




🚀 JPA 性能调优利器:被低估的 Tuple,告别脆弱的 Object[]
嘿,各位在 JPA (Java Persistence API, Java持久化API) 世界里追求代码艺术的伙伴们!👋
当我们在使用原生 SQL (Native SQL) 或 JPQL (Java Persistence Query Language, Java持久化查询语言) 进行复杂的、非标的查询时,最常用来接收结果的是什么?恐怕很多人会脱口而出:List<Object[]>。
Object[] 数组简单、直接,但它就像一个没有标签的盒子,你只能通过脆弱的索引位置 (obj[0], obj[1]) 来取用里面的东西。这不仅让代码可读性变差,更容易在 SELECT 子句顺序调整时,引发灾难性的数据错位 Bug。
今天,我想向大家隆重介绍一个经常被低估的“神器”——JPA Tuple 接口。在一次棘手的“导出功能数据错乱”Bug 修复中,正是 Tuple 帮助我们彻底摆脱了对顺序的依赖,让代码变得前所未有的健壮和清晰。
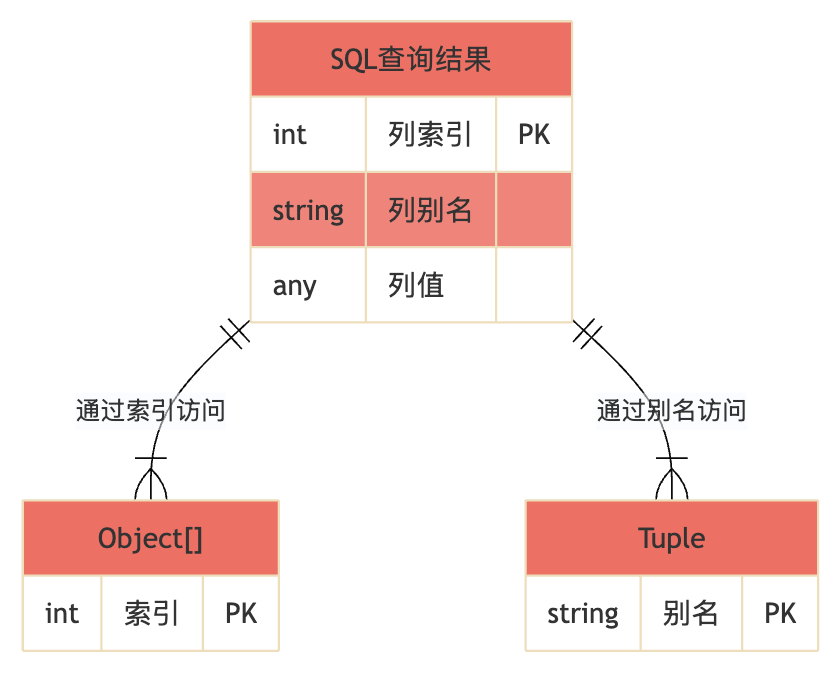
Tuple 是什么?—— 一个带标签的“万能盒子”
Tuple 是 JPA 规范 (javax.persistence.Tuple) 中定义的一个接口。你可以把它想象成一个动态的、带标签的数据容器。
与 Object[] 最大的不同在于:
Object[]: 通过索引 (index) 访问数据。result[0],result[1]…Tuple: 通过列别名 (alias) 或TupleElement访问数据。tuple.get("userName"),tuple.get("orderAmount")…
这种基于名称而非位置的访问方式,正是它强大的根源。
案发现场:Object[] 如何导致“张冠李戴”
在我们的 Bug 修复案例中,旧代码是这样工作的:
- SQL (Structured Query Language, 结构化查询语言) 查询:
SELECT p.code, p.name, b.name as brand FROM ... - 结果集: 返回
List<Object[]>。其中,obj[0]是code,obj[1]是name,obj[2]是brand。 - 数据解析:
// 脆弱的解析逻辑 for (Object[] obj : results) { // 错误地假设 obj[0] 永远是品牌,obj[1] 永远是品名... map.put("brand_id", obj[0]); map.put("name_id", obj[1]); // ... 灾难发生 }
这段代码的健壮性完全取决于 SELECT 子句的顺序永远不变,这在多人协作和长期维护的项目中,几乎是不可能的保证。
Tuple 登场:用“契约”取代“约定”
现在,让我们看看引入 Tuple 后的重构方案是如何力挽狂澜的。
第一步:在查询中明确“契约” - 使用别名
我们在原生 SQL 查询中,为每一列都赋予了一个明确的、与业务相关的别名 (Alias)。
// ProductSqlService.java
StringBuilder sql = new StringBuilder();
// 为每一列都赋予一个明确的别名
sql.append("SELECT DISTINCT ");
sql.append("p.code as code, ");
sql.append("p.name as name, ");
sql.append("b.name as brand "); // <-- 这就是“契约”
sql.append("... FROM product p INNER JOIN brand b ...");
这里的 as code, as name, as brand 就是我们和数据库之间建立的“数据契约”。
第二步:告诉 JPA 返回 Tuple
在创建查询时,我们多传递一个参数 Tuple.class,告诉 JPA 我们期望的返回类型。
// ProductSqlService.java
Query query = em.createNativeQuery(sql.toString(), Tuple.class);
List<Tuple> result = query.getResultList();
现在,result 不再是 List<Object[]>,而是一个 List<Tuple>。
第三步:基于“契约”进行安全解析
在解析数据时,我们彻底告别了脆弱的索引 i,转向了基于别名的安全访问。
// ProductSqlService.java
private List<HashMap<String, String>> parseToExportHashMapUsingTuple(List<Tuple> result) {
for (Tuple tuple : result) { // 每一个 tuple 就是一行数据
HashMap<String, String> map = new HashMap<>();
// 安全地、按名称获取数据
String codeValue = tuple.get("code", String.class);
String nameValue = tuple.get("name", String.class);
String brandValue = tuple.get("brand", String.class);
// ... 将获取到的值放入 map ...
}
return list;
}
或者,像我们的项目中那样,通过遍历 TupleElement 来动态处理所有列:
for (Tuple tuple : result) {
HashMap<String, String> map = new HashMap<>();
tuple.getElements().forEach(element -> {
String alias = element.getAlias(); // 获取列的别名
Object value = tuple.get(alias); // 根据别名获取值
// ... 后续映射逻辑 ...
});
list.add(map);
}
看到了吗? 无论 SELECT 子句中的 p.code, p.name, b.name 顺序如何颠倒,只要它们的别名 as code, as name, as brand 不变,tuple.get("code") 就永远能准确地拿到 p.code 的值。
顺序的隐式约定,被名称的显式契约所取代。代码的健壮性得到了质的飞跃。
Tuple 的更多优势
- 类型安全:
tuple.get("userName", String.class)可以在取值的同时进行类型转换,如果类型不匹配会立即报错,比手动强转(String)obj[0]更安全。 - 自解释性:
tuple.get("userName")这行代码本身就具有极高的可读性,任何人都能一眼看出它在获取什么数据,而obj[0]则需要读者去翻阅 SQL 才能理解其含义。 - 灵活性: 对于动态构建的、列不固定的查询,
Tuple更是如鱼得水。你可以通过tuple.getElements()动态地遍历所有返回的列,而无需事先知道有多少列。
总结:何时应该使用 Tuple?
虽然将结果映射到专门的 DTO (Data Transfer Object, 数据传输对象) 构造函数 (SELECT new com.example.MyDTO(...)) 是静态查询的最佳实践,但在以下场景中,Tuple 是你的不二之选:
- 执行原生 SQL 查询: 当你需要编写复杂的原生 SQL,特别是
SELECT列表是动态生成的,或者包含了多个表的字段时。 - 复杂的 JPQL/Criteria 查询: 当你的 JPQL 或 Criteria API (Application Programming Interface) 查询返回的是多个实体或聚合函数的组合,无法直接映射到一个 DTO 时。
- 需要高度灵活性的场景: 当你希望编写一个通用的数据处理方法,它能处理不同
SELECT子句返回的结果时。
下次当你准备写下 List<Object[]> 时,请停下来想一想:我是不是可以用 Tuple 来让我的代码更健壮、更清晰、更经得起未来的考验?
相信我,一旦你开始使用 Tuple,你就会爱上这种基于“契约”编程的安全感。
Happy Coding! 💻✨
总结与图表分析 📊
📝 Object[] vs Tuple 对比总结表
| 特性 (Feature) | List<Object[]> | List<Tuple> | 结论 (Conclusion) |
|---|---|---|---|
| 数据访问 | 按索引 (obj[0]) | 按别名 (tuple.get("name")) | ✅ Tuple 更直观、更安全 |
| 健壮性 | 脆弱 (依赖列顺序) | 健壮 (不依赖列顺序) | ✅ Tuple 完胜 |
| 可读性 | 差 (需要对照SQL) | 好 (代码自解释) | ✅ Tuple 更易于理解 |
| 类型安全 | 弱 (需手动强转) | 强 (get(alias, Type.class)) | ✅ Tuple 更安全 |
| 适用场景 | 简单、固定、内部使用的查询 | 复杂的原生SQL、动态列查询 | Tuple 适用范围更广 |
🗺️ 流程图:两种数据解析逻辑的对比
🔄 时序图:Tuple 如何在查询中工作
🚦 状态图:一个数据单元的生命周期
🏛️ 类图:JPA Tuple 核心接口
🔗 实体关系图:逻辑概念关系
🧠 思维导图 (Markdown Format)
- JPA (Java Persistence API) 神器
Tuple解析- 🎯 问题背景:
List<Object[]>的痛点- 访问方式: 依赖索引 (
obj[0],obj[1]) - 脆弱性: 对 SQL (Structured Query Language)
SELECT子句的列顺序有强依赖 - 可读性: 差,
obj[0]含义不明确,需要对照 SQL - 风险: 极易因 SQL 顺序调整导致数据错位 (张冠李戴)
- 访问方式: 依赖索引 (
- 💡 解决方案:引入
Tuple- 定义: JPA 规范中的接口,一个带**标签(别名)**的动态数据容器
- 核心优势: 从“依赖顺序”转向“依赖名称(契约)”
- 🛠️ 如何使用
Tuple- 第一步: 定义契约 (SQL)
- 动作: 在
SELECT子句中,为每一列都使用AS赋予一个明确的别名 - 示例:
SELECT p.name as productName, p.price as productPrice FROM ...
- 动作: 在
- 第二步: 获取
Tuple结果集 (Java)- 动作: 在创建查询时,指定返回类型为
Tuple.class - 示例:
em.createNativeQuery(sql, Tuple.class)
- 动作: 在创建查询时,指定返回类型为
- 第三步: 安全地解析 (Java)
- 动作: 遍历
List<Tuple>,使用tuple.get("别名")来获取数据 - 示例:
String name = tuple.get("productName", String.class);
- 动作: 遍历
- 第一步: 定义契约 (SQL)
- ✅
Tuple的收益- 健壮性: 代码不再受 SQL 列顺序调整的影响
- 可读性:
tuple.get("productName")让代码自解释 - 类型安全:
get(alias, Type.class)提供了编译时类型检查 - 灵活性: 通过
getElements()可以动态处理任意查询结果
- 🌟 最佳使用场景
- 复杂的原生 SQL 查询
- 返回多个实体或聚合结果的 JPQL (Java Persistence Query Language) / Criteria API (Application Programming Interface) 查询
- 需要处理动态列的通用数据服务
- 🎯 问题背景:



















 155
155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









