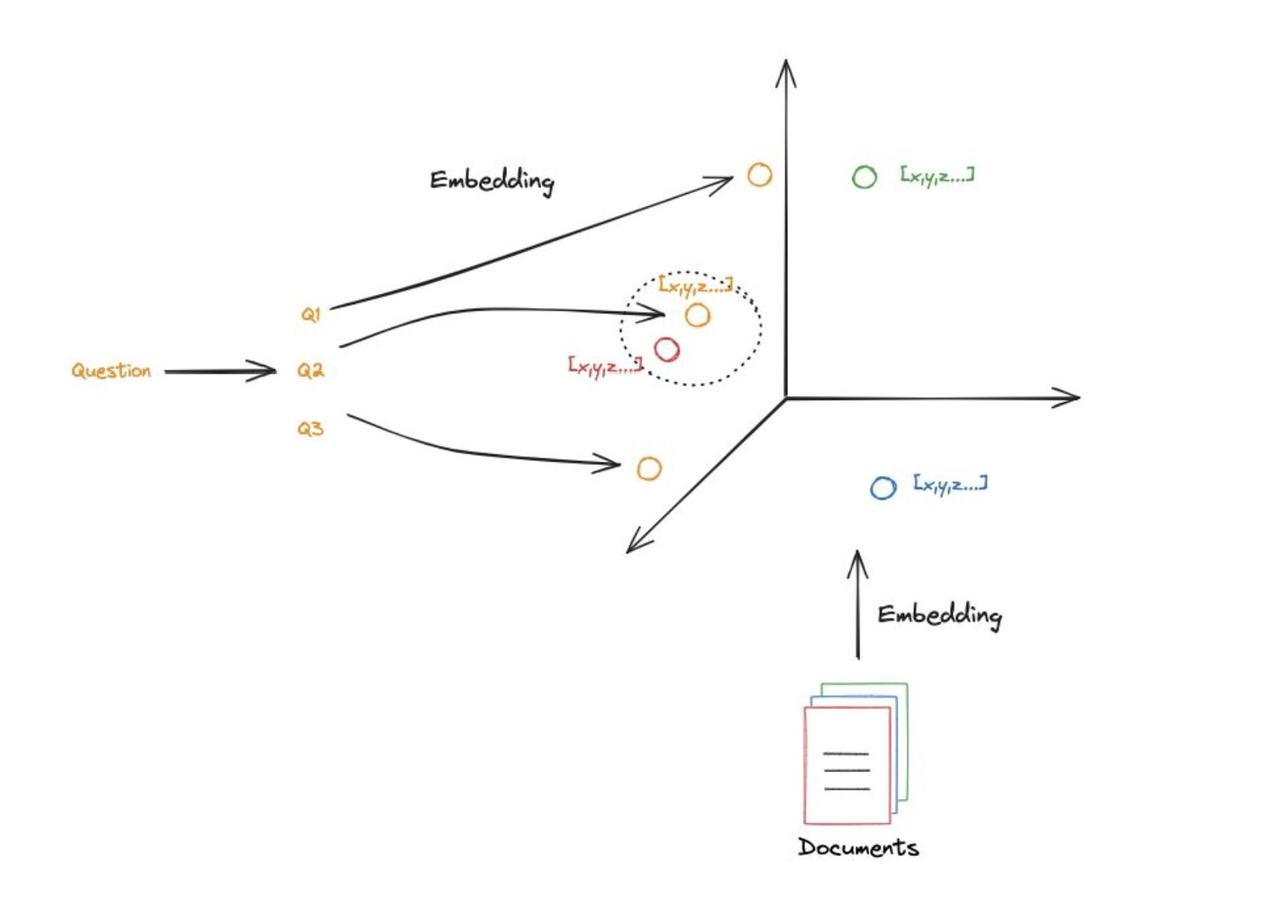
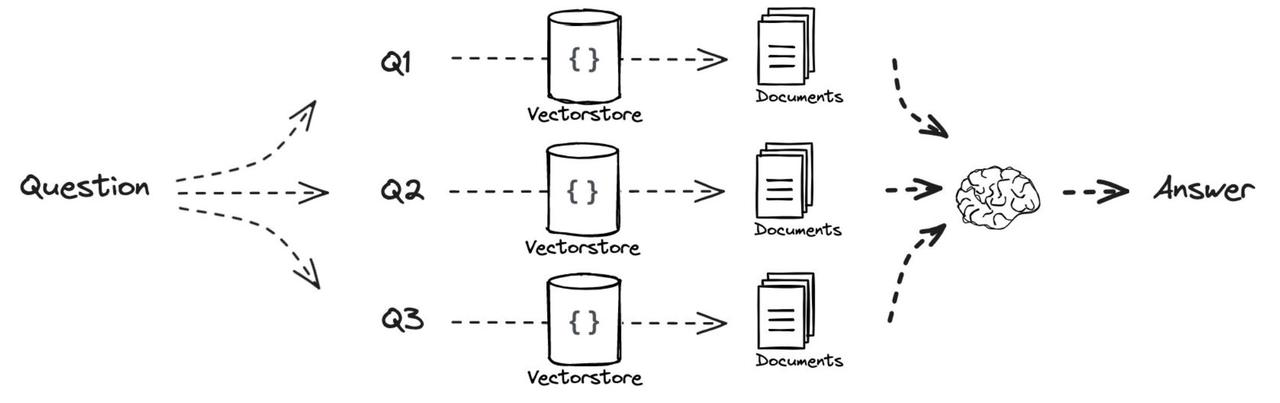
Multi-Query的流程
- 基于原始的用户 query 生成多个query,分别是Q1, Q2,Q3 ,这些生成的query是不同角度对原始 query 的补充。
- 对形成的每个query,Q1, Q2,Q3 ,都去检索一批相关文档。
- 所有的相关文档都会被喂给LLM,这样LLM就会生成比较完整和全面的答案。
代码实现
其核心实现如下,主要是让LLM根据给定的用户原始query,生成多个不同的视角的query。
#配置环境,构建索引, 构建检索器。
...
from langchain.prompts import ChatPromptTemplate
# Multi Query: Different Perspectives
template = """You are an AI language model assistant. Your task is to generate five
different versions of the given user question to retrieve relevant documents from a vector
database. By generating multiple perspectives on the user question, your goal is to help
the user overcome some of the limitations of the distance-based similarity search.
Provide these alternative questions separated by newlines. Original question: {question}"""
prompt_perspectives = ChatPromptTemplate.from_template(template)
from langchain_core.output_parsers import StrOutputParser
from langchain_opena 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5497
5497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









