




 这篇博客通过简化示例详细解析了Transformer的训练过程,包括数据集定义、词表大小计算、编码、词向量和位置向量计算、多头注意力机制、前馈神经网络等关键步骤。文中使用了一个包含三句话的小数据集来演示这些概念。
这篇博客通过简化示例详细解析了Transformer的训练过程,包括数据集定义、词表大小计算、编码、词向量和位置向量计算、多头注意力机制、前馈神经网络等关键步骤。文中使用了一个包含三句话的小数据集来演示这些概念。
1. 定义数据集
创建 ChatGPT 所使用的数据集大小为 570 GB。在本文中,为了便于演示Transformer的原理和进行可视化的数值计算,我们将使用一个非常小的数据集。

本文使用的数据集只包含三句话,来自于一个电视节目的对话。这个数据集已经经过清理来保证数据的质量以及避免泄漏敏感的信息,你可以想象在创建 ChatGPT 等实际项目中,清理一个超过 570 GB 的数据集需要付出多大的代价。
2. 计算词表大小
词表大小指的是数据集中去重后的单词的数量。可以使用以下公式计算,其中 N 是数据集中单词总数。
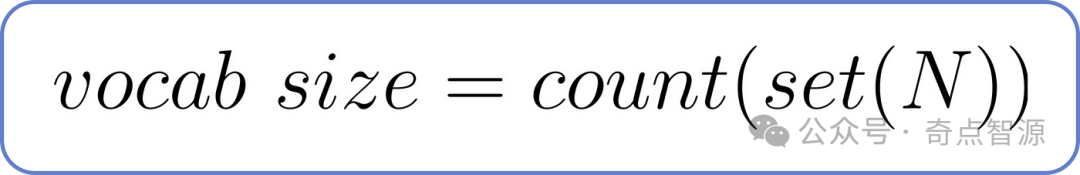
计算vocab size,其中N代表数据集中单词总数
首先,我们需要将数据集中的句子拆分成独立的单词。

然后通过集合操作 (set) 来去除重复项,这样就可以确定词表大小。

经过计算,词表大小为 23,因为数据集中存在 23 个不重复的单词。
3. 编码 (Encoding)
接下來,我们需要为每个不重复的单词分配一个唯一的编号。
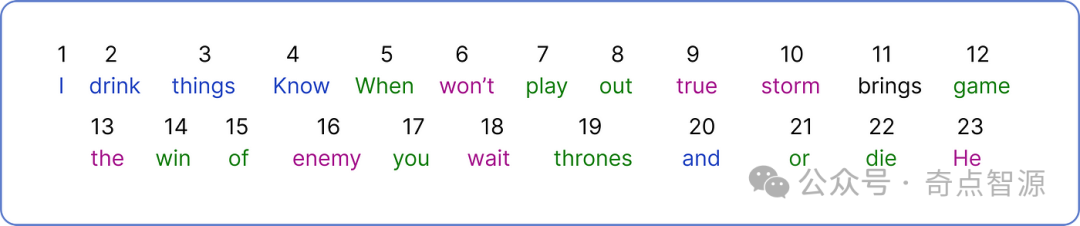
我们将每个单词作为一个单独的 token 并分配编号,而ChatGPT将单词的一部分作为一个token:1 Token = 0.75 Word。
将整个数据集编码之后,就可以开始使用 Transformer 架构进行处理。
4. 计算词向量
让我们从语料库中选择一个句子,将其作为输入在 Transformer 架构中进行处理。
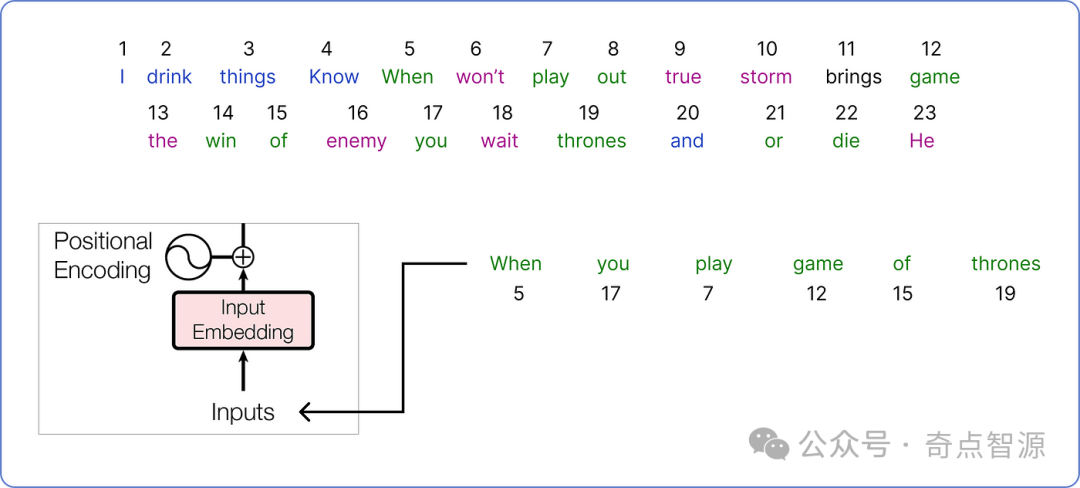
确定输入后,接下来需要将输入映射为词向量 (Embedding)。原始论文中对每个输入词使用的是512维的词向量。
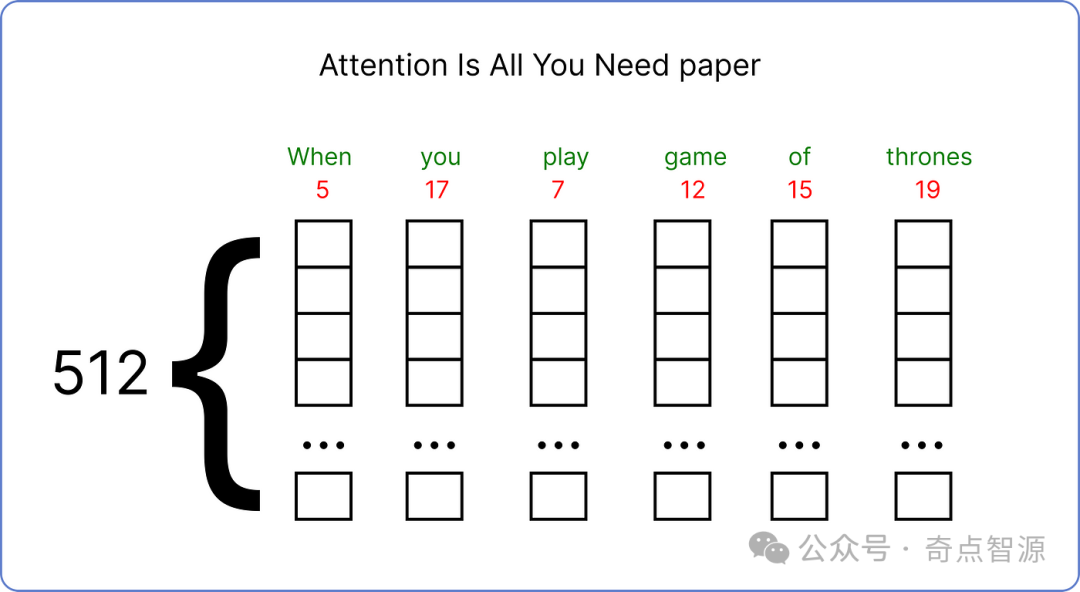
然而,为了方便演示和可视化计算过程,我们将使用较小的词向量维度,即 6 维。
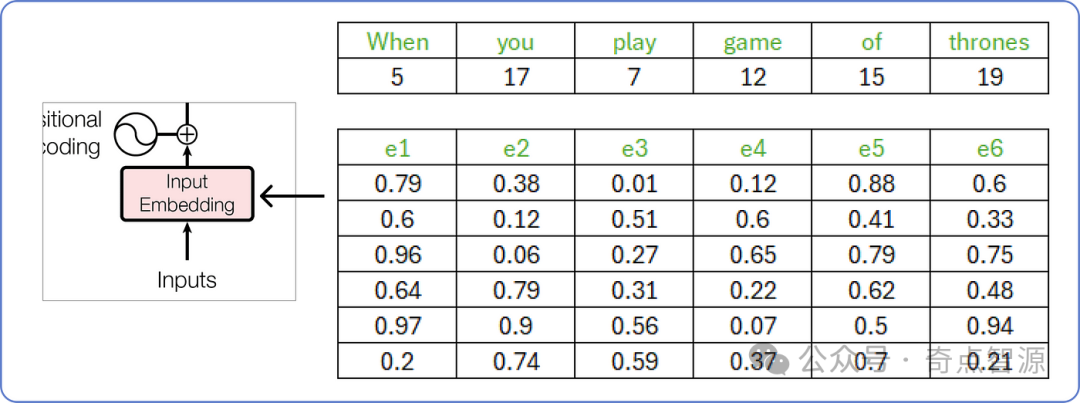
这些词向量的值介于 0 和 1 之间,并且在开始时是随机填充的。随着 Transformer 的训练,模型开始理解语料库中句子的含义,这些词向量的值会在之后进行更新。
5. 计算位置向量
现在,我们要为输入的单词生成位置向量 (Positional Embedding)。根据每个单词向量中第 i 个值的位置,位置向量中值的计算有两种公式。

在这个例子中,输入句子是 “when you play the game o
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2159
2159



 到【灌水乐园】发言
到【灌水乐园】发言








