 -1
-1





下面的内容完美地展示了在详情页这种特定场景下,如何利用 JOIN FETCH这一“银弹”来优雅地解决@ManyToMany懒加载引发的N+1问题。
JPA JOIN FETCH的威力:如何为一个“详情页”接口根除N+1“幽灵”
在JPA (Java Persistence API) 的世界里,懒加载(FetchType.LAZY)是我们应对复杂实体关联、提升初次查询性能的“好友”。但这位“好友”有时却会变成一个名为“N+1查询”的“幽灵”,在你最不经意的时候(比如在循环中访问关联集合),悄无声息地拖垮你的应用性能。
尤其是在开发“详情页”接口时,我们既需要主实体的信息,又需要其关联的完整集合数据。这正是N+1问题最容易爆发的“犯罪现场”。
今天,我将带你深入解剖一个GET /api/app/demands/{demandId}(小程序查询需求详情)接口。我们将看到,如何通过**JOIN FETCH**这一JPA“神兵利器”,仅用一行JPQL (Java Persistence Query Language) 的改动,就将N+1“幽灵”彻底驱除,构建出一个既安全又具备极致性能的详情页API。
业务场景:一个需要展示完整关联的详情页 📝
我们的需求非常明确:在小程序端,用户点击一个“福利需求单”(SolutionDemand)后,进入详情页,需要展示该需求单的所有“希望类型”分类。
数据模型:
SolutionDemand与SolutionDemandCategory之间是@ManyToMany关联,默认懒加载。
核心挑战:
如何高效地查询一个SolutionDemand实体,并同时加载其关联的所有SolutionDemandCategory,以便在Service层提取它们的名称或ID?
错误的方案:不经意的N+1(性能灾难)
一个直观但错误的实现思路是这样的:
Repository层 (V1.0 - 存在陷阱)
// 只做一个简单的查询
Optional<SolutionDemand> findByIdAndSolutionUserId(Integer demandId, Integer userId);
Service层 (V1.0 - 触发N+1)
// 1. 查询主实体
SolutionDemand demand = demandRepository.findByIdAndSolutionUserId(...).orElseThrow(...);
// 2. 转换为VO
return convertToDetailVO(demand);
// 辅助方法
private AppDemandDetailVO convertToDetailVO(SolutionDemand entity) {
// ...
// 3. 访问懒加载集合,N+1在此爆发!
Set<Integer> categoryIds = entity.getCategories().stream()
.map(SolutionDemandCategory::getId)
.collect(Collectors.toSet());
vo.setCategoryIds(categoryIds);
// ...
}
会发生什么?
- 第一次
SELECT:findByIdAndSolutionUserId执行,从数据库加载SolutionDemand实体。此时,demand对象中的categories属性只是一个“空壳”代理。 - 第二次
SELECT:当convertToDetailVO方法中,代码第一次访问entity.getCategories()时,JPA为了初始化这个代理集合,会再次向数据库发起一次SELECT查询,去solution_demand_category_relation和solution_demand_category表中捞取所有关联的分类数据。
虽然在这个详情页场景下,N=1,总共只有2次查询。但这种编码模式本身就是一种“坏味道”,如果被不慎用到列表查询中,后果不堪设想。
正确的方案:JOIN FETCH——一次查询,全部搞定!🚀
为了根除N+1,我们需要告诉JPA:“嘿,在查询SolutionDemand的时候,请不要偷懒,顺便把它的categories集合也一并‘抓取’回来!”
JOIN FETCH就是下达这个命令的关键字。
Repository层 (V2.0 - 高性能版)
// SolutionDemandRepository.java
@Query("SELECT d FROM SolutionDemand d LEFT JOIN FETCH d.categories WHERE d.id = :demandId AND d.solutionUser.id = :currentUserId")
Optional<SolutionDemand> findDetailByIdAndUserId(@Param("demandId") Integer demandId, @Param("currentUserId") Integer currentUserId);
技术解读:
LEFT JOIN FETCH d.categories: 这是优化的核心。FETCH关键字告诉JPA,这不仅仅是一个普通的JOIN,而是要将JOIN到的categories数据,立即、完整地填充到返回的SolutionDemand实体的categories集合属性中。LEFT JOIN: 使用LEFT JOIN可以确保即使一个需求单没有任何关联分类,这个查询也能成功返回SolutionDemand实体本身。
Service层代码:
好消息是:Service层的代码完全不需要任何改动! 它依然是调用findDetailByIdAndUserId,然后调用convertToDetailVO。但这次,当convertToDetailVO访问entity.getCategories()时,由于数据已被预先加载,将不会再有任何数据库查询。
成果验证:一份“干净”的SQL日志 ✨
执行这个优化后的接口,我们得到的SQL日志,完美地证明了JOIN FETCH的威力:
【最终日志】
Hibernate:
select
-- 查询了 solution_demand, category_relation, category 三个表的 *所有* 字段
solutionde0_.id as id1_142_0_, solutionde2_.id as id1_143_1_, ...
from
solution_demand solutionde0_
left outer join
solution_demand_category_relation categories1_ on solutionde0_.id=categories1_.demand_id
left outer join
solution_demand_category solutionde2_ on categories1_.category_id=solutionde2_.id
where
solutionde0_.id=? and solutionde0_.solution_user_id=?
日志解读:
- 只有一条SQL:整个业务逻辑,从安全校验到获取所有需要的数据,都通过一次数据库交互完成。
LEFT JOIN:Hibernate正确地将JOIN FETCH翻译为了LEFT OUTER JOIN,将三张表关联起来。- N+1“幽灵”已消失:日志中再也看不到第二条
SELECT语句了。
结论:JOIN FETCH是详情页查询的“银弹” 💡
这次的实践告诉我们一个重要的JPA性能优化原则:
对于需要加载关联集合的“详情页”查询,JOIN FETCH是避免N+1问题的最佳武器。
| 方案 | SELECT查询次数 | 优点 | 缺点 |
|---|---|---|---|
| 懒加载 (默认) 🐌 | 1 + 1 | 编码直观 | 性能差,有N+1风险 |
JOIN FETCH 🚀 | 1 | 性能最优,无N+1,代码简洁 | 存在轻微的“过度查询”(加载了完整Category实体) |
虽然JOIN FETCH会加载关联实体的所有字段(一种可接受的“过度查询”),但在“详情页”这种单体查询场景下,用一次重量级的查询,换取代码的简洁性和N+1风险的彻底消除,是一笔非常划算的“交易”。
附录:图表化总结与深度解析 📊✨
优化方案对比总结表 📋
| 特性 | V1.0 (懒加载) 🐌 | V2.0 (JOIN FETCH) 🚀 |
|---|---|---|
| 核心思想 | 需要时再去查 | 一次性全部查回来 |
| DB (Database) 交互 | 2次 (1次查主表, 1次查关联) | 1次 |
| 性能 | 差,存在N+1风险 | 高,无N+1风险 |
| 代码复杂度 | 低,但隐藏风险 | 低,只需修改@Query注解 |
| 适用场景 | 不推荐用于详情页 | 详情页查询的最佳实践 |
| 一句话总结 | “跑两次腿才买齐东西” | “一张购物清单,一次买齐” |
接口处理流程图 (Flowchart) 💡
关键交互时序图 (Sequence Diagram) 🔄
此图对比了懒加载和JOIN FETCH的交互差异。
实体状态图 (State Diagram) 🚦
此接口为只读操作,不改变任何实体状态。
核心类图 (Class Diagram) 🏗️
展示了Repository查询与Entity关联的加载关系。
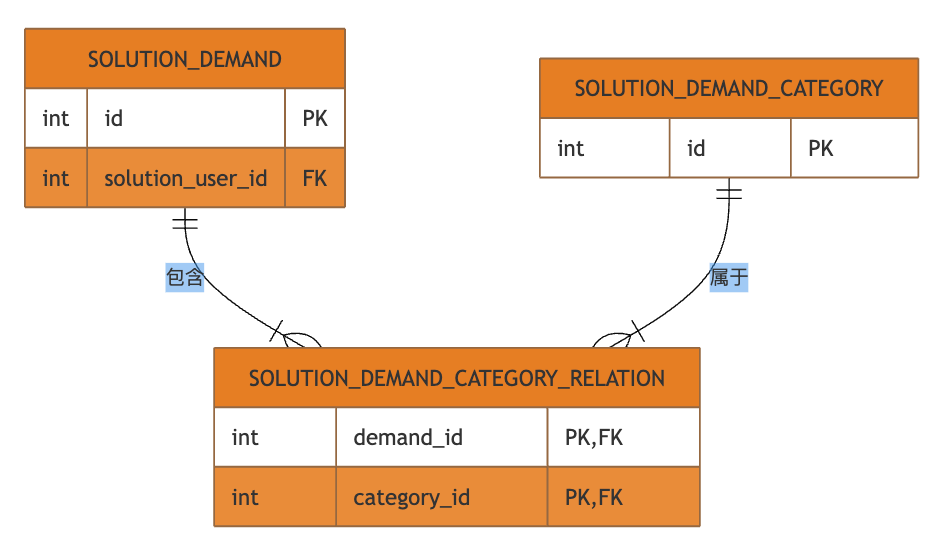
实体关系图 (Entity Relationship Diagram) 🔗
用ER图的形式更直观地展示JOIN FETCH查询涉及的所有数据库表。
思维导图 (Markdown Format) 🧠
- JPA (Java Persistence API) 详情页查询的N+1优化
- 问题场景:查询一个主实体,并需要展示其
@OneToMany或@ManyToMany关联的集合数据。 - 陷阱:懒加载 (Lazy Loading)
- 默认行为:JPA默认对集合使用懒加载 (
FetchType.LAZY)。 - N+1的产生:
find方法只查询主表 -> 在Service/VO (View Object) 转换层访问关联集合 -> 触发额外的SQL查询来加载该集合。
- 默认行为:JPA默认对集合使用懒加载 (
- 解决方案:“银弹”
JOIN FETCH- 核心思想:在查询主实体时,命令JPA立即、一次性地将关联集合的数据也一并查询并填充好。
- 实现:
- 在Repository方法上使用
@Query注解。 - 在JPQL (Java Persistence Query Language) 中,使用
JOIN FETCH关键字来连接要预加载的关联集合。 - 推荐:使用
LEFT JOIN FETCH以应对关联集合可能为空的情况。
- 在Repository方法上使用
- 成果 (通过SQL日志验证)
- 查询次数:从
1 + 1次(或1 + N次)减少到仅1次。 - SQL语句:Hibernate会生成一条包含
JOIN的SELECT语句,一次性获取所有数据。 - Service层:代码无需改变,访问关联集合时不再触发数据库查询。
- 查询次数:从
- 结论
JOIN FETCH是解决详情页场景下N+1问题的最佳实践。- 它用一次可控的“过度查询”(加载完整关联实体),彻底避免了多次不可控的懒加载查询。
- 问题场景:查询一个主实体,并需要展示其



















 155
155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









