




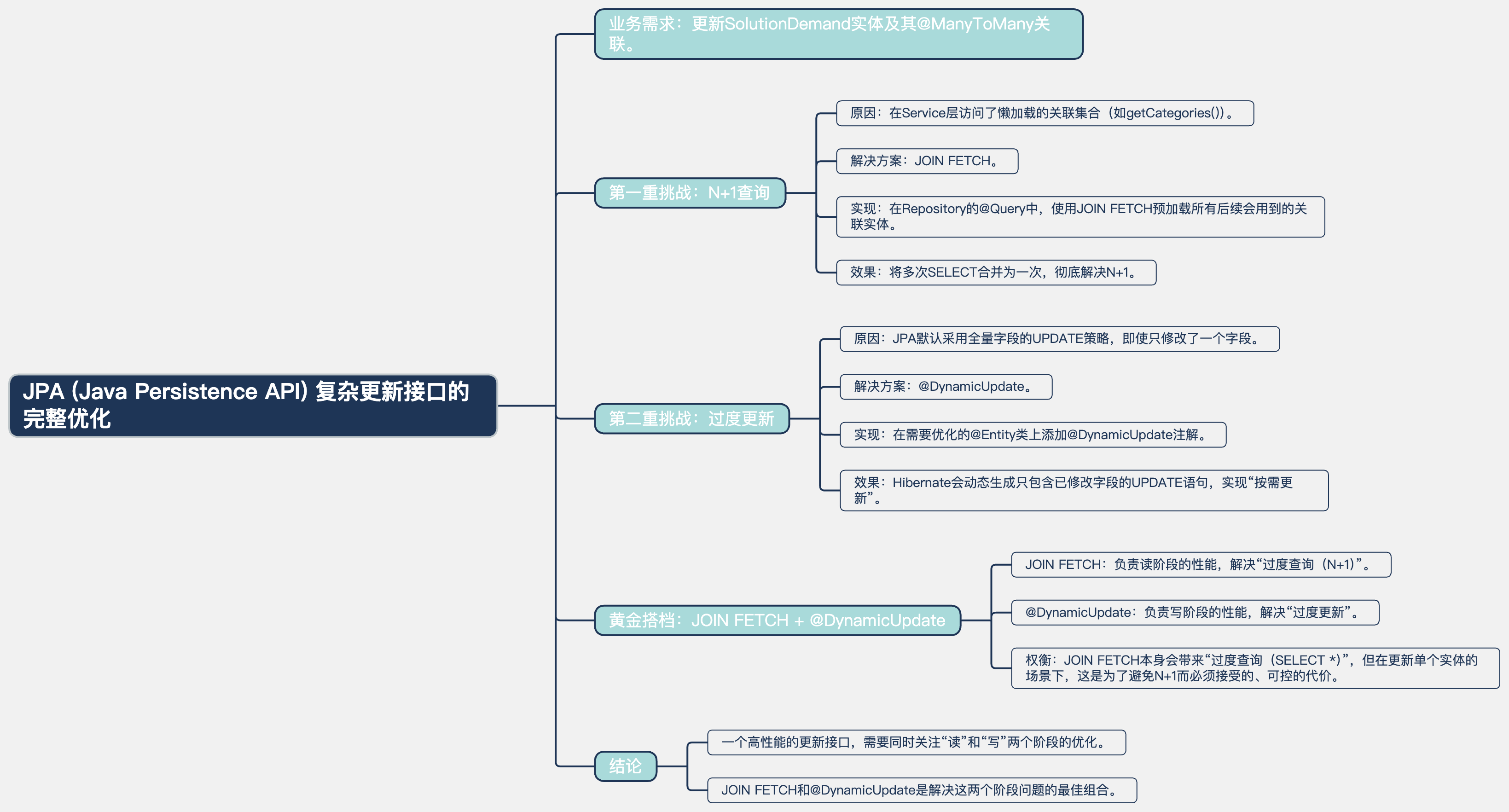
JPA JOIN FETCH的权衡艺术:从N+1到“精准更新”的完整优化之路
在JPA (Java Persistence API, Java持久化API) 的世界里,更新一个带有@ManyToMany关联的实体,是一项充满挑战的任务。一个直观的实现,往往会在不经意间,因为懒加载(FetchType.LAZY)而触发一系列灾难性的N+1查询。
JOIN FETCH是我们解决N+1问题的“银弹”,但它本身也并非毫无代价。今天,我将带你深入解剖一个updateDemandForApp(小程序修改需求)接口,我们将经历一场从解决N+1,到解决过度查询,再到实现精准更新的完整优化之旅。
业务场景:一个需要“改头换面”的需求单 📝
我们的需求是:小程序用户可以修改一个已存在的“福利需求单”(SolutionDemand)。他不仅可以修改基础字段(如男女数量),还需要能完全替换“希望类型”这个@ManyToMany关联的分类列表。
核心挑战:
- 性能(N+1):在执行“先清后增”的关联更新策略时,如何避免因访问懒加载集合而引发的N+1查询?
- 性能(精准更新):如果用户只修改了一个字段,如何避免
UPDATE所有字段?
第一步:用JOIN FETCH斩杀N+1“恶龙”
为了避免在调用demandToUpdate.getCategories().clear()和demandToUpdate.getSolutionUser().getAdmin()时触发懒加载,我们必须在查询时就将所有需要的数据“预加载”到内存中。JOIN FETCH是完成此任务的最佳武器。
Repository层:精心设计的JOIN FETCH查询
// SolutionDemandRepository.java
@Query("SELECT d FROM SolutionDemand d " +
"LEFT JOIN FETCH d.categories " + // 预加载categories
"JOIN FETCH d.solutionUser su " + // 预加载solutionUser
"JOIN FETCH su.admin " + // 预加载admin
"WHERE d.id = :demandId AND su.id = :currentUserId")
Optional<SolutionDemand> findByIdAndSolutionUserIdWithDetails(...);
技术解读:
- 通过一次功能强大的
SELECT查询,我们将Demand实体及其所有需要的关联对象(categories,solutionUser,admin)全部加载到了内存中。
Service层:清晰的业务逻辑编排
// AppSolutionDemandService.java
@Transactional
public void updateDemandForApp(...) {
// 1. 一次性加载所有需要的数据
SolutionDemand demandToUpdate = demandRepository
.findByIdAndSolutionUserIdWithDetails(demandId, currentUserId)
.orElseThrow(...);
// 2. 更新基础字段
demandToUpdate.setRemark(payload.getRemark()); // 假设只修改了remark
// 3. 更新@ManyToMany关联 (先清后增)
demandToUpdate.getCategories().clear(); // 安全!因为categories已被预加载
// ... (省略设置新categories的逻辑) ...
// 4. 事务提交时,JPA会自动执行UPDATE, DELETE, INSERT
}
成果与代价:N+1已死,但“过度更新”诞生
执行这个接口,我们得到的SQL (Structured Query Language) 日志如下:
【V1.0日志】
-- 1. 唯一的一次重量级SELECT,预加载所有数据
Hibernate:
select ... from solution_demand d
left outer join ...relation... c_rel on ...
left outer join ...category... c on ...
inner join solution_user su on ...
inner join admin a on ...
where d.id=? and su.id=?
-- 2. 更新主表 (问题所在!)
Hibernate:
update solution_demand set created_date=?, last_modified_date=?, delivery_city=?, demand_code=?, ... (所有字段) ... where id=?
-- 3. 清空旧关联 (DELETE) & 插入新关联 (INSERT)
-- ...
诊断:
- ✅ N+1问题已解决:日志中没有任何由懒加载触发的额外
SELECT。 - ❌ 新的性能问题:我们明明只修改了
remark这1个字段,但JPA生成的UPDATE语句却包含了所有字段。这就是 “过度更新”。
第二步:用@DynamicUpdate实现“精准更新”
这个“过度更新”问题的根源在于,Hibernate为了性能,会预先缓存好包含所有字段的UPDATE语句。当它检测到实体变“脏”时,就会直接使用这条缓存的语句。
要解决这个问题,我们只需要为SolutionDemand实体类添加一个简单的注解:@DynamicUpdate。
实体类修改
// SolutionDemand.java
import org.hibernate.annotations.DynamicUpdate; // 引入注解
@Entity
@Table(name = "solution_demand")
@DynamicUpdate // <-- 关键的优化注解!
@Data
public class SolutionDemand extends BaseEntity {
// ... 实体内容保持不变 ...
}
@DynamicUpdate的作用:
- 这个注解告诉Hibernate:“对于这个实体,请不要使用缓存的全量
UPDATE语句。” - “请在每次需要执行
UPDATE时,动态地生成一条只包含真正发生变化的字段的SQL语句。”
最终成果:一份“外科手术式”的SQL日志 🩺
添加@DynamicUpdate注解后,我们再次只修改remark字段并调用接口。
【V2.0最终日志】
-- 1. 重量级SELECT (不变,为解决N+1所必需)
Hibernate:
select ... from solution_demand d ... where d.id=? and su.id=?
-- 2. 精准的UPDATE!
Hibernate:
update solution_demand set last_modified_date=?, remark=? where id=?
-- 3. DELETE & INSERT (不变)
-- ...
日志解读:
UPDATE语句的SET子句中,现在只包含了两个字段:last_modified_date:由@LastModifiedDate自动更新。remark:我们唯一在代码中修改的那个字段。
- 所有其他没有变化的字段,都从
UPDATE语句中消失了。我们实现了**“按需更新”**!
结论:JOIN FETCH与@DynamicUpdate的黄金搭档 🤝
这次的实践,为我们揭示了在处理复杂更新时的一套“黄金搭档”策略:
JOIN FETCH负责“读”:在更新操作前,使用JOIN FETCH进行一次性的数据预加载,从根源上杜绝N+1查询。要接受它带来的可控的“过度查询”作为代价。@DynamicUpdate负责“写”:为实体添加@DynamicUpdate注解,让JPA的自动更新变得“智能”,实现精准的、按需的字段更新,避免“过度更新”。
| 策略 | 解决的问题 | 带来的“代价”/注意事项 |
|---|---|---|
JOIN FETCH | N+1查询 | 过度查询 (SELECT *) |
@DynamicUpdate | 过度更新 (UPDATE SET a,b,c…) | 轻微的运行时SQL生成开销(可忽略) |
通过将这两个强大的工具结合起来,我们构建了一个功能完整、逻辑严密、且在“读”和“写”两个层面都达到了高性能的更新接口。这正是在复杂的业务需求与极致的性能追求之间,寻找最佳平衡点的艺术。
附录:图表化总结与深度解析 📊✨
优化策略总结表 📋
| 优化工具 | 解决的核心问题 | 优化阶段 | 优点 |
|---|---|---|---|
JOIN FETCH | N+1查询 🐌 | 读 (SELECT) | 一次性加载对象图,避免多次DB (Database) 交互 |
@DynamicUpdate | 过度更新 ✍️ | 写 (UPDATE) | 生成只包含已修改字段的UPDATE语句,性能更高 |
| 组合使用 ✨ | N+1 和 过度更新 | 读 + 写 | 兼顾功能与性能,是复杂更新场景的最佳实践 |
| 一句话总结 | “先用JOIN FETCH把牛牵回来,再用@DynamicUpdate只割需要的肉” |
优化历程流程图 (Flowchart) 💡
关键交互时序图 (Sequence Diagram) 🔄
此图展示了最终方案中,Service层与数据库的完整交互。
实体状态图 (State Diagram) 🚦
以SolutionDemand实体在更新接口中的状态流转为例。
核心类图 (Class Diagram) 🏗️
展示了@DynamicUpdate注解在实体类上的应用。
实体关系图 (Entity Relationship Diagram) 🔗
用ER图的形式更直观地展示JOIN FETCH查询涉及的表关系。
思维导图 (Markdown Format) 🧠



















 155
155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









