




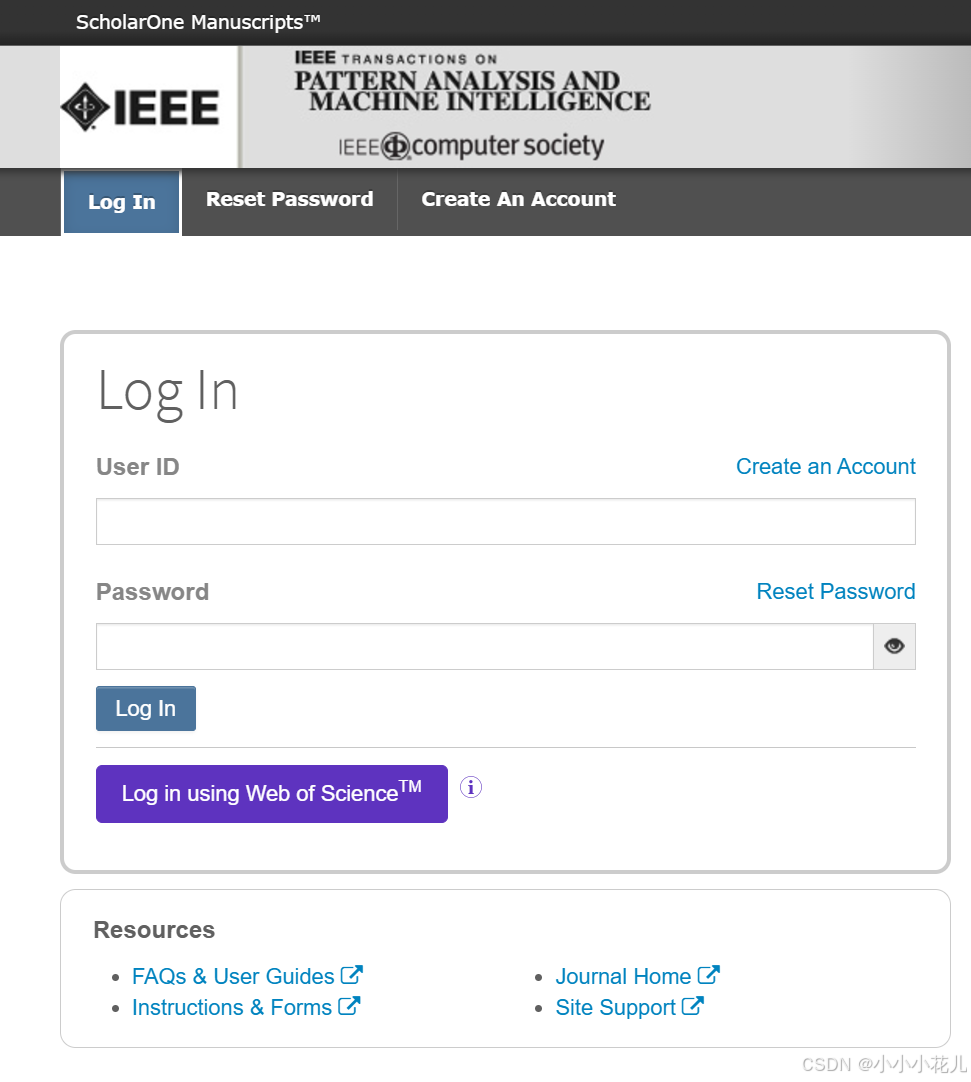
投稿地址:https://mc.manuscriptcentral.com/tpami-cs
一、账户注册(有账户的直接登录即可)
(1)
(2)
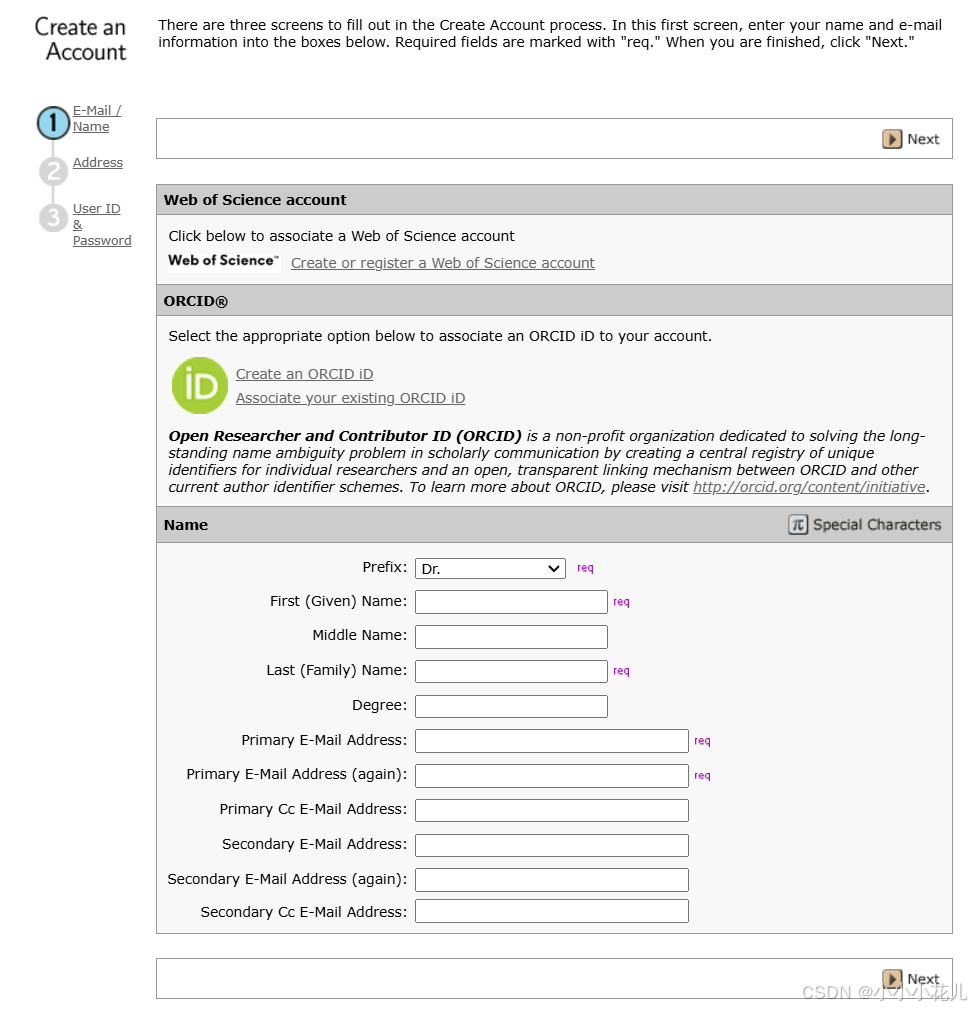
填写说明
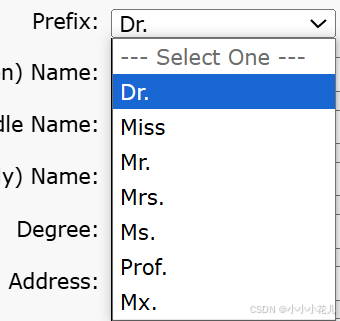
以下前缀的区别:
Dr.:博士
Miss:未婚女性,小姐
Mr.:先生
Mrs.:已婚女性,夫人随夫姓
Ms.:女士,在不清楚对方是否已婚的情况下可用
Prof.:教授
Mx.:当你知道对方不认同传统性别标签时,可以使用Mx.,或在不确定性别时使用
First (Given) Name:名
Last (Family) Name:姓

(3)
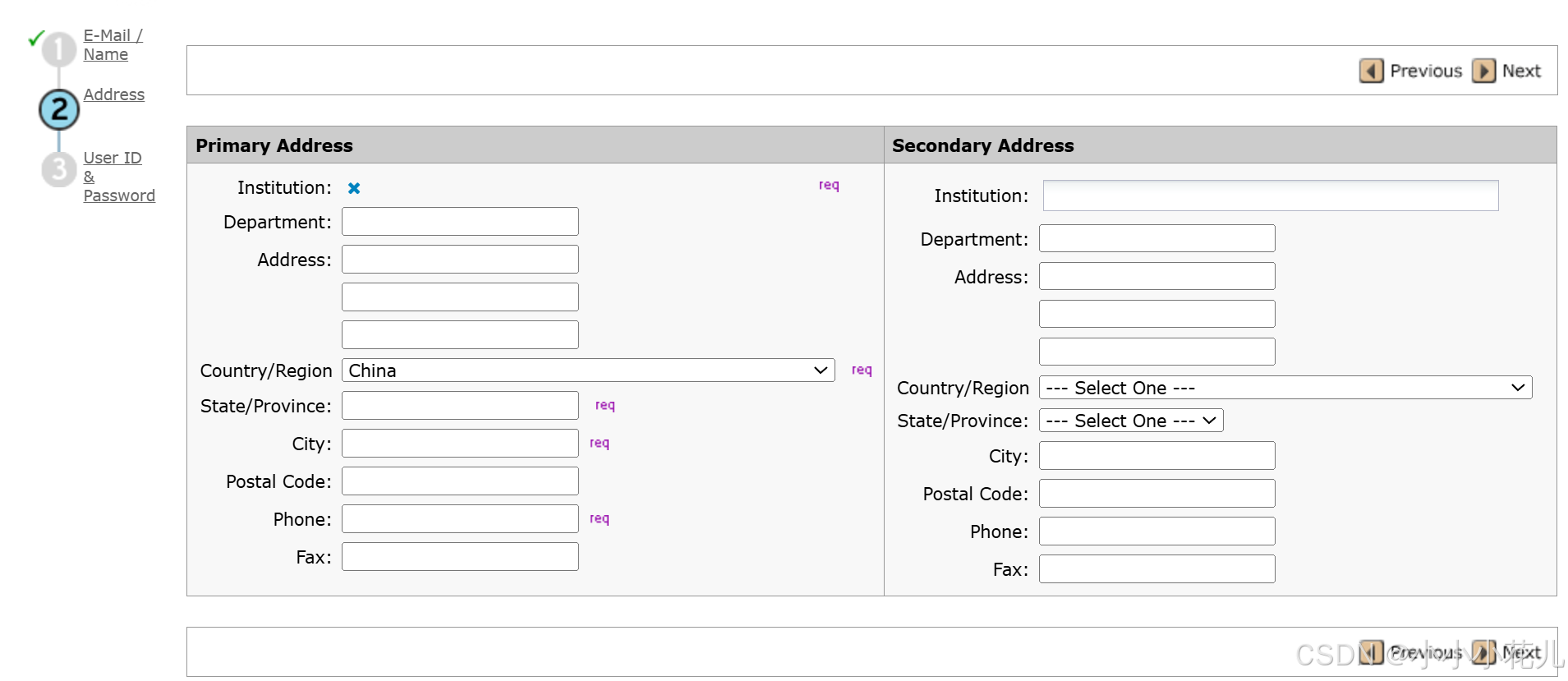
填写说明
Institution:指你所在的单位,例如学校或者其他单位
(3)
填写说明
根据自己的方向选两个就行
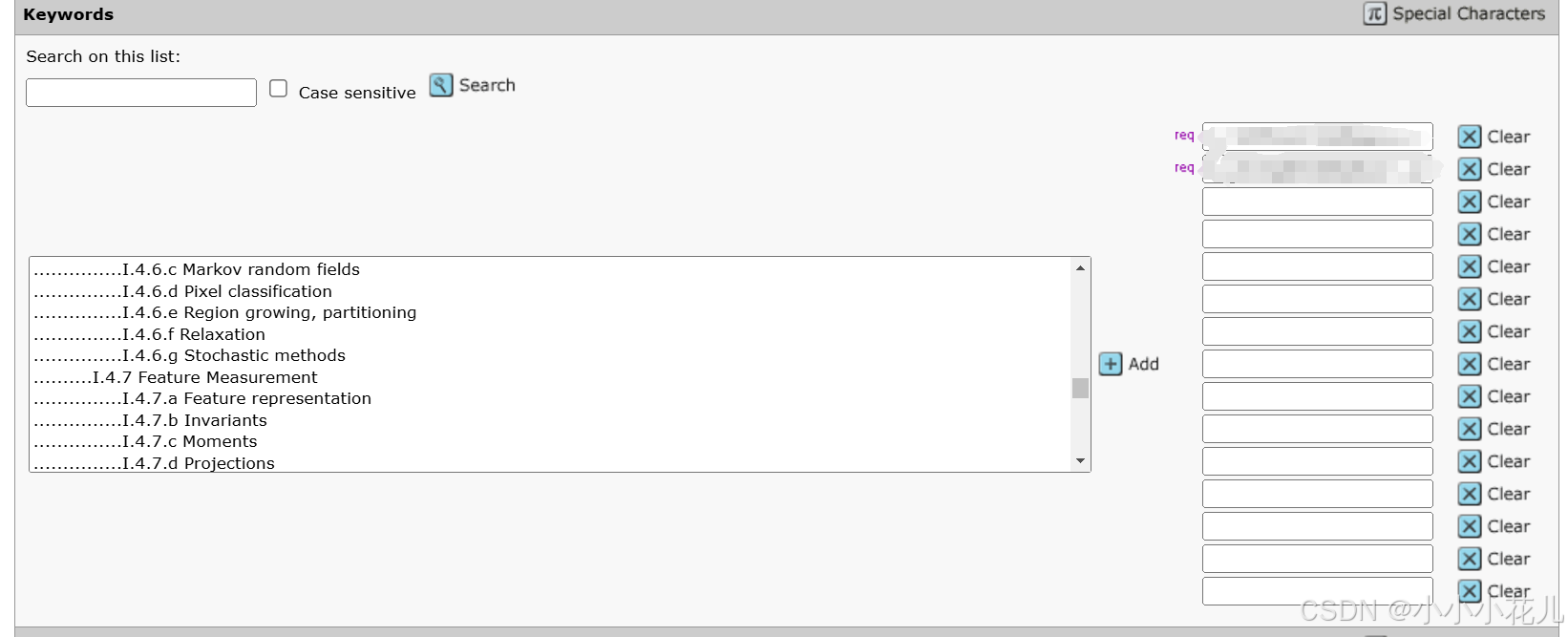
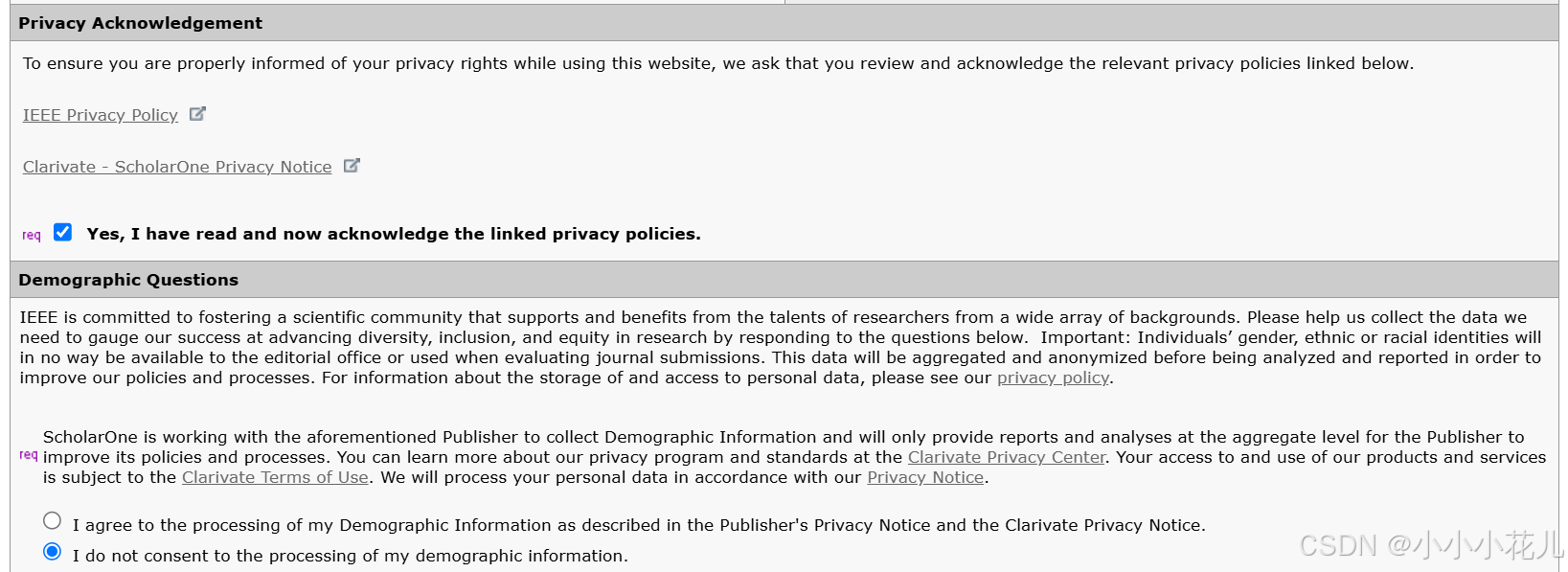
第一个必须同意,第二个是Demographic Questions,是一项有关人口统计问题的调查问卷,需要回答有关背景信息的基本问题,这个可以选择I do not那一项
二、开始提交!
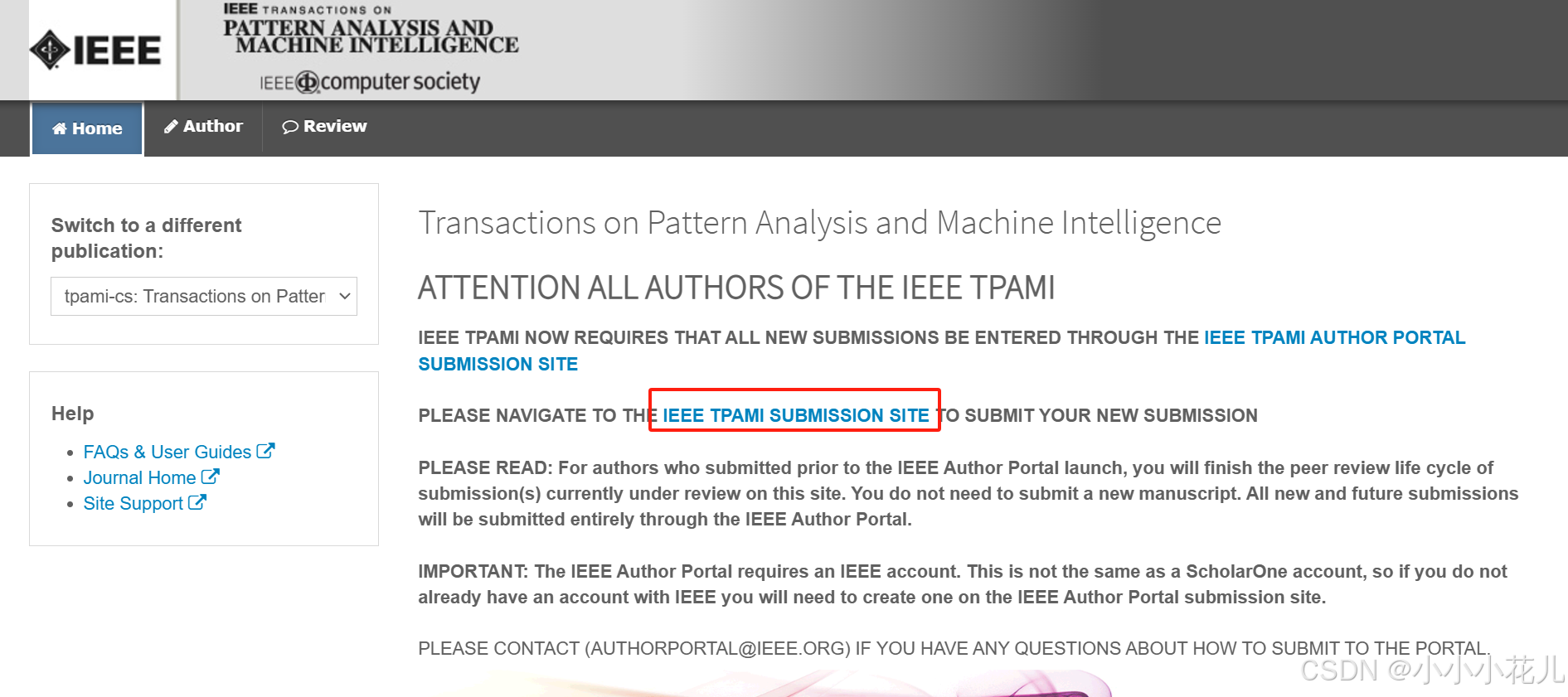
刚刚注册了账户,这里直接登录即可
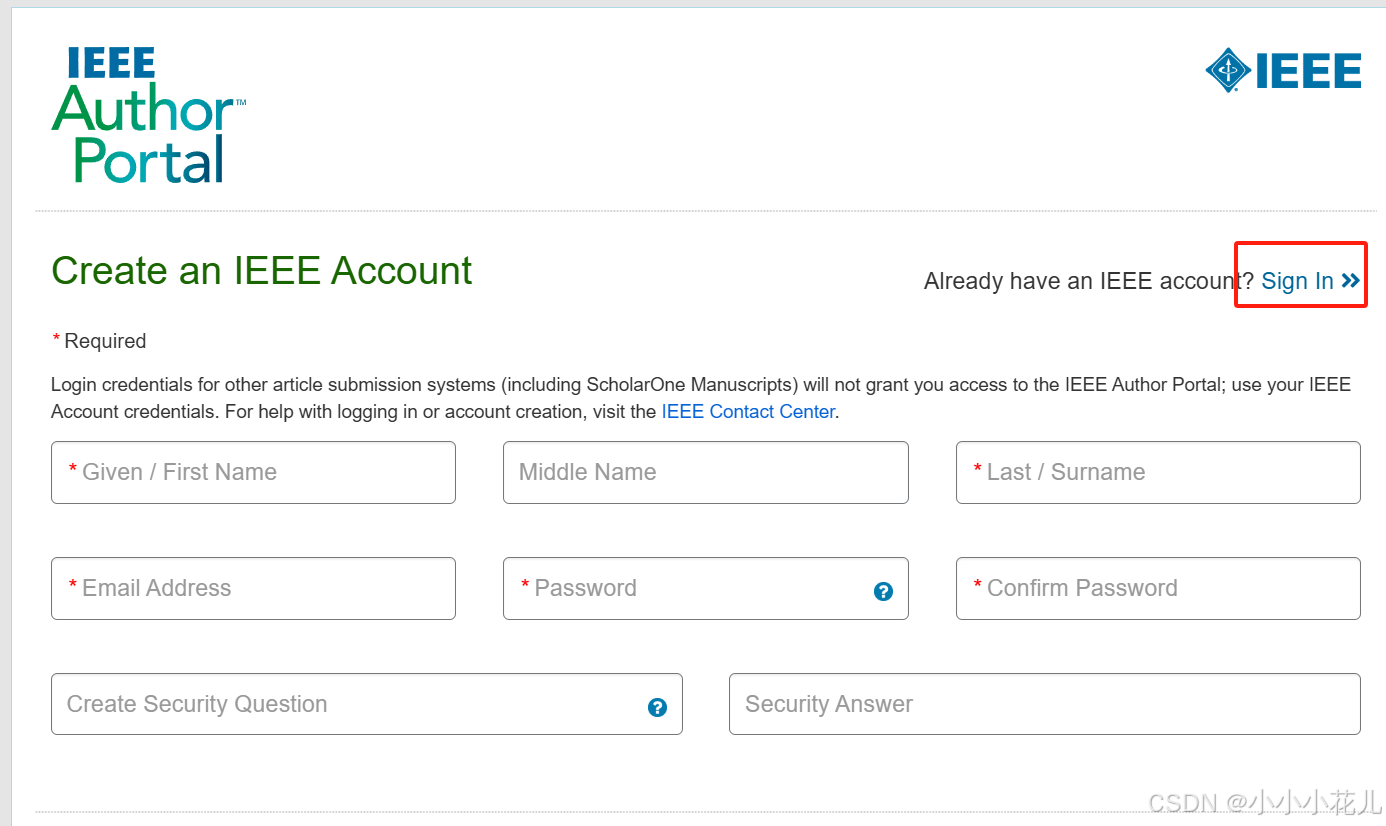
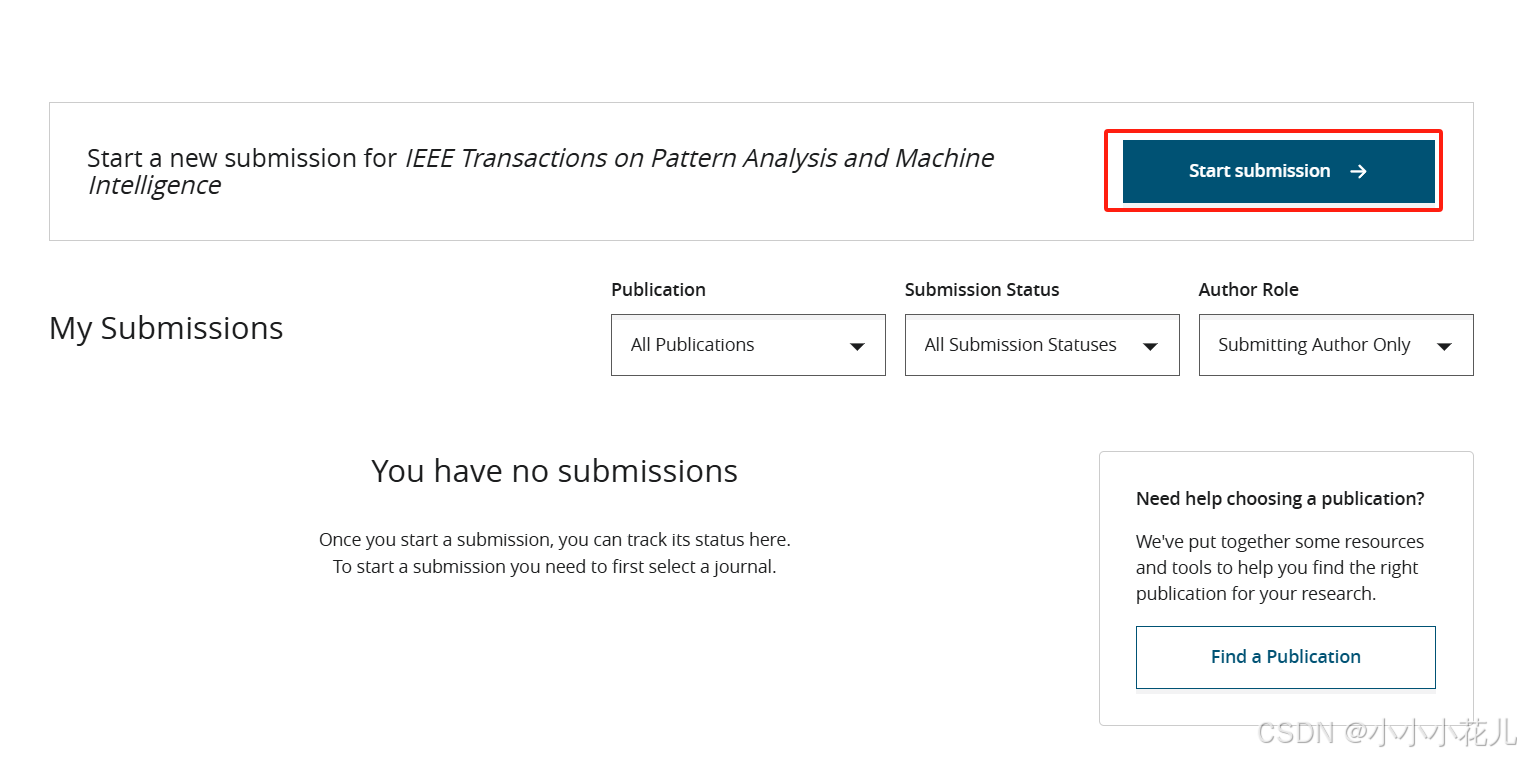
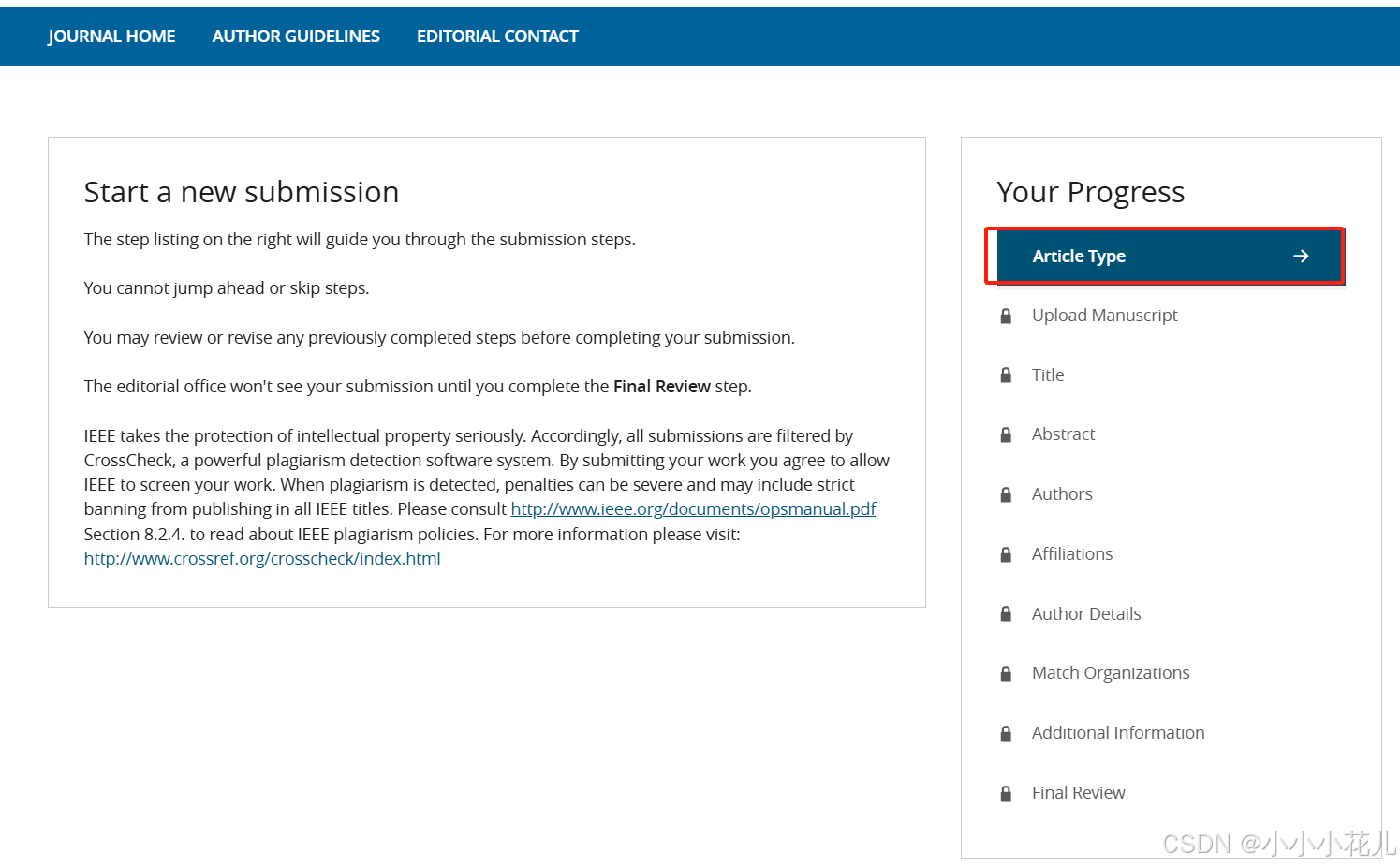
开始正式提交!
根据自己的论文类型选择
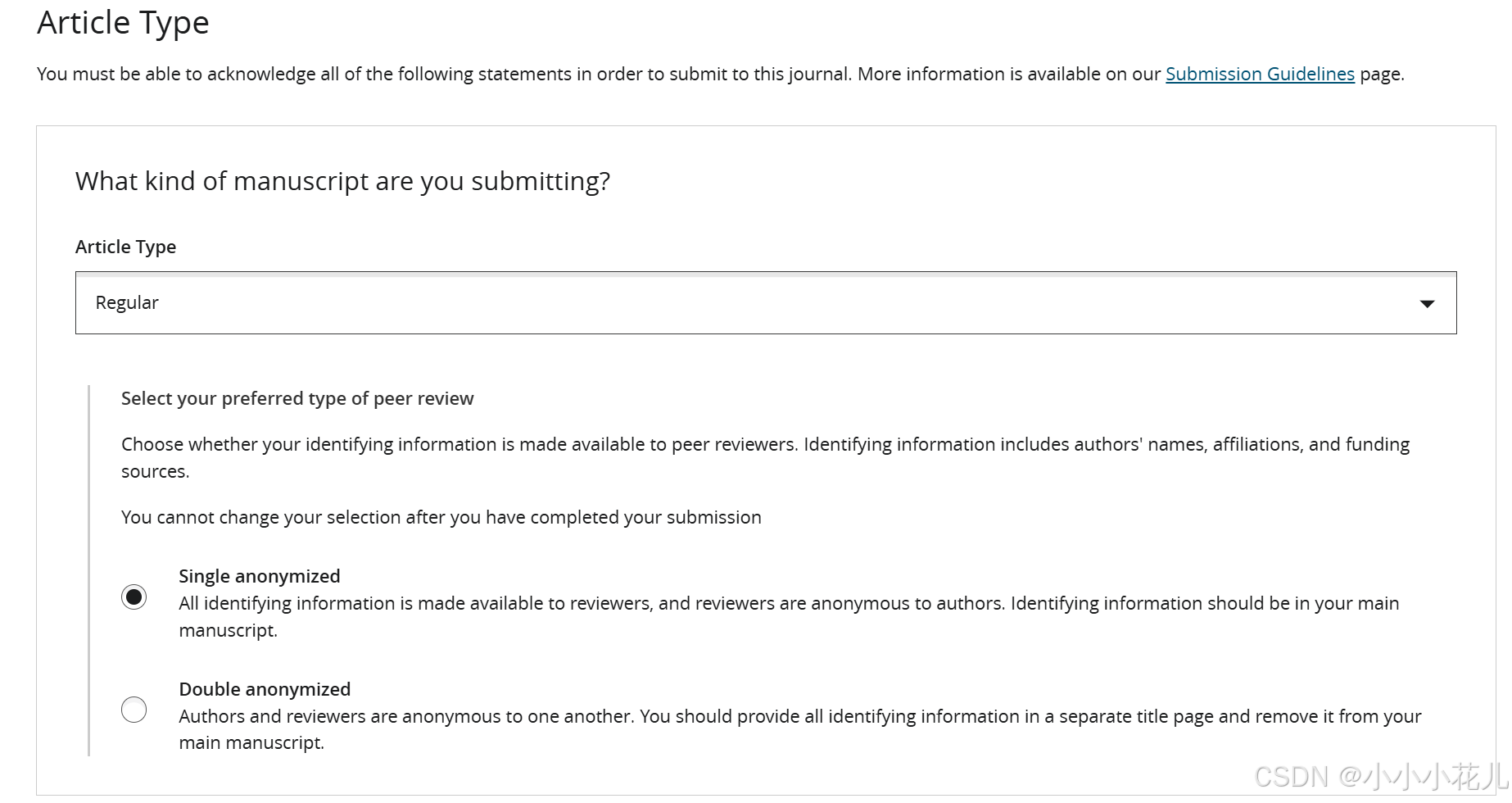
下面的都得选了才能下一步

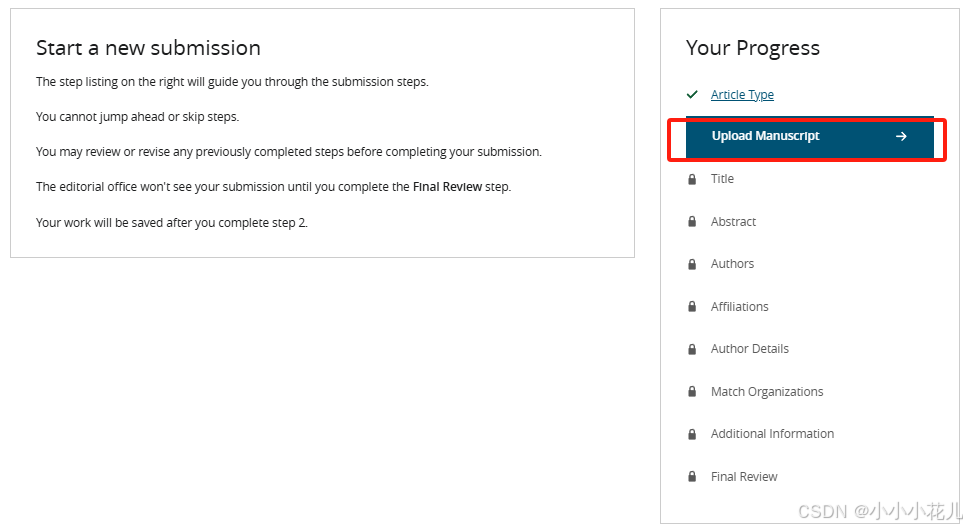
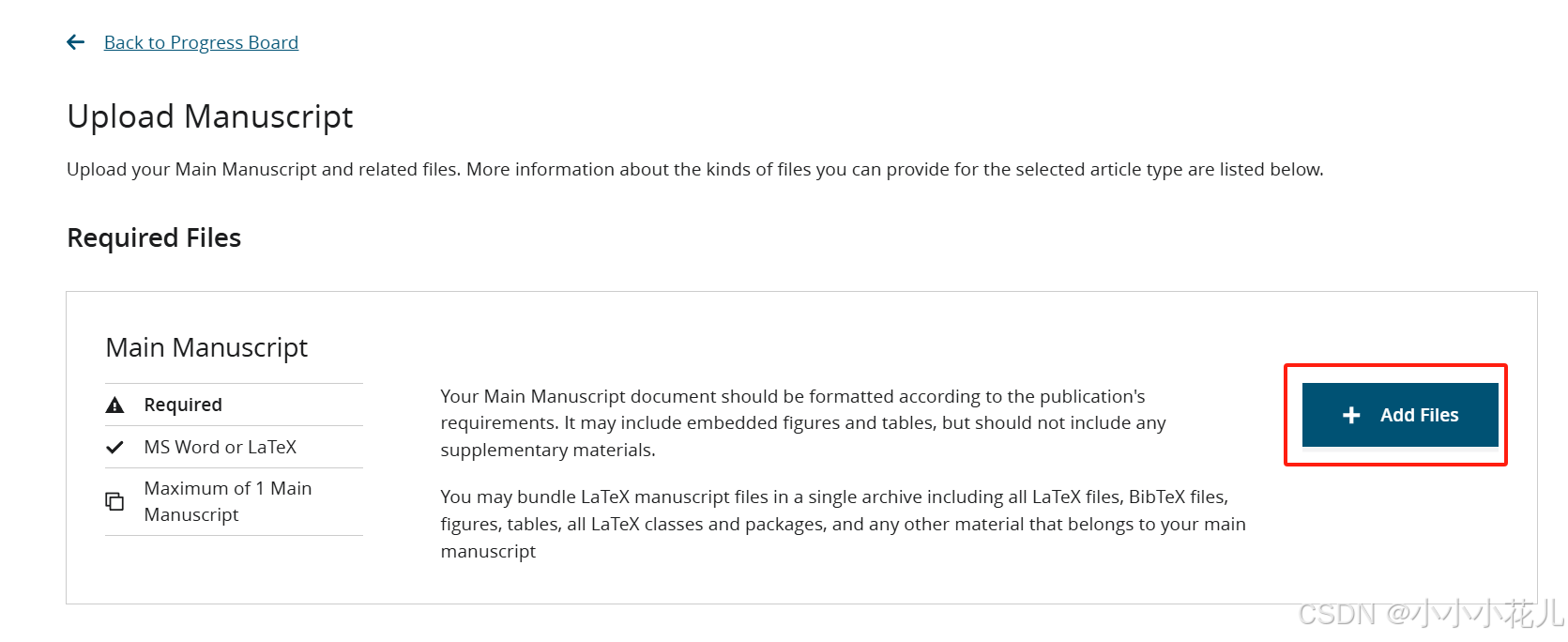
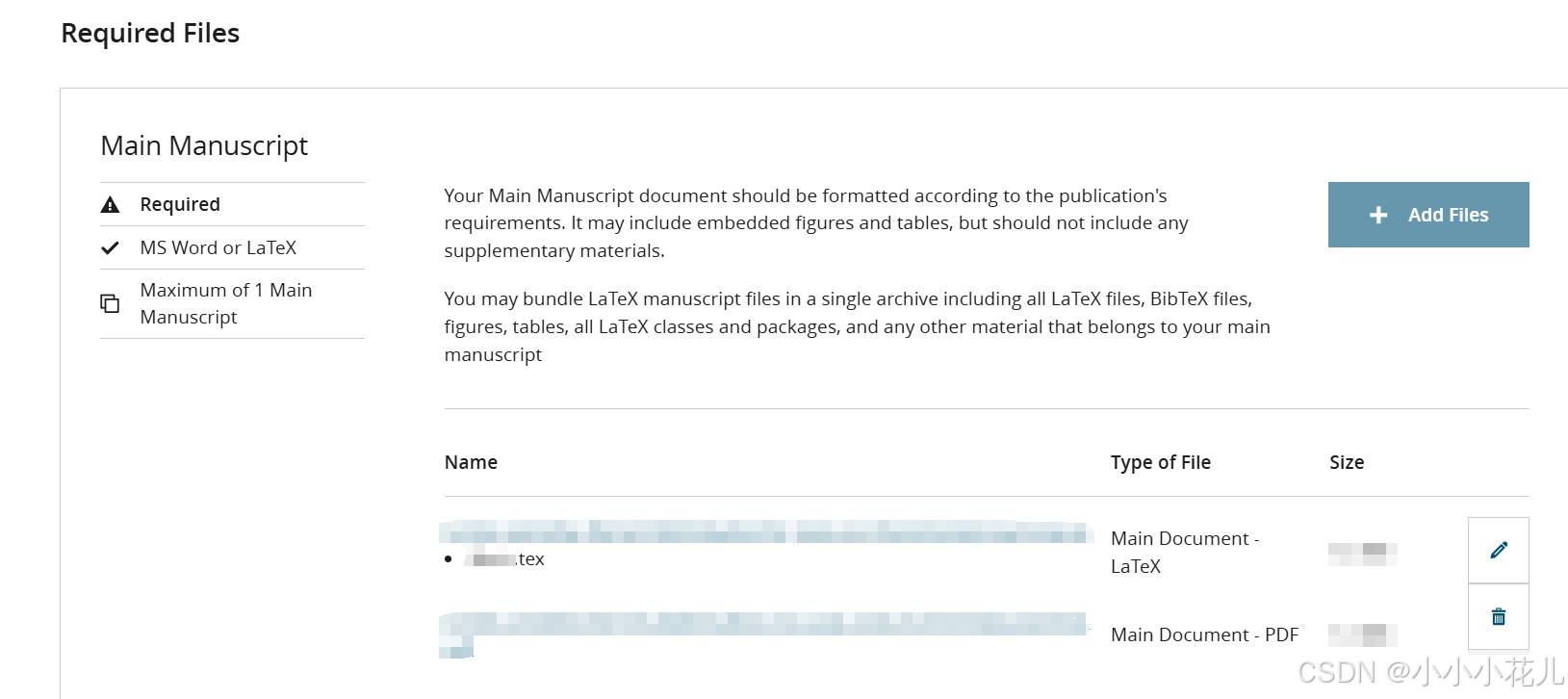
对论文Title、Abstract、Authors、Affiliations信息进行确认
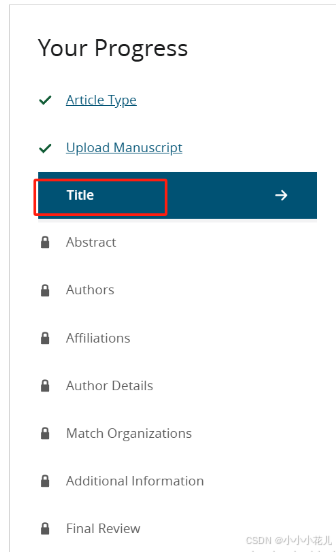
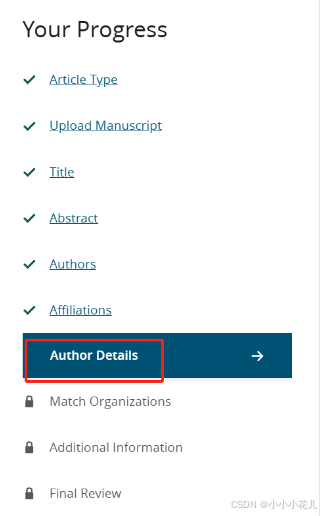
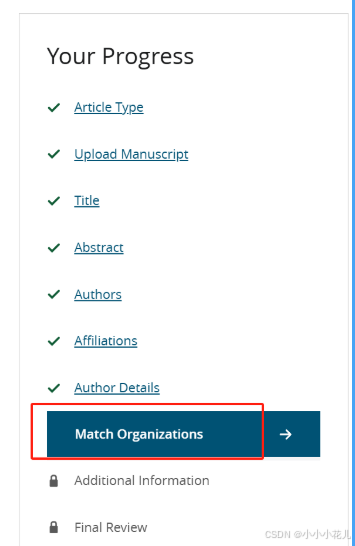
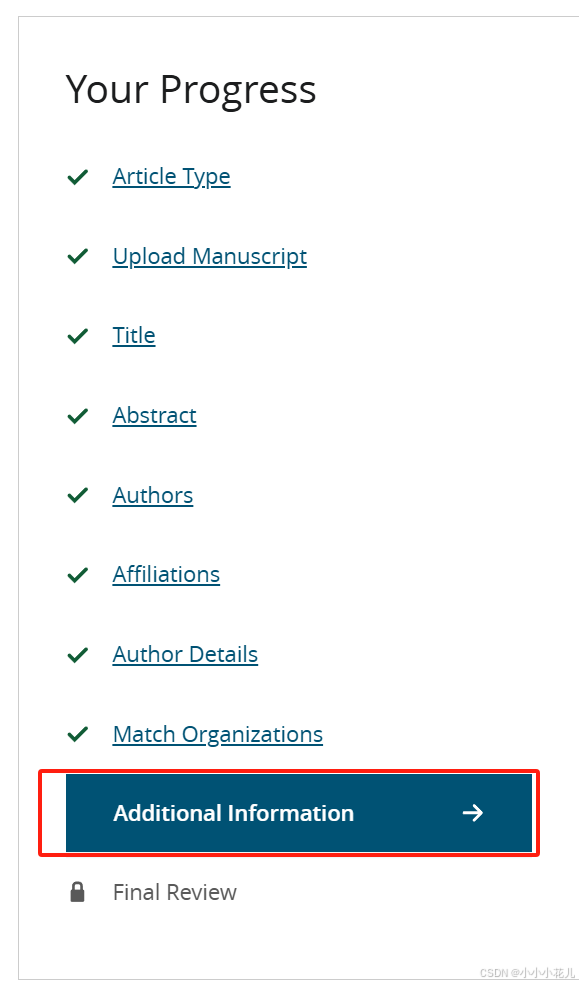
最后Final Review中会提供给你前面填写的信息的汇总界面,检查好没问题后就可以提交了,一定要检查好再提交哈,提交后就无法修改了。
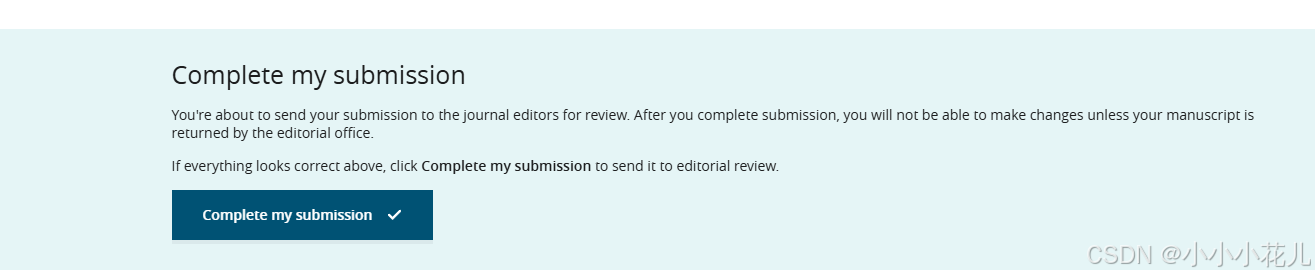
注意:TPAMI提交系统更改了,提交前没有最终pdf了,只有Final Review这个界面了,所以点击了Complete my submission后就是完成提交了。



















 5134
5134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









