







目录
本文使用的数据集是:加利福尼亚住房数据集(回归)
一、线性回归
1、加载数据集
# 加载加州住房数据集
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()
X = housing.data
y = housing.target
print(type(X))
print(type(y))
print(X.shape)
print(y.shape)输出结果为:
<class 'numpy.ndarray'>
<class 'numpy.ndarray'>
(20640, 8)
(20640,)2、数据集各特征和标签可视化
#数据可视化
import seaborn as sns
from matplotlib import pyplot as plt
# 绘制特征X密度图
for col in range(0,8):
sns.kdeplot(X[:,col], fill=True)
# 设置图形标题和标签
plt.title(f'X-{col} Distribution')
plt.xlabel(col)
plt.ylabel('Density')
plt.show()
# 绘制标签y密度图
sns.kdeplot(y, fill=True)
# 设置图形标题和标签
plt.title('y Distribution')
plt.xlabel('y')
plt.ylabel('Density')
plt.show()输出结果为:
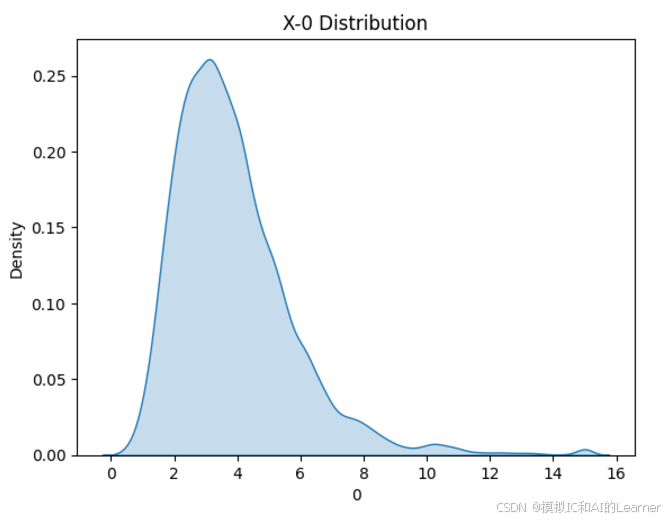
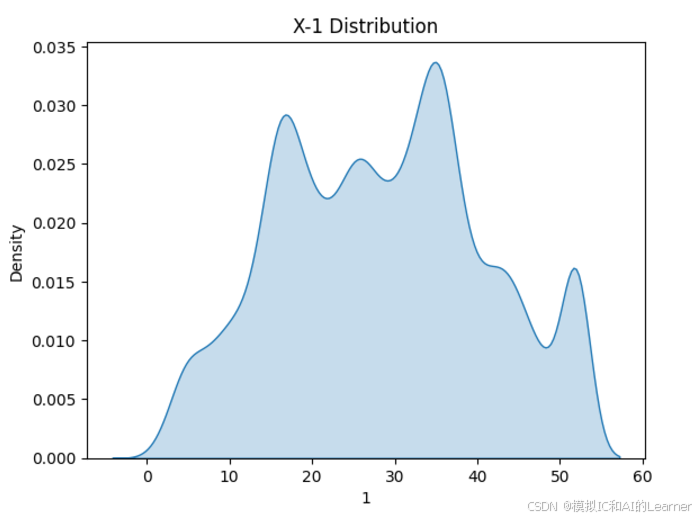
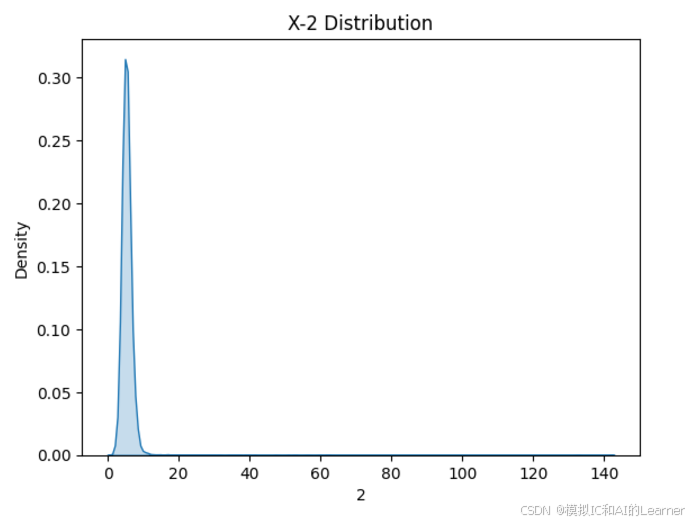
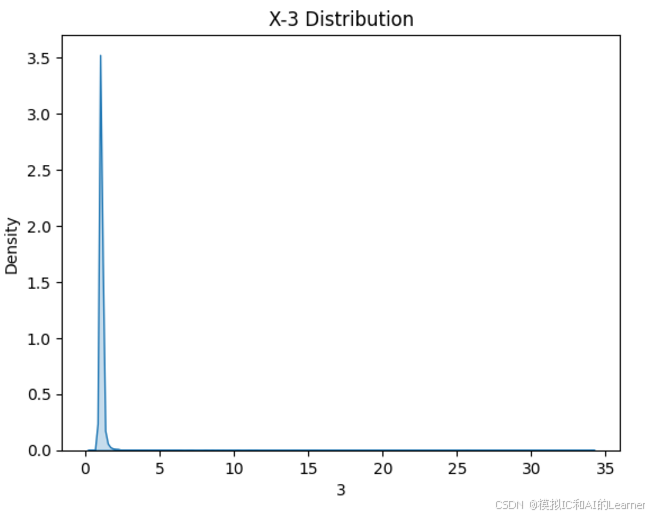
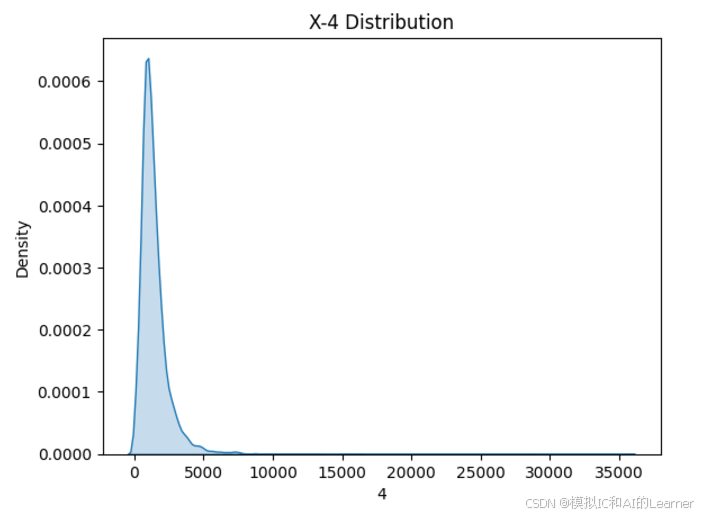
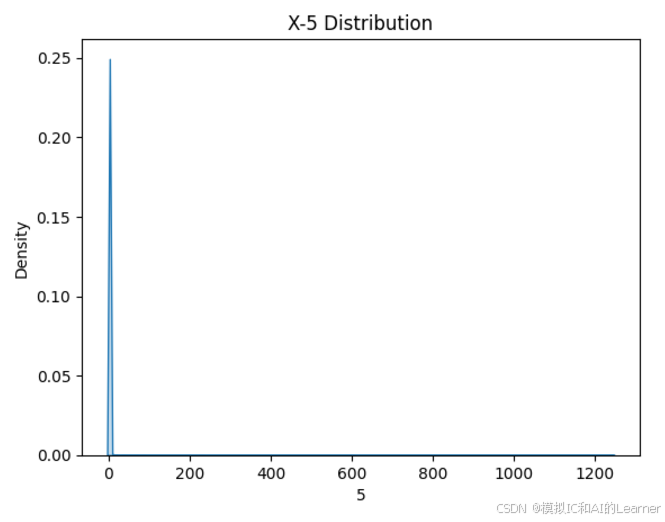
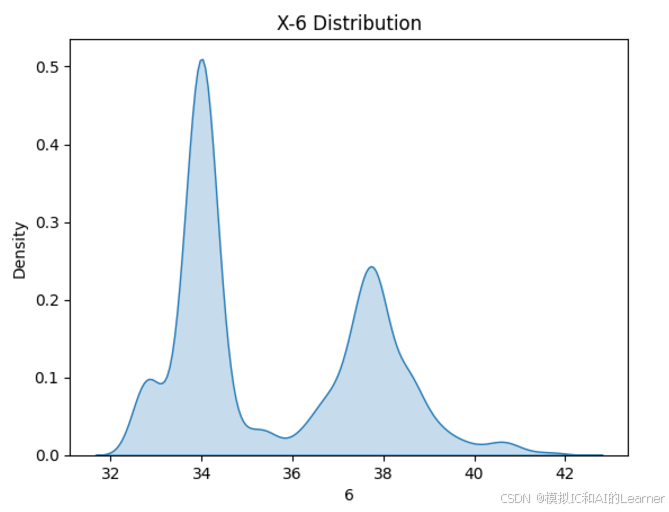
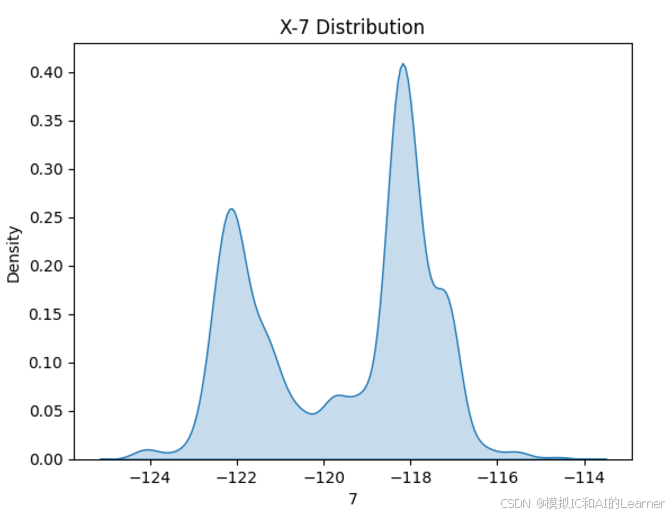
3、最普通的线性回归,数据未标准化,无正则化
#最普通的最小二乘,数据未标准化,无正则化
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
X_train_1, X_test_1, y_train_1, y_test_1 = train_test_split(X, y, test_size=0.2, random_state=42)
#训练模型
reg_1 = LinearRegression().fit(X_train_1, y_train_1)
print("R^2系数为:",reg_1.score(X_train_1, y_train_1))
print("权重为:",reg_1.coef_)
print("截距为:",reg_1.intercept_)
#计算均方误差
from sklearn.metrics import mean_squared_error
#在训练集上计算均方误差
y_pred_in_train_1 = reg_1.predict(X_train_1)
# 计算均方误差
mse_in_train_1 = mean_squared_error(y_train_1, y_pred_in_train_1)
print(f"训练集上的均方误差为: {mse_in_train_1}")
#在测试集上计算均方误差
y_pred_in_test_1 = reg_1.predict(X_test_1)
# 计算均方误差
mse_in_test_1 = mean_squared_error(y_test_1, y_pred_in_test_1)
print(f"测试集上的均方误差为: {mse_in_test_1}")输出结果为:
R^2系数为: 0.6125511913966952
权重为: [ 4.48674910e-01 9.72425752e-03 -1.23323343e-01 7.83144907e-01
-2.02962058e-06 -3.52631849e-03 -4.19792487e-01 -4.33708065e-01]
截距为: -37.02327770606391
训练集上的均方误差为: 0.5179331255246699
测试集上的均方误差为: 0.55589159869524224、最普通的线性回归,有标准化,无正则化
#有标准化,无正则化
#对X进行标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_standardized = scaler.fit_transform(X)
print(X_standardized[[0,1,2],:])
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
X_train_2, X_test_2, y_train_2, y_test_2 = train_test_split(X_standardized, y, test_size=0.2, random_state=42)
#训练模型
reg_2 = LinearRegression().fit(X_train_2, y_train_2)
print("R^2系数为:",reg_2.score(X_train_2, y_train_2))
print("权重为:",reg_2.coef_)
print("截距为:",reg_2.intercept_)
#计算均方误差
from sklearn.metrics import mean_squared_error
#在训练集上计算均方误差
y_pred_in_train_2 = reg_2.predict(X_train_2)
# 计算均方误差
mse_in_train_2 = mean_squared_error(y_train_2, y_pred_in_train_2)
print(f"训练集上的均方误差为: {mse_in_train_2}")
#在测试集上计算均方误差
y_pred_in_test_2 = reg_2.predict(X_test_2)
# 计算均方误差
mse_in_test_2 = mean_squared_error(y_test_2, y_pred_in_test_2)
print(f"测试集上的均方误差为: {mse_in_test_2}")
输出结果为:
[[ 2.34476576 0.98214266 0.62855945 -0.15375759 -0.9744286 -0.04959654
1.05254828 -1.32783522]
[ 2.33223796 -0.60701891 0.32704136 -0.26333577 0.86143887 -0.09251223
1.04318455 -1.32284391]
[ 1.7826994 1.85618152 1.15562047 -0.04901636 -0.82077735 -0.02584253
1.03850269 -1.33282653]]
R^2系数为: 0.6125511913966952
权重为: [ 0.85238169 0.12238224 -0.30511591 0.37113188 -0.00229841 -0.03662363
-0.89663505 -0.86892682]
截距为: 2.067862309508389
训练集上的均方误差为: 0.5179331255246699
测试集上的均方误差为: 0.555891598695244二、岭回归
1、岭回归 Ridge
#岭回归
import numpy as np
from sklearn.linear_model import Ridge
#对X进行标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_standardized = scaler.fit_transform(X)
print(X_standardized[[0,1,2],:])
from sklearn.model_selection import train_test_split
X_train_3, X_test_3, y_train_3, y_test_3 = train_test_split(X_standardized, y, test_size=0.2, random_state=42)
#训练模型
reg_3 = Ridge(alpha=1).fit(X_train_3, y_train_3)
print("R^2系数为:",reg_3.score(X_train_3, y_train_3))
print("权重为:",reg_3.coef_)
print("截距为:",reg_3.intercept_)
#计算均方误差
from sklearn.metrics import mean_squared_error
#在训练集上计算均方误差
y_pred_in_train_3 = reg_3.predict(X_train_3)
# 计算均方误差
mse_in_train_3 = mean_squared_error(y_train_3, y_pred_in_train_3)
print(f"训练集上的均方误差为: {mse_in_train_3}")
#在测试集上计算均方误差
y_pred_in_test_3 = reg_3.predict(X_test_3)
# 计算均方误差
mse_in_test_3 = mean_squared_error(y_test_3, y_pred_in_test_3)
print(f"测试集上的均方误差为: {mse_in_test_3}")
输出结果为:
[[ 2.34476576 0.98214266 0.62855945 -0.15375759 -0.9744286 -0.04959654
1.05254828 -1.32783522]
[ 2.33223796 -0.60701891 0.32704136 -0.26333577 0.86143887 -0.09251223
1.04318455 -1.32284391]
[ 1.7826994 1.85618152 1.15562047 -0.04901636 -0.82077735 -0.02584253
1.03850269 -1.33282653]]
R^2系数为: 0.612551119993334
权重为: [ 0.85231009 0.12246004 -0.3048709 0.37081855 -0.00227294 -0.03662725
-0.89588451 -0.86816501]
截距为: 2.067863077782602
训练集上的均方误差为: 0.5179332209751273
测试集上的均方误差为: 0.55585120073675142、带有内置交叉验证的岭回归 RidgeCV
RidgeCV 是基于 Ridge(岭回归)的一个扩展版本,其主要特点在于内置了交叉验证功能,用于自动选择最佳的正则化参数(α 值)。在 Ridge 回归中,通过添加 L2 正则化项来缓解多重共线性问题,并防止模型过拟合。而 RidgeCV 则在训练过程中,通过交叉验证来评估多个候选 α 值,从而确定一个在数据上表现最优的正则化强度。
#带内置交叉验证的岭回归
import numpy as np
from sklearn.linear_model import RidgeCV
#对X进行标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_standardized = scaler.fit_transform(X)
print(X_standardized[[0,1,2],:])
from sklearn.model_selection import train_test_split
X_train_4, X_test_4, y_train_4, y_test_4 = train_test_split(X_standardized, y, test_size=0.2, random_state=42)
#训练模型
reg_4 = RidgeCV(alphas=[1e-3,1e-2,1e-1,1]).fit(X_train_4, y_train_4)
print("R^2系数为:",reg_4.score(X_train_4, y_train_4))
print("权重为:",reg_4.coef_)
print("截距为:",reg_4.intercept_)
#计算均方误差
from sklearn.metrics import mean_squared_error
#在训练集上计算均方误差
y_pred_in_train_4 = reg_4.predict(X_train_4)
# 计算均方误差
mse_in_train_4 = mean_squared_error(y_train_4, y_pred_in_train_4)
print(f"训练集上的均方误差为: {mse_in_train_4}")
#在测试集上计算均方误差
y_pred_in_test_4 = reg_4.predict(X_test_4)
# 计算均方误差
mse_in_test_4 = mean_squared_error(y_test_4, y_pred_in_test_4)
print(f"测试集上的均方误差为: {mse_in_test_4}")
输出结果为:
[[ 2.34476576 0.98214266 0.62855945 -0.15375759 -0.9744286 -0.04959654
1.05254828 -1.32783522]
[ 2.33223796 -0.60701891 0.32704136 -0.26333577 0.86143887 -0.09251223
1.04318455 -1.32284391]
[ 1.7826994 1.85618152 1.15562047 -0.04901636 -0.82077735 -0.02584253
1.03850269 -1.33282653]]
R^2系数为: 0.6125511199933349
权重为: [ 0.85231009 0.12246004 -0.3048709 0.37081855 -0.00227294 -0.03662725
-0.89588451 -0.86816501]
截距为: 2.0678630777825378
训练集上的均方误差为: 0.5179332209751261
测试集上的均方误差为: 0.5558512007384657三、Lasso回归
1、Lasso回归
#Lasso回归
import numpy as np
from sklearn import linear_model
#对X进行标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_standardized = scaler.fit_transform(X)
print(X_standardized[[0,1,2],:])
from sklearn.model_selection import train_test_split
X_train_5, X_test_5, y_train_5, y_test_5 = train_test_split(X_standardized, y, test_size=0.2, random_state=42)
#训练模型
reg_5 = linear_model.Lasso(alpha=0.01).fit(X_train_5, y_train_5)
print("R^2系数为:",reg_5.score(X_train_5, y_train_5))
print("权重为:",reg_5.coef_)
print("截距为:",reg_5.intercept_)
#计算均方误差
from sklearn.metrics import mean_squared_error
#在训练集上计算均方误差
y_pred_in_train_5 = reg_5.predict(X_train_5)
# 计算均方误差
mse_in_train_5 = mean_squared_error(y_train_5, y_pred_in_train_5)
print(f"训练集上的均方误差为: {mse_in_train_5}")
#在测试集上计算均方误差
y_pred_in_test_5 = reg_5.predict(X_test_5)
# 计算均方误差
mse_in_test_5 = mean_squared_error(y_test_5, y_pred_in_test_5)
print(f"测试集上的均方误差为: {mse_in_test_5}")输出结果为:
[[ 2.34476576 0.98214266 0.62855945 -0.15375759 -0.9744286 -0.04959654
1.05254828 -1.32783522]
[ 2.33223796 -0.60701891 0.32704136 -0.26333577 0.86143887 -0.09251223
1.04318455 -1.32284391]
[ 1.7826994 1.85618152 1.15562047 -0.04901636 -0.82077735 -0.02584253
1.03850269 -1.33282653]]
R^2系数为: 0.6082259693662162
权重为: [ 0.79530412 0.12700165 -0.1593924 0.21628228 -0. -0.02829497
-0.79223 -0.75673715]
截距为: 2.067942536287589
训练集上的均方误差为: 0.5237149880961657
测试集上的均方误差为: 0.54793277955062、带有内置交叉验证的 Lasso回归
#Lasso回归
import numpy as np
from sklearn import linear_model
#对X进行标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_standardized = scaler.fit_transform(X)
print(X_standardized[[0,1,2],:])
from sklearn.model_selection import train_test_split
X_train_6, X_test_6, y_train_6, y_test_6 = train_test_split(X_standardized, y, test_size=0.2, random_state=42)
#训练模型
reg_6 = linear_model.LassoCV(cv=5, random_state=0).fit(X_train_6, y_train_6)
print("R^2系数为:",reg_6.score(X_train_6, y_train_6))
print("权重为:",reg_6.coef_)
print("截距为:",reg_6.intercept_)
#计算均方误差
from sklearn.metrics import mean_squared_error
#在训练集上计算均方误差
y_pred_in_train_6 = reg_6.predict(X_train_6)
# 计算均方误差
mse_in_train_6 = mean_squared_error(y_train_6, y_pred_in_train_6)
print(f"训练集上的均方误差为: {mse_in_train_6}")
#在测试集上计算均方误差
y_pred_in_test_6 = reg_6.predict(X_test_6)
# 计算均方误差
mse_in_test_6 = mean_squared_error(y_test_6, y_pred_in_test_6)
print(f"测试集上的均方误差为: {mse_in_test_6}")输出结果为:
[[ 2.34476576 0.98214266 0.62855945 -0.15375759 -0.9744286 -0.04959654
1.05254828 -1.32783522]
[ 2.33223796 -0.60701891 0.32704136 -0.26333577 0.86143887 -0.09251223
1.04318455 -1.32284391]
[ 1.7826994 1.85618152 1.15562047 -0.04901636 -0.82077735 -0.02584253
1.03850269 -1.33282653]]
R^2系数为: 0.6125069391599488
权重为: [ 0.84677361 0.12319172 -0.29057195 0.35575098 -0.00105138 -0.0358658
-0.8857684 -0.8573757 ]
截距为: 2.067869881926557
训练集上的均方误差为: 0.5179922809505753
测试集上的均方误差为: 0.5544062174455687四、最小角度回归LAR
1、LAR回归
#LAR回归
import numpy as np
from sklearn import linear_model
#对X进行标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_standardized = scaler.fit_transform(X)
print(X_standardized[[0,1,2],:])
from sklearn.model_selection import train_test_split
X_train_7, X_test_7, y_train_7, y_test_7 = train_test_split(X_standardized, y, test_size=0.2, random_state=42)
#训练模型
reg_7 = linear_model.Lars().fit(X_train_7, y_train_7)
print("R^2系数为:",reg_7.score(X_train_7, y_train_7))
print("权重为:",reg_7.coef_)
print("截距为:",reg_7.intercept_)
#计算均方误差
from sklearn.metrics import mean_squared_error
#在训练集上计算均方误差
y_pred_in_train_7 = reg_7.predict(X_train_7)
# 计算均方误差
mse_in_train_7 = mean_squared_error(y_train_7, y_pred_in_train_7)
print(f"训练集上的均方误差为: {mse_in_train_7}")
#在测试集上计算均方误差
y_pred_in_test_7 = reg_7.predict(X_test_7)
# 计算均方误差
mse_in_test_7 = mean_squared_error(y_test_7, y_pred_in_test_7)
print(f"测试集上的均方误差为: {mse_in_test_7}")输出结果为:
[[ 2.34476576 0.98214266 0.62855945 -0.15375759 -0.9744286 -0.04959654
1.05254828 -1.32783522]
[ 2.33223796 -0.60701891 0.32704136 -0.26333577 0.86143887 -0.09251223
1.04318455 -1.32284391]
[ 1.7826994 1.85618152 1.15562047 -0.04901636 -0.82077735 -0.02584253
1.03850269 -1.33282653]]
R^2系数为: 0.6125511913966952
权重为: [ 0.85238169 0.12238224 -0.30511591 0.37113188 -0.00229841 -0.03662363
-0.89663505 -0.86892682]
截距为: 2.067862309508389
训练集上的均方误差为: 0.5179331255246699
测试集上的均方误差为: 0.55589159869524462、交叉验证的最小角度回归模型
#LARCV回归
import numpy as np
from sklearn import linear_model
#对X进行标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_standardized = scaler.fit_transform(X)
print(X_standardized[[0,1,2],:])
from sklearn.model_selection import train_test_split
X_train_8, X_test_8, y_train_8, y_test_8 = train_test_split(X_standardized, y, test_size=0.2, random_state=42)
#训练模型
reg_8 = linear_model.LarsCV().fit(X_train_8, y_train_8)
print("R^2系数为:",reg_8.score(X_train_8, y_train_8))
print("权重为:",reg_8.coef_)
print("截距为:",reg_8.intercept_)
#计算均方误差
from sklearn.metrics import mean_squared_error
#在训练集上计算均方误差
y_pred_in_train_8 = reg_8.predict(X_train_8)
# 计算均方误差
mse_in_train_8 = mean_squared_error(y_train_8, y_pred_in_train_8)
print(f"训练集上的均方误差为: {mse_in_train_8}")
#在测试集上计算均方误差
y_pred_in_test_8 = reg_8.predict(X_test_8)
# 计算均方误差
mse_in_test_8 = mean_squared_error(y_test_8, y_pred_in_test_8)
print(f"测试集上的均方误差为: {mse_in_test_8}")输出结果为:
[[ 2.34476576 0.98214266 0.62855945 -0.15375759 -0.9744286 -0.04959654
1.05254828 -1.32783522]
[ 2.33223796 -0.60701891 0.32704136 -0.26333577 0.86143887 -0.09251223
1.04318455 -1.32284391]
[ 1.7826994 1.85618152 1.15562047 -0.04901636 -0.82077735 -0.02584253
1.03850269 -1.33282653]]
R^2系数为: 0.6125284264168372
权重为: [ 0.84829912 0.12295169 -0.29457668 0.36001341 -0.00140771 -0.03607767
-0.88897885 -0.86076655]
截距为: 2.0678677052360808
训练集上的均方误差为: 0.5179635572537357
测试集上的均方误差为: 0.5548051360099295五、弹性回归(L1+L2正则)
1、弹性回归
#弹性回归
import numpy as np
from sklearn import linear_model
#对X进行标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_standardized = scaler.fit_transform(X)
print(X_standardized[[0,1,2],:])
from sklearn.model_selection import train_test_split
X_train_9, X_test_9, y_train_9, y_test_9 = train_test_split(X_standardized, y, test_size=0.2, random_state=42)
#训练模型
reg_9 = linear_model.ElasticNet(alpha=0.1, l1_ratio=0.1).fit(X_train_9, y_train_9)
print("R^2系数为:",reg_9.score(X_train_9, y_train_9))
print("权重为:",reg_9.coef_)
print("截距为:",reg_9.intercept_)
#计算均方误差
from sklearn.metrics import mean_squared_error
#在训练集上计算均方误差
y_pred_in_train_9 = reg_9.predict(X_train_9)
# 计算均方误差
mse_in_train_9 = mean_squared_error(y_train_9, y_pred_in_train_9)
print(f"训练集上的均方误差为: {mse_in_train_9}")
#在测试集上计算均方误差
y_pred_in_test_9 = reg_9.predict(X_test_9)
# 计算均方误差
mse_in_test_9 = mean_squared_error(y_test_9, y_pred_in_test_9)
print(f"测试集上的均方误差为: {mse_in_test_9}")输出结果为:
[[ 2.34476576 0.98214266 0.62855945 -0.15375759 -0.9744286 -0.04959654
1.05254828 -1.32783522]
[ 2.33223796 -0.60701891 0.32704136 -0.26333577 0.86143887 -0.09251223
1.04318455 -1.32284391]
[ 1.7826994 1.85618152 1.15562047 -0.04901636 -0.82077735 -0.02584253
1.03850269 -1.33282653]]
R^2系数为: 0.5663150481219212
权重为: [ 0.72053917 0.15152293 -0.03202614 0.05370572 0. -0.02739113
-0.37827649 -0.33677859]
截距为: 2.0685307128041894
训练集上的均方误差为: 0.5797405944515618
测试集上的均方误差为: 0.5912701223053162、带交叉验证的弹性回归ElasticNetCV
#带交叉验证的弹性回归
import numpy as np
from sklearn import linear_model
#对X进行标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_standardized = scaler.fit_transform(X)
print(X_standardized[[0,1,2],:])
from sklearn.model_selection import train_test_split
X_train_10, X_test_10, y_train_10, y_test_10 = train_test_split(X_standardized, y, test_size=0.2, random_state=42)
#训练模型
reg_10 = linear_model.ElasticNetCV(cv=5, random_state=0).fit(X_train_10, y_train_10)
print("R^2系数为:",reg_10.score(X_train_10, y_train_10))
print("权重为:",reg_10.coef_)
print("截距为:",reg_10.intercept_)
#计算均方误差
from sklearn.metrics import mean_squared_error
#在训练集上计算均方误差
y_pred_in_train_10 = reg_10.predict(X_train_10)
# 计算均方误差
mse_in_train_10 = mean_squared_error(y_train_10, y_pred_in_train_10)
print(f"训练集上的均方误差为: {mse_in_train_10}")
#在测试集上计算均方误差
y_pred_in_test_10 = reg_10.predict(X_test_10)
# 计算均方误差
mse_in_test_10 = mean_squared_error(y_test_10, y_pred_in_test_10)
print(f"测试集上的均方误差为: {mse_in_test_10}")输出结果为:
[[ 2.34476576 0.98214266 0.62855945 -0.15375759 -0.9744286 -0.04959654
1.05254828 -1.32783522]
[ 2.33223796 -0.60701891 0.32704136 -0.26333577 0.86143887 -0.09251223
1.04318455 -1.32284391]
[ 1.7826994 1.85618152 1.15562047 -0.04901636 -0.82077735 -0.02584253
1.03850269 -1.33282653]]
R^2系数为: 0.6124786022650697
权重为: [ 0.84699182 0.12403155 -0.29038901 0.35484741 -0.00097329 -0.03606413
-0.87819697 -0.84980088]
截距为: 2.0678783701103045
训练集上的均方误差为: 0.5180301610942394
测试集上的均方误差为: 0.554245232686696六、Huber损失的回归—对异常值具有鲁棒性
参数epsilon 的作用与含义
-
定义阈值:
epsilon 定义了在损失函数中何时从二次(L2)损失转为线性(L1)损失的临界点。- 当预测误差
小于等于 epsilon 时,使用 L2 损失,模型对这些较小误差进行精确拟合;
- 当误差超过 epsilon 时,损失函数切换为 L1 损失,从而降低异常值对模型的影响。
- 当预测误差
-
鲁棒性调节:
- 较小的 epsilon:将阈值设定得较低,会使得更多的误差被认为是“异常”并使用 L1 损失,这增强了模型对异常值的鲁棒性,但可能牺牲一部分在正常数据上的拟合效率。
- 较大的 epsilon:阈值较高时,大部分误差依然在 L2 损失范围内,模型会更像传统的最小二乘回归,可能在异常值存在时表现不够鲁棒。
-
默认值与适用场景:
sklearn默认的 epsilon 值为 1.35。这个默认值在许多情况下能取得一个较好的平衡,假设残差大致服从正态分布。但如果数据的噪声分布或者异常值特性与正态分布有较大偏离,则可能需要通过交叉验证或其他方式调整 epsilon 以获得更好的模型表现。
#带交叉验证的弹性回归
import numpy as np
from sklearn import linear_model
#对X进行标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_standardized = scaler.fit_transform(X)
print(X_standardized[[0,1,2],:])
from sklearn.model_selection import train_test_split
X_train_11, X_test_11, y_train_11, y_test_11 = train_test_split(X_standardized, y, test_size=0.2, random_state=42)
#训练模型
reg_11 = linear_model.HuberRegressor(epsilon=5).fit(X_train_11, y_train_11)
print("R^2系数为:",reg_11.score(X_train_11, y_train_11))
print("权重为:",reg_11.coef_)
print("截距为:",reg_11.intercept_)
#计算均方误差
from sklearn.metrics import mean_squared_error
#在训练集上计算均方误差
y_pred_in_train_11 = reg_11.predict(X_train_11)
# 计算均方误差
mse_in_train_11 = mean_squared_error(y_train_11, y_pred_in_train_11)
print(f"训练集上的均方误差为: {mse_in_train_11}")
#在测试集上计算均方误差
y_pred_in_test_11 = reg_11.predict(X_test_11)
# 计算均方误差
mse_in_test_11 = mean_squared_error(y_test_11, y_pred_in_test_11)
print(f"测试集上的均方误差为: {mse_in_test_11}")输出结果为:
[[ 2.34476576 0.98214266 0.62855945 -0.15375759 -0.9744286 -0.04959654
1.05254828 -1.32783522]
[ 2.33223796 -0.60701891 0.32704136 -0.26333577 0.86143887 -0.09251223
1.04318455 -1.32284391]
[ 1.7826994 1.85618152 1.15562047 -0.04901636 -0.82077735 -0.02584253
1.03850269 -1.33282653]]
R^2系数为: 0.6125474458474925
权重为: [ 0.8554186 0.12299684 -0.30901178 0.37582821 -0.00230365 -0.03672557
-0.89469167 -0.86738322]
截距为: 2.0680122661277878
训练集上的均方误差为: 0.5179381324932351
测试集上的均方误差为: 0.5565907434185678

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









