




 本文探讨了对抗训练在实体识别和关系抽取联合模型中的应用,通过在输入序列上添加微小扰动增强模型鲁棒性,实现了跨语言、多数据集的优秀结果。模型采用双向LSTM抽取序列信息,并将实体类型作为关系预测的输入,通过多标签头选择解决关系抽取问题。对抗训练通过扰动输入以优化模型,提高整体性能。
本文探讨了对抗训练在实体识别和关系抽取联合模型中的应用,通过在输入序列上添加微小扰动增强模型鲁棒性,实现了跨语言、多数据集的优秀结果。模型采用双向LSTM抽取序列信息,并将实体类型作为关系预测的输入,通过多标签头选择解决关系抽取问题。对抗训练通过扰动输入以优化模型,提高整体性能。
Adversarial training for multi-context joint entity and relation extraction
Abstract
对抗训练是一种正则化方法,通过对模型的输入增加微小而持久的扰动从而提高模型的鲁棒性。本文将对抗训练应用到实体识别和关系抽取的联合实验当中去,取得了跨语言、多数据集的先进结果。
Model
Joint learning as head selection
对于baseline模型的详细介绍我们可以参考这篇论文(An attentive neural architecture for joint segmentation and parsing and its application to real estate ads)。该模型的两个主要任务为:
(1)识别出实体的类型和边界。
(2)抽取出实体之间的关系类型。
对于该模型的一个输入序列 W =w1, ..., wn。用基于字符的词嵌入技术和基于单词的词嵌入技术将输入token向量化表示,然后使用双向lstm网络去抽取其序列化信息。
NER task:对于实体识别任务,论文中应用(Beginning, Inside, Outside)模式去encoding。对于预测实体标签:
(1)使用softmax算法对实体进行分类(假设实体边界已经知道)。
(2)或者使用CRF识别实体的类型和边界。
如图所示,实体的类型标签会被label embedding 以供关系预测时使用,论文中认为实体类型标签信息对关系预测任务是肯定有所增益的,其joint模式也是以此来体现的。(但是如果实体类型预测的不对,对于关系抽取任务的影响也自然是负面的,其也会导致错误传播。)
Relation Extraction task:作为一个multi-label head selection 问题,句子中的每个单词可以被包含在多种关系当中去。例如图中的“smith”和“California”表达的是“Lives in”关系,同时其也可以表示其他的关系类型(例如:Works for,Born in)。模型的任务是对于s(wj, wi, rk),根据单词wj去预测它和wi之间的关系rk。
![]()
Relation extraction loss:
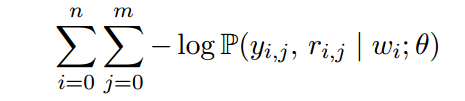
这里m是可能和wi发生关系的词的个数。对于联合任务的loss:
![]()
![]()
对于multi-token任务,为了消除其冗余性,一个实体对的最后一个实体才能和另一个实体发生关系。对于一个没有任何关系包含的实体,我们用“N”标签来标记它。
Adversarial training (AT)
对抗训练通过对模型输入增加小而持久的扰动实现。具体细节查看(对抗训练在关系抽取中的应用)
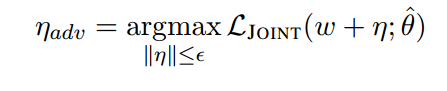
这里参数全部copy原模型参数,由于上述公式在神将网络中不好实现,我们通过下述公式代替:
![]()
![]()
![]()
最后,训练原始数据和增加扰动后的数据对模型进行优化。
具体实验结果请参考原始论文(Adversarial training for multi-context joint entity and relation extraction)。

















 2333
2333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









