







目录
一、逻辑回归
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
X, y = load_iris(return_X_y=True)
clf = LogisticRegression(random_state=0).fit(X, y)
print(clf.predict(X[:2, :]))
print(clf.predict_proba(X[:2, :]))
print(clf.score(X, y))输出结果为:
[0 0]
[[9.81789983e-01 1.82100025e-02 1.44245431e-08]
[9.71713219e-01 2.82867510e-02 3.01589159e-08]]
0.9733333333333334二、分类任务中的样本不均衡问题
使用生成合成样本来进行过采样补充数目少的类的样本:使用SMOTE(合成少数类过采样技术)
# 导入所需库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from imblearn.over_sampling import SMOTE
# 生成一个不平衡的数据集
X, y = make_classification(n_samples=1000, n_features=2, n_redundant=0,
n_clusters_per_class=1, weights=[0.9, 0.1],
random_state=42)
print("原始数据集中各类别样本数:", dict(zip(*np.unique(y, return_counts=True))))
# 可视化原始数据
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.scatter(X[y == 0][:, 0], X[y == 0][:, 1], label="类别 0", alpha=0.5)
plt.scatter(X[y == 1][:, 0], X[y == 1][:, 1], label="类别 1", alpha=0.5)
plt.title("原始数据分布")
plt.legend()
# 使用SMOTE进行过采样
smote = SMOTE(random_state=42)
X_res, y_res = smote.fit_resample(X, y)
print("过采样后数据集中各类别样本数:", dict(zip(*np.unique(y_res, return_counts=True))))
# 可视化过采样后的数据
plt.subplot(1, 2, 2)
plt.scatter(X_res[y_res == 0][:, 0], X_res[y_res == 0][:, 1], label="类别 0", alpha=0.5)
plt.scatter(X_res[y_res == 1][:, 0], X_res[y_res == 1][:, 1], label="类别 1", alpha=0.5)
plt.title("SMOTE过采样后数据分布")
plt.legend()
plt.show()输出结果为:
原始数据集中各类别样本数: {0: 895, 1: 105}
过采样后数据集中各类别样本数: {0: 895, 1: 895}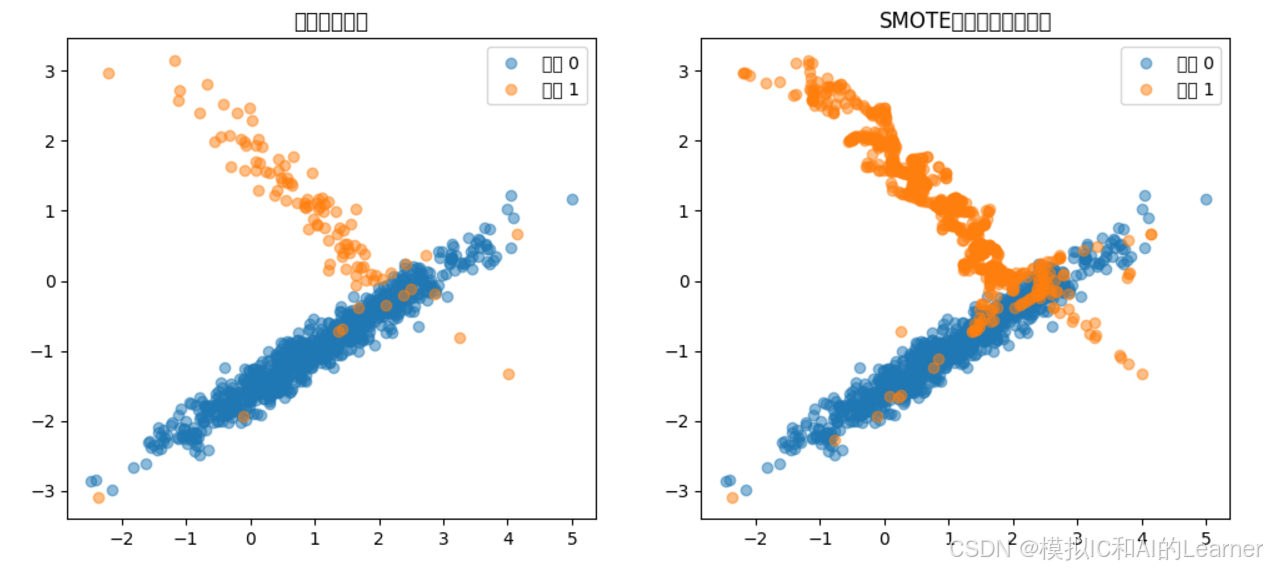
三、分类任务模型评估方法
1、cross_val_score交叉验证返回评分
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
X, y = load_iris(return_X_y=True)
clf_1 = LogisticRegression(random_state=0)
#交叉验证cross_val_score:返回每一折交叉验证后的模型评分
from sklearn.model_selection import cross_val_score
#scoring的参数可选:accuracy,f1,roc_auc,precision,recall
scores = cross_val_score(clf_1, X, y, cv=5, scoring='accuracy')
print("每折的准确率:", scores)
print("交叉验证的平均准确率:", scores.mean())输出结果为:
每折的准确率: [0.96666667 1. 0.93333333 0.96666667 1. ]
交叉验证的平均准确率: 0.9733333333333334scoring 是用来指定模型评估指标的参数。常见的评分方法有:
- 分类任务:
accuracy:准确率。f1:F1-score。roc_auc:ROC曲线下面积。precision:精确度。recall:召回率。
- 回归任务:
neg_mean_squared_error:负均方误差(因为cross_val_score默认最大化评分,因此使用负值)。r2:决定系数(R^2)。neg_mean_absolute_error:负均方误差。
2、cross_val_predict交叉验证返回预测值
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
X, y = load_iris(return_X_y=True)
clf_2 = LogisticRegression(random_state=0)
#交叉验证cross_val_predict:返回的是每个样本的预测结果
from sklearn.model_selection import cross_val_predict
predictions = cross_val_predict(clf_2, X, y, cv=5)
print("预测结果:", predictions)
输出结果为:
预测结果: [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1 1 1
1 1 1 2 1 1 1 1 1 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 1 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]cross_val_predict 会执行与交叉验证相同的过程,但它返回的是每个样本的预测结果。每个样本的预测是由对应的验证集预测得到的。这个方法的主要目的是获取交叉验证的预测结果,以便我们可以进一步分析或可视化这些预测,尤其是在模型调优或模型比较时非常有用。
cross_val_predict 的功能
- 评估模型:
cross_val_predict可以帮助你查看模型在每个折上预测的具体结果,而不仅仅是整体评分,这对于诊断和改进模型的表现非常有用。 - 生成完整的预测输出: 可以用于生成所有样本的预测输出,尤其是当你需要绘制混淆矩阵、绘制 ROC 曲线,或者进行进一步的分析时,这些预测结果非常关键。
- 避免数据泄漏: 与直接在训练集上预测不同,
cross_val_predict确保每个样本只会出现在一次验证集上,避免了数据泄漏问题。
3、混淆矩阵
#得到混淆矩阵
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y,predictions)
#展示混淆矩阵
from sklearn.metrics import ConfusionMatrixDisplay
import matplotlib.pyplot as plt
disp = ConfusionMatrixDisplay(confusion_matrix=cm)
disp.plot()
plt.show()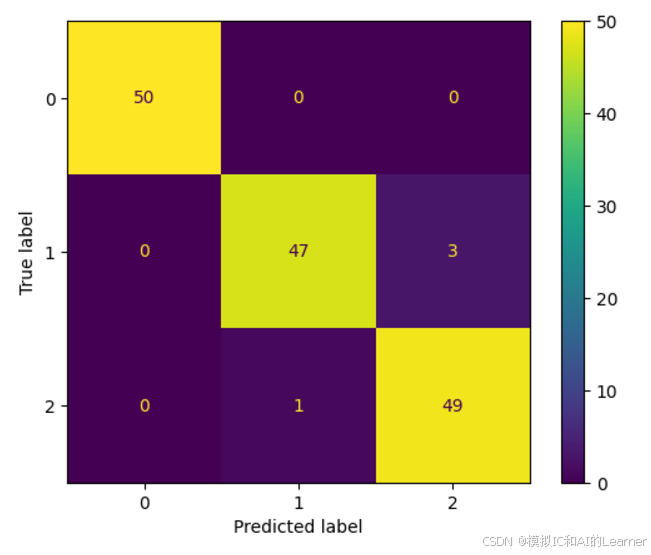
4、准确率,召回率,f1-得分
准确率:模型预测的正确率
召回率:模型预测对目标的找出能力
F1得分:两者的调和平均
#准确率,召回率,f1-得分
from sklearn.metrics import precision_score,recall_score,f1_score
precision_score_ = precision_score(y, predictions, average='macro')
recall_score_ = recall_score(y, predictions, average='macro')
f1_score_ = f1_score(y, predictions, average='macro')
print("宏平均精确率:", precision_score_)
print("宏平均召回率:", recall_score_)
print("宏平均F1分数:", f1_score_)宏平均精确率: 0.9738247863247862
宏平均召回率: 0.9733333333333333
宏平均F1分数: 0.9733226623982927评估函数(如 precision_score、recall_score、f1_score)默认是为二分类问题设计的,而此例的目标数据 y 是多分类(multiclass)数据。当目标变量包含多个类别时,默认参数 average='binary' 就无法处理,
需要指定合适的 average 参数来处理多分类情况。常用的选择有:
average=None:返回每个类别的指标分数。average='micro':计算全局指标,将所有类别的混淆矩阵元素累加后计算。适用于样本数不均衡时。average='macro':对每个类别计算指标,然后取均值,不考虑类别样本数差异。average='weighted':对每个类别计算指标,然后根据每个类别的样本数加权平均,适用于类别分布不均的情况。
5、准确率-召回率曲线
准确率-召回率曲线是针对两分类的,本例中为3分类,所以三种类别分别绘制准确率-召回率曲线。对每种类别均采用 "vs.其他" 来计算。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.preprocessing import label_binarize
from sklearn.model_selection import train_test_split
from sklearn.multiclass import OneVsRestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import precision_recall_curve, average_precision_score
# 1. 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 2. 将多分类标签二值化,转换为 One-vs-Rest 格式
# 这里将类别 0,1,2 分别转换为二进制形式
y_bin = label_binarize(y, classes=[0, 1, 2])
n_classes = y_bin.shape[1]
# 3. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y_bin, test_size=0.5, random_state=42)
# 4. 构造 One-vs-Rest 分类器并进行训练
classifier = OneVsRestClassifier(LogisticRegression(max_iter=200))
# 使用 decision_function 得到每个类别的得分
y_score = classifier.fit(X_train, y_train).decision_function(X_test)
# 5. 计算每个类别的准确率-召回率曲线和平均准确率
precision = dict()
recall = dict()
average_precision = dict()
for i in range(n_classes):
precision[i], recall[i], _ = precision_recall_curve(y_test[:, i], y_score[:, i])
average_precision[i] = average_precision_score(y_test[:, i], y_score[:, i])
# 6. 计算 micro-average 准确率-召回率曲线和平均准确率
precision["micro"], recall["micro"], _ = precision_recall_curve(y_test.ravel(), y_score.ravel())
average_precision["micro"] = average_precision_score(y_test, y_score, average="micro")
# 7. 绘制准确率-召回率曲线
plt.figure(figsize=(8, 6))
plt.plot(recall["micro"], precision["micro"],
label='micro-average Precision-recall curve (area = {0:0.2f})'
''.format(average_precision["micro"]), linestyle='--', color='gray')
colors = ['navy', 'turquoise', 'darkorange']
for i, color in zip(range(n_classes), colors):
plt.plot(recall[i], precision[i], color=color,
label='Class {0} (area = {1:0.2f})'
''.format(i, average_precision[i]))
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall Curve for Iris Dataset')
plt.legend(loc="lower left")
plt.grid(True)
plt.show()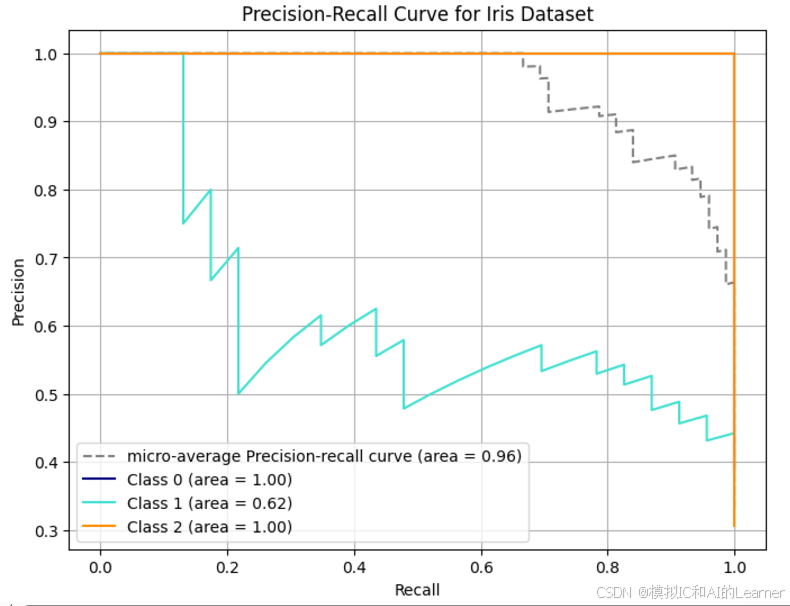
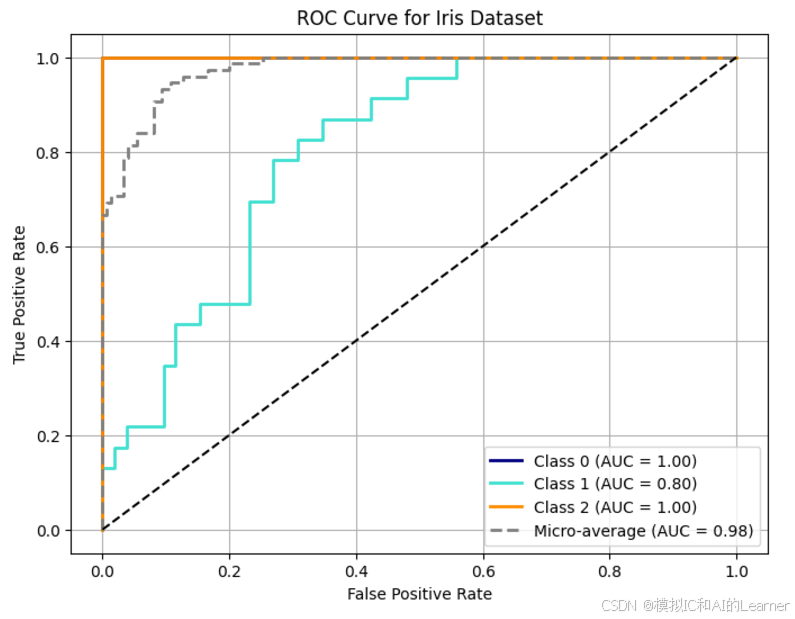
6、ROC曲线
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.preprocessing import label_binarize
from sklearn.model_selection import train_test_split
from sklearn.multiclass import OneVsRestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve, auc
# 1. 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 2. 将多分类标签二值化,转换为 One-vs-Rest 格式
y_bin = label_binarize(y, classes=[0, 1, 2])
n_classes = y_bin.shape[1]
# 3. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y_bin, test_size=0.5, random_state=42)
# 4. 构造 One-vs-Rest 分类器并进行训练
classifier = OneVsRestClassifier(LogisticRegression(max_iter=200))
y_score = classifier.fit(X_train, y_train).predict_proba(X_test)
# 5. 计算每个类别的 ROC 曲线和 AUC
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_test[:, i], y_score[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
# 6. 计算 micro-average 的 ROC 曲线和 AUC
fpr["micro"], tpr["micro"], _ = roc_curve(y_test.ravel(), y_score.ravel())
roc_auc["micro"] = auc(fpr["micro"], tpr["micro"])
# 7. 绘制 ROC 曲线
plt.figure(figsize=(8, 6))
# 绘制每个类别的 ROC 曲线
colors = ['navy', 'turquoise', 'darkorange']
for i, color in zip(range(n_classes), colors):
plt.plot(fpr[i], tpr[i], color=color, lw=2,
label='Class {0} (AUC = {1:0.2f})'.format(i, roc_auc[i]))
# 绘制 micro-average 的 ROC 曲线
plt.plot(fpr["micro"], tpr["micro"], color='gray', linestyle='--', lw=2,
label='Micro-average (AUC = {0:0.2f})'.format(roc_auc["micro"]))
# 绘制对角线(随机分类器)
plt.plot([0, 1], [0, 1], color='black', linestyle='--')
# 设置图像标签
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve for Iris Dataset')
plt.legend(loc='lower right')
plt.grid(True)
plt.show()


















 1093
1093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









