




目录
前言:当数据洪流遇上AI浪潮
我们正处在一个数据爆炸的时代。从智能工厂的传感器,到新能源汽车的电池管理系统,再到智慧城市的环境监测设备,每分每秒,数以亿计的数据点如潮水般涌来。这些携带时间戳的数据,便是“时序数据”——它们是物理世界在数字空间的真实脉搏。
为了驯服这股数据洪流,时序数据库(TSDB)应运而生。它专为处理这种“时间-数值”对的数据而设计,提供了传统关系型数据库无法比拟的写入吞吐、压缩效率和查询性能。
然而,故事并未就此结束。当强大的AI大模型开始席卷各行各业,我们对数据的需求发生了质变。我们不再满足于仅仅“存储”和“查询”数据,我们渴望“理解”数据、“预测”未来,并最终实现“智能决策”。这向作为数据底座的TSDB提出了一个全新的、极其严苛的考题:你,为AI时代准备好了吗?
一、地基与承重墙:基础性能依然是“硬通货”
无论概念如何演进,一个TSDB的立身之本,永远是其处理海量时序数据的硬核能力。在考察一个TSDB时,以下四个基础性能指标是必须严格评估的“生命线”。
(1)极致的写入性能
工业物联网(IIoT)场景的特点是“测点多、频率高”。一个大型工厂可能有数百万个传感器测点,部分设备的数据采集频率甚至达到赫兹(Hz)级别。这意味着TSDB必须具备每秒处理数百万甚至数千万数据点的写入能力。如果写入性能不足,轻则导致数据延迟,重则造成数据丢失,这对于依赖实时数据进行监控和预警的工业场景是不可接受的。
因此,一个优秀的TSDB必须拥有专为高并发、高吞吐写入设计的架构,例如基于LSM-Tree的存储引擎、内存写入优化、批量提交机制等。Apache IoTDB在设计之初就将高吞-吐写入作为核心目标,通过其独特的存储结构和数据模型,能够轻松应对大规模测点的并发写入压力。
(2)高效的存储压缩
时序数据量巨大,日积月累下,存储成本是一个不容忽视的问题。动辄TB甚至PB级别的历史数据,如果未经高效压缩,将带来巨大的财务负担。
顶级的TSDB会内置多种专为时序数据优化的压缩算法。因为时序数据往往具有高度的规律性和冗余性(例如,温度值在短时间内变化平缓),通过时间戳压缩、数值压缩(如差分、游程编码)等手段,可以实现极高的压缩比,通常能达到10:1甚至更高。IoTDB就提供了包括SNAPPY、LZ4在内的通用压缩算法,以及专为不同数据类型设计的TS_2DIFF、RLBE等多种高效编码方式,能将存储成本降至最低。
(3)灵活高速的查询能力
数据的价值在于被使用。TSDB需要支持两类核心查询场景:
* 实时监控查询:这类查询要求极低的延迟,用于实时监控大屏、即时告警等。查询的特点是时间范围近、数据量不大,但并发度高。
* 复杂分析查询:这类查询用于故障追溯、趋势分析、生成报表等。查询的特点是时间跨度长、数据量大,通常涉及聚合(平均、最大/小值)、降采样、窗口计算等复杂操作。
一个成熟的TSDB,应该能同时高效地满足这两类需求,提供丰富的查询函数库和灵活的SQL支持,让数据分析师和工程师能够方便地从海量数据中挖掘洞见。
-- 示例1:实时获取指定设备最新的温度读数,用于实时监控
SELECT last temperature FROM root.factory.workshop_1.device_2;
-- 示例2:计算指定设备在过去一个月内,温度的日平均值,用于趋势分析
SELECT AVG(temperature)
FROM root.factory.workshop_1.device_2
GROUP BY ([2025-01-01T00:00:00, 2025-01-31T23:59:59), 1d);(4)无缝的水平扩展能力
业务的增长是动态的,数据量和设备数量也可能在未来几年内呈指数级增长。因此,TSDB必须具备强大的水平扩展能力。一个优秀的分布式TSDB,应该能通过简单地增加节点,就线性地提升整个集群的写入和查询能力,而无需对业务进行大规模改造。这种“在线扩容”的能力,是保障业务连续性和未来发展的关键。IoTDB的分布式架构正是为此而生,能够随着业务规模的增长而平滑扩展。

二、桥梁与生态圈:一个数据库不是一座孤岛
一个TSDB再强大,如果无法与企业现有的技术栈和工具链顺畅集成,其价值也会大打折扣。一个繁荣的生态系统,是衡量其成熟度和易用性的重要标准。
(1)数据接入生态:能否轻松对接主流的数据传输中间件(如Kafka, MQTT)、流处理引擎(如Flink, Spark)和ETL工具?丰富的连接器(Connector)意味着更低的数据集成成本。
(2)数据应用生态:能否与Grafana等主流可视化工具无缝集成,快速搭建监控仪表盘?能否支持各类编程语言的客户端(Java, Python, Go等),方便应用开发?
(3)部署运维生态:是否支持容器化部署(Docker, Kubernetes),以适应现代云原生运维体系?是否提供完善的监控和管理工具?
(4)社区与支持:背后是否有活跃的开源社区(如Apache软件基金会)?这意味着技术能持续演进,遇到问题时能找到丰富的文档和社区帮助。同时,是否有专业的商业公司提供企业级的技术支持和解决方案?这对于在生产环境中大规模应用至关重要。
IoTDB作为Apache顶级项目,拥有一个全球化的活跃社区,并与Flink、Spark、Grafana等主流大数据和可视化工具深度集成。同时,其背后的商业公司时序未央(Timecho)也为企业用户提供了稳定可靠的商业支持。
三、AI时代的决胜局:谁能与AI“无缝对话”?
如果说基础性能和生态系统是当下的核心竞争力,那么与AI的融合深度,则直接决定了一个TSDB的未来。在AI时代,数据不再仅仅是被动查询的对象,而是需要主动参与到模型训练和推理中。
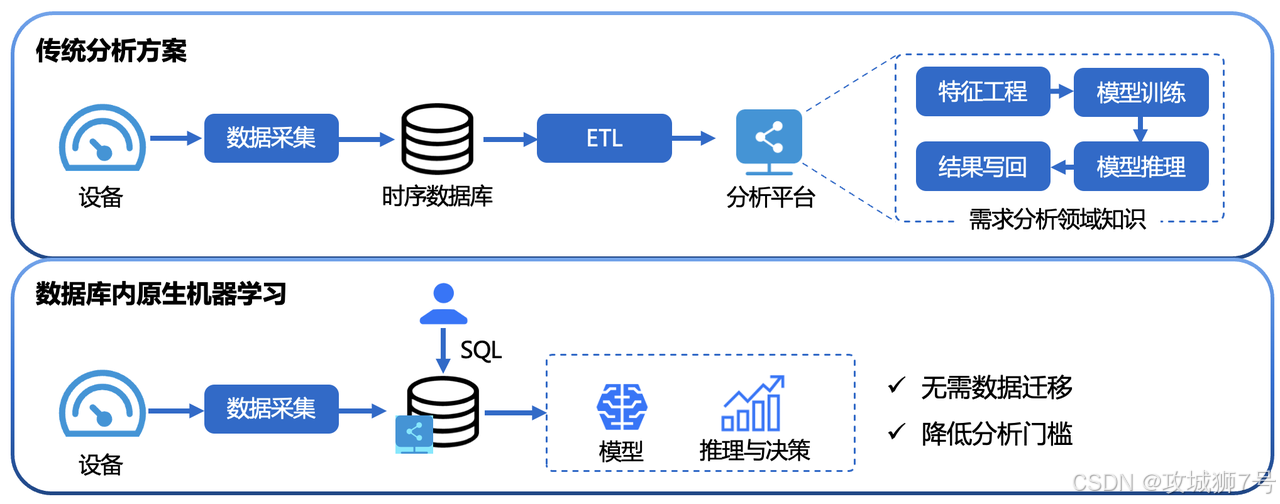
传统的“数据+AI”工作流,通常是割裂的:
`从TSDB导出数据` → `传输到数据分析平台` → `编写Python脚本进行预处理` → `送入模型进行训练/推理` → `获得结果`
这个流程冗长、低效,且存在数据冗余和安全风险。未来的范式,必然是“AI能力内建”和“与大模型无缝对话”。
3.1 AI能力内建:让数据库“会思考”
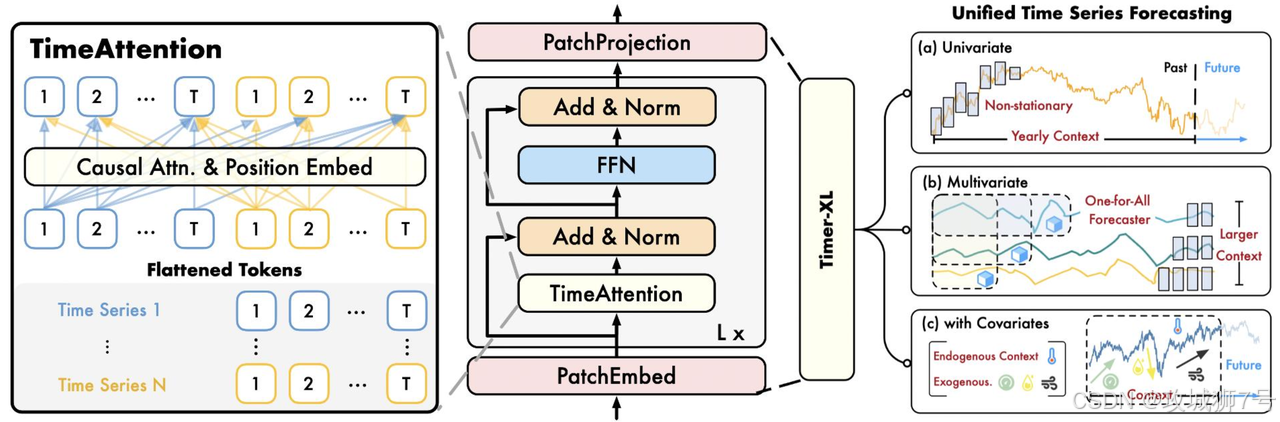
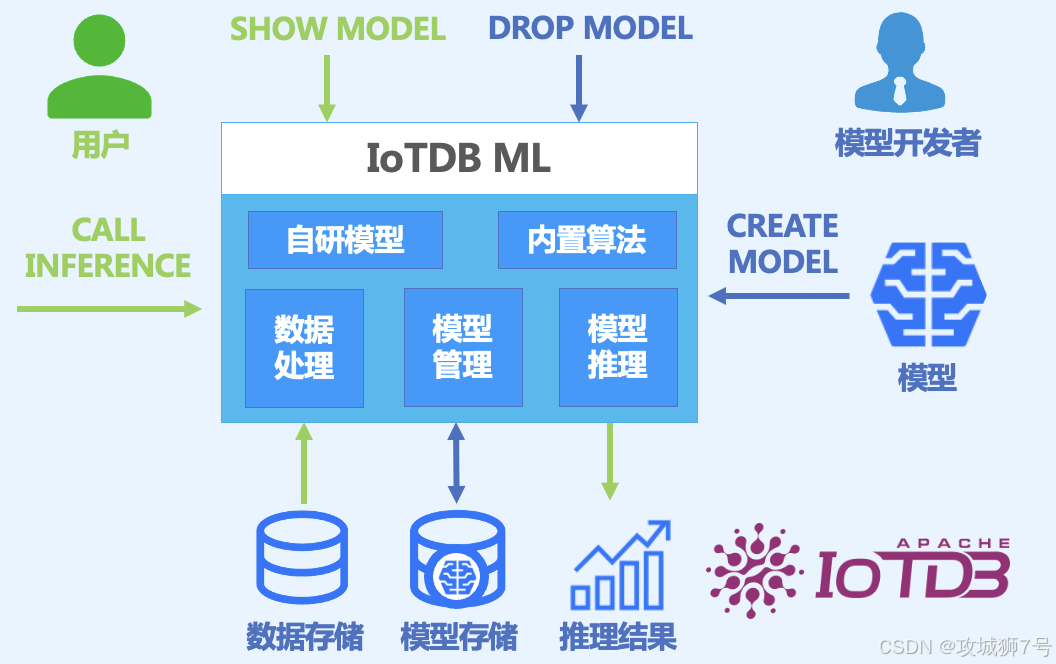
新一代的TSDB开始将AI能力直接构建在数据库内核中。以IoTDB为例,其创新的AINode设计,允许用户直接在数据库内部署和调用AI模型。
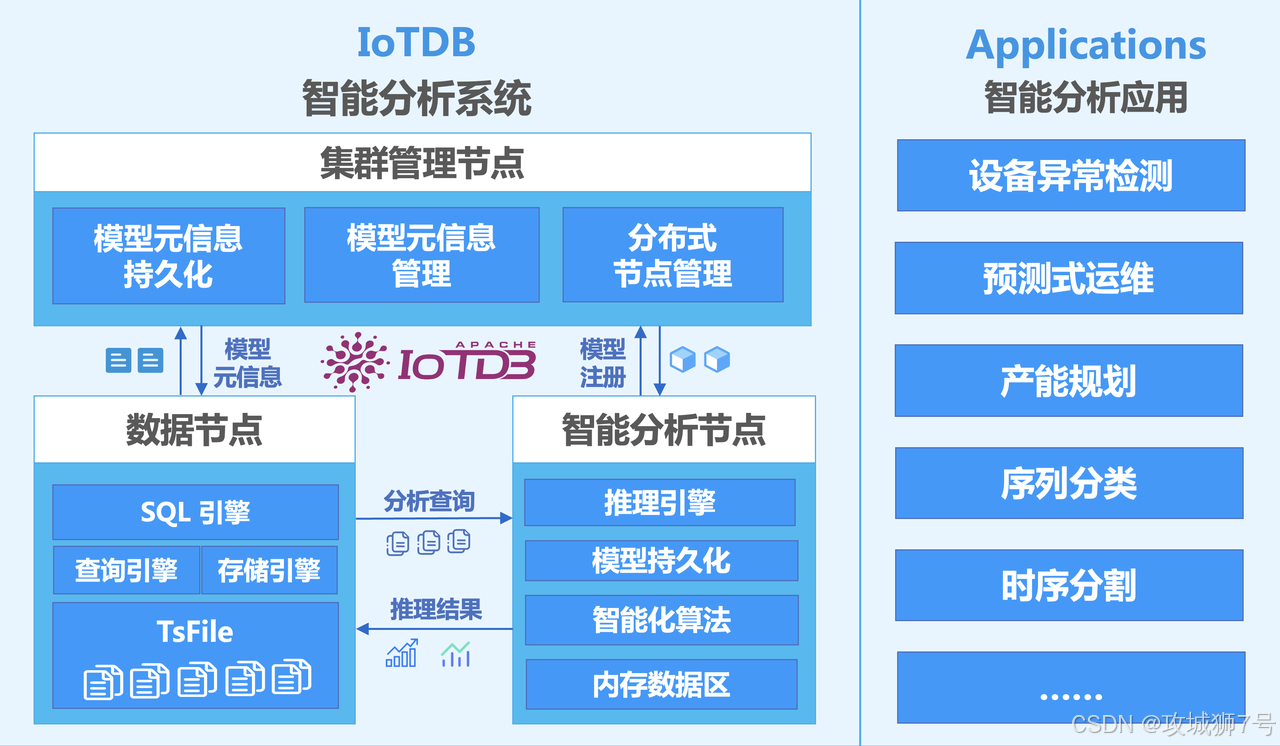
这意味着,过去需要复杂外部流程才能完成的时序预测、异常检测、数据填补等任务,现在只需要一条类似SQL的语句即可完成,例如 `CALL INFERENCE(...)`。
-- 示例:使用内置的timer_xl时序大模型,
-- 基于传感器过去一段时间的温度和湿度数据,预测未来24个时间点的值
CALL INFERENCE(
timer_xl,
"SELECT temperature, humidity FROM root.factory.greenhouse.sensor_1",
predict_length=24
);这种模式的革命性在于:
(1)数据零迁移:AI计算直接在数据存储的地方发生,避免了大规模数据传输的开销和延迟。
(2)极致的易用性:数据工程师无需学习复杂的Python AI库,用熟悉的SQL就能调用强大的时序模型,极大地降低了AI技术的使用门槛。
(3)内置先进算法:IoTDB内置了如Timer系列等业界领先的时序大模型,开箱即用,为数据库赋予了原生的智能。
3.2 与大模型无缝对话:让数据库“听懂人话”
大语言模型(LLM)的出现,为我们提供了一种全新的、基于自然语言的人机交互方式。如何让LLM能够理解并操作私有、实时、海量的时序数据,成为一个核心挑战。
由知名AI公司Anthropic(Claude模型的创造者)推出的 MCP(Model Context Protocol,模型上下文协议),正为此而生。你可以把MCP理解成一个为AI大模型设计的“通用USB接口”或“标准电源适配器”。在MCP出现之前,大模型要连接不同的数据库或API,需要编写各种定制化的“连接器”,费时费力。而MCP提供了一个标准化的协议,任何数据源只要实现了MCP Server,就能立刻被支持MCP的大模型(如Claude)识别和调用。
Apache IoTDB正是全球首批官方集成MCP的时序数据库。
这意味着什么?这意味着,用户可以直接用“人话”来查询和分析IoTDB中的数据。
例如,一个运维工程师不再需要编写复杂的SQL,他可以直接在对话框里问:
> “查询2025年3月19日,所有基站的整流模块电流的平均值是多少?”
大模型会自动理解这个需求,通过MCP调用IoTDB的查询工具,生成正确的SQL语句 `SELECT AVG(rectifier_current) FROM ...`,执行查询,然后将结果用自然语言反馈给工程师。
-- 大模型自动生成的SQL语句可能如下所示:
SELECT AVG(rectifier_current)
FROM root.telecom.station_*.battery_data
WHERE time >= '2025-03-19T00:00:00' AND time < '2025-03-20T00:00:00';
IoTDB对MCP的集成,不仅是技术上的领先,更是理念上的飞跃。它彻底打通了工业时序数据与前沿AI大模型之间的壁垒,让数据分析的门槛从“会写代码”降低到了“会说话”,这对于推动AI在工业领域的普惠化应用,具有里程碑式的意义。
结论:为你的数据心脏,选择一个智慧的未来
选择一个时序数据库,在今天已经成为一项关乎企业数字化和智能化转型成败的战略决策。
一个理想的、面向未来的TSDB,应该像一个“三好学生”:
* 基础扎实:具备经得起考验的高写入、高压缩、快查询和强扩展能力。
* 社交广泛:拥有开放、繁荣的生态系统,能与企业现有技术栈无缝融合。
* 头脑聪明:深度拥抱AI,不仅内置原生智能,更能与最前沿的大模型无缝对话。
Apache IoTDB正是这样一个在三个维度上都表现出色的典范。它不仅拥有源于清华大学的强大技术基因和Apache社区的开放生态,更通过AINode和MCP集成,前瞻性地布局了AI与数据的深度融合,为用户提供了一条从海量数据管理通往智慧决策的平滑路径。
资源链接
* Apache IoTDB官方下载页面:
[https://iotdb.apache.org/zh/Download/]
* 如需企业级的解决方案、商业支持和更强大的功能:
[https://timecho.com]


















 660
660







 到【灌水乐园】发言
到【灌水乐园】发言









