




🚀 “顺序”的陷阱:从一次导出功能的数据错乱,反思代码中的“隐形契约”
嘿,各位在代码世界里追求健壮与优雅的伙伴们!👋
今天,我想分享一个发生在我项目中的真实“悬案”。故事的主角是一个产品导出功能,它在某些时候工作正常,但在另一些时候,导出的 Excel 文件却出现了匪夷所思的“张冠李戴”现象——“品牌”列下全是“品名”,“资源代码”列下又是“条码”……一场彻头彻尾的“张冠李戴”惨案。
经过一番深入的调试和分析,我们发现“真凶”并非某个明显的 Bug,而是两个设计上看似独立、实则被一条 脆弱的“隐形顺序契约” 捆绑在一起的核心组件:ExportProductDto.java 和 ProductExportFieldEnum.java。
案发现场:两份看似无关的“清单”
要理解问题的根源,我们必须先看看这两个“主角”的代码。
清单 A:ProductExportFieldEnum - 业务字段的“元数据字典”
这是一个枚举类,它定义了我们系统中所有可供导出的产品字段。每个枚举都包含了字段的ID、用户可见的中文名、以及在实体类中对应的属性名。
ProductExportFieldEnum.java (部分代码):
public enum ProductExportFieldEnum {
// 注意这里的声明顺序
BRAND(1, "品牌", "brand", 256 * 15),
CATEGORY(2, "类目", "category", 256 * 15),
NAME(3, "名称", "name", 256 * 30),
JANCODE(4, "条码", "jancode", 256 * 15),
CODE(5, "资源代码", "code", 256 * 22),
// ... 其他30多个字段
}
这份清单定义了业务逻辑上的顺序。
清单 B:ExportProductDto - SELECT 子句的“蓝本”
这是一个 DTO (Data Transfer Object, 数据传输对象) 类,我们的一个工具方法 SqlUtil.sqlGenerate 会通过Java反射读取这个类的字段,来动态生成数据库查询的 SELECT 子句。
ExportProductDto.java (部分代码):
public class ExportProductDto {
// 注意这里的声明顺序
private String code;
private String name;
private String brand;
private String jancode;
private Integer carton;
// ... 其他30多个字段
}
这份清单定义了 SQL (Structured Query Language, 结构化查询语言) 查询语句中列的物理顺序。
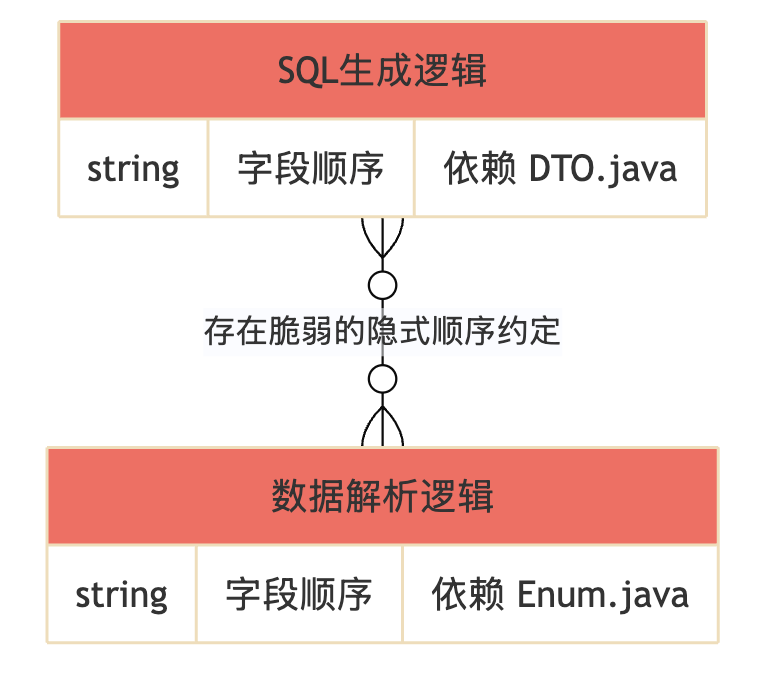
貌合神离的协作:问题的根源
我们的导出数据解析逻辑,就像一座建立在流沙之上的脆弱桥梁,它错误地假设了这两份“清单”的顺序是完全一致的。
ProductSqlService.java 中脆弱的解析逻辑 (伪代码):
// 1. 获取数据库返回的 Object[] 数组 (其顺序由 ExportProductDto 决定)
List<Object[]> results = database.query("SELECT " + SqlUtil.sqlGenerate(ExportProductDto.class) + "...");
// 2. 遍历数据并解析
for (Object[] row : results) {
Map<String, String> dataMap = new HashMap<>();
int i = 0;
// 3. 按照 ProductExportFieldEnum 的顺序进行遍历
for (ProductExportFieldEnum field : ProductExportFieldEnum.values()) {
// 4. 错误地假设第 i 个枚举对应 Object[] 中的第 i 个元素
dataMap.put(field.getId().toString(), row[i].toString());
i++;
}
// ...
}
看到了吗?这里存在一个致命的“跨空喊话”:
- 生产者 (
SqlUtil.sqlGenerate) 基于ExportProductDto的字段声明顺序来排列 SQL 列。 - 消费者 (
parseToExportHashMap) 基于ProductExportFieldEnum的枚举声明顺序来解析结果。
这两套顺序之间没有任何代码层面的强制关联,完全依赖于开发者在编写和维护时,能够“心有灵犀”地保持它们同步。
“惨案”复盘:当顺序不再同步
让我们看看实际代码中的顺序差异:
| 顺序 | ProductExportFieldEnum | ExportProductDto |
|---|---|---|
| 1 | BRAND | code |
| 2 | CATEGORY | name |
| 3 | NAME | brand |
| 4 | JANCODE | jancode |
| 5 | CODE | carton |
当解析逻辑开始工作时:
- 它期望的第一个字段是品牌 (BRAND),于是它取了
row[...][0],但这里面实际存放的是资源代码 (code) 的值。—— 第一次张冠李戴! - 它期望的第二个字段是类目 (CATEGORY),于是它取了
row[...][1],但这里面实际存放的是名称 (name) 的值。—— 第二次张冠李戴! - … 这个过程持续下去,导致了整个数据表的混乱。
结论与反思:警惕代码中的“隐形契约”
这次 Bug 的根源,是一个典型的设计缺陷——依赖于隐式的、脆弱的顺序约定。
- “隐形契约”是魔鬼:两个模块之间的协作,不应该依赖于开发者需要时刻记在脑子里的“潜规则”。这种契约非常容易在后续的代码重构、格式化或多人协作中被无意间破坏。
- 反射的顺序不可靠:Java 语言规范从未保证
Class.getDeclaredFields()的返回顺序。将核心逻辑建立在这样一个不确定的行为之上,无异于在沙滩上盖楼。 - 追求明确的“契约”:健壮的系统设计,应该建立在明确的、不易改变的“契约”之上。在这个场景下,这个“契约”应该是字段的名称 (或别名),而不是它们的物理顺序。
最终的解决方案 (回顾)
我们最终的解决方案是彻底抛弃对顺序的依赖,重构为基于别名的映射:
- 在 SQL 中:为每一个
SELECT的列都赋予一个与业务(ProductExportFieldEnum的property属性)对应的明确别名。 - 在 Java 中:使用 JPA (Java Persistence API, Java持久化API) 的
Tuple接口来接收结果集。 - 在解析时:遍历
Tuple的元素,通过element.getAlias()获取列的别名,再根据别名去查找对应的业务字段 ID,从而实现精确、健壮的映射。
这次重构的经历深刻地提醒我们,编写代码时不仅要关注“它现在能跑”,更要思考“它在未来是否依然健壮”。
Happy Coding, and beware of the invisible contracts! 💻✨
总结与图表分析 📊
📝 问题根源与解决方案总结表
| 方面 | 问题描述 (Problem) | 解决方案 (Solution) | 效果 (Effect) |
|---|---|---|---|
| SQL生成 | SqlUtil.sqlGenerate 基于反射顺序,不确定 | 手动编写 SELECT,为每列赋予明确别名 | ✅ 可控 & 健壮 |
| 数据解析 | parseToExportHashMap 基于枚举声明顺序,与SQL脱节 | parseToExportHashMapUsingTuple 基于列别名 | ✅ 精确 & 可靠 |
| 核心缺陷 | 隐式的、脆弱的顺序约定 | 显式的、基于名称的契约 | ✅ 设计升级 |
| Bug | 数据错位 (线上), SQL报错 (本地) | 全部解决 | ✅ 质量提升 |
🗺️ 流程图:脆弱的顺序依赖 vs 健壮的别名契约
🔄 时序图:数据解析流程的对比
🚦 状态图:一个数据字段的映射状态
🏛️ 类图:核心工具类与数据对象的关系
🔗 实体关系图:逻辑依赖关系
🧠 思维导图 (Markdown Format)
- Bug排查实录:修复导出功能数据错位
- 🎯 现象 (Bugs)
- 线上: 导出Excel数据列“张冠李戴”
- 本地: 执行导出时直接报 SQL (Structured Query Language) 错误
- 🤔 根本原因:脆弱的“隐形顺序契约”
- 生产者:
SqlUtil.sqlGenerate方法- 行为: 通过 Java 反射 读取
ExportProductDto.class的字段来生成SELECT列 - 问题: 反射返回的字段顺序不被 Java 规范保证
- 行为: 通过 Java 反射 读取
- 消费者:
parseToExportHashMap方法- 行为: 遍历
ProductExportFieldEnum.values(),按枚举声明顺序,通过递增索引从Object[]结果集中取值 - 问题: 错误地假设了两种顺序完全一致
- 行为: 遍历
- 冲突: 两套独立的、不可靠的顺序标准不一致,导致映射错乱和 SQL 报错
- 生产者:
- 💡 重构方案:拥抱“契约”而非“顺序”
- 核心技术: 引入 JPA (Java Persistence API)
Tuple - 步骤一: 修改 SQL 查询 (
exportList)- 动作: 手动编写
SELECT子句,为每一列都赋予一个与业务字段对应的明确别名 (Alias) - 效果: 建立 SQL 列与业务字段的“契约”,并解决
sql_mode报错
- 动作: 手动编写
- 步骤二: 修改结果集类型
- 动作: 调用
em.createNativeQuery(sql, Tuple.class) - 效果: 查询结果是
List<Tuple>,不再是List<Object[]>
- 动作: 调用
- 步骤三: 重构解析逻辑 (
parseToExportHashMapUsingTuple)- 动作: 遍历
Tuple结果,通过element.getAlias()获取列别名,再根据别名查找业务字段 ID (Identifier) 并进行映射 - 效果: 解析逻辑不再依赖顺序,变得极其健壮
- 动作: 遍历
- 核心技术: 引入 JPA (Java Persistence API)
- 🌟 经验反思
- 警惕隐式约定: 代码模块间的协作应建立在明确的接口或名称契约之上
- 反射的陷阱: 不要依赖反射返回成员的顺序
- 健壮性设计: 编写能适应环境变化和代码重构的、有容错性的代码
- 🎯 现象 (Bugs)



















 155
155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









