



 文章详细描述了RAG模型的检索流程,包括文档加载、拆分、向量化和检索,以及在拆分与检索中遇到的问题。提出改进策略,如使用预检索和后检索,以及根据位置标识提取上下文信息以提升回答质量。
文章详细描述了RAG模型的检索流程,包括文档加载、拆分、向量化和检索,以及在拆分与检索中遇到的问题。提出改进策略,如使用预检索和后检索,以及根据位置标识提取上下文信息以提升回答质量。
RAG(Retrieval-Augmented Generation)模型的检索流程主要包括以下步骤:
- 加载文档:此步骤涉及将不同格式的文件转化为可处理的文档形式,例如将PDF文件转换为文本,或将表格数据转化为键值对。
- 拆分文档:在此步骤中,文档被分割成更小的单元,以便于存储和检索。例如,将“我是kxc。我喜欢唱跳、rap和篮球。”拆分为“我是kxc。”和“我喜欢唱跳、rap和篮球。”两个数据块。
- 嵌入表示:文档被转换为向量形式,这通常通过BERT或TF-IDF等模型完成。
- 存储向量:向量化后的数据块被存入向量数据库中。
- 检索:根据输入的问题和文档向量,计算它们之间的相似度,然后根据相似度排序,选择最相关的文档作为检索结果。余弦相似度或点积是常用的相似度度量方法。
- 生成回答:最后,使用检索到的文档作为生成模型的输入,根据问题生成回答。GPT-3或T5等模型常用于这一步骤。
虽然基础RAG的检索流程相对简单,但在拆分(split)和检索(retrive)步骤中存在一些问题,这些问题可能会影响RAG的检索效果,导致生成的回答不准确或不完整。
- 如果拆分的数据块太大,那么在检索时,同一块中可能包含大量与问题不相关的内容,从而影响检索的准确性。例如,如果将维基百科的一篇文章作为一个整体进行检索,那么由于文章可能涉及多个主题和细节,与问题的相关性可能会降低。在这种情况下,生成模型可能会提取出一些无关或错误的信息,从而降低回答的质量。
- 另一方面,如果拆分的数据块太小,虽然可以提高检索的匹配度,但在生成回答时,由于缺乏足够的上下文信息,可能导致回答不准确。例如,如果将维基百科的一篇文章拆分为多个句子进行检索,那么每个句子可能只包含部分信息,与问题的相关性较高。在这种情况下,生成模型可能会提取出一些有用的信息,但可能会忽略重要的上下文信息,从而影响回答的完整性。
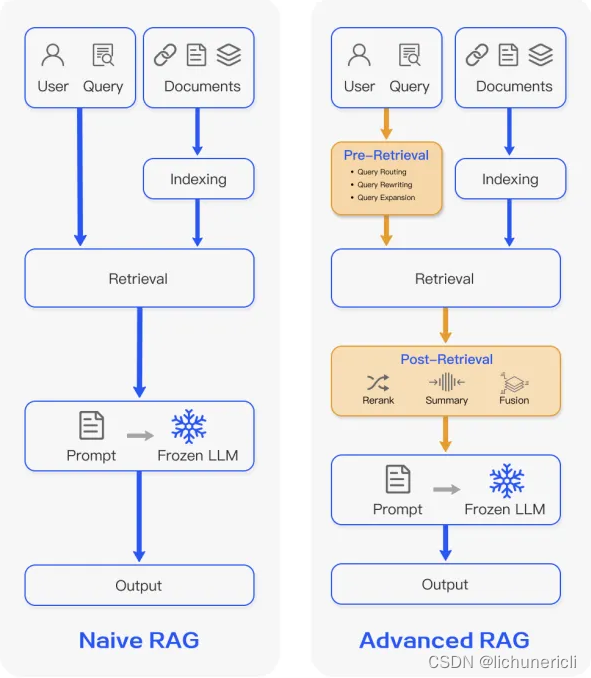
在比较两种RAG(Retrieval-Aided Generation)模型的流程时,我们可以观察到它们在生成任务中的不同处理方式。左侧展示的是基本的RAG模型,而右侧则展示了更为先进的RAG模型。这两个模型都包含检索和生成两个核心阶段。
在基本RAG模型中,用户的查询直接与文档进行索引,随后通过检索过程得到结果,这些结果作为提示传递给冻结的LLM(Language Learning Model,语言学习模型),最终由LLM生成输出。
相比之下,先进RAG模型引入了预检索和后检索阶段。在预检索阶段,对用户查询进行路由、重写和扩展等操作;在检索阶段,获取结果;在后检索阶段,对这些结果进行重新排序、总结和融合,然后传递给冻结的LLM以生成输出。
为了解决在拆分和检索步骤中遇到的问题,通常采取的策略是在拆分时尽可能将文本划分为最小的语义单元,如句子或段落,并为每个单元分配一个唯一编号,作为其在文本中的位置标识。
在检索时,基于问题和文档向量之间的相似度,选择最相关的文档作为结果,并记录其编号。
在生成回答时,利用这些编号从文本中提取相关单元的上下文信息,如前后相邻的单元,然后将这些信息拼接成一个完整的文档,作为生成模型的输入,以便根据问题生成回答。这种方法不仅提高了检索的精确度,还保留了上下文的完整性,从而提升了生成回答的质量和多样性。
总结
当检索出相关文档后,系统会根据这些文档的位置标识符,在原始文本中提取它们的上下文信息,比如前后几个单位的内容。然后,将这些上下文信息与检索结果合并,形成一个新的文档,作为生成模型的输入。

















 525
525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









