







以下内容记录我在阅读DETR和Deformable DETR论文及源码过程中对网络结构、以及自注意力、可变形注意力的理解,可能存在一些错误,欢迎讨论~
代码理解DETR
重绘网络图
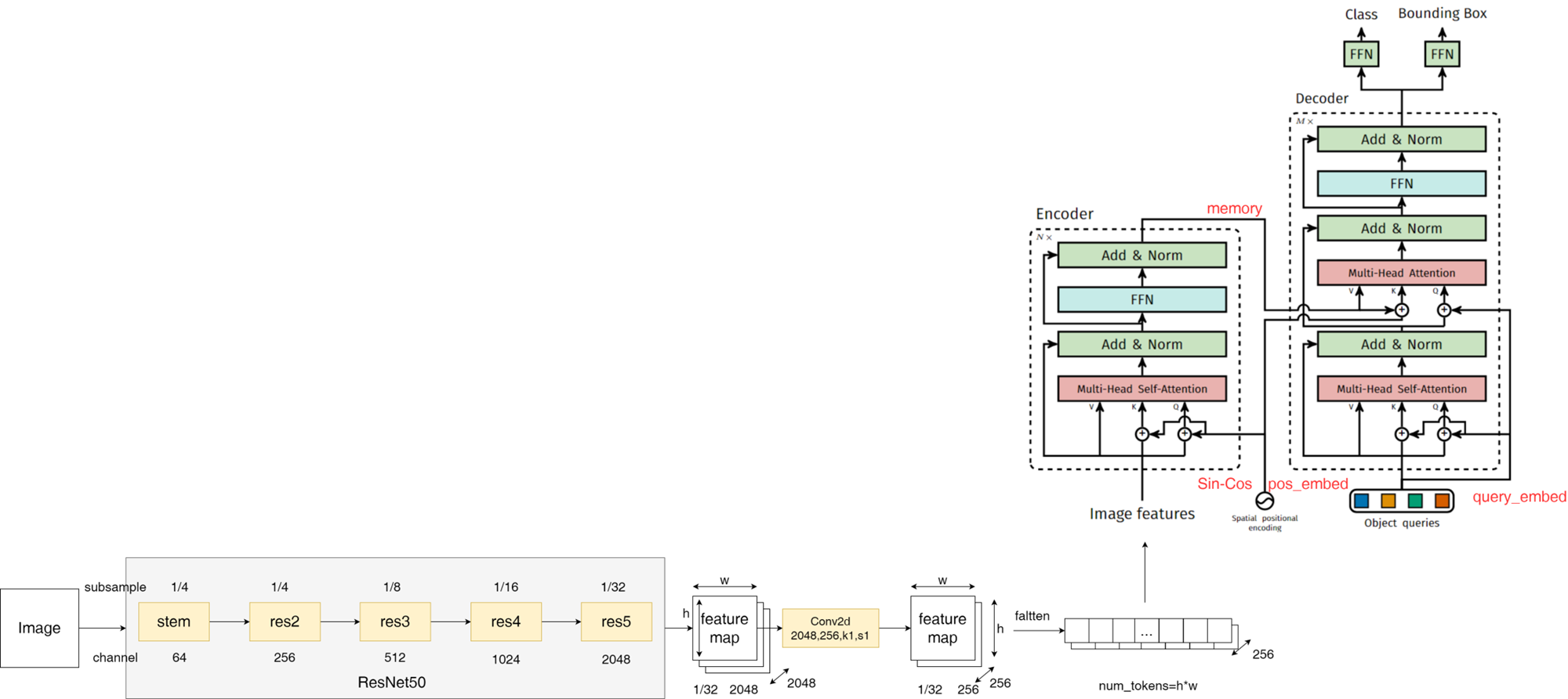
理解
encoder:
Q/K/V的内容信息是一样的,都是输入的图像特征,Q/K还增加了位置信息;Q/K增加的位置信息是一样的,都是利用Sin-Cos生成的固定位置信息;- 各个
encoder layer的输出值都是施加了自注意力后的、各位置关注了其他所有位置信息后而优化出的、更好的feature representations;(体现Transformer的全局依赖建模能力) - 新的
feature representations作为下一层encoder layer的输入特征,再结合Sin-Cos生成的固定位置信息pos_embed,一起作为下一层encoder layer的输入; - 各个
encoder layer的Sin-Cos固定位置信息pos_embed都是一样的,只在最初生成一次; - 最后整个
encoder的输出值(即memory),就是充分施加了自注意力后的、各位置充分关注了其他所有位置信息后而优化出的、更好的feature representations; memory作为输入decoder的K/V的内容信息,K还需要加上Sin-Cos的固定位置信息pos_embed,二者一起作为cross-attention输入
decoder:
query_embed代表object query的位置信息,是可学习的;- 初始化时
object query被初始化为(100, 256)的全零向量; - 在
self-attention中,Q/K/V拥有同样的内容信息,K/V还增加了相同的可学习的位置信息query_embed; self-attention的输出值是施加了自注意力后的、各object query关注了其他所有位置object query信息后而优化的、更好的object query(内容信息更优质的object query);- 在
cross-attention中,Q是self-attetion输出的object query再加上可学习的位置信息query_embed,K/V包含memory的内容信息,K还增加了Sin-Cos的固定位置信息pos_embed; cross-attention的输出值代表:根据object query信息(由Q代表)去图像特征(由memory得到的K/V代表)查找到最相关的图像特征,这个图像特征会作为下一个decoder layer的object query进行输入
代码理解Deformable DETR
重绘网络图
理解
encoder:
Q/K/V的内容信息是一样的,都是输入的多尺度图像特征,Q/K还增加了位置信息;Q/K增加的位置信息是一样的,即level_pos_embed,它包括利用Sin-Cos生成的固定位置信息pos_embed_per_level和可学习的区分不同尺度特征层的位置信息scale_level_embed;sampling_locations = references_points + sampling_offsets;其中references_points代表各特征层的grid center point位置全部归一化后再汇总,最终得到的全部特征点的坐标(所有特征层的会一起投影到每个特征层),sampling_offsets是网络预测的采样点的偏移位置(个数为num_levels*num_samping_points),sampling_locations为最终deformable attention关注的采样点位置;- 在
Multi Scale Deformable Attention中,Q通过Linear得到针对sampling points的注意力权重attention weights,V通过Linear得到Value(代表所有reference points的value),要想加权求和,还需要从V中精选出sampling points位置的value,所以这里的输入包括3个新增红线; - 各个
encoder layer的输出值都是施加了可变形注意力后的、各位置关注了其他几个重要位置信息后而优化出的、更好的feature representations;(体现Deformable Attention的关注重点能力) - 新的
feature representations作为下一层encoder layer的输入特征,再结合位置信息level_pos_embed,一起作为下一层encoder layer的输入; - 在一次前向传播过程中,各个
encoder layer在输入时添加的位置信息level_pos_embed都是一样的; - 最后整个
encoder的输出值(即memory),就是充分施加了可变形注意力后的、各位置充分关注了其他几个重要位置信息后而优化出的、更好的feature representations memory作为输入decoder的V的内容信息,作为cross-attention的输入
decoder:
query position embeding代表object query的位置信息,是可学习的;object query和query position embeding都是可学习的,维度都为(300, 256);- 在
self-attention中,Q/K/V拥有同样的内容信息,K/V还增加了相同的可学习的位置信息query position embedding; self-attention的输出值是施加了自注意力后的、各object query关注了其他所有位置object query信息后而优化的、更好的object query(内容信息更优质的object query);- 在
cross-attention(Multi Scale Deformable Attention)中,Q是self-attention输出的object query再加上可学习的位置信息query position embedding,V包含memory的内容信息;为了执行可变形注意力,还需要找到采样点sampling points,所以还需要输入reference points、spatial_shapes和level_start_index; - 注意这里的
reference points是可学习的,和encoder中固定位置的reference points不同; cross-attention的输出值代表:根据object query信息(由Q代表)去图像特征(由memory得到的V代表)查找到最相关的图像特征,这个图像特征会作为下一个decoder layer的object query进行输入;- 在一次前向传播过程中,每一个
decoder layer层输入的reference points、level_start_index、spatial_shapes都是相同的;其中level_start_index、spatial_shapes在encoder和decoder中都是相同的
Self-Attention和Deformable Attention
- 正如前面黄色高亮的部分,
Self-Attention关注序列中一个位置的token和其他所有位置(包括自身)token的相互依赖关系,这体现了Transformer的全局建模能力(relation modeling capability); - 而
Deformable Attention关注序列中一个位置的token和其他几个重要位置(即采样点sampling points)的token的相互依赖关系,这体现了Deformable Attention的稀疏空间采样(sparse spatial sampling)能力


















 1786
1786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









