



GRANO:面向云原生分布式数据平台的基于图的交互式根本原因分析
王汉章∗,方·阮∗,李军,SelcukKopru,张基因,桑吉夫·卡塔里亚,萨米·本‐罗姆丹{ hanzwang,phuonnguyen,junli5,skopru,genzhang,skatariya,sbenromdhane}@ebay.comeBay公司
摘要
我们要展示了 Grano1,一个面向云原生分布式数据平台的端 到端异常检测和根因分析(简称RCA)系统,该系统通过提 供系统组件拓扑、告警和应用事件的整体视图来实现。
Grano提供:一种 Detection Layer,用于处理大量时 序监控数据,以在逻辑和物理系统组件上检测异常;一种 Anomaly Graph Layer,采用新颖的图建模和算法,利用系 统拓扑数据和检测结果识别系统组件级别的根因相关性;以 及一种 Application Layer,可自动通知值班人员,并通过 交互式图界面提供实时和按需的根因分析支持。该系统已使 用eBay的生产数据进行部署和评估,帮助值班人员将根本原 因的识别时间从数小时缩短至几分钟。
PVLDB参考格式:
王汉章、方·阮、李军、塞尔丘克·科普鲁、张基因、桑吉夫·卡塔里 亚、萨米·本‐罗姆丹。Grano:面向云原生分布式数据平台的交互式 基于图的根因分析。 PVLDB,12(12):1942‐1945,2019。数字对 象标识符:https://doi.org/10.14778/3352063.3352105
引言
及时准确地识别事件的根本原因,对于大多数信息技术 公司维持业务高可用性至关重要。然而,在云原生分布式数 据平台中执行此类任务面临诸多挑战。(1)架构复杂性:为 了实现可用性和可扩展性,系统通常由数千个不同且相互依 赖的 logical(例如数据库的键空间,每个键空间包含多个分 片,且每个分片在多个数据中心之间复制)以及 physical组 件构成。逻辑组件实际上被部署在跨多个数据中心的机架、主机和 Pod上。eBay开发的地理分布数据库NuData,部署在 eBay内部基于Kubernetes的云基础设施中数千台主机上。因此,要通过系统组件定位根本原因既耗时又麻烦。(2)系统指标和事件数量庞大:每个系统组件都通过数百个不同类别的指标(如延迟、吞吐量、资源和错误)进行监控。eBay的 NuData监控系统每个抓取间隔在每个数据中心采集2000万 条指标数据。此外,系统还会产生大量应用事件以提供运维 洞察。因此,开发并有效维护大量检测模块来处理如此庞大的指标和事件数据极具挑战性。而且,(3)分布式数据平台的系统指标和事件高度动态且不可预测,导致异常和根本原因 的检测准确率难以提高。事实上,高敏感度的基于规则的告警机制以及基于机器学习的检测模型,常因训练数据不足2而产生大量误报警,给值班人员的处理带来困难。上述挑战 导致从检测到响应的时间间隔较长。在发生事件时,值班人 员通常需要逐一查看数百个不同的指标/事件仪表板和告警信 息以确定根本原因。这一过程可能耗费长达数小时的高度集 中工作,严重影响业务可用性。
本文提出 Grano,一种用于云原生分布式数据平台的 交互式根本原因分析系统。首先,Grano包含一个检测层, 支持对大量系统组件和指标进行异常检测。我们采用人机协 同方法进行异常检测,并实现可暴露直观可调模型参数且具 备可预测模型性能的检测算法。其次,将检测结果结合其他 基于规则的告警和应用事件,投射到分布式数据平台的拓扑 结构上,形成统一的 anomaly graph。第三,我们引入一种 新颖的基于图的根因相关性算法,该算法利用系统组件之间 的相互依赖关系、异常严重程度以及指标重要性来更准确地衡量每个系统组件与根本原因的相关性,并减少误报 的影响。最后但同样重要的是,异常图谱和相关性结果呈现在 interactive knowledge graph 界面上,使用户能够轻松浏览、 关联和进行故障排查,以识别实际根本原因。
相关工作。关于图上的异常检测已有大量相关研究,[2],主要 集中在应用级图(例如社交网络、网页、零售网络)。据我们 所知,目前尚无公开发表的针对分布式数据平台采用基于图方 法的异常检测工作。此外,我们的端到端系统结合了逻辑组件 和物理组件,以最小化误报的影响,并更准确地识别根本原因。其他开源的异常检测系统[1]主要关注第一层检测。由于缺乏 对检测结果的可解释性,使用黑盒机器学习模型(如深度学习) [4],难以实现根本原因识别。程等人[3]提出了一种基于核矩 阵的图异常检测方法,但在输入图之前未使用检测模型作为第 一层。塔尔海姆等人[6]利用调用图进行异常检测。在 Grano中,检测结果被投影为异常图谱上物理组件和逻辑组 件的新节点,用于根本原因识别。
2.系统概述
2.1系统架构
Grano的系统架构如图1所示。Grano由三个主要层组 成:异常检测层、异常图谱和应用层。
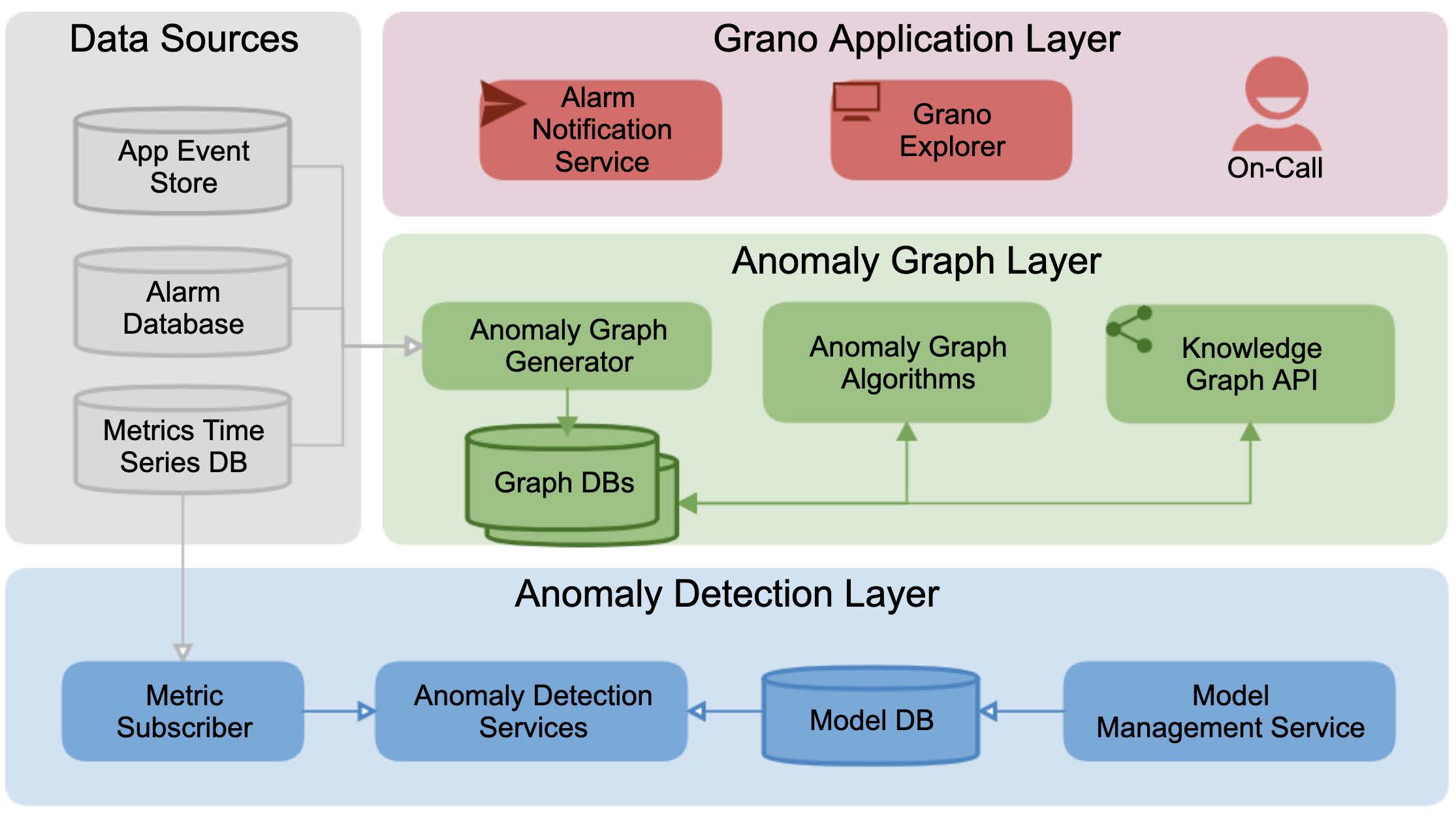
异常检测层 为数据平台的组件和指标提供第一级异常检测。检测模型包括基于机器学习和统计方法的异常检测模型,这些 模型以RESTful服务的形式实现。指标订阅者定期从指标时序 数据库中拉取数据,并调用检测模型以检测异常。检测事件被 创建并发送到告警数据库。模型和特征数据库用于维护在线检 测所用的模型配置和计算出的特征。模型管理服务提供一组 API接口以及管理界面,用于管理模型配置、指标订阅以及新 检测模型的便捷接入。
异常graph layer 提供检测事件的二级聚合,并度量 root cause relevance(简称RCR),通过利用分布式数据平台的系统拓 扑。异常图生成器构建一个异常图,该图包含所有物理和逻 辑系统组件及其相互依赖关系(即表示为边)、告警(包括 由一级检测模型产生的检测事件和基于规则的告警)以及应 用事件。每个告警或事件都被投影到异常图上,作为一个节 点,并通过边连接到触发该告警或事件的相应系统组件。生 成的图存储在图数据库中,并由异常图算法用于计算系统组 件的根本原因相关性评分(详见第3节)。所有异常图及相关 性结果均可通过异常图API获取。
Grano的应用层 包含一个交互式前端服务,即 Grano Explorer,值班人员可使用该服务与异常图谱进行交互, 对系统组件和异常进行故障排查,并利用计算得出的RCR和知识 图谱轻松识别根本原因。Alarm Notification Service通过Slack发 送关键警报,附带访问警报详细/增强报告的链接,并将警报连接 至 Grano的探索器工具以进行根因分析。
2.2检测模型
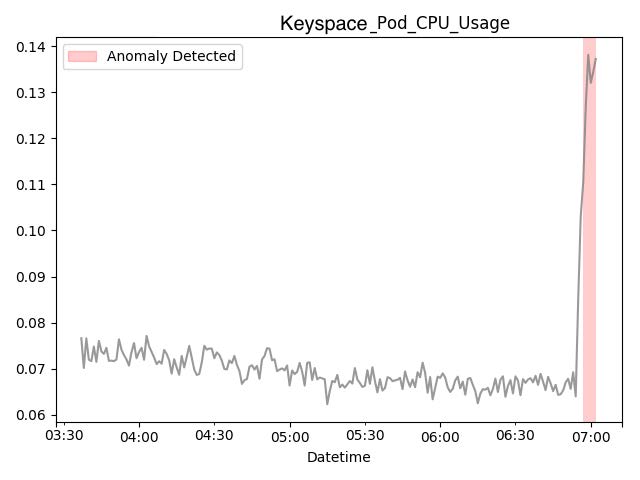
我们识别了分布式数据平台中最常见的异常检测用例(图 2)。 First,即从一组具有相似行为的目标中识别出异常值 (图2a)。针对此用例,我们采用基于密度的聚类算法来检 测异常,因为该方法无需预先指定聚类数量,并且提供了直观 的参数以控制正常聚类的期望密度水平。 Second,即判断某 个目标在某一指标上的行为是否与其正常行为(即其时序模式) 不同(图2b)。针对此用例,我们实现了一种基于加法分解 预测的检测模型[5]来检测异常。具体而言,预测服务以批处 理模式运行,生成目标指标的预测结果,在线检测模型则将实 时指标数据与预测结果进行比较以检测异常。该预测模型还提 供了直观的参数,用于调节模型对数据中变化点的灵活性以及 对数据中时序模式的保留程度。 Third,即判断某项指标的行 为是否与其近期行为不同(图2c)。针对第三种检测用例, 我们实现了基于指数平滑的检测模型。该模型提供数据平滑因 子,使分析人员能够轻松调整模型对指标时间序列中系统性变 化的响应速度。
为了轻松地将上线检测扩展到大量目标和指标,我们采用 model inheri-tance 方法进行模型实现和 部署。
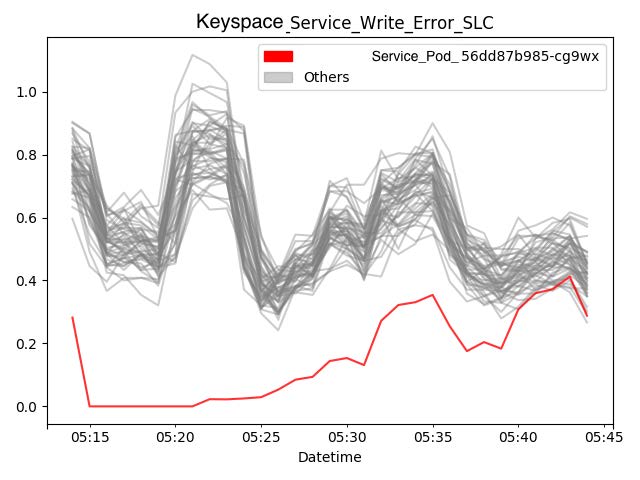
图3:基于图的根因相关性流程。
图4:分布式数据基础设施拓扑示例。
具体而言,我们对检测模型、目标和指标类型的实现进行了抽 象。只需通过为目标和指标类型配置特定参数来扩展基础检测 模型,即可接入一个实际的模型实例。
3.基于图的根因分析相关性
在本节中,我们将更详细地介绍基于图的二级根因分析方 法如何利用第一级检测的结果,并对系统组件的根因相关性提 供更深入的洞察。 Grano所采用的基本概念是使用图建模和 传播算法来衡量检测事件的重要性,并最小化误报警的影响。告警的重要性随后被用于衡量系统组件的根因相关性。最终结 果通过交互式知识图谱界面呈现,便于识别根本原因和因果关 系。
接下来,我们将详细解释使用基于图的系统拓扑和告警 事件表示来测量系统组件根因相关性的逐步过程(图3)。
步骤1‐图构建
我们的方法将第一层异常检测模型产生的检测告警、实时监控系统生成的基于规则的告警3以及应用事件 作为输入。给定一个时间范围,检索到的告警和事件集合, 记为A,随后被投影到分布式数据平台的拓扑图上,形成一个 统一异常图,记为G=(V,E),其中V= C ∪ A,C表示 系统组件集合,E中的每条边表示组件之间的相互依赖关系 (例如,容器与其所部署的主机之间的连接)或组件与告警 之间的关系。
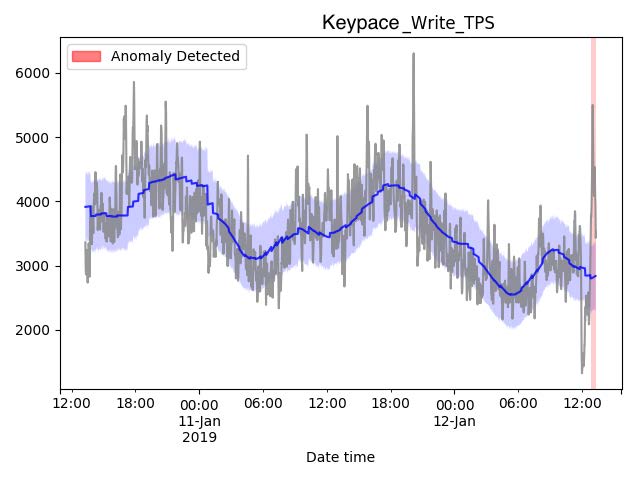
图4展示了一个常见的分布式数据平台拓扑示例,我们将 在本文和演示场景中使用该示例。该图的顶点包括逻辑组件 (如键空间、分片和副本)以及物理组件(如区域、机架、主 机和Pod)。每个键空间对应一个数据库模式,且一个键空间可以拆分为多个分片,每个分片会复制为多个副本以 实现高可用性。副本作为物理Pod部署在分布式基础设施上, 多个Pod位于同一主机上。区域表示由多个机架组成的数据中 心,每个机架包含多个主机。
每个告警事件都关联一个 criticality,表示为 ρa, a ∈ A 4。在告警 a与其对应组件 c之间创建一个告警“edge” e(a, c),其权重表示告警 severity,记为σe(a,c)(下文将详细描 述)。
步骤2‐告警边评分
其思想是评估告警对连接的系统组件的重要性。由于告警可能以不同的严重性和严重程度出现在不同 的组件上,我们为每个告警与组件之间的边计算并分配一个分 数。对于每个组件,我们将其在给定时间间隔内发生的告警集 合视为一个“bag-of-alarms”。每个告警通过以下两个方面进 行度量:i)告警严重性:基于在给定时间间隔内某个告警对特 定系统组件的严重程度;ii)告警的组件(或逆)频率:基于 该告警在所有组件中于给定时间间隔内的出现频率。
让我们考虑告警 a 与系统组件 c之间的一条告警边 e(a, c)。在给定的时间间隔内, c 可能因组件指标的动态变化等 原因多次触发告警 a,每次触发具有不同的严重性级别,记 为 x0, x1,…, xt,其中 xi(0 ≤ i ≤ t)表示在时间 i的严重性。为了度量 e(a, c)(即σe(a,c))的严重性,我们使用指数平滑 公式对时间间隔内的不同告警严重性级别进行聚合:
$$
\sigma^0_{e(a,c)} = x_0 \
\sigma^t_{e(a,c)} = \alpha x_t + (1 - \alpha)\sigma^{t-1}_{e(a,c)} \quad (t > 0)
$$
其中 α是平滑因子,上一次迭代中计算出的严重性评分 将作为边 e(a, c)的最终严重性评分。
边 e(a, c)在 a 和c之间的告警边评分,记为se(a,c),按如下 方式计算:
$$
s_{e(a,c)} = \sigma_{e(a,c)} \log\left(\frac{|C|}{|C_a|}\right)
$$
其中 Ca是触发了告警 a的系统组件集合。分数se(a ,c)被归一化 到(0, 1]。
步骤3‐组件节点评分
在上一步之后,所有告警边都被赋予了一个分数,该分数反映了告警对组件的重要性。在此步骤中, 我们计算组件上的聚合置信度评分。置信度评分(表示为cs) 通过告警的关键性以及连接到组件的边的评分来计算 c:
$$
cs_c = \sum_{a \in A_c} \rho_a s_{e(a,c)}
$$
其中 A c 是与组件 c相连的所有告警的集合。
步骤4‐评分传播
此步骤旨在利用系统拓扑来检测实际根本 原因。我们设计了一种定制算法,在节点上传播置信度评分。该算法在每个至少被连接的节点上传播置信度评分一个告警传递给其所有连通组件。然后,连通组件使用其分配 的分数继续传播,直到到达图的末端(区域或键空间节点)。对于接收节点 c,其连接到其他组件 Vc(包括告警和系统 组件),传播的分数pc按如下方式计算:
$$
p_c =
\begin{cases}
\beta cs_c & \text{if } |V_c| = 1 \
\gamma \frac{\sum_{\hat{c} \in V_c} cs_{\hat{c}}}{|V_c|} & \text{if } |V_c| > 1
\end{cases}
$$
其中 β和 γ是我们设置为0.9和log(|Vc| +1)的算法参数。所有传播的评分将与初始评分相加以计算最终的RCR评分。该评分表示此系统节点作为根本原因的整体相关性。
步骤5‐结果展示
我们定义了自定义的图搜索和场景以探索该图。我们以排序和聚合的方式返回结果。因此,用户能够 浏览疑似事件的根本原因、告警类型、告警频率以及拓扑。
4.演示说明
为了展示 Grano的功能,并方便分析人员推断异常并识 别根本原因,我们构建了图1所示的完整系统以及基于Web的 前端界面。我们将在下文中描述演示场景。
4.1管理检测模型生命周期
在第一个演示场景中,我们将让参会者体验在Grano上 接入新检测模型的过程。用户将使用 Grano的模型管理服务 接口,按照分步流程选择系统指标和键空间来接入新的检测 模型,并在提交最终模型定义之前,查看由 Grano自动生成 的模型定义。一旦新模型提交完成,我们将展示用户如何通 过控制模型订阅及其参数,在 Grano上轻松管理该模型的生 命周期,并通过 Grano的检测事件时间线观察结果。特别是, 用户能够实时动态更新模型定义,例如直观的模型参数、检 测间隔和订阅配置,并实时观察这些更新对检测结果的影响。由此,用户可进一步体验如何通过 Grano的模型管理服务交 互式地调优模型,以达到理想的性能表现。
4.2使用知识图谱进行根因分析
在第二种场景中,我们将演示如何使用我们的异常图谱, 通过真实的脱敏数据来识别根本原因。从一个关键告警出发, 参与者将能够利用 Grano的增强工具快速了解有关该告警及 其受影响键空间的更多信息。
然后,与会人员将使用 Explorer来检索所有系统组件 (包括逻辑组件和物理组件)的 real-timeRCR评分。除了 RCR评分外,探索器还会显示其他组件评分,即“初始”和 “传播”(这些评分来自第3节中步骤3和步骤4的计算结果)。值班人员可以查看系统对每个组件的初始根因相关性以及其 所接收到的传播影响的预测情况。
从其连通组件中。过滤按钮可以仅显示任何选定平台实体的连 通组件(通过其他不同类型的组件直接或间接连接)的检测结 果。用户还可以选择特定的时间范围来生成异常检测结果并刷 新。
通过单击一个组件,可以可视化其动态图,该图会检索 所有关联的系统组件及相关的告警(基于规则和模型检测) 以及应用事件。图5展示了一个数据分片组件的异常知识图谱 示例,其中不同类型的节点以不同颜色填充,节点大小根据 其RCR评分(针对系统组件节点)或严重程度(针对告警/事 件节点)确定。对于告警与系统组件之间的边,告警严重性 越高,边越粗。用户可通过将光标悬停在任意节点上来查看 该节点的详细评分及相关信息。
从组件的图视图中,用户还可以通过在顶部选择一个或 多个目标实体并更新知识图谱视图,遍历图以搜索根本原因。
5.结论
我们介绍了用于云原生分布式数据平台的异常检测框架 Grano的概述和演示描述。主要结果表明,使用 Grano能 够有效快速地检测异常并识别系统事件的根本原因。未来, 我们希望更加关注组件级别与系统级异常之间的差距,并将 Grano与自动化修复引擎集成。
6.参考文献
[1] 异常检测项目 s. https://github.com/rob-med/awesome-TS-anomaly-detection。访问日期:2019-03-15。
[2] L. Akoglu,H. Tong,和 D. Koutra。基于图的异常检测与描述:综述。Data Mining and Knowledge Discovery 29(3): 626–688, 2015。
[3] H. Cheng,P.-N. Tan,C. Potter,和 S. Klooster。多元时间序列中异常的检测与特征描述。在 Proceedings of the 2009 SDM 中,第413–424页。SIAM,2009。
[4] M. Du 等人。DeepLog:通过深度学习从系统日志中进行异常检测与诊断。在 Proceedings of CCS 2017 中,第1285–1298页。ACM,2017。
[5] R. J. Hyndman 和 G. Athanasopoulos。Forecasting: principles and practice。OTexts,2018。
[6] J. Thalheim,Rodrigues 等人。Sieve:从分布式系统监控指标中获取可操作洞察。在 Proceedings of the 18th Middleware Conference 中,第14–27页。ACM,2017。


















 1336
1336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









