




 该研究提出了一种利用元学习的方法,从高频关系实例中学习参数,以适应少样本关系的多跳推理问题。在知识图谱问答中,通过定义三元组查询并解决需要推理的多步关系。针对知识图谱构建类别的不平衡和长尾问题,采用了少样本学习策略。模型由两部分组成:关系特定学习,使用强化学习寻找目标实体和推理路径;元学习,则用于快速适应新的few-shot关系任务。
该研究提出了一种利用元学习的方法,从高频关系实例中学习参数,以适应少样本关系的多跳推理问题。在知识图谱问答中,通过定义三元组查询并解决需要推理的多步关系。针对知识图谱构建类别的不平衡和长尾问题,采用了少样本学习策略。模型由两部分组成:关系特定学习,使用强化学习寻找目标实体和推理路径;元学习,则用于快速适应新的few-shot关系任务。
Adapting Meta Knowledge Graph Information for Multi-Hop Reasoning over Few-Shot Relations(2019 EMNLP)
Idea:该论文利用meta-learning从高频关系实例中学得参数,然后快速应用于few-shot关系推理中。
该QA问题被定义为:一个三元组的query被定义为![]() ,其中e代表源实体,r代表关系类别,目的是从知识图谱中找到目标实体。例如:“What is the nationality of Mark Twain” 被形式化为 (Mark Twain; nationality; ?) → target entity :America
,其中e代表源实体,r代表关系类别,目的是从知识图谱中找到目标实体。例如:“What is the nationality of Mark Twain” 被形式化为 (Mark Twain; nationality; ?) → target entity :America
multi-hop reasoning:(Mark Twain; nationality; ?) 的答案不能从单一实例中得出,需加以推理。
multi-hop explainable paths:(Mark Twain; born-In; Florida) ^(Florida; located-In; America)
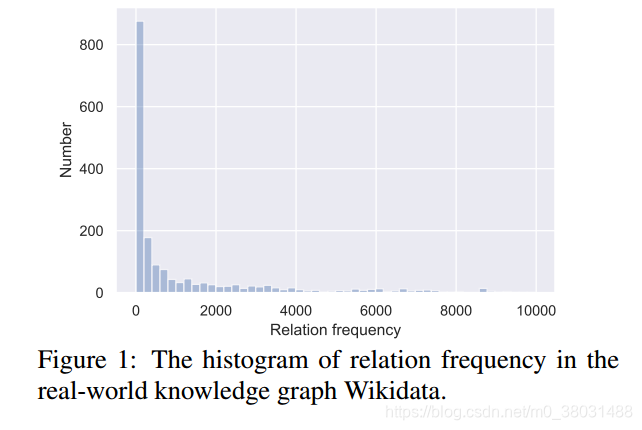
few-shot:从真实数据集中观察得出,其知识图谱的构建类别很不均衡,有长尾问题。从而引入few-shot learning来解决这一问题。
Problem Formulation
将该问题定义为:![]() ,其中前两个集合分别代表实体和关系集合。目的是求得
,其中前两个集合分别代表实体和关系集合。目的是求得![]() 。K被设置成超参数,小于K则为few-shot关系类,反之则为正常关系类。最后目标是预测出目标实体和推理路径。
。K被设置成超参数,小于K则为few-shot关系类,反之则为正常关系类。最后目标是预测出目标实体和推理路径。
Model
模型的主要目的是在正常关系类别上训练出一个好的参数,然后将其作为一个好的起点应用于few-shot关系类别上。
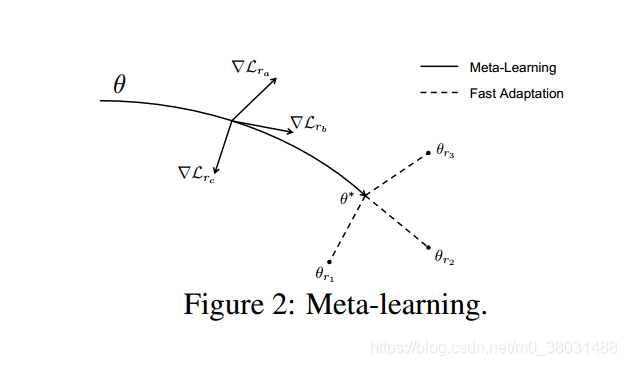
该Meta-KGR模型可以被分成两个部分(1)relation-specific learning:旨在通过强化学习来找到目标实体和推理路径。(2)meta-learning:旨在基于(1)学习到的参数快速的解决few-shot关系。
Relation-Specific Learning
Reinforcement Learning Formulation
rq代理从源实体起去寻找目标实体:
states:t时刻的状态被定义为![]() ,
,
Actions:基于当前状态st,action空间包括可能的边关系和t+1时刻的当前实体。
![]()
![]()
Transition:在t时刻,当代理做出了action![]() 。状态会改变为
。状态会改变为![]() 。Transition函数被定义为
。Transition函数被定义为![]() 。
。
当达到设置的步骤数后,会产生最终状态![]() 。
。
Rewards:当最终停止在目标实体上![]() = 1,否则是一个概率
= 1,否则是一个概率![]() 。
。
Policy Network
基于状态如何做出选择,该模型考虑任务上的所有搜索历史。
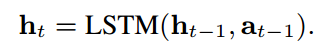
![]() ,最后网络输出被定义为在所有状态上的一个分布:
,最后网络输出被定义为在所有状态上的一个分布:
![]()
Meta-Learning
对于当前参数θ,将其迁移到新的任务上:
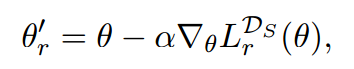
其中Ds为新任务上支持集合。在将学到的参数应用于新任务上的查询集合上用于更新参数θ。
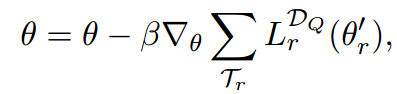
至此更新后的参数θ可以作为某个few-shot关系类别的起始参数了。

















 103
103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









