




声明:语音合成(TTS)论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
Fast and lightweight on-device TTS with Tacotron2 and LPCNet
本文章是俄罗斯华为技术有限公司在interspeech2020上的工作,主要做轻量级的神经网络语音合成优化(tacotron+lpcnet),使该TTS系统能够在低中端的移动设备上使用,文章的具体链接为https://www.isca-speech.org/archive/Interspeech_2020/pdfs/2169.pdf
1 研究背景
现在的TTS系统的流行方案包括声学模型(tacotron, fastspeech等等)+声码器(wavenet,wavernn,lpcnet等等)。即使很多文章对这些流行的架构做了很多优化策略,但依然不能够在低端的移动设备上使用。另外本文也阐述了很少有关于语音合成的文章对并行合成策略很少涉及,而本文就是优化并行合成策略,使tacotron+lpcnet的方案可以在移动设备上实时合成。
2 详细设计
tacotron+lpcnet的方案,主要复杂度如公式所示,E为encoder的开销,D为decoder生成一帧的开销,R为postnet的视野,P为后处理时间开销,V为声码器时间开销。
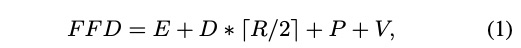
本文先对tacotron的时间瓶颈做优化。首先,把decoder的lstm的处理单元数1024缩小4倍,同时也可以再增加一层lstm。其次,postnet的5层一维卷积的内核变为【5,3,3,3】,视野降了一半。另外可以把postnet和lpcnet的frame rate network相融合。
对于声码器LPCNET可以并行合成,但对于声学特征如何划分是个问题,本文提出了两种基于frame的划分方法。第一种是按照能量进行划分,多划分在静音段和清音段,因为划分在silence和清音处不影响合成的音质效果。如图1所示,静音的能量从低频到高频总体分布很小,而清音的能量在某个频段能量较高,根据该特点本文提出了公式2的判断方法。如果划分的帧属于浊音,会造成图2的竖线,有很明显的机械声。第二种方法使使用类似lpcnet的frame rate network的结构来进行frame的划分。

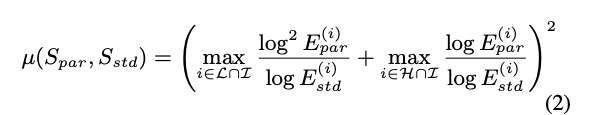

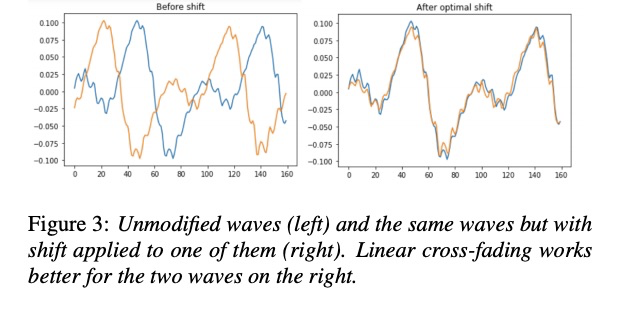
除了进行划分帧的方法使并行合成不影响音质,本文也提出了后处理方法,则在任意处划分都可以。划分的地方需要有重叠的帧,使其平滑过渡。重叠部分的处理为公式4。为了更好使重叠处重合,本文提出了linear cross fading with shift,其公式为5,6。具体的如图3所示,右边的重叠更好。
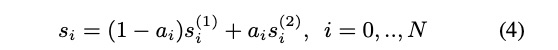
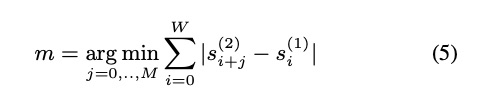
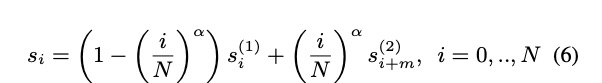
3 实验
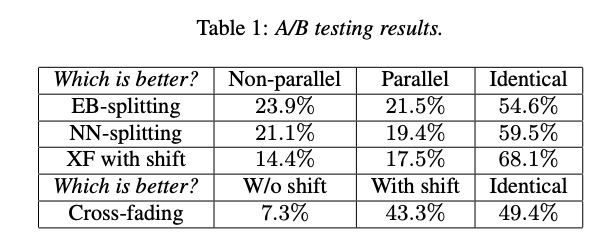
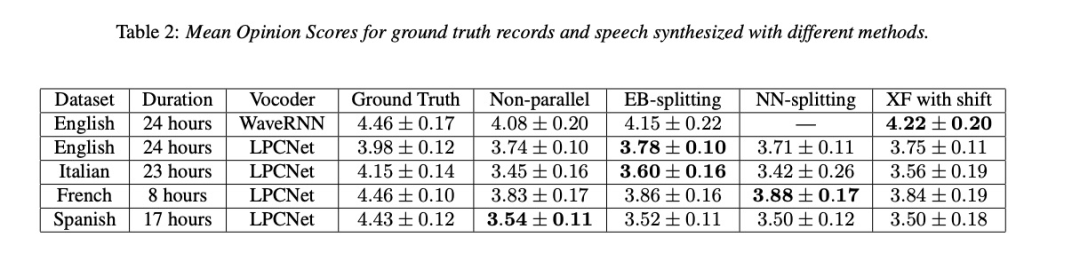
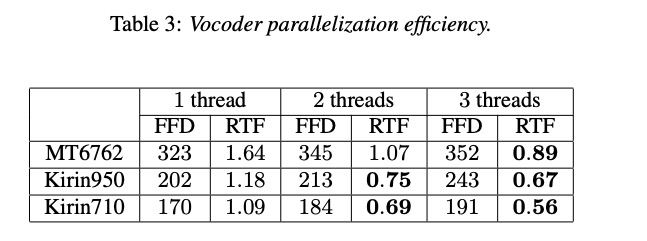
本文的实验主要包括主客观的评比。主观是合成的音质评测,客观为性能测试。首先,先使用AB test的方法对以上策略进行对比,其中EB-splitting为基于能量的划分,NN-splitting为基于神经网络的划分,XF with shift为cross-fading with shitf。由结果table 1可知,使用以上策略不影响音质,同时使用shift明显比不使用的好。其次看下MOS测试table 2,使用以上策略几乎甚至好于没有并行合成,而且本文的策略在其它声码器上依然奏效。最后table 3是性能测试,由结果可知,并行合成可以提高2倍速度。
4 总结
本文主要研究轻量级TTS,使taoctron+lpcnet的TTS系统能够在中低端的移动设备上运行。为了使该系统可以并行运行,提出了基于能量和基于神经网络的帧级别的划分方法和任意划分的后处理cross fading with shift方法,使合成的音质不下降的情况下,速度提高两倍。



















 36
36

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











