




 这篇文章介绍了SenseTimeResearch提出的DeformableDETR,一种改进的Transformer模型,通过引入多尺度可变形注意力解决DETR的收敛速度和特征图尺度问题。文章详细解析了模型的框架,包括Backbone、Encoder、Decoder的变化,以及如何处理不同尺度的特征图和位置编码,使得模型在小目标检测方面表现更优。
这篇文章介绍了SenseTimeResearch提出的DeformableDETR,一种改进的Transformer模型,通过引入多尺度可变形注意力解决DETR的收敛速度和特征图尺度问题。文章详细解析了模型的框架,包括Backbone、Encoder、Decoder的变化,以及如何处理不同尺度的特征图和位置编码,使得模型在小目标检测方面表现更优。
一、前言
论文: Deformable DETR: Deformable Transformers for End-to-End Object Detection
作者: SenseTime Research
代码: Deformable DETR
特点: 提出多尺度可变形注意力 (Multi-scale Deformable Attention) 解决DETR收敛速度慢、特征图尺度单一等问题。
二、框架
下图为DETR(左)和Deformable DETR(右)的结构图:
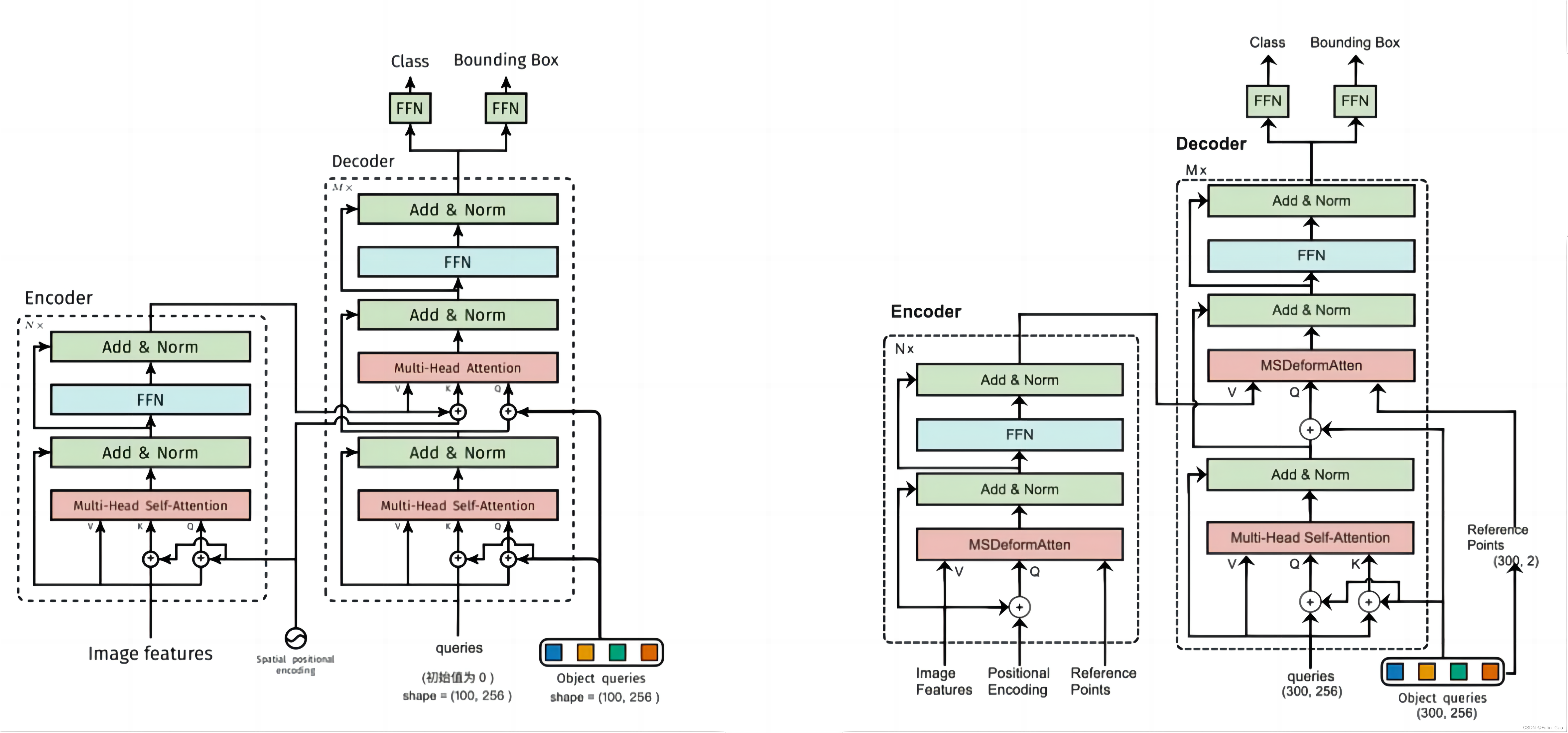
可见,二者的总体结构类似,主要区别在于注意力模块和相应的输入不同。所以,我们按照之前介绍DETR时的顺序依次介绍Deformable DETR与DETR在Backbone、Encoder、Decoder、Prediction Heads中的不同之处。
1. Backbone
保留尺寸小的特征图有利于检测大目标,保留尺寸大的特征图善于检测小目标。 为此,Deformable DETR提取4个尺寸下的特征图(DETR仅1个尺寸),特征提取过程如下图:
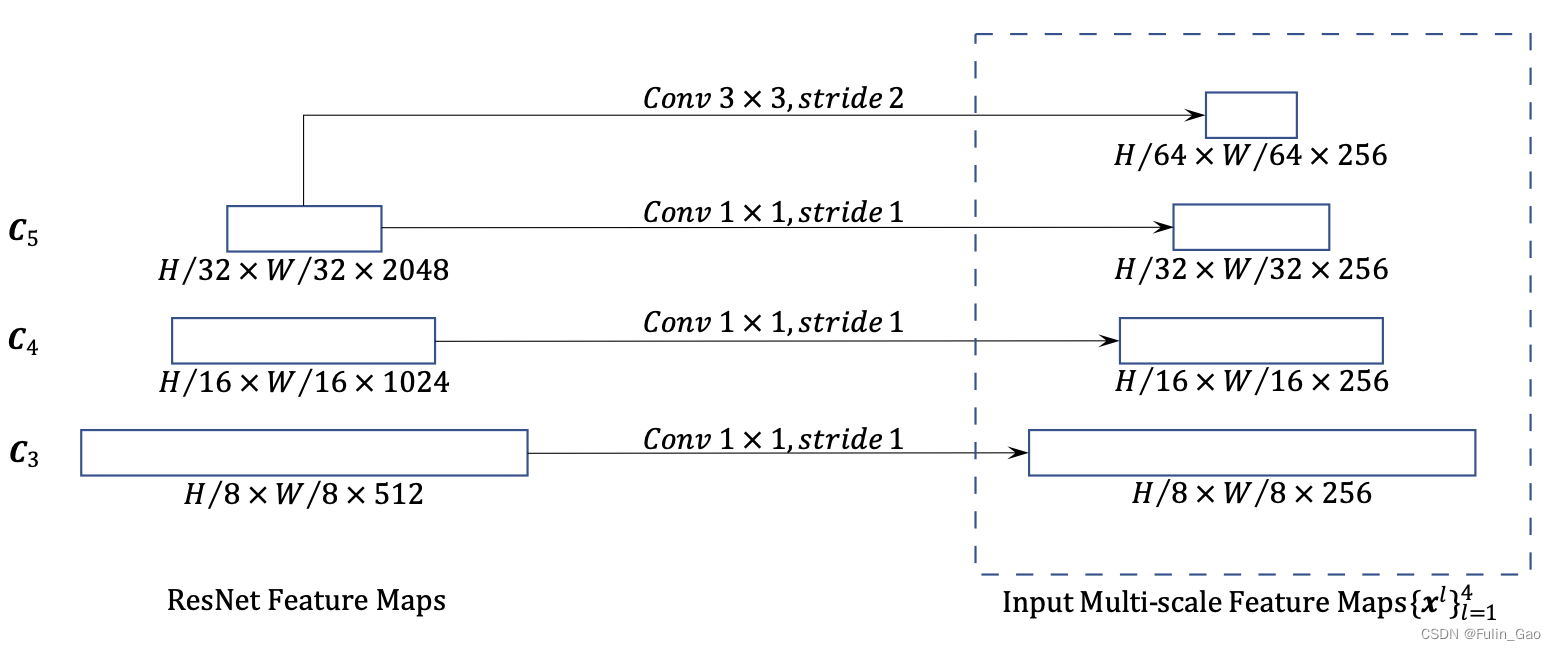
首先,Deformable DETR通过ResNet-50输出3个尺寸的特征图,分别为原图高宽的 1 8 \frac{1}{8} 81、 1 16 \frac{1}{16} 161、 1 32 \frac{1}{32} 321。3个特征图后接核为 1 ∗ 1 1*1 1∗1、步长为1的卷积层统一通道数为256。其次,在最后一层 1 32 \frac{1}{32} 321的特征图后跟一个核为3*3、步长为2的卷积层实现降采样和通道数统一,得到1个原图高宽 1 64 \frac{1}{64} 641通道数为256的特征图。于是共得到4个不同尺寸下( 1 8 \frac{1}{8} 81、 1 16 \frac{1}{16} 161、 1 32 \frac{1}{32} 321、 1 64 \frac{1}{64} 641)通道数均为256的特征图。
每个用于统一通道数的卷积层后都跟了一个GroupNorm层,Group的大小(32)与token向量长度(256)和多头注意力的头数(8)有关( 32 = 256 ÷ 8 32=256\div 8 32=256÷8)。此外,每个特征图都有对应的mask(表示padding情况,同一批次的图像尺寸会被统一以方便计算)和位置编码(与DETR中的Spatial positional encoding相同)。
不过,Spatial positional encoding无法区分不同层同一像素位置的位置编码向量,即小的特征图的位置编码是大的特征图的位置编码的子集。例如,第一个特征图在(2,4)像素点上的位置编码向量与另外三个特征图在(2,4)像素点上位置编码向量是相同的;只是大的特征图的位置编码向量数量更多,第一个特征图有(70,100)这个像素点,但其他特征图可能没有这个像素点。为此,Deformable DETR为不同特征图的位置编码加上了不同的可学习参数(nn.Parameter(特征图数量, 256)),同一特征图的所有像素点的位置编码加上的参数是相同的。
2. Encoder
Deformable DETR与DETR在Encoder部分的主要区别在下图的左下角部分:
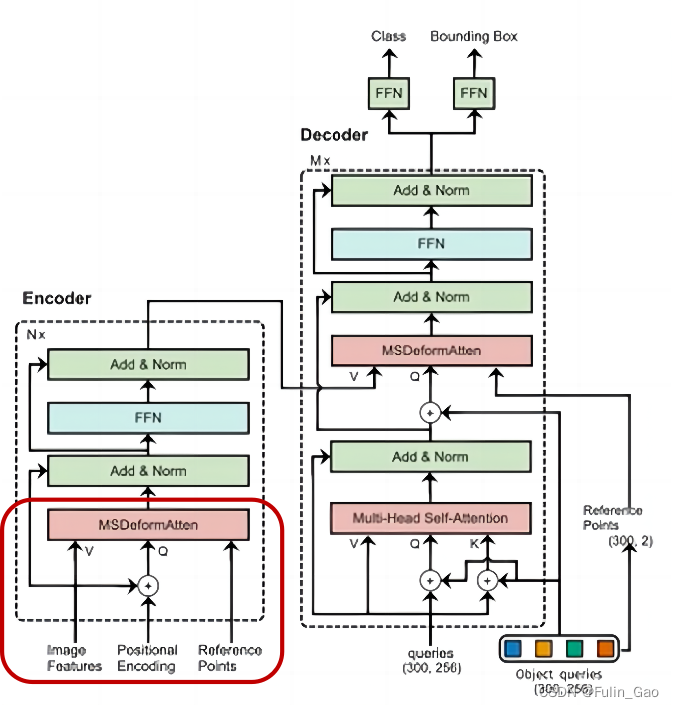
其中,Image Features为Backbone输出的4个不同尺寸下的特征图;Positional Encoding为各特征图的Spatial positional encoding+各自的可学习参数;Reference Points为各个特征图像素点的归一化坐标。
2.1 参考点
Deformable DETR的注意力模块需要参考点 (Reference Points) 作为基准来定位用于加权的像素点。注意力我们在后面讲,这里先理解参考点。
之前我们说参考点是各个特征图像素点的归一化坐标,其实不完全正确。一般来说,每个特征图都有且只有自己的像素点(如下图左侧两个子图):
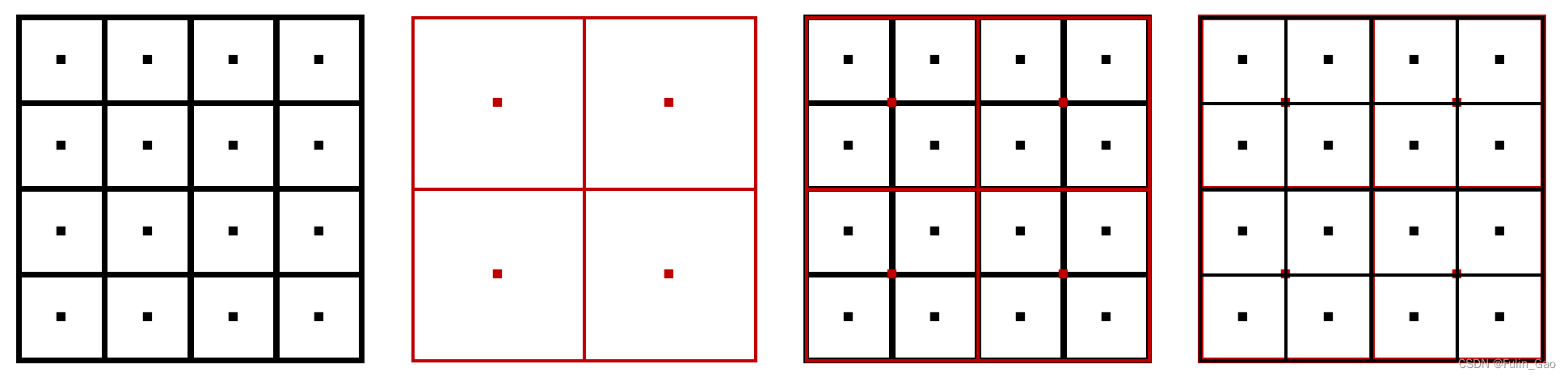
Deformable DETR用 (x,y) 表达各特征图的像素点。x和y均从0.5开始,分别从宽-0.5和高-0.5结束。具体来说,第一个特征图,宽为4,则各列x的坐标为 0.5 , 1.5 , 2.5 , 3.5 0.5,1.5,2.5,3.5 0.5,1.5,2.5,3.5,高为4,则各行y的坐标为 0.5 , 1.5 , 2.5 , 3.5 0.5,1.5,2.5,3.5 0.5,1.5,2.5,3.5;第二个特征图,宽为2,则各列x的坐标为 0.5 , 1.5 0.5,1.5 0.5,1.5,高为2,则各行y的坐标为 0.5 , 1.5 0.5,1.5 0.5,1.5。
为了增加像素点的数量,Deformable DETR将各个特征图的像素点坐标映射到了其它特征图上(如上图右侧两个子图)。映射前需要通过 (x/宽,y/高) 将不同特征图下单像素点坐标归一化(如果不归一化,小的特征图能映射到大的特征图上,但大的特征图无法映射到小的特征图上)。
原本4个尺度下的特征图共有 h e i g h t / 64 ∗ w i d t h / 64 + h e i g h t / 32 ∗ w i d t h / 32 + h e i g h t / 16 ∗ w i d t h / 16 + h e i g h t / 8 ∗ w i d t h / 8 height/64*width/64+height/32*width/32+height/16*width/16+height/8*width/8 height/64∗width/64+
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 6177
6177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











