






服务器有8张RTX3090显卡,部署DeepSeek-VL2最大模型时,总提示cuda out of memory,deepseek-vl2为MOE模型,4.5B是激活参数,实际参数在30B左右,8张卡跑它妥妥够啊,最后发现:
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python web_demo.py --model_name "deepseek-ai/deepseek-vl2" --ip 0.0.0.0 --root_path "/deepseek-vl2" --port 37914虽然指定了8张卡,但实际只用了一张卡,Gradio Demo程序并不支持多卡推理。修改文件:
vim deepseek_vl2/serve/inference.pyimport os
os.environ["TOKENIZERS_PARALLELISM"] = "false"
def split_model(model_name):
device_map = {}
model_splits = {
# 'deepseek-ai/deepseek-vl2-tiny': [13, 14], # 2 GPU
'deepseek-ai/deepseek-vl2-small': [13, 14], # 2 GPU
'deepseek-ai/deepseek-vl2': [4, 4, 4, 4, 4, 4, 3, 3], # 8 GPU
}
num_layers_per_gpu = model_splits[model_name]
num_layers = sum(num_layers_per_gpu)
layer_cnt = 0
for i, num_layer in enumerate(num_layers_per_gpu):
for j in range(num_layer):
device_map[f'language.model.layers.{layer_cnt}'] = i
layer_cnt += 1
device_map['vision'] = 0
device_map['projector'] = 0
device_map['image_newline'] = 0
device_map['view_seperator'] = 0
device_map['language.model.embed_tokens'] = 0
device_map['language.model.norm'] = 0
device_map['language.lm_head'] = 0
device_map[f'language.model.layers.{num_layers - 1}'] = 0
return device_map
def load_model(model_path, dtype=torch.bfloat16):
vl_chat_processor = DeepseekVLV2Processor.from_pretrained(model_path)
tokenizer = vl_chat_processor.tokenizer
# csdn2k
device_map = split_model(model_path)
vl_gpt: DeepseekVLV2ForCausalLM = AutoModelForCausalLM.from_pretrained(
model_path,
trust_remote_code=True,
torch_dtype=dtype,
device_map=device_map
).eval()
return tokenizer, vl_gpt, vl_chat_processor
把原来的load_model注释掉。
关键位置就是:'deepseek-ai/deepseek-vl2': [4, 4, 4, 4, 4, 4, 3, 3],为不同的卡分配不同层。
然后重新运行成功。
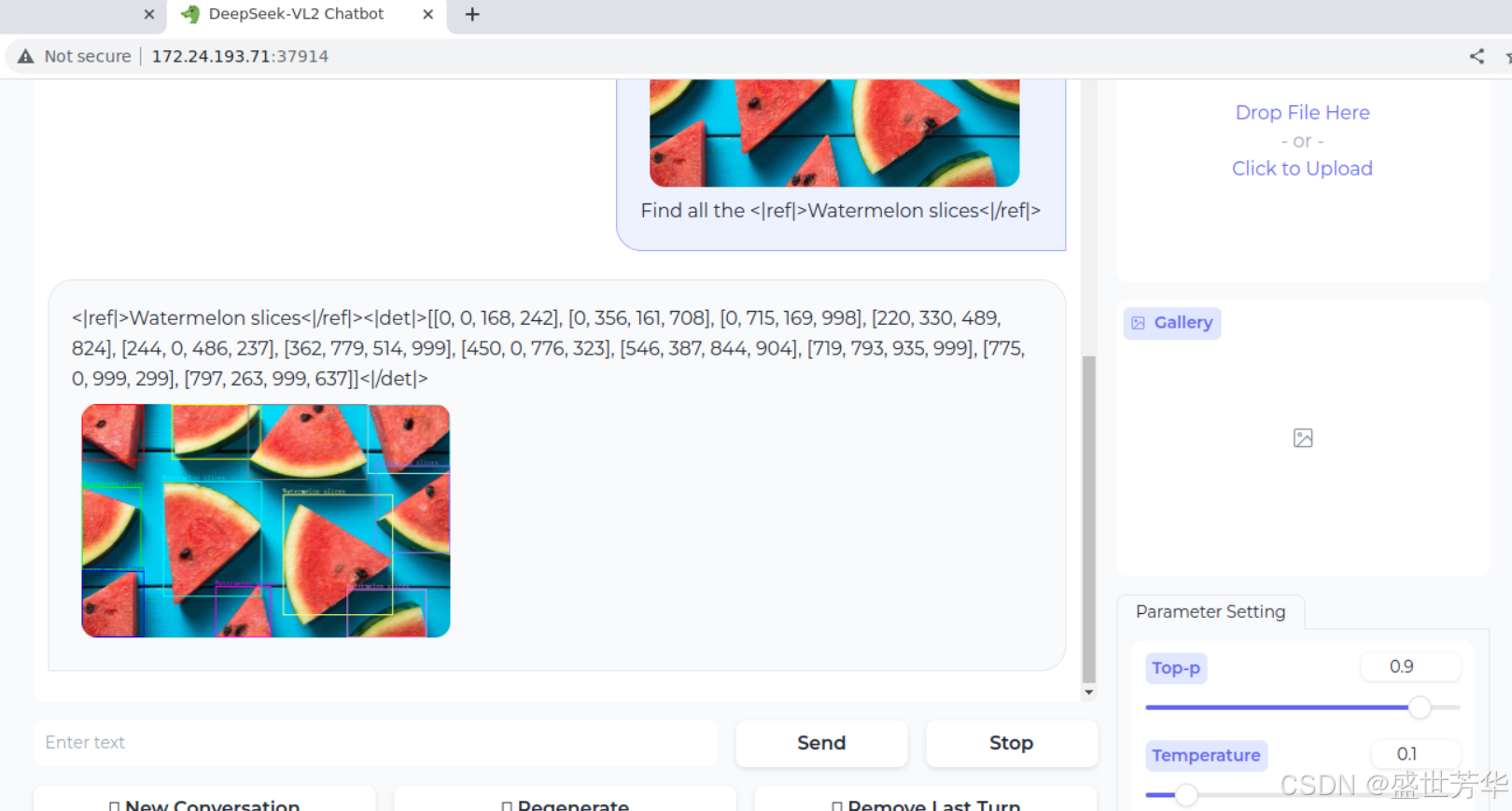
参考:
Running DeepSeek-VL2 with multiple cards · Issue #8 · deepseek-ai/DeepSeek-VL2


















 2899
2899

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









