







1、混淆矩阵
在二分类问题中,混淆矩阵被用来度量模型的准确率。因为在二分类问题中单一样本的预测结果只有Yes or No,即:真或者假两种结果,所以全体样本的经二分类模型处理后,处理结果不外乎四种情况,每种情况都有一个专门称谓,如果用一个2行2列表格描述,得到的就是“混淆矩阵”,

2.准确率
准确率(Accuracy)的定义,即预测正确的结果占总样本的百分比,表达式为

虽然准确率能够判断总的正确率,但是在样本不均衡的情况下,并不能作为很好的指标来衡量结果。
比如在样本集中,正样本有90个,负样本有10个,样本是严重的不均衡。对于这种情况,我们只需要将全部样本预测为正样本,就能得到90%的准确率,但是完全没有意义。对于新数据,完全体现不出准确率。因此,在样本不平衡的情况下,得到的高准确率没有任何意义,此时准确率就会失效。所以,我们需要寻找新的指标来评价模型的优劣。
3、精确率
精确率(Precision)是针对预测结果而言的,其含义是在被所有预测为正的样本中实际为正样本的概率,表达式为:
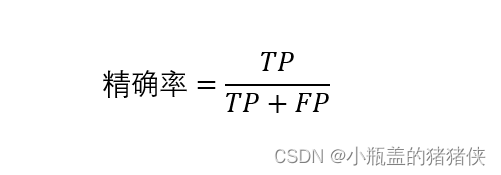
精确率和准确率看上去有些类似,但是是两个完全不同的概念。精确率代表对正样本结果中的预测准确程度,准确率则代表整体的预测准确程度,包括正样本和负样本
4、召回率
召回率(Recall)是针对原样本而言的,其含义是在实际为正的样本中被预测为正样本的概率,表达式为:

下面我们通过一个简单例子来看看精确率和召回率。假设一共有10篇文章,里面4篇是你要找的。根据你的算法模型,你找到了5篇,但实际上在这5篇之中,只有3篇是你真正要找的。
那么算法的精确率是3/5=60%,也就是你找的这5篇,有3篇是真正对的。算法的召回率是3/4=75%,也就是需要找的4篇文章,你找到了其中三篇。以精确率还是以召回率作为评价指标,需要根据具体问题而定。
5、漏报率
反映分类器或者模型正确预测负样本纯度的能力,减少将正样本预测为负样本,即正样本被预测为负样本占总的正样本的比例。

6、误报率
反映分类器或者模型正确预测正样本纯度的能力,减少将负样本预测为正样本,即负样本被预测为正样本占总的负样本的比例。

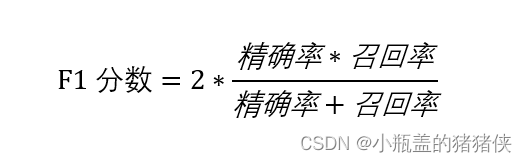
7、F1分数
精确率和召回率又被叫做查准率和查全率,可以通过P-R图进行表示
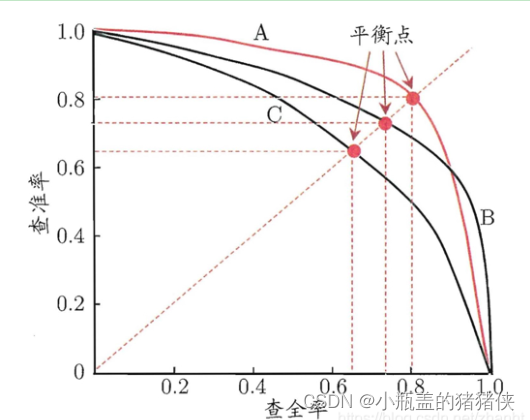
如何理解P-R(精确率-召回率)曲线呢?或者说这些曲线是根据什么变化呢?
以逻辑回归举例,其输出值是0-1之间的数字。因此,如果我们想要判断用户的好坏,那么就必须定一个阈值。比如大于0.5指定为好用户,小于0.5指定为坏用户,然后就可以得到相应的精确率和召回率。但问题是,这个阈值是我们随便定义的,并不知道这个阈值是否符合我们的要求。因此为了寻找一个合适的阈值,我们就需要遍历0-1之间所有的阈值,而每个阈值都对应一个精确率和召回率,从而就能够得到上述曲线。
根据上述的P-R曲线,怎么判断最好的阈值点呢?首先我们先明确目标,我们希望精确率和召回率都很高,但实际上是矛盾的,上述两个指标是矛盾体,无法做到双高。因此,选择合适的阈值点,就需要根据实际问题需求,比如我们想要很高的精确率,就要牺牲掉一些召回率。想要得到很高的召回率,就要牺牲掉一些精准率。但通常情况下,我们可以根据他们之间的平衡点,定义一个新的指标:F1分数(F1-Score)。F1分数同时考虑精确率和召回率,让两者同时达到最高,取得平衡。F1分数表达式为
上图P-R曲线中,平衡点就是F1值的分数

















 1709
1709

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









