







 本文介绍了机器学习模型的评估指标,包括混淆矩阵、精度、召回率和F1分数。混淆矩阵用于描述模型预测结果的四个基本类别:真阳性、真阴性、假阳性、假阴性。精度关注正确预测为阳性的比例,而召回率关注真正阳性的样本被正确预测的比例。F1分数结合精度和召回率,是两者的调和平均数。根据不同业务需求,可以选择不同的F-β得分来平衡精度和召回率。
本文介绍了机器学习模型的评估指标,包括混淆矩阵、精度、召回率和F1分数。混淆矩阵用于描述模型预测结果的四个基本类别:真阳性、真阴性、假阳性、假阴性。精度关注正确预测为阳性的比例,而召回率关注真正阳性的样本被正确预测的比例。F1分数结合精度和召回率,是两者的调和平均数。根据不同业务需求,可以选择不同的F-β得分来平衡精度和召回率。
最近在复盘udacity 的机器学习的课程,现在来整理一下关于机器学习模型的评估指标的相关知识。
不同数据集采用不同的模型进行训练,会得到完全不同的效果,那么如何衡量一个模型是否适合该数据集呢?在数据集训练后可以对一些指标进行运算,观察实际的效果,进行调整参数或者更换模型等等。
学习模型的评估指标常用的有几种:F-β得分(F1得分,F2得分等等,根据不同的业务实际需求来指定适合的β值),ROC 曲线,回归指标包含:平均绝对误差,均方误差,R2分数等等
1 混淆矩阵
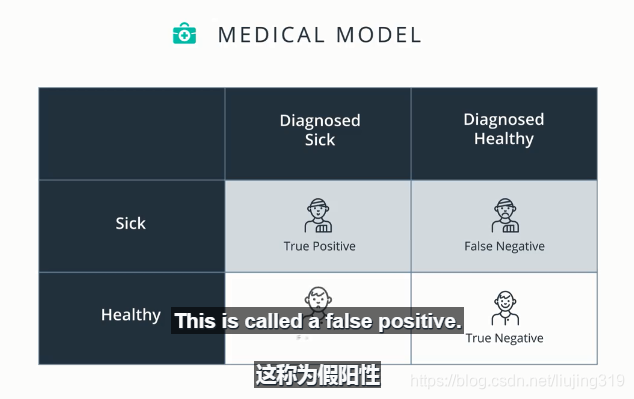
上图为检测特定疾病的例子,如果一个人检测出生病,那么成为阳性,如果检测结果是未生病则为阴性,阳性分为真阳性和假阳性,阴性分为真阴性和假阴性.
如果一个病人检测出生病,则为真阳性 (True Positive ,TP)
如果一个病人检测为健康,则为假阴性(False Negative,FN);
如果一个健康人检测出生病,称为假阳性 (False Positive,FP);
如果一个健康人检测为健康,称为真阴性(True Negative,TN)
由上面四种状态构成的矩阵称之为混淆矩阵。
再看一个检测垃圾邮件的例子:

上图是对应的混淆矩阵,假设一封邮件检测出是垃圾邮件时候称为阳性,那么
当一封垃圾邮件被检测出是垃圾邮件的时候称为真阳性(True Positive ,TP);
当一封垃圾邮件被检测出是正常邮件时候称为假阴性(False Negative,FN);
当一封正常的邮件被检测出是垃圾邮件时候
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1848
1848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









