




目录
3.2 Gated DeltaNet:实现高效“速读”的关键
四、核心揭秘三:从“逐字蹦”到“批量吐”——多Token预测

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 阿里开源Qwen3-Next的子系列模型
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言:大模型的“成本-性能”困境
在过去几年里,大语言模型(LLM)的发展似乎遵循着一个简单粗暴的逻辑:参数越大,模型越强。从几十亿到几百亿,再到如今的数千亿甚至万亿参数,这场“军备竞赛”在推动模型能力飞跃的同时,也带来了两个巨大的“拦路虎”:
天文数字般的成本:训练一个顶级大模型,所需的计算资源(GPU hours)和电力消耗,是初创公司甚至许多科技巨头都难以承受的重负。
缓慢的推理速度:模型越大,响应速度通常越慢,尤其是在处理成千上万字的“长文本”时,用户等待的时间会变得难以忍受,同时其背后的计算成本也水涨船高。
性能、成本、速度,这三者构成了一个“不可能的三角”。想要极致的性能,似乎就必须接受高昂的成本和缓慢的速度。整个行业都在寻找一个能打破这个魔咒的方案。
一、阿里的破局之道:Qwen3-Next的“降本增效”魔法

就在此时,阿里通义团队带着Qwen3-Next给出了他们的答案。其开源的Qwen3-Next-80B-A3B模型,交出了一份令人瞠目结舌的成绩单:
(1)成本暴降90%:与上一代Qwen3-32B模型相比,训练成本(消耗的GPU计算资源)仅为其9.3%。
(2)效率飙升10倍:在处理超过32k Token的长上下文时,推理吞吐量是Qwen3-32B的10倍以上。
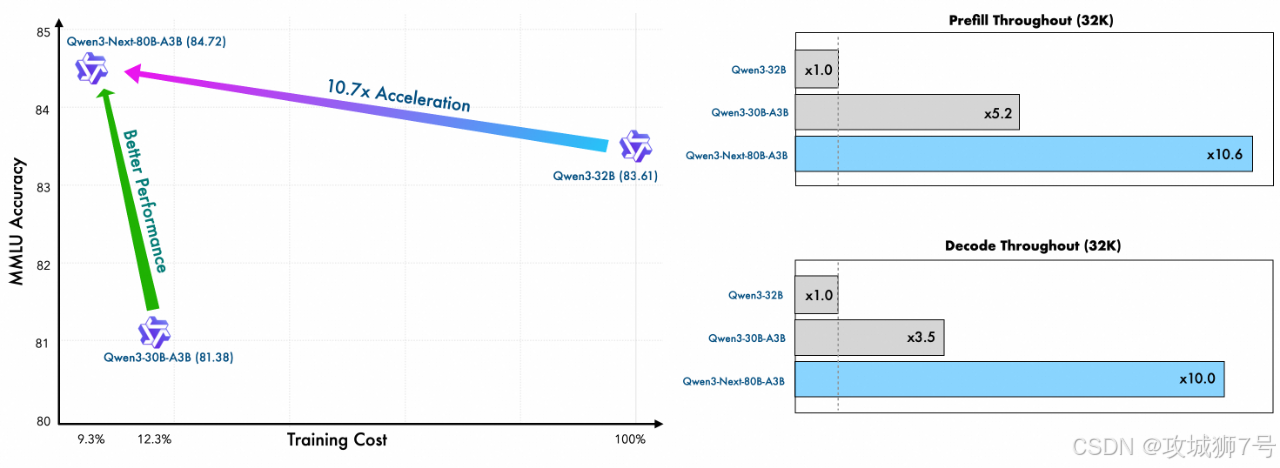
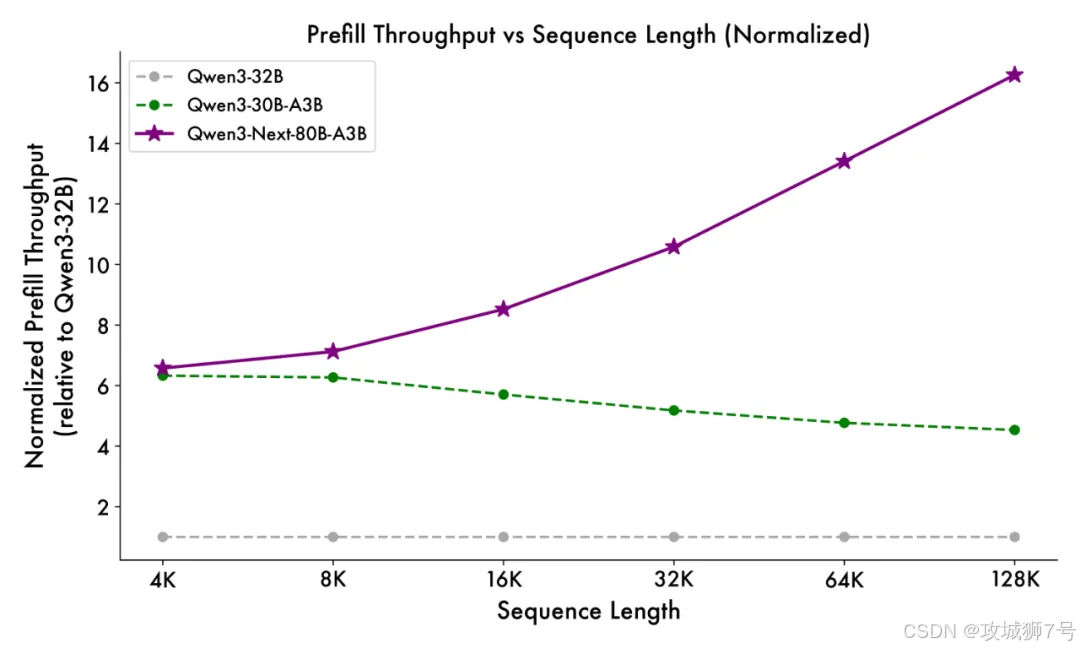
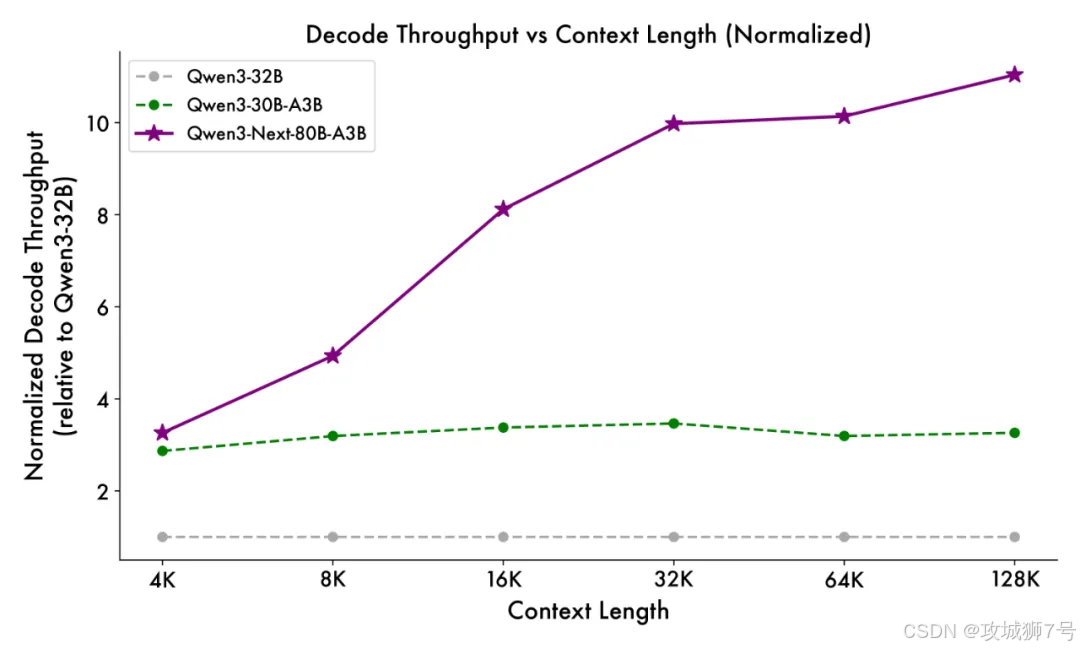
(3)性能越级挑战:以区区30亿的激活参数量,在多个基准测试中,性能却能接近自家2350亿参数的旗舰模型,甚至超越了谷歌的闭源模型Gemini-2.5-Flash-Thinking。
这个成果被许多人称为阿里的“DeepSeek时刻”,意指它像DeepSeek模型一样,通过架构的革新,实现了成本和性能的极致优化。那么,阿里究竟施展了什么“魔法”?答案藏在它的三大核心架构创新之中。
二、核心揭秘一:极致的“专业分工”——高稀疏度MoE架构
2.1 什么是MoE(混合专家)?
想象一下,你要解决一个超级复杂的问题,是找一个什么都懂一点的“通才”,还是找一群各自精通某一领域的“专家”,然后根据问题的具体方面去咨询相应的专家?MoE(Mixture-of-Experts)架构选择的是后者。
传统的“稠密”模型,就像一个“通才”,在回答任何问题时,都需要调动它全部的知识(所有参数)。而MoE模型则像一个“专家委员会”,它内部有许多个“专家网络”(Experts),还有一个“路由器”(Router)。当一个问题进来时,“路由器”会判断这个问题应该交给哪些专家来处理,然后只激活那一小部分专家去计算,其他专家则“待命休息”。
2.2 Qwen3-Next如何将“稀疏”做到极致?
Qwen3-Next将MoE的“专家分工”理念推向了一个新的高度。
庞大的专家团队:它构建了一个拥有512个专家的庞大团队,外加1个所有问题都会咨询的“共享专家”。
极低的激活率:尽管模型总参数高达800亿,但“路由器”每次只会从512个专家中挑选10个最相关的来“开会”。这意味着,在任何一次计算中,实际被激活的参数只有大约30亿,激活率仅为惊人的3.7%。
这就好比一家拥有8000名员工的大公司,但处理任何一个项目,都只需要一个10人精英小队就能高效搞定。这极大地降低了计算量,是实现“推理效率提升10倍”的首要功臣。
三、核心揭秘二:快读与精读的结合——混合注意力机制
如果说MoE解决了“谁来干活”的问题,那么混合注意力机制则解决了“活该怎么干”的效率问题,尤其是在阅读长文章时。
3.1 当模型拥有“两种阅读模式”
人类阅读一篇长文时,通常会先快速浏览(速读)抓住大意,遇到重点段落再放慢速度仔细研读(精读)。Qwen3-Next的混合注意力机制(Hybrid Attention)就模仿了这种行为。
标准注意力(精读):这是传统模型都在用的机制,它会仔细计算文章中每一个词与其他所有词之间的关系。效果好,但计算量巨大,是处理长文本时的性能瓶颈。
线性注意力(速读):这是一种更高效的机制,计算成本随文本长度线性增长,而非平方级增长。速度飞快,但可能会忽略一些细节。
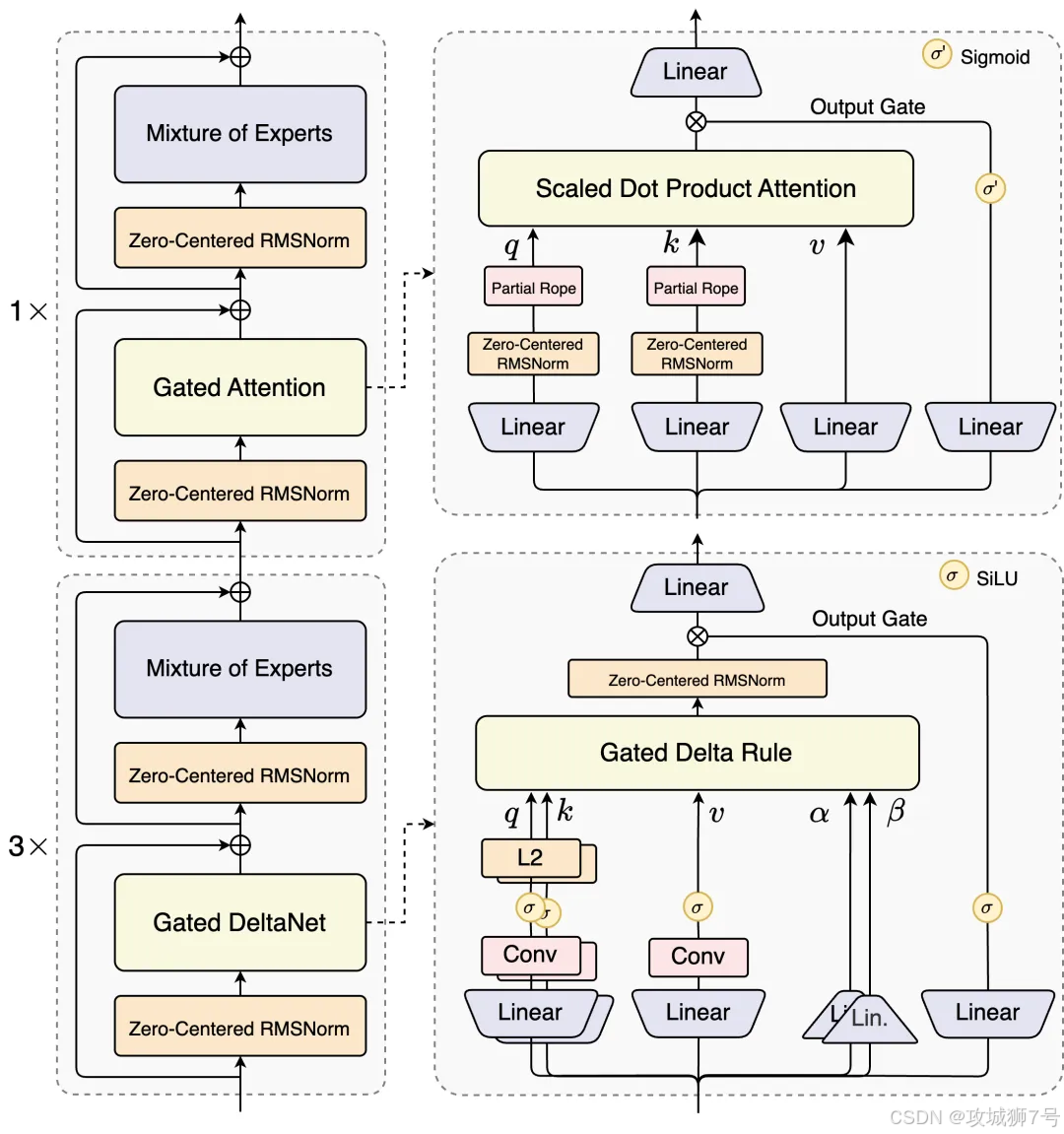
Qwen3-Next创新地将两者结合,以3:1的比例进行混合,即75%的模型层使用高效的线性注意力(Gated DeltaNet)进行“速读”,另外25%的层则保留标准注意力进行“精读”和关键信息召回。
3.2 Gated DeltaNet:实现高效“速读”的关键
在多种线性注意力方案中,阿里团队通过实验发现,一种名为Gated DeltaNet的技术在上下文学习能力上表现优于其他方案(如滑动窗口注意力和Mamba2)。正是这个选择,让Qwen3-Next在处理26万Token(约40万汉字)甚至百万Token的超长上下文时,依然能保持极高的效率和准确性。
四、核心揭秘三:从“逐字蹦”到“批量吐”——多Token预测
传统的语言模型在生成文本时,像是一个说话有点“结巴”的人,预测完一个词,才能基于这个词去预测下一个词。这个过程被称为“自回归”,效率较低。
Qwen3-Next引入了多Token预测(Multi-Token Prediction, MTP)机制。这让它具备了“预判”能力,可以一次性预测出接下来好几个词。这极大地提升了文本生成的速度,尤其是在进行一种名为“投机采样”(Speculative Decoding)的推理加速技术时,能获得更高的效率提升。
简单来说,就是模型从过去的“逐字蹦”,进化到了“批量吐”,输出自然更加流畅快速。
五、性能成绩单:它真的能叫板巨人吗?
先进的架构最终要靠实力说话。阿里这次开源了两个版本的模型,它们的表现足以证明新架构的成功。
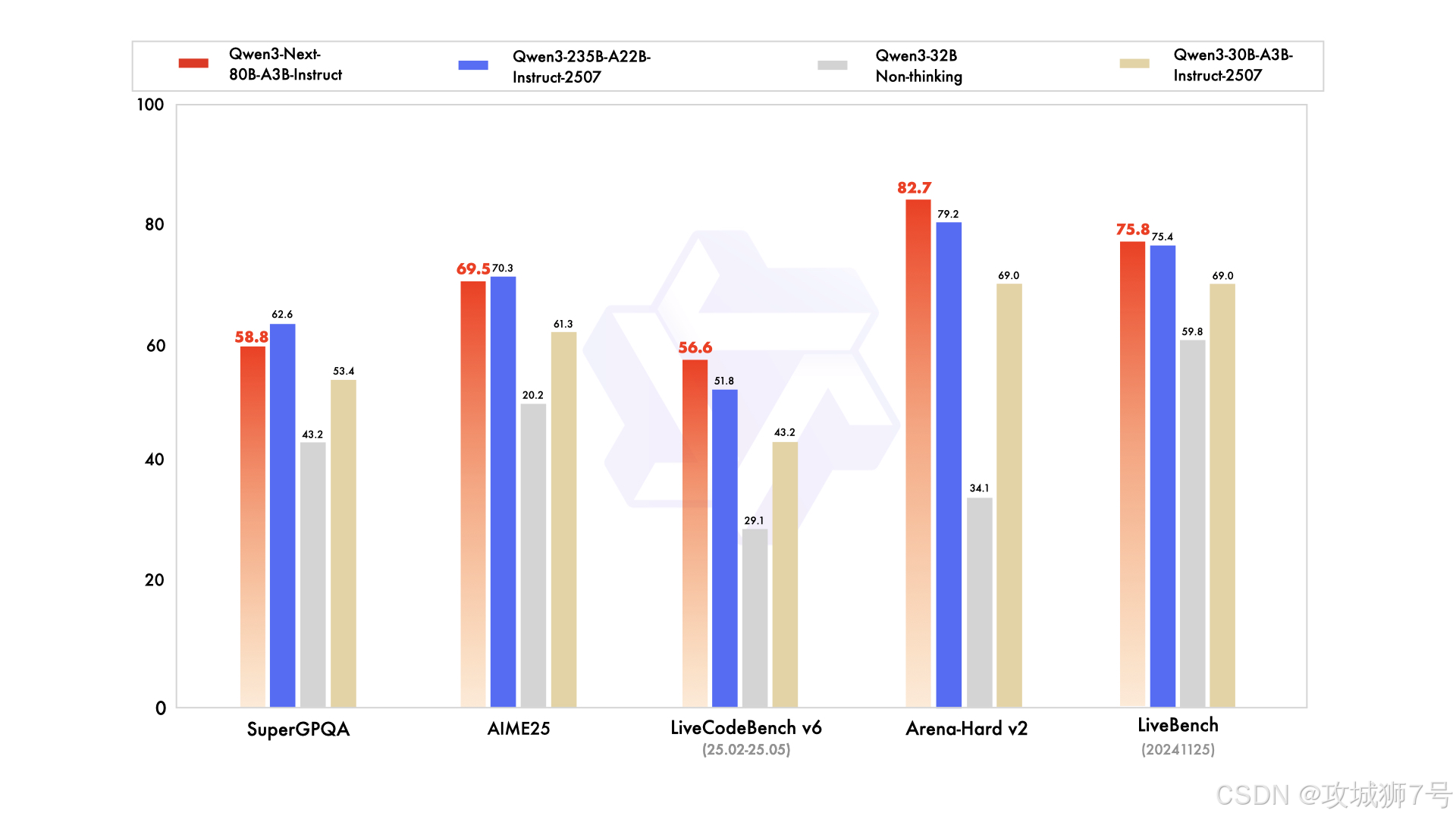
(1)指令模型:直逼自家235B旗舰
`Qwen3-Next-80B-A3B-Instruct` 是一个通用对话模型。在编程、复杂问答和长对话等多个评测中,它的表现优于参数规模更大的自家模型,甚至取得了与2350亿参数的旗舰模型`Qwen3-235B`相近的结果。这充分证明了新架构“以小博大”的能力。
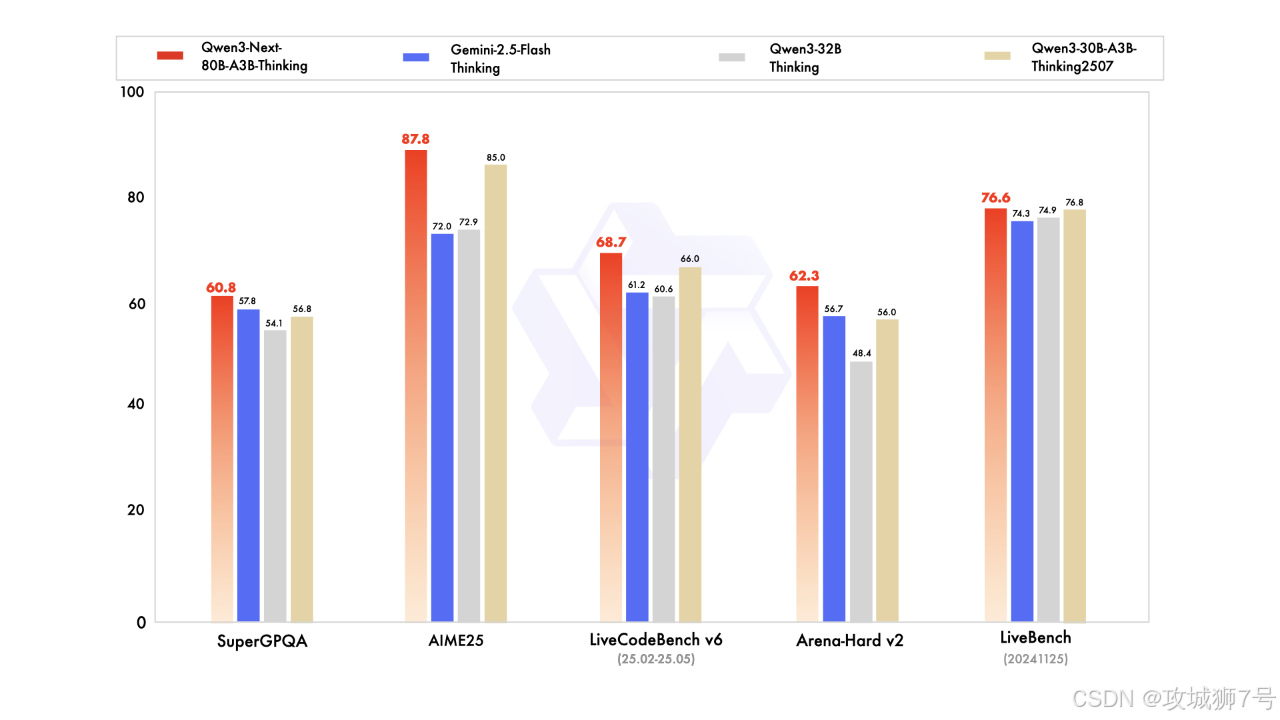
(2)思维模型:超越谷歌Gemini-2.5-Flash
`Qwen3-Next-80B-A3B-Thinking` 则是一个专注于复杂推理的模型。在多个基准测试中,它的性能全面超过了谷歌强大的闭源模型`Gemini-2.5-Flash-Thinking`,并在一些关键指标上接近`Qwen3-235B`的思维模型。这标志着开源模型在推理能力上,正迎头赶上甚至超越一些顶级的闭源模型。
六、这对开发者和我们意味着什么?
Qwen3-Next的发布,不仅仅是一次技术炫技,它对整个AI生态都意义重大。
对于开发者和企业来说,这意味着可以用更低的成本,获得更强的性能和更快的速度。过去因为算力不足而无法实现的应用,比如实时长文档分析、高并发的AI客服、低成本的个人AI助手等,都变得触手可及。
对于普通用户来说,这意味着我们未来接触到的AI应用,响应会更快,能处理更复杂的任务(比如一口气读完一整本小说并进行总结),而且服务价格可能会更便宜。
结语:阿里的“DeepSeek时刻”,更是AI的普惠时刻
Qwen3-Next的成功,本质上是在大模型设计的十字路口上,找到了一条通往“高效率”和“低成本”的光明大道。它通过极致稀疏的MoE、创新的混合注意力机制和多Token预测技术,完美地平衡了性能、成本与速度这“不可能的三角”。
这不仅是阿里巴巴展示其技术肌肉的“DeepSeek时刻”,更可能成为推动AI技术大规模落地和普及的“普惠时刻”。当顶尖的AI能力不再是少数巨头的专利,当高昂的算力成本不再是创新的壁垒,一个更加开放、繁荣的AI时代,或许正加速到来。
在线体验:https://chat.qwen.ai/
开源地址:https://huggingface.co/collections/Qwen/qwen3-next-68c25fd6838e585db8eeea9d
https://modelscope.cn/collections/Qwen3-Next-c314f23bd0264a
阿里API:https://www.alibabacloud.com/help/en/model-studio/models#c5414da58bjgj
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!




















 969
969




 到【灌水乐园】发言
到【灌水乐园】发言









