







MMTracking是一款基于PyTorch的视频目标感知开源工具箱,是OpenMMLab项目的一部分,封装了MOT、SOT、VIS等各种算法,对新手来说非常友好,最近想要使用Mmtracking自定义数据集进行多目标跟踪,在标注数据集以及训练过程中遇到各种问题,特此记录一下,我会从数据集标注到训练、预测完整的进行介绍。
一、数据集介绍
官方对自定义数据集的介绍大家可参考以下网址:
看完后我觉着参考意义不大,重点就是“将数据离线转换成 CocoVID 格式”,不错的是官方提供了一个MOT17_tiny.zip数据示例,参照这个示例准备数据集,就能保证完全没问题,数据集下载地址:https://download.openmmlab.com/mmtracking/data/MOT17_tiny.zip
关于MOT-17数据集的格式
解压MOT17_tiny.zip文件会看到test和train目录,test不用管,在train目录下有MOT17-02-FRCNN、MOT17-04-FRCNN两个文件夹,实际上对应了两个视频文件,在MOT17-02-FRCNN目录下有det、gt、img1三个文件夹,和一个叫做seqinfo.ini的文件。
det目录存储的其实就是目标识别的标注信息,文件夹下有一个det.txt文件,每行一个标注,代表一个检测的物体

上面每行的含义是:
<frame>, <id>, <bb_left>, <bb_top>, <bb_width>, <bb_height>, <conf>, <x>, <y>, <z> 第一个代表第几帧
第二个代表轨迹编号,咱只需要把他设置成-1就行
bb开头的4个数代表物体框的左上角坐标及长宽
conf代表置信度,咱直接设置成1就行了,手动标注的,肯定置信度为1
最后3个是MOT3D用到的内容,2D检测可以直接忽略不写
总结一下,det.txt文件中保存每张图片目标标注信息,咱们自定义的数据集,在det.txt文件中要写入的内容就是:
图片是第几帧,-1,物体框的左上角x值,物体框的左上角y值,物体框的宽度,物体框的高度,1一行7个数据,缺一不可。
在MMTracking中会使用这个文件进行目标检测模型的训练,毕竟多目标跟踪并不是一个端到端的过程在,而是目标检测算法+ReID行人重识别算法配合的过程。
在gt目录下存储的是标注的用于训练行人重识别模型的数据,gt目录下只有一个gt.txt文件。
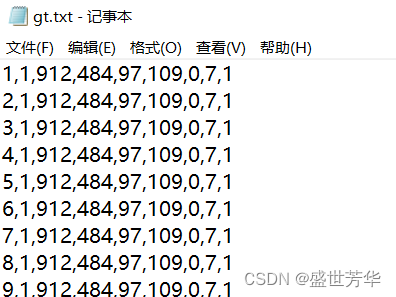
第一个代表第几帧
第二个值为目标运动轨迹的ID号
第3个到第六个数代表物体框的左上角坐标及长宽(和det文件一样)
第7个值为目标轨迹是否进入考虑范围内的标志,0表示忽略,1表示active(0相当于无效数据)
第八个值为该轨迹对应的目标种类
第九个值为box的visibility ratio,表示目标运动时被其他目标box包含/覆盖或者目标之间box边缘裁剪情况。
一行9个数据,缺一不可。
如果你认真看了,就知道,gt.txt中其实包含了det.txt中的所有数据。
img1文件夹保存的是图片帧序列
seqinfo.ini文件中存储的是视频文件信息
[Sequence]
name=MOT17-02-FRCNN
imDir=img1
frameRate=30
seqLength=600
imWidth=1920
imHeight=1080
imExt=.jpgname是文件夹名称
imDir=img1是保存图片的路径(建议别改)
frameRate是视频文件帧率
seqLength是img1文件夹下图片的数量
imWidth是图片宽度
imHeight是图片高度
imExt是图片文件后缀
二、下载数据集标注软件
这里使用DarkLabel作为标注软件,下载地址:Release darklabel2.4 · darkpgmr/DarkLabel · GitHub
我使用的是darklabel2.4版本,为了保证能复现成功,建议大家也使用2.4版本。
三、配置标注内容
我主要为了实现车辆的识别和目标跟踪,所以我只定义了一个“car”分类。
解压darklabel2.4,不着急打开软件,先用记事本打开darklabel.yml文件,然后在文件的末尾添加代码:
myMOT_classes: ["car"] # 你要检测的东西有多少个类别,就写多少个
format9:
name: "myMOT" #工程名
fixed_filetype: 1 #GUI界面不能修改配置
data_fmt: [fn, id, x1, y1, w, h, c=1, classid, c=1] #想要保存的数据格式,第1个值:第几帧;第2个值:目标运动轨迹的ID号;第3~6个值:代表物体框的左上角坐标及长宽;第7个值:目标轨迹是否进入考虑范围内的标志,0表示忽略,1表示active;第8个值:该轨迹对应的类别种类;第9个值:box的visibility ratio,表示目标运动时被其他目标box包含/覆盖或者目标之间box边缘裁剪情况
gt_file_ext: "txt" #gt文件的保存类型
delimiter: "," #分隔符
gt_merged: 1 #0表示每张图片一个gt文件,1表示所有图片保存在一个文件
classes_set: "myMOT_classes" #类别标签名称解释一下代码的含义:
1、myMOT_classes: ["car"]定义分类的名称,如果你有多个分类,就加在这里。
2、format9是第九个标注格式,官方已经自带了8个示例,咱自定义第9个。
3、name: "myMOT" 自定义标注工程的名字
4、fixed_filetype:1 保持默认就行,应该是为了禁止在GUI中修改配置内容
5、data_fmt:[fn, id, x1, y1, w, h, c=1, classid, c=1] 标注完成后,数据保存的格式,第1个值:第几帧;第2个值:目标运动轨迹的ID号;第3~6个值:代表物体框的左上角坐标及长宽;第7个值:目标轨迹是否进入考虑范围内的标志,0表示忽略,1表示active;第8个值:该轨迹对应的类别种类;第9个值:box的visibility ratio,表示目标运动时被其他目标box包含/覆盖或者目标之间box边缘裁剪情况。实际上这里配置的就是gt.txt文件中每一行数据的格式。
6、gt_file_ext: "txt" gt文件保存后的后缀
7、delimiter: "," 使用的分隔符,保持默认
8、gt_merged: 1 0表示每张图片一个gt文件,1表示所有图片保存在一个文件,MOT-17数据集是把所有标注信息保存在一个文件中的,所以这里使用1
9、classes_set: "myMOT_classes" 定义类别标签名称,这个变量在代码第一行我就定义了myMOT_classes: ["car"]
四、开始标注数据
双击“DarkLabel.exe”,在这里可以看到我们自己配置的标注规则,选中它
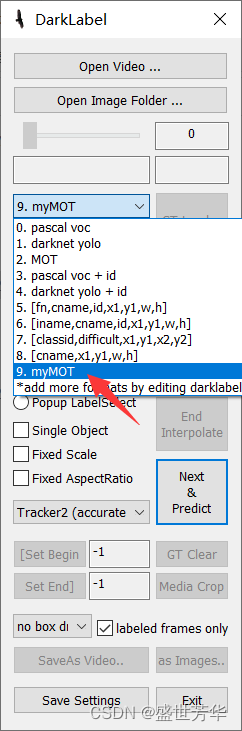
其它按如下的设置
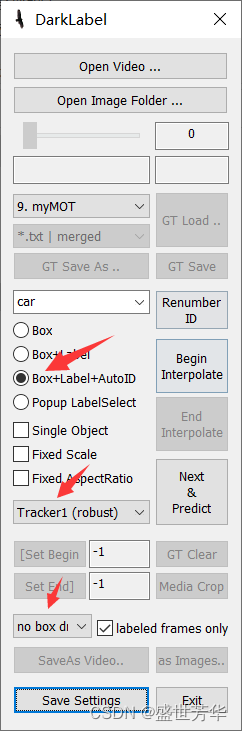
要注意这里:
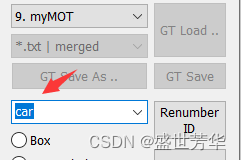
当选中我们自定义的标注规则后,这里会显示分类名称,因为我只定义了一个car类,所以默认选中了car,如果你定义多个类型,在标注之前需要先选中你要标注的分类,再开始标注。
还有这里,darklabel是带有自带标注功能的,它会自带预测你的标注框在下账图片中的位置,它提供了两种预测方式,如图:
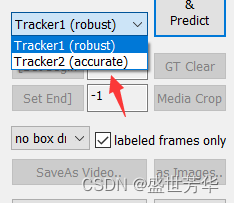
Tracker1(robust),插值法,每次只能标注一个目标。
首先在第一帧点击Begin Interpolation,然后画目标bbox,按↓键往后几帧,在找到该目标画出bbox,点击End Interpolation,然后就可以看到中间帧该目标都被圈住了,效果挺好的,效果如下:
DarkLable使用Tracker1(robust)插值法
Tracker2(accurate),每次可标注多个目标。
在当前帧画出多个目标bbox,然后点击next,算法会自动计算目标框的位置,越往后bbox就越不准了,但是可以多个目标同时跟踪,效果如下:
DarkLable使用Tracker2(accurate)
我在标注过程中,用的是Tracker1(robust),一个车一个车的标注,每隔7、8帧标注一下,效果不错,切忌帧数跨度太大,太大会出现标注框漂移。不使用Tracker2是因为预测后期,框越来越不准,需要不断的调整框的大小,很麻烦。
开始标注,点击![]() 打开视频文件,例如我先标注蓝色车辆,先点击
打开视频文件,例如我先标注蓝色车辆,先点击 ,然后标注蓝色的车。
,然后标注蓝色的车。

此时,左上角出现了这个车的编号为0,按小键盘的↓箭,跳5-6帧后,再标注一下。

过程中,一定要注意左上角的图片编号,同一辆车编号一定不要变,一辆车标注完以后,一定要点击 ,然后才能开始重新标注下一辆车。
,然后才能开始重新标注下一辆车。
注意:shift+双击编号可以修改编号,shift+鼠标左键拖拽可调整矩形边框,shift+鼠标右键可删除矩形。
等全部标注完成后,点击![]() 保存gt文件,然后点击
保存gt文件,然后点击
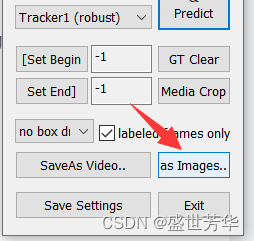
将图片序列保存到某个目录(这些图片未来将放在img1文件夹下)。
此时,我们得到了一个gt.txt和一个图片序列,还缺一个det.txt文件,上面我说过,gt.txt其实已经包含了det.txt中需要的数据,我们只要把指定数据抽出来就行,然后按照官方的MOT17_tiny文件夹格式,放置gt.txt、det.txt、以及图片序列文件即可。手动创建太麻烦,我特意写了一个脚本:
import os
import shutil
# 定义要创建的目录路径
dataset_directory = "dataset"
test_directory = os.path.join(dataset_directory, "test")
train_directory = os.path.join(dataset_directory, "train")
# 创建目录
os.makedirs(test_directory, exist_ok=True)
os.makedirs(train_directory, exist_ok=True)
print("创建数据集结构")
# 定义要遍历的目录路径
work_directory = "work"
# 遍历目录中的所有txt文件
for filename in os.listdir(work_directory):
if filename.endswith(".txt"):
file_path = os.path.join(work_directory, filename)
# 获取文件名(不包括后缀)
fname = os.path.splitext(filename)[0]
gt_file = 'gt.txt'
print(f"处理文件: {file_path}")
# 读取文件内容并处理
with open(file_path, 'r') as file:
lines = file.readlines()
modified_lines = []
# 修改每一行的内容
for line in lines:
print(line.strip())
values = line.strip().split(',')
# 将第一列和第二列的值加1
values[0] = str(int(values[0]) + 1)
values[1] = str(int(values[1]) + 1)
modified_line = ','.join(values)
modified_lines.append(modified_line)
# 将修改后的内容写回文件中
with open(gt_file, 'w') as file:
file.write('\n'.join(modified_lines))
# 创建det文件
# 打开原始文件和新文件
det_file = 'det.txt'
with open(gt_file, 'r') as original_file, open(det_file, 'w') as new_file:
lines = original_file.readlines()
# 遍历原始文件的每一行
for line in lines:
values = line.strip().split(',')
# 保留感兴趣的列
selected_columns = [values[0], str(-1), values[2], values[3], values[4], values[5], str(1)]
# 将这些列写入新文件
new_line = ','.join(selected_columns) + '\n'
new_file.write(new_line)
#组织数据集
gt_dir = os.path.join(train_directory, fname,"gt")
det_dir = os.path.join(train_directory, fname,"det")
img1_dir = os.path.join(train_directory, fname,"img1")
#删除文件夹
if os.path.exists(gt_dir):
shutil.rmtree(gt_dir)
if os.path.exists(det_dir):
shutil.rmtree(det_dir)
if os.path.exists(img1_dir):
shutil.rmtree(img1_dir)
#创建文件夹
os.makedirs(gt_dir, exist_ok=True)
os.makedirs(det_dir, exist_ok=True)
os.makedirs(img1_dir, exist_ok=True)
#复制文件
shutil.move('gt.txt', gt_dir)
shutil.move('det.txt', det_dir)
for item in os.listdir(os.path.join(work_directory,fname)):
# 构建原始文件和目标文件的路径
source_item_path = os.path.join(work_directory, fname, item)
shutil.copy(source_item_path, img1_dir)
print(f"处理完成: {file_path}")脚本放在DarkLabel2.4根目录下,然后创建work文件夹,然后把刚才标注的gt文化和图片序列文件夹放在work目录下,重新起个名字,如图所示:
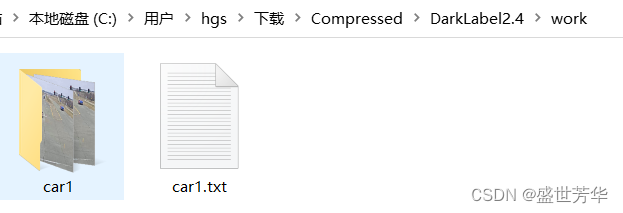
如果你标注了多个视频,那么就把所有视频生成的标注文件都放在work目录下。然后执行脚本,脚本会扫描work目录的所有txt文件,然后创建MMTracking需要的MOT-17格式数据集。
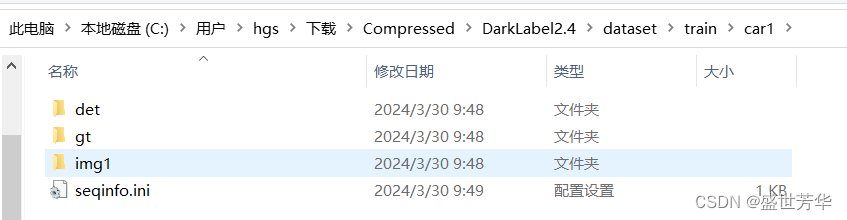
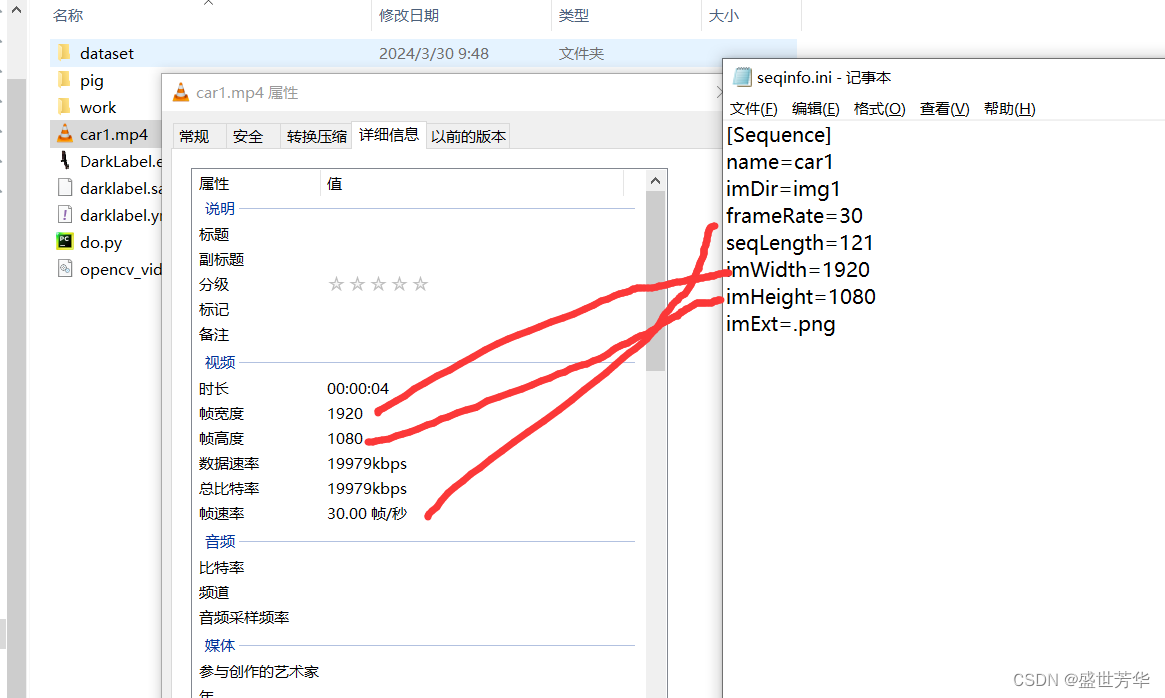
train文件夹下就出现了car1目录,里面存储了刚才标注好的所有文件,同时手动创建一个seqinfo.ini文件,把视频信息保存进去,右键视频文件查看属性,可以看到图片分辨率和视频帧率,根据实际情况填写即可。
五、未完待续
参考:
python darklabel标注的数据格式转成MOT16格式_darklabel标注mot的方法-优快云博客
多目标跟踪数据集 :mot16、mot17数据集介绍以及多目标跟踪指标评测-优快云博客
将Yolov5的检测结果文本输出格式改成MOT17格式_yolov5识别生成的txt格式是什么-优快云博客
目标跟踪--目标跟踪数据集MOT16/MOT17/MOT20的区别-优快云博客
目标跟踪心得篇六:如何转换DarkLabel的标注并在MMTracking上输出跟踪评测(Win, Linux均适用)_目标跟踪干货分享-优快云专栏 从零开始学习DarkLabel视频标注软件_darklabel下载-优快云博客
【DarkLabel】使用教程(标注MOT数据集)_darklabel使用教程-优快云博客
目标跟踪--目标跟踪数据集MOT16/MOT17/MOT20的区别-优快云博客
【DarkLabel】使用教程(标注MOT数据集)_darklabel制作数据集-优快云博客
MMTracking 多目标跟踪(MOT)任务的食用指南 - 知乎 (zhihu.com)
Darklabel多目标跟踪标注工具 - 知乎 (zhihu.com)

















 1292
1292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









