



十七、基于YOLOv8的目标检测跟踪系统 1.提供测试图片和测试视频。 2.含模型训练权重。 3.pyqt5设计的界面,带登录界面,注册界面和运行界面。 4.提供详细的环境部署说明和算法原理介绍。
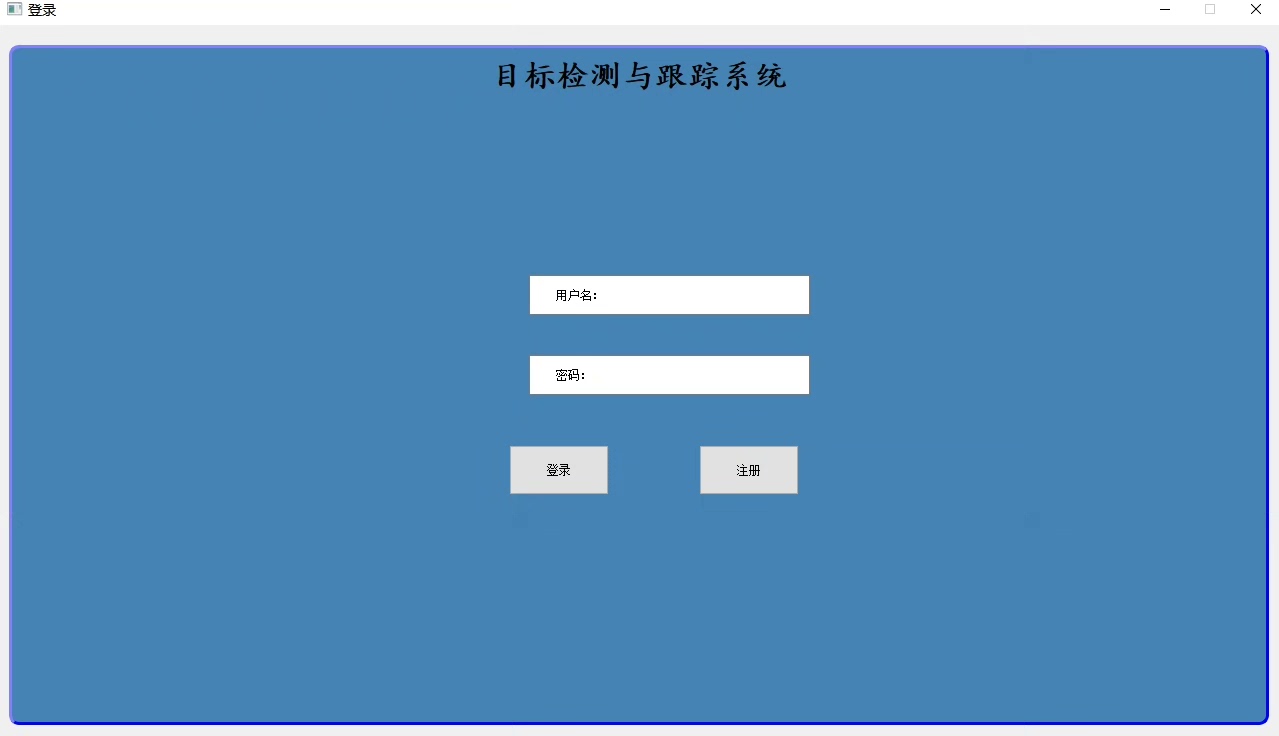
最近在搞一个挺有意思的项目——基于YOLOv8的目标检测跟踪系统。这玩意儿不仅整合了最新的目标检测算法,还带完整的用户系统,从环境搭建到模型训练都踩过不少坑,这就把实战经验给大家唠唠。
咱们先来说说环境搭建。项目需要Python3.8+和PyTorch1.10+,建议直接用Anaconda开个新环境:
conda create -n yolo_track python=3.8
conda activate yolo_track
pip install ultralytics PyQt5 opencv-python scipy注意要装带CUDA的PyTorch,官网命令直接复制就行。有个坑是PyQt5和opencv的版本冲突,建议先装PyQt5再装opencv-python。

项目核心是YOLOv8的检测+BoT-SORT跟踪算法。这里有个骚操作,直接用ultralytics库的YOLO类加载训练好的权重:
from ultralytics import YOLO
class Detector:
def __init__(self):
self.model = YOLO('best.pt') # 换成自己的权重路径
self.tracker = BOTSORT() # 自定义跟踪器
def process_frame(self, frame):
results = self.model.predict(frame, verbose=False)
detections = results[0].boxes.data.cpu().numpy()
tracked_objects = self.tracker.update(detections)
return self.draw_boxes(frame, tracked_objects)这里用到的BoT-SORT跟踪算法其实是传统卡尔曼滤波和深度学习特征的混合体。核心思想是先用卡尔曼预测位置,再用ReID特征做关联。重点在于特征提取模块的设计,我们直接用了YOLOv8自带的特征图:
def extract_features(self, bbox, frame):
x1, y1, x2, y2 = map(int, bbox)
crop = frame[y1:y2, x1:x2]
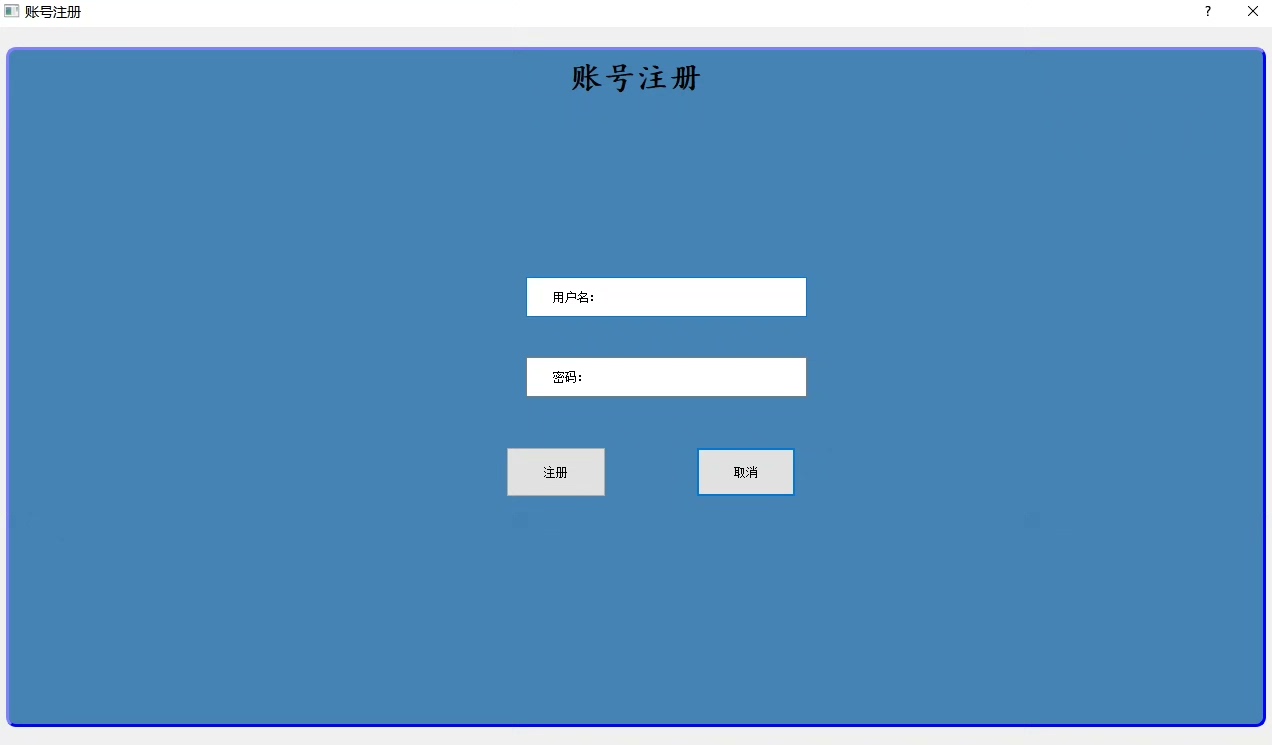
return self.model(crop).features # 直接调用模型内部特征界面部分用PyQt5整了个三件套:登录->注册->主界面。这里有个小技巧,用QSS美化按钮比直接写样式方便得多:
self.login_btn.setStyleSheet("""
QPushButton {
background: #4CAF50;
border-radius: 15px;
padding: 10px;
color: white;
}
QPushButton:hover {
background: #45a049;
}
""")视频处理必须开多线程,否则界面会卡成PPT。这里用QThread配合信号槽实现:
class VideoThread(QThread):
frame_signal = pyqtSignal(np.ndarray)
def run(self):
cap = cv2.VideoCapture(video_path)
while True:
ret, frame = cap.read()
if ret:
processed = detector.process_frame(frame)
self.frame_signal.emit(processed)模型训练建议准备5000+张带标注的数据集,启动命令很简单:
yolo task=detect mode=train data=your_data.yaml model=yolov8n.pt epochs=100 imgsz=640重点在于数据增强配置,在data.yaml里加上:
augment:
- hsv_h: 0.015
- hsv_s: 0.7
- hsv_v: 0.4
- translate: 0.1
- scale: 0.5这组参数亲测能提升小目标检测效果。训练完别急着用,记得用验证模式看看混淆矩阵:
results = model.val(data='coco.yaml', split='test')
print(results.confusion_matrix)项目部署时遇到的最大坑是CUDA内存管理。有个邪门技巧是在推理前加这个:
torch.cuda.empty_cache()
with torch.cuda.amp.autocast():能有效降低显存占用。实测1080Ti上跑1080p视频能到25FPS,还算流畅。
最后说下怎么扩展功能。比如要在跟踪时加轨迹绘制,可以改draw_boxes方法:
def draw_trails(self, frame, obj_id):
for prev_pos in self.tracker.trails[obj_id]:
cv2.circle(frame, prev_pos, 2, (0,255,0), -1)整个项目最爽的部分是把PyQt5和YOLO无缝对接,看着自己设计的界面跑起目标跟踪,确实有种造轮子的快乐。代码已打包好环境配置文档和示例权重,需要的老铁评论区自取。下期可能会做跨镜头跟踪,有兴趣的可以关注下更新。


















 1511
1511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









