







文章目录
- 一、混淆矩阵与 F1-Score
- 1. 准确率局限
- 2. 混淆矩阵(Confusion matrix)
- 3. 混淆矩阵中的模型评估指标
- 3.1 围绕识别类别 1 所构建的评估指标
- 3.2 围绕识别类别 0 所构建的评估指标
- 4. 混淆矩阵评估指标使用策略
- 5. 多分类混淆矩阵
- 接下来,我们重点讨论关于分类模型评估指标相关内容。
# 科学计算模块
import numpy as np
# 绘图模块
import matplotlib as mpl
import matplotlib.pyplot as plt
# 自定义模块
from ML_basic_function import *
一、混淆矩阵与 F1-Score
- 分类模型作为使用场景最为广泛的机器学习模型,相关模型评估指标也伴随着使用场景的拓展而不断丰富。
- 除了此前所介绍的准确率以外,常用的二分类模型的模型评估指标还有召回率(Recall)、F1 指标(F1-Score)、受试者特征曲线(ROC-AUC)、KS 曲线等等。不同评估指标有对应的不同的计算方法,当然也有不同的使用场景。
- 接下来,我们就依据不同评估指标彼此之间的计算关系来对二分类问题的模型评估指标进行统一介绍,并给出对应指标使用场景的介绍。
1. 准确率局限
- 首先,是准确率作为模型评估指标时的局限。
- 整体来看,准确率作为最为通用、同时也是较好理解的评估指标,在机器学习领域其实仍然存在一定局限。当然,归根结底,这些局限其实是由准确率本身的计算过程所决定的。
- 准确率在计算过程中,所有样本是均匀投票的,也就是说对每个样本的判别结果,对于最终准确率的影响其实是相同的。例如假设总共有 100 条数据进行分类,其中任意一条样本被误判都会且仅会影响 1% 的准确率。
- 如此一来就会造成两方面影响,其一,对于某些样本极端不平衡的分类数据集来说准确率很难很好的衡量模型表现,例如,假设总共有 100 样本,其中 0 类有 99 条,1 类有 1 条,则此时就算模型判别此 100 条样本全都为 0 类,准确率也将达到 99%,但很多时候可能我们希望的是模型能够将这些 1 识别出来,例如癌症病患数据中癌症患者、金融风控中欺诈用户等。
- 从更加本质的角度来看,那就是在很多业务场景中,将 0 错判为 1、和将 1 错判为 0,其实实际付出的代价是不一样的,很多时候我们并不是单纯的追求将所有的 0 样本都正确的识别为 0 且将 1 样本都正确的判别为 1,而是根据误判的代价,选择更加激进或者更加保守的策略来进行识别。
- 例如如果将 1 样本误判为 0 的代价非常大,而将 0 样本误判为 1 的代价并不大,则会采用“宁可错杀一千、不可放过一个”的激进策略来识别 1。
- 关于准确率的第二方面局限,实际上是一个相对隐藏更深的问题,那就对于哪怕是均衡的分类样本数据集,准确率有时也无法很好的衡量分类模型的分类性能、尤其是模型本身的泛化能力,这也是为什么我们不以准确率而以交叉熵作为损失函数的另一个原因。
- 例如,假设对下述 5 条样本的二分类数据集,构建 A、B 两个逻辑回归模型进行判别,模型判结果如下所示:
| index | labels | A-predicts | B-predicts | predicts_results |
|---|---|---|---|---|
| 1 | 1 | 0.8 | 0.6 | 1 |
| 2 | 0 | 0.6 | 0.9 | 1 |
| 3 | 0 | 0.2 | 0.4 | 0 |
| 4 | 1 | 0.9 | 0.7 | 1 |
| 5 | 1 | 0.9 | 0.6 | 1 |
- 如果是从准确率指标来看,两个模型在阈值为 0.5 的情况下,判别准确率都是 80%(仅判错第二条样本),二者并无高下之分。
- 但如果我们更加仔细的观察模型对各样本输出的概率欧安别结果,其实我们会发现模型 A 其实会更加“优秀”:首先,对于判断正确的 1 类数据,模型A输出的概率预测分别为 0.8、0.9 和 0.9,表示模型非常肯定这些样本应该属于 1 类。
- 而模型 B 的概率预测结果为 0.6、0.7、0.6,表示模型并不是特别肯定这样样本属于 1 类,类似的情况也出现在两个模型正确识别 0 类的判别过程中。
- 此外,对于误判的样本,虽然两个模型都将原本属于 0 类的 2 号样本误判为 1,但模型 B 给出的概率结果是 0.9,代表其非常肯定该样本应该属于 1 类,而模型 A 输出的概率结果为 0.6,表示其并不是非常肯定该样本属于 1 类。
- 在实际建模过程中,类似 A 模型的模型,即对判断正确的样本有较高的肯定、对判断错误的样本不太肯定,这类模型其实是更加准确的捕捉到了数据规律,在后续对于新数据集预测时,也将拥有更强的泛化能力。
- 但遗憾的是,准确率评估指标并无法很好的将 A 类模型和 B 类模型的模型判别能力进行准确区分。
- 此时我们可以通过交叉熵来比较两个模型的好坏优劣。我们知道,交叉熵计算结果越小、模型本身判别能力越强,我们尝试借助交叉熵计算公式来计算两个模型输出结果的交叉熵: B C E A = − l o g 2 ( 0.8 ) − l o g 2 ( 0.4 ) − l o g 2 ( − 0.8 ) − l o g 2 ( 0.9 ) − l o g 2 ( 0.9 ) 5 BCE_A = \frac{-log_2(0.8)-log_2(0.4)-log_2(-0.8)-log_2(0.9)-log_2(0.9)}{5} BCEA=5−log2(0.8)−log2(0.4)−log2(−0.8)−log2(0.9)−log2(0.9)
(-np.log(0.8)-np.log(0.4)-np.log(0.8)-np.log(0.9)-np.log(0.9)) / 5
#0.31465977316364546
B C E B = − l o g 2 ( 0.6 ) − l o g 2 ( 0.1 ) − l o g 2 ( − 0.6 ) − l o g 2 ( 0.7 ) − l o g 2 ( 0.6 ) 5 BCE_B = \frac{-log_2(0.6)-log_2(0.1)-log_2(-0.6)-log_2(0.7)-log_2(0.6)}{5} BCEB=5−log2(0.6)−log2(0.1)−log2(−0.6)−log2(0.7)−log2(0.6)
(-np.log(0.6)-np.log(0.1)-np.log(0.6)-np.log(0.7)-np.log(0.6)) / 5
#0.83834738164615
- 此处也可以直接调用此前定义的 BCE 函数进行计算。
- 能够看出,模型 A 输出结果的交叉熵是要小于模型 B 的,因此模型 A 其实拥有对既定样本更强的判别能力。
- 此时我们发现,无论是从通俗的角度看模型对样本类别判别的肯定程度,还是从交叉熵计算结果来看,模型 A、B 实际上是存在判别能力的差异的,但这种差异无法被准确率很好的衡量。
- 那么既然能够通过交叉熵观察模型判别能力,那为何我们不选取交叉熵作为模型评估指标?
- 其实交叉熵一般不作为模型评估指标的主要原因以下有两个方面。
- 其一是交叉熵的取值并不在一个固定的区间范围内,交叉熵 = 相对熵 + 信息熵,由于相对熵大于等于 0 的特性,所以交叉熵实际上是在 [信息熵, +∞) 内取值,而不在一个固定区间内取值就导致交叉熵数值很难进行不同模型、数据之间的横向对比。
- 其二则是尽管在建模的时候我们是通过梯度下降求解交叉熵损失函数的最小值,此时我们希望交叉熵的值越小越好,但其实有的时候,一味追求交叉熵更小的值也有可能导致模型过拟合,因此实际上交叉熵的值也不是越小越好,此时甚至会需要结合准确率来综合调参,寻找一个准确率较高、但交叉熵不是特别小的模型,来削弱过拟合倾向。
- 因此,在绝大多数时候,交叉熵的主要功能还是作为指导模型进行参数求解的损失函数。
- 而为了修正准确率的“均匀投票”在某些场景下的缺陷,我们将引入混淆矩阵、召回率、精确度、F1-Score 等指标来完善模型评估指标体系,而为了更好的评估模型整体分类效力,我们将引入 ROC-AUC 等指标,此外我们还将介绍用于模型结果代价衡量和辅助判别最佳阈值的 K-S 曲线。
2. 混淆矩阵(Confusion matrix)
- 混淆矩阵作为分类模型结果的更加细致精确的可视化展示,有时也被称为误差矩阵或者可能性表格,通常混淆矩阵会应用于二分类问题中,对此首先有如下关键定义:
- (1) Actual condition:样本真实标签;
- (2) Predicated condition:模型预测标签;
- 例如,有如下数据集,第一列为真实标签,即 Actual condition,第二列为模型预测结果,即 Predicated condition,数据集如下:
| labels(Actual condition) | predicted(Predicated condition) |
|---|---|
| 1 | 0 |
| 1 | 0 |
| 1 | 1 |
| 1 | 1 |
| 1 | 1 |
| 1 | 1 |
| 1 | 1 |
| 1 | 1 |
| 0 | 0 |
| 0 | 0 |
| 0 | 0 |
| 0 | 1 |
- 而在不同标签类别方面,则可进一步细分为:
- (1) Actual condition positive(P):样本中阳性样本总数,一般也就是真实标签为 1 的样本总数;
- (2) Actual condition negative(N):样本中阴性样本总数,一般也就是真实标签为 0 的样本总数;
- (3) Predicted condition positive(PP):预测中阳性样本总数,一般也就是预测标签为 1 的样本总数;
- (4) Predicted condition negative(PN):预测中阳性样本总数,一般也就是预测标签为 0 的样本总数;
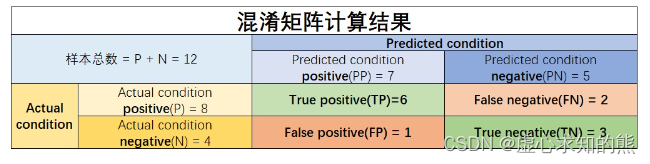
- 对于上述数据集而言,P=8,N=4,PP=7,PN=5。并且,样本总数 = P + N = PP + NN = 12。
- 此外,在进行二分类模型预测过程中,样本类别被模型正确识别的情况其实有两种,一种是阳性样本被正确识别,另一种是阴性样本被正确识别,据此我们可以有如下定义:
- (1) True positive(TP):样本属于阳性(类别 1)、并且被正确识别为阳性(类别 1)的样本总数;TP发生时也被称为正确命中(hit);
- (2) True negative(TN):样本属于阴性(类别 0)、并且被正确识别为阴性(类别 0)的样本总数;TN发生时也被称为正确拒绝(correct rejection);
- 对于上述数据集而言,TP=6,TN=3。
- 当然,对于误分类的样本,其实也有两种情况,其一是阳性样本被误识别为阴性,其二是阴性样本被误识别为阳性,据此我们也有如下定义:
- (1) False positive(FP):样本属于阴性(类别 0),但被错误判别为阳性(类别 1)的样本总数;FP发生时也被称为发生I类了错误(Type I error),或者假警报(False alarm)、低估(underestimation)等;
- (2) False negative(FN):样本属于阳性(类别 1),但被错误判别为阴性(类别 0)的样本总数;FN发生时也被称为发生了II类错误(Type II error),或者称为错过目标(miss)、高估(overestimation)等;
- 对于上述数据集而言,FP=1,FN=2。
- 不难发现,混淆矩阵其实具有非常强的统计表的背景,并且和此前介绍的一样、也是更倾向于重点识别 1 类(阳性)样本。
- 对于上述符号,其实不难发现,第一位字母其实表示模型判断的正误(True or False),第二位字母代表样本预测标签(Positive or Negative)。通过上述关键指标,则可构成混淆矩阵:

- 对于上述数据集,混淆矩阵计算结果为:
3. 混淆矩阵中的模型评估指标
3.1 围绕识别类别 1 所构建的评估指标
- 当然,对于混淆矩阵来说,其实仍然属于第一级观察指标,通过混淆矩阵,通常我们并不会直接使用混淆矩阵中的一级指标,而是去使用基于这些一级指标的二级指标。
- 例如从上述混淆矩阵所提供的结果不难看出,准确率其实就是 ACC=TP+TNTP+TN+FP+FN 。
- 当然此外其实还有其他很多常用的二级指标,通过这些二级指标的构建,可以补充准确率在偏态样本中重点识别某类样本时表现的不足。首先,如果是更加关注类别 1 样本的识别情况,则有两个常用指标:
- 召回率(Recall)
- 召回率侧重于关注全部的 1 类样本中别准确识别出来的比例,其计算公式为: R e c a l l = T P T P + F N Recall = \frac{TP}{TP+FN} Recall=TP+FNTP
- 对于上例中,全部 12 条样本中有 8 条 1 类样本,而其中有 6 条被正确识别,因此上例的召回率为 6/8=75%。
- 根据召回率的计算公式我们可以试想,如果以召回率作为模型评估指标,则会使得模型非常重视是否把 1 全部识别了出来,甚至是牺牲掉一些 0 类样本判别的准确率来提升召回率,即哪怕是错判一些 0 样本为 1 类样本,也要将 1 类样本识别出来。
- 因此,召回率其实是一种较为激进的识别 1 类样本的评估指标,在 0 类样本被误判代价较低、而 1 类样本被误判成本较高时可以考虑使用。
- 当然,对于极度不均衡样本,这种激进的判别指标也能够很好的判断模型有没有把 1 类样本成功的识别出来。
- 例如总共 100 条数据,其中有 99 条样本标签为 0、剩下一条样本标签为 1,假设模型总共有 A、B、C 三个模型,A 模型判别所有样本都为 0 类,B 模型判别 50 条样本为 1 类 50 条样本为 0 类,并且成功识别唯一的一个 1 类样本,C 模型判别 20 条样本为 1 类、80 条样本为 0 类,同样成功识别了唯一的一个 1 类样本,则各模型的准确率和召回率如下:
| Model | ACC | Recall |
|---|---|---|
| A | 99% | 0 |
| B | 51% | 100% |
| C | 81% | 100% |
- 不难发现,在偏态数据中,相比准确率,召回率对于 1 类样本能否被正确识别的敏感度要远高于准确率,但对于是否牺牲了 0 类别的准确率却无法直接体现。
- 此外,召回率往往还被称为 sensitivity(敏感度)、hit rate(命中率)、true positive rate(TPR)以及查全率等。
- 精确度(Precision)
- 和召回率不同,精确度并不主张“宁可错杀一千不可放过一个”,而是更加关注每一次出手(对 1 类样本的识别)能否成功(准确识别出 1)的概率,精确度计算公式为: P r e c i s i o n = T P T P + F P Precision = \frac{TP}{TP+FP} Precision=TP+FPTP
- 对于上例中,全部 12 条样本,模型总共判别 7 条样本为 1 类样本,但其中有 6 条判别准确,精确度为 6/7=86%。
- 当然,也正是由于这种力求每次出手都尽可能成功的策略,使得当我们在以精确度作为模型判别指标时,模型整体对 1 的判别会趋于保守,只对那些大概率确定为 1 的样本进行 1 类的判别,从而会一定程度牺牲 1 类样本的准确率,在每次判别成本较高、而识别 1 样本获益有限的情况可以考虑使用精确度。
- 同样,对于召回率中所举的例子来看,此时A、B、C三个模型的精确度为:
| Model | ACC | Recall | Precision |
|---|---|---|---|
| A | 99% | 0 | 0 |
| B | 51% | 100% | 2% |
| C | 81% | 100% | 5% |
- 能够发现,对于偏态样本,相比准确率,精确度能够一定程度反应是否成功识别出 1 类样本(尽管敏感度不如召回率),并且能够较好的反应对 0 类样本准确率的牺牲程度。
- 此外,精确度有时也被称为 positive predictive value(PPV)和查准率等。
- 关于召回率和精确度,也可以通过如下形式进行更加形象的可视化展示
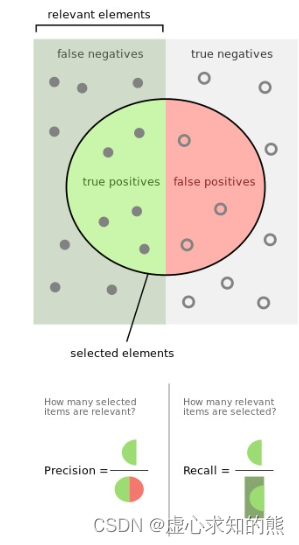
- F1-Score
- 不难发现,召回率和精确度其实是一对相对的概念,在围绕 1 类样本的识别过程中,召回率力求尽可能更多的将 1 识别出来,而精确度则力求每次对 1 样本的判别都能获得一个正确的结果。
- 在大多数情况下,其实我们是希望获得一个更加“均衡”的模型判别指标,即我们既不希望模型太过于激进、也不希望模型太过于保守,并且对于偏态样本,既可以较好的衡量 1 类样本是否被识别,同时也能够兼顾考虑到0类样本的准确率牺牲程度。
- 此时,我们可以考虑使用二者的调和平均数(harmonic mean)作为模型评估指标,即 F1-Score。
- 所谓 A 和 B 的调和平均数,指的是 2 1 A + 1 B = 2 A B A + B \frac{2}{\frac{1}{A}+\frac{1}{B}}=\frac{2AB}{A+B} A1+B12=A+B2AB 的计算结果,则 F1-Score 计算公式如下: F 1 − S c o r e = 2 1 R e c a l l + 1 P r e c i s i o n = 2 ⋅ R e c a l l ⋅ P r e c i s i o n R e c a l l + P r e c i s i o n F1-Score = \frac{2}{\frac{1}{Recall}+\frac{1}{Precision}}=\frac{2 \cdot Recall \cdot Precision}{Recall+Precision} F1−Score=Recall1+Precision12=Recall+Precision2⋅Recall⋅Precision
- 当然,通常我们也会用 TPR 表示 Recall、PPV 表示 Precision,此时 F1-Score 可表示如下: F 1 − S c o r e = 2 ⋅ T P R ⋅ P P V T P R + P P V F1-Score = \frac{2\cdot TPR \cdot PPV}{TPR+PPV} F1−Score=TPR+PPV2⋅TPR⋅PPV
- 如果更近一步用混淆矩阵的一级指标来进行表示,则: F 1 − S c o r e = 2 ⋅ T P 2 ⋅ T P + F P + F N F1-Score = \frac{2\cdot TP}{2\cdot TP+FP+FN} F1−Score=2⋅TP+FP+FN2⋅TP
- 根据 F1-Score 的计算公式不难发现,F1-Score 是一个介于 [0,1] 之间的计算结果,当 FP+FN=0 时候(即没有误判样本时),F1-Score 计算结果为 1;而当没有正确识别出一个 1 时,即 TP=0 时,F1-Score=0。
- 对于偏态样本中的建模结果来说,此时 A、B、C 三个模型的 F1-Score 为:
| Model | ACC | Recall | Precision | F1-Score |
|---|---|---|---|---|
| A | 99% | 0 | 0 | 0 |
| B | 51% | 100% | 2% | 0.04 |
| C | 81% | 100% | 5% | 0.095 |
- 对于下述混淆矩阵来说,F1-Score 计算结果为 12 12 + 2 + 1 = 0.8 \frac{12}{12+2+1}=0.8 12+2+112=0.8

- F1-Score 基本性质
- 当然,从上述结果来看,F1-Score 指标能够一定程度上综合 Recall 和 Precision 的结果,综合判断模型整体分类性能。
- 当然,除了 F1-Score 以外我们还可以取 Recall 和 Precision 的均值(balanced accuracy,简称BA)来作为模型评估指标: B A = R e c a l l + P r e c i s i o n 2 BA = \frac{Recall+Precision}{2} BA=2Recall+Precision
- 不过,相比平均数,调和平局数其实会更大程度上受到短板数据的影响。
- 从上述结果不难发现,从模型 B 到模型 C,F1-Score 的数值增长幅度和 Precision 涨幅类似,这其实就是由 F1-Score 的调和平均数的性质决定的。
- 关于这点,我们可以通过下面一组代码实验来进行相关测试:
def harmonic_mean(A, B):
return 2 * A * B/(A + B)
A = np.linspace(0, 1, 100)
B = np.ones(shape = A.shape)
A
#array([0. , 0.01010101, 0.02020202, 0.03030303, 0.04040404,
# 0.05050505, 0.06060606, 0.07070707, 0.08080808, 0.09090909,
# 0.1010101 , 0.11111111, 0.12121212, 0.13131313, 0.14141414,
# 0.15151515, 0.16161616, 0.17171717, 0.18181818, 0.19191919,
# 0.2020202 , 0.21212121, 0.22222222, 0.23232323, 0.24242424,
# 0.25252525, 0.26262626, 0.27272727, 0.28282828, 0.29292929,
# 0.3030303 , 0.31313131, 0.32323232, 0.33333333, 0.34343434,
# 0.35353535, 0.36363636, 0.37373737, 0.38383838, 0.39393939,
# 0.4040404 , 0.41414141, 0.42424242, 0.43434343, 0.44444444,
# 0.45454545, 0.46464646, 0.47474747, 0.48484848, 0.49494949,
# 0.50505051, 0.51515152, 0.52525253, 0.53535354, 0.54545455,
# 0.55555556, 0.56565657, 0.57575758, 0.58585859, 0.5959596 ,
# 0.60606061, 0.61616162, 0.62626263, 0.63636364, 0.64646465,
# 0.65656566, 0.66666667, 0.67676768, 0.68686869, 0.6969697 ,
# 0.70707071, 0.71717172, 0.72727273, 0.73737374, 0.74747475,
# 0.75757576, 0.76767677, 0.77777778, 0.78787879, 0.7979798 ,
# 0.80808081, 0.81818182, 0.82828283, 0.83838384, 0.84848485,
# 0.85858586, 0.86868687, 0.87878788, 0.88888889, 0.8989899 ,
# 0.90909091, 0.91919192, 0.92929293, 0.93939394, 0.94949495,
# 0.95959596, 0.96969697, 0.97979798, 0.98989899, 1. ])
B
#array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
# 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
# 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
# 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
# 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
# 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
plt.plot(A, harmonic_mean(A, B), label = 'harmonic_mean')
plt.plot(A, (A+B)/2, label = 'mean')
plt.xlabel('A')
plt.ylabel('result')
plt.title('harmonic_mean vs mean')
plt.legend(loc = 4)
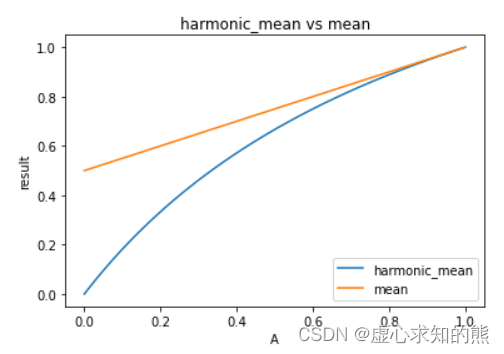
- 能够看出,调和平均数和均值相比,其实会更大程度受到短板数据影响,从这个角度来看,F1-Score 其实会更加严格。
- 只要参与计算的 Recall 和 Precision 其中一个指标较小,F1-Score 指标就会整体偏小,而当 F1-Score 结果较大时,则说明模型整体分类性能较强,并且哪怕是极端不平衡数据,只要 F1-Score 计算结果较大,就说明模型对少数类别样本也具有很好的分类性能。
- 从这个角度来说,F1-Score 是个比 ACC 更全面的评估指标,并且,为了能够更严格的要求模型训练过程以期达到一个更好的建模效果,我们往往更倾向于采用 F1-Score 作为模型评估指标,而不是 BA。
- 除了 F1-Score 以外,还有一种更为一般的、可以自主调整召回率和精确度在参与调和平均数计算过程中的权重的评估指标, F β F_\beta Fβ,其计算公式如下: F β = ( 1 + β 2 ) p r e c i s i o n ⋅ r e c a l l ( β 2 ⋅ p r e c i s i o n ) + r e c a l l F_\beta=(1+\beta ^2)\frac{precision \cdot recall}{(\beta ^2 \cdot precision)+recall} Fβ=(1+β2)(β2⋅precision)+recallprecision⋅recall
- 值得注意的是,F1-Score 并不是类别对称的,也就是说,如果我们将 0 类和 1 类数据标签互换,最终算得的 F1-Socre 结果会有所不同。
- 因此其实 F1-Score 虽然是一个更加均衡的评估指标,但其实也只是均衡了在识别 1 类样本时“激进”或者“保守”的倾向性,但本质上还是一个围绕模型对 1 类样本识别能力所构建的评估指标。
3.2 围绕识别类别 0 所构建的评估指标
- 如果说 Recall 和 Precision 其实都是围绕以识别类别 1 为核心目标来构建的评估指标,那么由于二分类的两个类别的对称性,我们完全可以识别类别 0 为核心目标来构建一套镜像的模型评估指标。

- 特异度(Specificity)
- 首先是用来衡量 0 类被正确识别比例的特异度,该指标类似召回率,都是较为激进的评估指标,只考虑关注的类(0 类或者 1 类)被识别出来的比例,而不考虑在识别过程中是否牺牲了另外一类的准确率。该指标计算公式如下: S p e c i f i c i t y = T N T N + F P Specificity = \frac{TN}{TN+FP} Specificity=TN+FPTN
- 同样,对于上述例子来看,特异度计算结果为 3/4=0.75

- 此外,特异度往往也被称为 true negative rate (TNR)。
- 阴性预测值(negative predictive value)
- 同样,类似 Precision,对于 0 类样本的衡量,也有一个相对保守评估指标,用于衡量对 0 类样本进行判别的所有判别结果中正确识别的 0 类样本所占得比例,也就是阴性预测值指标,往往也被称为NPV(negative predictive value)。其计算公式如下: N P V = T N T N + F N NPV = \frac{TN}{TN+FN} NPV=TN+FNTN
- 而对于上述例子来说,NPV 计算结果为 3/5=0.6
3/5
#0.6
- 不过,需要注意的是,尽管有一套和识别 1 类镜像的识别 0 类的指标,但是,通常来说,我们还是会倾向于将重点识别的类别划为 1 类,然后采用围绕 1 类构建的指标来进行模型评估,而不是将其任意划为 1 类或者 0 类,然后选取对应类别评估指标来进行模型评估。
- 此外,对于 F1-Score 指标来说,尽管其能够间接兼顾 0 类别的判别情况,但归根结底,F1-Score 仍然还是围绕类别 1 的识别建立起来的评估指标,因此如果重点识别类别是 0 类,那么还是建议先将其改为 1 类,然后再利用 F1-Score 进行建模。
- 其实我们仿造 F1-Score 构造一个由 TNR 和 NPV 的调和平均数计算结果指标,通过验证该指标和 F1-Score 计算结果的不同,来证明 F1-Score 其实并非 0-1 类别对称指标。
- F1-Score 指标的非对称性主要是受到不同类别样本数量影响。
- 伪阳率(false positive rate)
- 除了上述指标外,我们还需要补充一个对后续会经常用到的一个评估指标:伪阳率(false positive rate),其计算公式为: F P R = 1 − s p e c i f i c i t y = F P F P + T N FPR = 1-specificity=\frac{FP}{FP+TN} FPR=1−specificity=FP+TNFP
- 即表示在所有预测为 0 类的样本中,错误样本所占比例。
- 此外,Matthews correlation coefficient(马修斯相关系数)、Fowlkes–Mallows index(聚类评价标准)系数等常用评估指标。
4. 混淆矩阵评估指标使用策略
- 在介绍了这么多基于混淆矩阵的评估指标之后,接下来我们简单总结这些评估指标的一般使用策略。
- 首先,在类别划分上,仍然需要强调的是,我们需要根据实际业务情况,将重点识别的样本类划为类别 1,其他样本划为类别 0。
- 当然,如果 0、1 两类在业务判断上并没有任何重要性方面的差异,那么我们可以将样本更少的哪一类划为 1 类。
- 其次,在评估指标选取上,同样需要根据业务情况判断,如果只需要考虑 1 类别的识别率,则可考虑使用 Recall 作为模型评估指标,若只需考虑对 1 样本判别结果中的准确率,则可考虑使用 Precision 作为评估指标。
- 但一般来说这两种情况其实都不多,更普遍的情况是,需要重点识别 1 类但也要兼顾 0 类的准确率,此时我们可以使用 F1-Score 指标。目前来看,F1-Score 其实也是分类模型中最为通用和常见的分类指标。
- 当然,在某些情况下,例如使用 Scikit-Learn 利用网格搜索进行模型调参时,对于某些本身分类性能比较强(本身对两类都能进行较好识别)的模型,我们可以适时采用召回率作为网格搜索评价指数,来提升 1 类识别准确率。
5. 多分类混淆矩阵
- 一般来说混淆矩阵常用于二分类问题,对于多分类问题,我们同样可以构建如下形式的混淆矩阵:
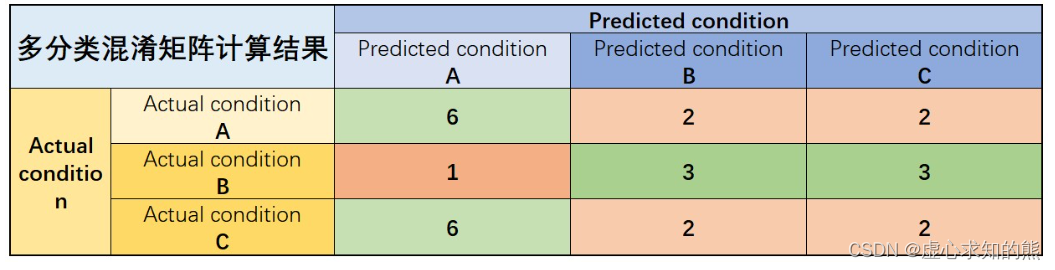
- 此时,如果要进行 Recall、Precision 的计算,则需要先采用此前介绍的 OVR 策略进行“划分”、然后采用均值策略进行“集成”,依次将 A、B、C 视为 1 类,其余类别视为 0 类来进行计算。
- 例如,A、B、C 三类的 Recall 为: R e c a l l A = 6 6 + 2 + 2 = 0.6 Recall_A = \frac{6}{6+2+2} = 0.6 RecallA=6+2+26=0.6 R e c a l l B = 3 3 + 1 + 3 = 3 7 = 0.42 Recall_B = \frac{3}{3+1+3} = \frac{3}{7} = 0.42 RecallB=3+1+33=73=0.42 R e c a l l C = 2 2 + 2 + 6 = 0.2 Recall_C = \frac{2}{2+2+6} = 0.2 RecallC=2+2+62=0.2
- 然后,进行均值计算,即可算得此时模型整体 Recall: R e c a l l = 0.6 + 0.42 + 0.2 3 = 0.4 Recall = \frac{0.6+0.42+0.2}{3} = 0.4 Recall=30.6+0.42+0.2=0.4
- 类似,可以算得 P r e c i s i o n A = 6 13 = 0.46 Precision_A = \frac{6}{13} = 0.46 PrecisionA=136=0.46, P r e c i s i o n B = 3 7 = 0.42 Precision_B = \frac{3}{7} = 0.42 PrecisionB=73=0.42, P r e c i s i o n C = 2 7 = 0.28 Precision_C = \frac{2}{7} = 0.28 PrecisionC=72=0.28,随后利用三者均值求出模型整体 P r e c i s i o n = 0.38 Precision=0.38 Precision=0.38。
- 当然,我们也可以计算模型整体 F1-Score,此时仍然需要分别计算 A、B 和 C 三个模型的 F1-Score,然后利用均值进行集成即可。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











