




目录
-
引言
-
简介
-
ReSum范式与ReAct范式的差异
-
如何重置上下文?
-
如何训练摘要模型
-
ReSum-GRPO
引言
小伙伴们好,今天继续Agent智能体专题。前文已经陆续介绍阿里通义实验室WebAgent项目中的5项成果:WebWatcher、WebShaper、WebSailor、WebDancer、WebWalker。并针对这些WebAgent进行了多维度的对比:
今天继续介绍阿里通义实验室WebAgent项目下的最新成果:ReSum,也可以称为WebResummer。
更多AI Agent相关欢迎关注公众号"小窗幽记机器学习"。
论文地址:
https://arxiv.org/abs/2509.13313
GitHub地址: https://github.com/Alibaba-NLP/DeepResearch/tree/main/WebAgent/WebResummer
简介
ReSum旨在解决基于大型语言模型(LLM)的WebAgent在执行长周期搜索任务时遇到的上下文窗口限制问题。ReSum 通过周期性地调用摘要工具来压缩不断增长的交互历史,将其转化为紧凑的推理状态,从而实现无限探索。为了使智能体适应这种基于摘要的推理模式,作者们设计了 ReSum-GRPO 强化学习算法,该算法通过分割长轨迹并广播轨迹级别的优势来进行训练。实验结果表明,与传统的 ReAct 范式相比,ReSum 在训练自由和强化学习两种设置下,都能在多个挑战性基准测试中显著提升性能,同时还开发了专用的 ReSumTool-30B 摘要模型,以实现高效且高质量的上下文压缩。
ReSum范式与ReAct范式的差异
ReSum范式与ReAct范式的主要差异在于它们处理长周期探索所需的上下文限制问题的方式。
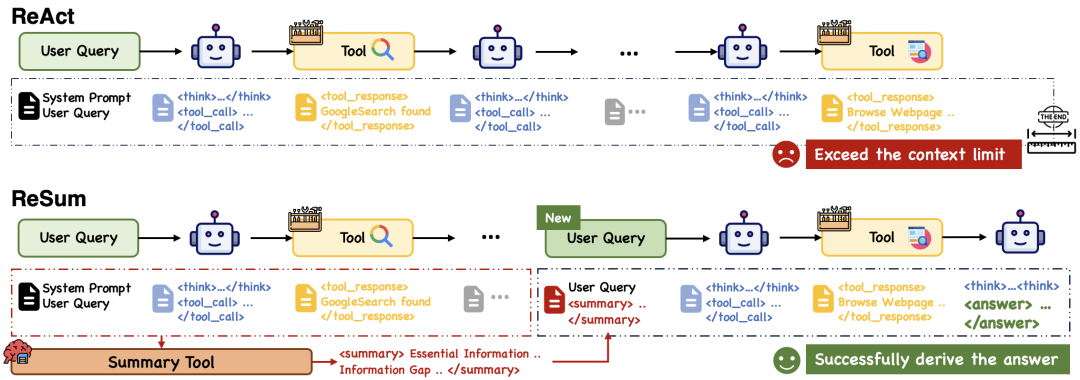
图1:ReSum范式与ReAct范式的对比。在ReAct中追加每个观察、思考和动作会在多轮探索完成之前耗尽上下文预算。相比之下,ReSum定期调用摘要工具来压缩历史记录,并从压缩后的摘要中恢复推理,从而实现无限期的探索。
以下是二者的对比:
| 特征 | ReAct范式 | ReSum范式 |
|---|---|---|
| 上下文处理机制 | 追加全部历史 :将每一次的思考(Thought)、行动(Action)和观察(Observation)都附加到对话历史中。 | 周期性摘要与压缩 :在接近上下文限制时,周期性地调用摘要工具来压缩历史。 |
| 推理状态 | 基于完整的、不断增长的交互历史。 | 将冗长的交互历史转化为紧凑的推理状态(结构化摘要)。 |
| 探索限制 | 受限于上下文窗口 :上下文预算快速耗尽,导致在复杂、知识密集型任务中探索过早终止。 | 实现无限探索 :通过压缩历史并从新的状态继续推理,Agent能够绕过上下文约束,进行长周期探索。 |
| 目标 | 广泛采用的Agent工作流程,结合推理与行动。 | 专门解决ReAct范式的上下文限制问题,释放长周期搜索智能。 |
简而言之,ReAct 的核心缺陷在于它不断累积上下文,使其无法应对需要大量步骤的复杂查询。而 ReSum 通过定期将积累的历史信息提炼为精简的摘要,然后从这个压缩的摘要状态恢复推理,从而能够在保持对先前发现的感知的同时,实现无限制的探索。ReSum通过最小化对ReAct的修改,确保了与现有Agent的兼容性、简洁性和效率。
使用一个特殊token对<summary>、</summary>对摘要内容进行包裹,最大限度保留原来ReAct结构。
如何重置上下文?
ReSum 范式中“上下文重置”的核心目标是:用一个紧凑的、目标导向的摘要来替换不断增长的完整交互历史,从而使Agent能够从一个新的、压缩的状态继续探索。上下文重置的具体示例和机制如下:
1. 机制定义
当触发器(例如,接近上下文窗口限制)被激活时,系统会调用摘要工具 来执行上下文压缩:
-
摘要生成: 摘要工具根据当前的积累历史 生成一个目标导向的摘要 。
-
标记包裹: 这个摘要 被包裹在一对特殊的标记中,即
<summary> </summary>。 -
状态压缩与重置: 系统将原始查询 和生成的摘要 组合成一个新的压缩状态。
-
历史替换: 工作历史 被重置为只包含这个新的压缩状态 。
原始查询摘要
2. 案例示例(来自 BrowseComp-zh 轨迹,翻译成英语)
在 ReSum-GRPO 训练后的 WebSailor-30B Agent执行的一个复杂查询轨迹中,可以看到上下文重置的具体应用:
背景: Agent在 Round 1 到 Round 6 进行了多次搜索和思考,积累了大量的 Thought, Action, Observation 交互历史 。
重置发生: 在 Round 6 结束之后,系统触发了摘要机制。
Round 7 的输入上下文(即重置后的新状态):
在 Round 7 开始时,Agent接收到的上下文不再是 Round 1 到 Round 6 的冗长历史,而是原始的“问题”加上一个包裹在特殊token中的“摘要”:
Question: A renowned film from the last century, adapted from a film literary script whose title (different from the film title) contains numbers. After more than 60 years, it was restored and re-screened. The film’s director worked as a teacher with a four-character female actress in southwestern China during the 1930s-40s. What is the birth place of this female actress?<summary>* The film “Shangganling” (produced by Changchun Film Studio in 1956) was adapted from the film literary script “Twenty-Four Days”. The script title differs from the film title and contains numbers. The film underwent 4K digital restoration and re-screening around 2020, more than 60 years after its original release.* One of the directors of “Shangganling”, Sha Meng (original name Liu Shangwen, 1907-11-02 to 1964-06-26), worked as a teacher alongside actress Ouyang Ruqiu at the Yucai School founded by Tao Xingzhi in Beibei, Chongqing during the Anti-Japanese War period (1939). The two later married.* Ouyang Ruqiu (born 1918 to December 27, 2007) was a four-character name actress, performing artist, and educator, born in Xiaoxian County, Anhui Province. Therefore, the birthplace of the four-character name actress referred to in the question is Xiaoxian County, Anhui Province.</summary> <think> The summary has already provided complete clues and a clear answer... I can directly provide the final answer. </think><answer>Based on the detailed clues and multiple rounds of verification, the birth place of the femaleactress Ouyang Ruqiu involved in the question is Xiaoxian County, Anhui Province.</answer>小结:
通过这次重置,系统将先前 6 轮交互中所有的中间思考、行动和观察结果浓缩成了一个结构化的、包含关键证据和下一步行动指引的紧凑推理状态。Agent在 Round 7 仅基于这个精简的上下文 就能够判断信息已足够,并直接生成最终答案。
这种机制是 ReSum 实现无限探索的关键,因为它在保持对先前发现的“感知”的同时,避免了上下文预算的耗尽。
如何训练摘要模型
ReSum范式中使用的摘要模型(ReSumTool-30B)是通过有针对性的训练进行专门化开发的,以确保其能够执行目标导向的对话摘要,而不仅仅是常规的通用摘要。
以下是其具体的训练方式和目标:
1. 基础模型与方法
ReSumTool-30B 是基于强大的开源模型 Qwen3-30B-A3B-Thinking,通过监督微调(supervised fine-tuning,SFT)获得的。
2. 训练数据的收集
为了使模型具备在网络搜索环境中进行有效摘要的能力,研究人员采用了以下数据:
-
数据类型: 使用从 ReSum rollout 轨迹中收集到的 对话历史 (Conversation), 摘要 (Summary) 对进行训练。
-
数据来源: 训练数据主要来自 SailorFog-QA 基准测试。该基准测试具有高难度和挑战性,要求Agent在扩展探索期间调用摘要工具。
-
数据引擎:对话历史, 摘要 对是从强大的开源模型(如 Qwen3-30B、DeepSeek-R1-671B 等)的 ReSum rollout 中收集的,并被蒸馏到 ReSumTool-30B 中。
3. 摘要模型的专业化目标
与传统摘要工具不同,ReSumTool-30B 经过专门训练,旨在满足Web Agent长期探索的需求。它的目标能力包括:
-
提取关键证据: 从冗长而嘈杂的交互历史中提炼出关键线索和可验证的证据。
-
识别信息空白:明确识别仍缺乏的关键信息和信息空白。
-
指导下一步方向:突出下一步行动的明确指示,这些行动应基于网络上下文并具有明确范围。
通过这种有针对性的训练,ReSumTool-30B 具备了任务特定的增强,使其能够胜过仅缺乏网络上下文推理能力的通用模型,甚至在摘要质量上优于更大的模型,例如 Qwen3-235B 和 DeepSeek-R1-671B。
ReSum-GRPO
ReSum-GRPO算法是为了使Agent模型(例如 WebSailor)适应 ReSum 范式,特别是掌握从压缩后的摘要状态 中继续推理的能力。它通过在标准 GRPO 流程中引入针对长轨迹的分割机制和优势广播机制来实现这一目标。
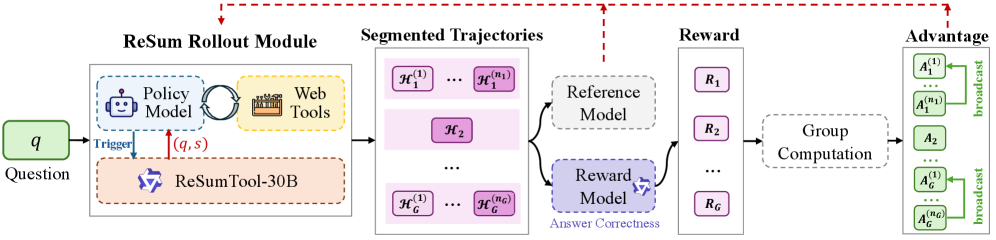
图3:ReSum-GRPO示意图。ReSum会定期对长轨迹进行总结,并从压缩状态重新启动,由此生成分段轨迹。根据最终答案计算出单一的轨迹级奖励值,在组内归一化后得到轨迹级优势值,该优势值会被广播至同一次推出过程中的所有片段。
以下是 ReSum-GRPO 具体的训练细节:
1. 核心目标与必要性
-
适应摘要条件推理: ReSum 范式引入了一种新的查询类型 (原始查询 加上摘要 )。对于标准Agent而言,这种模式是分布外(out-of-distribution)的,因为它们在训练中从未遇到过基于摘要的推理。
-
自我演进: ReSum-GRPO 采用强化学习(RL)。与需要昂贵专家级 ReSum 轨迹数据的监督微调(supervised fine-tuning)不同,RL 允许Agent通过自我演进来适应新范式,同时保留其固有的推理能力。
-
基础算法: ReSum-GRPO 是基于标准的 GRPO流程实例化的。
2. 轨迹分割
这是 ReSum-GRPO 对标准 RL 流程的关键修改:
-
触发分割: 当轨迹在探索过程中因达到上下文限制而触发摘要机制时,长轨迹会被自然地分割成多个训练片段。
-
片段定义: 假设一条完整的 ReSum 轨迹经历了 次摘要事件,轨迹将被分割成 个片段 。
-
输入状态: 每个片段 都构成一个独立的训练回合(training episode)。
-
第一个片段 以初始查询 作为输入 。
-
随后的片段 则以第 次摘要后生成的压缩状态 作为输入。
-
轨迹更新公式:
其中 是初始查询, 是第 k 次总结后的压缩状态,而 表示最终答案。每个分段 都构成一个独立的训练回合,其输入为 ,输出为 。对于那些未经总结就完成的轨迹,我们会遇到 的退化情况,这会产生一个遵循相同训练格式的单一分段。
轨迹更新算法:

3. 奖励计算
为了简化训练信号,ReSum-GRPO 使用了统一的轨迹级奖励信号:
-
奖励来源: 奖励 是从轨迹的最终答案 中提取并计算的,使用“LLM-as-Judge”策略来确定答案的正确性。这种方法仅依赖于结果的正确性,避免了手动设计每个片段(per-segment)的奖励。
-
格式检查惩罚: 在每个生成步骤中,如果Agent未能遵循特定的格式标记(例如
<think> </think>),则该轨迹将被终止并分配零奖励作为惩罚。这隐式地引导Agent有效遵循所需的格式。
4. 优势广播(Advantage Broadcasting)
ReSum-GRPO 并非直接广播奖励,而是广播轨迹级优势(trajectory-level advantage),以利用 GRPO 的群组稳定化特性:
-
轨迹奖励计算: 对于一个批次中的 个rollouts中的轨迹 ,首先计算其轨迹级奖励 。
-
优势计算: 奖励 在群组内进行归一化,以获得轨迹级优势 。
-
优势广播: 这个计算出的优势 被广播给该轨迹 中的所有片段(即 )。
5. 训练目标
优势广播机制(Advantage broadcasting mechanism)鼓励Agent实现两个关键目标:
-
有效利用摘要: 从压缩状态中成功推理的能力。
-
战略性信息收集: 收集能够产生高质量摘要的证据的能力。
6. 训练实施细节
-
基础模型: 实验中使用的基础模型是 WebSailor 系列模型(例如 WebSailor-30B),这些模型已通过 rejection sampling fine-tuning(RFT) 获得了工具调用能力,作为纯净的 RL 训练基础。
-
数据规模: 训练数据规模被限制在1K 样本,这些样本是从 SailorFog-QA 数据集中随机选择的。
-
训练回合: 训练持续4 个 Epoch。
-
超参数(Hyper-parameters): 学习率(learning_rate)设置为 ,批次大小(batch_size)为 64,群组大小(group size)为 8。
-
工具调用限制: ReSum-GRPO 的最大工具调用次数增加到 60;相比之下,标准 GRPO(ReAct范式)的限制是 40 次。
-
Token分配: ReSum-GRPO 分配 4k token用于查询提示,28k token用于响应(总限制为 32k)。当达到token限制时,系统会调用 ReSumTool-30B 进行摘要并重启对话,收集分段轨迹。
#WebAgent #Agent #智能体


















 36
36

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









