 强化学习与马尔可夫决策过程
强化学习与马尔可夫决策过程





马尔可夫过程
强化学习基于马尔可夫过程,研究的问题都可以抽象成马尔可夫过程。其定义为满足马尔可夫性质的随机过程。
马尔可夫性质:通俗来讲,即当前状态包含了所有相关的历史,只要当前的状态已知,下一个状态的发生可能性就已经确定,不需要知道从开始到当前状态所经历的具体的状态变换。
P(st+1∣st)=P(st+1∣st,st−1,st−2...s0)P(s_{t+1}|s_t)=P(s_{t+1}|s_t,s_{t-1},s_{t-2}...s_0)P(st+1∣st)=P(st+1∣st,st−1,st−2...s0)
马尔可夫过程奖励
马尔可夫过程可以用一个元组(S,A,P,R,γ)(S,A,P,R,γ)(S,A,P,R,γ),SSS为状态空间集合,AAA为动作空间集,PPP为状态转移概率分布矩阵,RRR为各个状态sss的奖励集,γγγ折扣因(0-1)
奖励(回报)
每一个状态sss都有一个奖励值,集合为RRR,在ttt时刻从状态sts_tst开始,到这个回合(episode)结束,所能获得的奖励总和称为回报。
Gt=rt+1+γrt+2+γ2rt+3+γ3rt+4+γ4rt+5+...G_t=r_{t+1}+γr_{t+2}+γ^2r_{t+3}+γ^3r_{t+4}+γ^4r_{t+5}+...Gt=rt+1+γrt+2+γ2rt+3+γ3rt+4+γ4rt+5+...
Gt=rt+1+γGt+1G_t=r_{t+1}+γG_{t+1}Gt=rt+1+γGt+1
其中γγγ为折扣因子,取值0-1,其代表的意义为,当前眼前的奖励值与未来奖励值的占比关系。从现实生活考虑,未来的回报不确定性因素高,需要打个折扣。当γγγ趋于1时,表示对未来的回报越看重,更加考虑未来的收益,不局限于眼前的利益。相反,趋于0时,表示注重眼前的收益。
由于每个episode所经历的状态过程是随机的,不确定性高,但是我们需要一个稳定的奖励值来指导Agent,因此我们可以对回报函数求期望,就得到一个价值函数V(s)V(s)V(s)。
策略
策略πππ是指智能体在某个时刻的状态,根据策略决策应该选择哪个动作。
确定性策略:sss->aaa的映射,即在状态sss,选择动作aaa的概率为1.
随机策略:π(a∣s)π(a|s)π(a∣s),表示在状态sss下,选择动作aaa的概率值,该值不一定为1,即面对状态sss,agent依概率选择动作,则有可能会选到概率值小的动作(可能性较小而已)。
价值函数
状态的奖励RRR是状态的立即回报,描述的是进入某个状态后,立马能获取到的奖励,是‘眼前的利益’;价值函数,描述的是从某个状态,到终止状态整个过程能够获得到的所有立即回报R的期望。
状态价值函数
在某一个策略πππ下,状态sts_tst的价值函数,即为根据这个策略,一步步走到结束,每个状态的奖励的加和期望。
Vπ(st)=Eπ[Gt∣st]=Eπ(rt+1+γGst+1)V_π(s_t)=E_π[G_t|s_t]=E_π(r_{t+1}+γG_{s_{t+1}}) Vπ(st)=Eπ[Gt∣st]=Eπ(rt+1+γGst+1)=Eπ(rt+1)+Eπ(γGst+1)=Rt+1+γVπ(st+1)=E_π(r_{t+1})+E_π(γG_{st+1})=R_{t+1}+γV_π(s_{t+1})=Eπ(rt+1)+Eπ(γGst+1)=Rt+1+γVπ(st+1)
当前状态价值,等于该状态的立即回报的期望(下一个状态是不确定,因此不能确定立即回报,要取期望)+下个状态打了折扣的价值,状态价值函数描述了该状态的好坏。
动作价值函数
在某一个策略πππ下,状态sts_tst,选择具体某个动作ata_tat的价值函数,即选择完动作后,一直走到结束的所有奖励加和的期望。
Qπ(st,at)=Eπ[Gt∣st,at]Q_π(s_t,a_t)=E_π[G_t|s_t,a_t]Qπ(st,at)=Eπ[Gt∣st,at]
动作价值函数描述了在状态sts_tst下,选择该动作的好坏。
状态价值函数和动作价值函数的关系
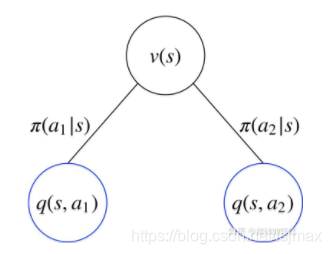
要求某个状态sss的状态价值函数,主要考虑,从这个状态出发,一共有几个动作可以选,每个动作对应的动作价值函数的累加和就是该状态的价值。
Vπ(s)=∑π(ai∣s)qπ(s,ai)V_π(s)=\sum π(a_i|s)q_π(s,a_i)Vπ(s)=∑π(ai∣s)qπ(s,ai)
对于确定性策略,对于某个状态,选择的动作是确定的,概率是1,因此π(a∣s)=1π(a|s)=1π(a∣s)=1,上式就可以写成,Vπ(s)=qπ(s,a)V_π(s)=q_π(s,a)Vπ(s)=qπ(s,a),状态价值函数就等于了动作价值函数。
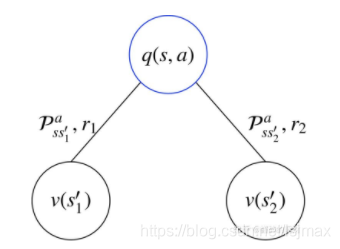
要求某一状态下sss下,确定选择某个动作aaa后,这个动作的价值函数,可以考虑,动作确定后,他就会转变成下一个状态,获得一个立即回报,但是转变成哪个状态是不确定的,和状态转移概率有关,因此当前动作的价值等于可能转变成的下一个状态的s′s\primes′的状态价值累计和以及状态改变带来的立即回报。
qπ(s,a)=∑Pss′a(ri+vπ(s′i))=Rsa+∑Pss′avπ(s′i)q_π(s,a)=\sum P_{ss\prime}^a (r_i+v_π(s\prime_i))=R_s^a+\sum P_{ss\prime}^a v_π(s\prime_i)qπ(s,a)=∑Pss′a(ri+vπ(s′i))=Rsa+∑Pss′avπ(s′i)
将qπ(s,a)q_π(s,a)qπ(s,a)带入Vπ(s)V_π(s)Vπ(s)可以得到:
Vπ(s)=∑π(ai∣s)[Rsa+∑Pss′avπ(s′i)]V_π(s)=\sum π(a_i|s)[R_s^a+\sum P_{ss\prime}^a v_π(s\prime_i)]Vπ(s)=∑π(ai∣s)[Rsa+∑Pss′avπ(s′i)]
该方程就是贝尔曼方程(Bellman)。
用矩阵形式表示:Vπ⃗=Rsa⃗+γPss′Vπ⃗\vec{V_π}=\vec{R_s^a}+γP_{ss\prime}\vec{V_π}Vπ=Rsa+γPss′Vπ
和Vπ(st)=Rt+1+γVπ(st+1)V_π(s_t)=R_{t+1}+γV_π(s_{t+1})Vπ(st)=Rt+1+γVπ(st+1)
本质上是一致的,当前状态的价值=立即回报+下一个状态的价值
同理可以推出qπ(s,a)=Rsa+∑Pss′a∑π(ai∣s′)qπ(s′,ai)q_π(s,a)=R_s^a+\sum P_{ss\prime}^a \sum π(a_i|s\prime)q_π(s\prime,a_i)qπ(s,a)=Rsa+∑Pss′a∑π(ai∣s′)qπ(s′,ai)
通过贝尔曼方程,当状态转移矩阵和策略已知的条件下,就可以通过迭代求出最优策略。
最优策略
对于MDP问题,一定存在一个最优策略π∗π^*π∗,设该策略下的状态价值函数为V∗(s)V^*(s)V∗(s),动作价值函数Q∗(s,a)Q^*(s,a)Q∗(s,a),则有下式成立
Q∗(s,a)≥Qπ(s,a),V∗(s)≥V(s)对任意的策略πQ^*(s,a)\geq Q_π(s,a),V^*(s) \geq V(s) 对任意的策略πQ∗(s,a)≥Qπ(s,a),V∗(s)≥V(s)对任意的策略π
定理:
- 对于任何MDP,存在一个最优策略,比任何其他策略更好,或至少相等;
- 所有的最优策略有相同的最优价值函数;
- 所有的最优策略有相同的动作价值函数;
因此,求最优策略可以通过求最优价值函数,转换为求价值函数的最大值问题。
动态规划
动态规划是需要在状态转移概率矩阵和回报函数已知的情况下,可以通过迭代求解得到最优策略。
动态规划问题两个性质:
最优子结构:保证能够使用最优性原理(多阶段决策过程的最优决策序列具有这样的性质:不论初始状态和初始决策如何,对于前面决策所造成的某一状态而言,其后各阶段的决策序列必须构成最优策略),问题可以转化成求子问题最优。
子问题重叠:子问题反复出现,可以缓存子问题和重利用子问题的解。
策略迭代
给定初始策略πkπ_kπk,计算出该策略下的状态VπkV_{π_k}Vπk和动作价值函数VπkV_{π_k}Vπk,根据贪心策略πk+1(s,a)=maxaQπk(s,a)π_{k+1}(s,a)=max_aQ_{π_k}(s,a)πk+1(s,a)=maxaQπk(s,a),得到新的策略πk+1π_{k+1}πk+1,然后在新的策略下,求出新的价值函数,反复迭代,直到价值函数和策略收敛,就求出了最优策略。
策略评估:Vπk+1(s)=∑π(ai∣s)[Rsa+γ∑Pss′aVπk(s′i)]V_{πk+1}(s)=\sum π(a_i|s)[R_s^a+γ\sum P_{ss\prime}^a V_{πk}(s\prime_i)]Vπk+1(s)=∑π(ai∣s)[Rsa+γ∑Pss′aVπk(s′i)]
即求出该策略下价值函数最终的收敛值,贝尔曼方程中,求解当前状态sss下的价值Vk+1(s)V_{k+1}(s)Vk+1(s)等于立即回报+下一个状态s′s\primes′的价值Vk+1(s′)V_{k+1}(s\prime)Vk+1(s′),但是我们不知道下一个状态s′s\primes′的价值Vk+1(s′)V_{k+1}(s\prime)Vk+1(s′)是多少,因此这里采用的是上一次迭代的s′s\primes′的价值Vk(s′)V_{k}(s\prime)Vk(s′)替代。因此在一轮迭代中,可以对将所有的状态的价值函数进行更新,然后进行下一轮,直到价值收敛了,就求出了该策略下的状态价值函数。
策略改进:
对于小问题,第一轮状态价值函数更新收敛,求出某策略下的状态价值函数后,根据贪心策略,可能就能得到最终最优策略。而复杂大问题,此时根据贪心策略得到新的策略,该策略还不是最优策略,需要重新进行策略评估,然后在进行策略改进,不断进行迭代,直到策略收敛。
价值迭代
策略迭代中,需要先进行策略评估,先求出当前策略下的价值函数,在根据价值函数进行策略改进。如果将贝尔曼方程:
V(s)=∑π(ai∣s)[Rsa+γ∑Pss′aV(s′i)]V(s)=\sum π(a_i|s)[R_s^a+γ\sum P_{ss\prime}^a V(s\prime_i)]V(s)=∑π(ai∣s)[Rsa+γ∑Pss′aV(s′i)]改成
Vk+1(s)=maxa[Rsa+γ∑Pss′aVk(s′i)]V_{k+1}(s)=max_a[R_s^a+γ\sum P_{ss\prime}^a V_k(s\prime_i)]Vk+1(s)=maxa[Rsa+γ∑Pss′aVk(s′i)]价值迭代不涉及策略,(但是需要知道具体状态下,下一个所有的状态以及相应的转换概率)直接通过价值函数迭代逼近最优价值函数,跳过了策略改进的步骤。实际上改进过程已经通过maxamax_amaxa实现了。贝尔曼方程是求的期望,改进后的价值方程是贝尔曼优化方程。
同理,动作价值函数也有迭代公式:
Qπ+1(s,a)=Rsa+γ∑Pss′amaxaQπ(s′,a′)Q_{π+1}(s,a)=R_s^a+γ\sum P_{ss\prime}^amax_aQ_π(s\prime,a\prime)Qπ+1(s,a)=Rsa+γ∑Pss′amaxaQπ(s′,a′)
广义策略迭代
在策略迭代中,策略改进,必须在策略评估迭代收敛后再进行。然而,实际上并不需要策略评估收敛后再进行策略改进,值迭代就是最极端的例子,不进行评估就进行策略改进(实际暗中是进行了策略评估的一次更新),同样也可以得到最优策略。因此还有很多介于两者之间的方法,只要所有的状态价值和策略在不断地更新迭代,则最终一定会收敛到最优价值函数和最优策略,称为广义策略迭代。即只强调价值函数和策略在不断迭代提升,不关注具体的细节。强化学习都可以很好地描述成广义策略迭代。

















 87
87

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









