



随机森林的系统性分析基于社交媒体垃圾信息分类
摘要
近年来,随机森林分类成为检测在线社交网络中垃圾内容的机器学习应用中的流行选择。本文报告了针对此目的的随机森林分类的系统性分析。我们评估了关键参数(如树的数量、树的深度以及叶节点的最小大小)对分类性能的影响。我们的结果表明,控制应用于社交媒体垃圾信息的随机森林分类器的复杂度对于避免过拟合和优化性能非常重要。我们还得出结论:为了支持实验结果的可重复性,报告随机森林分类器的关键参数至关重要。
1 引言
在线社交网络(OSN)已成为主要的通信媒介之一。社交网络用户的估计数量超过二十亿[1],这吸引了大量试图以未授权方式利用社交媒体的垃圾信息发布者。女巫攻击使用虚假社交媒体账号的集合来发起大规模的垃圾广告活动[2]。许多研究表明,在线社交网络中这些虚假账户的比例超过百分之十[3]。除了这一高比例外,使问题更加复杂的是,可通过技术手段利用智能机器人自动控制这些账户。机器人是一种计算机程序,可用于执行自动化任务。为了在社交网络中传播垃圾内容,垃圾信息发布者部署这些机器人以模仿用户在在线社交网络中的行为。这些行为包括人类用户所做的一切操作,例如发布推文、转发和关注/取消关注账号。虚假账户和智能机器人的存在使得在这些网络中传播有害内容变得相对容易。在社交网络背景下,有害内容可能包括误导性信息、谣言、材料或可疑链接。近期人们对社交媒体中假新闻的关注突显了有效应对此类误导性信息传播的重要性和紧迫性[4, 5]。
基于机器学习的分类器常被用于检测附带恶意(垃圾信息、诈骗、钓鱼、自动下载攻击)网址的垃圾推文。与黑名单相比,这种方法的优势在于能够对攻击进行早期检测(零时至零日)。
在在线社交网络中检测垃圾内容最常用的机器学习分类算法是随机森林、支持向量机、朴素贝叶斯和k‐最近邻分类器[6–8]。大多数旨在检测在线社交网络中垃圾内容的研究表明,与其他监督学习算法相比,随机森林分类器具有更高的分类准确率。然而,大多数报告将随机森林分类器应用于在线社交网络垃圾信息检测的论文并未提供有关所使用分类器参数的详细信息,通常也未分析分类器复杂度对分类器性能的影响。
本文报告了对随机森林参数(包括树的数量、树的深度和最小叶大小)在应用于在线社交网络垃圾信息检测的随机森林分类器分类性能上影响的系统性研究。我们使用了一段时间内收集的Twitter数据,其中包含一组已验证的Twitter垃圾信息,这些垃圾信息含有指向垃圾链接的链接。我们的结果表明,控制随机森林分类器的复杂度非常重要。本研究还表明,在未对关键随机森林参数进行适当分析和设置的情况下,默认应用随机森林分类器进行在线社交网络垃圾信息检测可能会导致虚假的良好结果。我们还指出,为了支持垃圾邮件检测实验结果的可重复性,报告随机森林分类器的关键参数非常重要,例如树的数量、树的最大深度以及与叶节点相关联的数据子集的最小尺寸。
本文其余部分安排如下。第2节简要回顾了关于使用随机森林算法进行推特垃圾信息检测的前期研究,以及有关随机森林算法参数分析的一般性论文。第3节简要描述了随机森林算法。第4节介绍了本研究中使用的数据集以及用于垃圾推文检测的数据特征。第5节对随机森林分类器在推特垃圾信息检测中的参数进行了系统性分析。第6节对全文进行讨论并得出结论。
2 相关工作
在当前旨在减少在线社交网络中恶意内容和链接数量的研究中,使用机器学习算法十分普遍。在本节中,我们简要回顾了专门采用随机森林算法构建分类器用于在线社交网络垃圾信息检测的研究。
2.1 垃圾邮件分类研究
随机森林是在构建分类模型以检测在线社交网络中有害内容分布时常用的算法之一。
古普塔等人[8]提出了一种专门用于识别通过bit.ly缩短服务缩短的恶意URL的机制。这种缩短服务经常被垃圾信息发布者利用,他们自动生成恶意短链接,并通过推特上的虚假账户进行传播。他们构建了三种模型(朴素贝叶斯、决策树和随机森林),对模型的分类性能进行了比较。他们报告称,随机森林分类器在所考虑的数据上表现出最佳性能。
楚等人[10]使用了一系列常见的学习算法,包括随机森林、贝叶斯网络、简单逻辑回归和决策树,以检测推特上的垃圾信息活动。他们根据推文数据集的网址落地页进行聚类,每个聚类被视为一个活动。每种算法都在包含744条垃圾信息活动推文和580条合法推文的真值数据上进行训练。他们发现,随机森林取得了最高的准确率以及最低的误报和漏报分类率。
麦科德等人[11]使用轻量级特征将用户内容分类为垃圾信息或正常内容。这些特征从推特账户信息(例如关注者/被关注者数量)和推文内容信息(例如提及和话题标签的数量)中提取。与之前的研究类似,作者使用了多种机器学习算法来比较其性能。所使用的算法包括随机森林、支持向量机、朴素贝叶斯和k‐最近邻。他们发现,随机森林算法取得了最高的精确率(95.7%)和F值(0.957)。
尽管随机森林算法在在线社交网络垃圾邮件检测领域广受欢迎,但大多数论文并未提供构建随机森林分类器时所使用的参数设置(例如树的数量、树的深度)的详细信息。这使得难以评估这些结果的有效性,并且未提供任何关于随机森林参数如何影响所报告应用中分类性能的信息。我们还注意到,缺乏此类信息使得其他研究人员难以复现这些研究,而可复现性是有效科学研究的关键要求。
2.2 随机森林参数
这里我们简要回顾了几篇关于随机森林分类应用的论文,这些论文考虑了该技术的参数对分类性能的影响。
Bosch等人[12]使用随机森林分类器来解决物体图像的分类问题。评估所使用的数据集是Caltech‐101和Caltech‐256,这两个是相关文献中常用的基准数据集。他们使用不同的参数设置训练了多个随机森林分类器。他们关注的参数包括树的数量和最大树深度。树的数量从1变化到100,并采用了三种不同的深度设置:10、15和20。结果表明,较深的树比浅层的树具有更高的性能。分类性能随着树的数量增加而提升,在使用100棵树且最大树深度为20时,性能达到80.0%。该研究还对多种算法(如支持向量机、随机蕨分类器和随机森林分类器)进行了比较,结果显示随机森林分类器的效果最佳。
连皮茨基等人[13]使用随机森林分类,基于高分辨率超声数据对心肌进行自动勾画。他们分析了参数,例如数据样本数量、树的最大深度和数据维度。他们确定了这些参数的最优值,并将其用于实验结果中。他们表明,在考虑召回率、精确率和ROC作为性能指标时,包含3棵树的随机森林与包含20棵树的随机森林表现相当。
3 随机森林算法
随机森林是一种基于集成的分类器,这意味着它由一组子模型组成,用于共同做出决策。随机森林使用多个决策树分类器。这些树是通过从完整的训练数据集中抽取随机样本构建的,因此由于不同树的特征重要性排序可能存在差异,导致各树之间具有潜在的差异性。依赖多个树的决策使得随机森林分类器相比单个决策树和其他非集成方法更加稳健,并且更不容易过拟合[14]。
构建一棵树需要确定几个关键参数[15],例如使用的特征数量、树的深度[13],以及最小叶大小。特征的数量由所用数据的维度决定。最大树深度是指决策树允许拥有的连续二元决策的最大数量。最小叶大小是指期望属于决策树任意叶节点相关数据子集的数据项的最小数量。如果对某个叶节点关联的子集进一步分割会导致产生的叶节点所关联的数据项少于最小叶大小,则不分割,该节点仍保持为叶节点。
先前的研究表明,为决策树和随机森林设置合适的参数有助于避免过拟合。
4 检测包含可疑网址的推文
我们收集了两个多月的随机推文。我们将约两百万条推文存储在MongoDB数据库中。我们仅选取包含外部URL的推文进行后续工作,若某条推文包含的外部网址已在所选推文数据库中存在,则该推文被舍弃。最终使用的推文数据集包含15万条带有外部URL的推文。
构建真实数据集需要一个准确且无偏见的标注机制。为此,我们使用了一个名为VirusTotal的在线服务。VirusTotal是一项提供黑名单、杀毒软件和恶意软件检测器组合的服务。此前,其他研究人员已使用该工具来标注Twitter数据[8,17, 18]。VirusTotal会检查提交的网址,并返回一份报告,说明该网址的状态,即是否可信。如果报告中包含至少两个恶意正向标记,则我们认为该网址为恶意的。通过使用VirusTotal进行验证,我们能够在包含外部URL的15万条推文中识别出3万条恶意推文。
对于每条推文,我们收集了36个特征。这些推文特征包括:Twitter来源特征(例如用户信息、推文)、页面内容(例如文本和HTML元素)以及域名信息(源自WHOIS)。
我们使用随机森林算法来构建推文分类器。我们使用Python和Scikit‐learn机器学习库构建了系统(系统的代码可在以下网址获取:(https://github.com/mohfadhil/NSS17)。我们使用了39017条推文来训练每棵决策树,其中包括18075个正例和20942个负例(即垃圾信息和非垃圾信息推文)。基于随机森林的推文分类引擎在检测包含恶意URL的垃圾推文时,平均F1值为0.885,精确率为96%,召回率为82.2%。推文的收集与分析过程总结于图1机器学习。
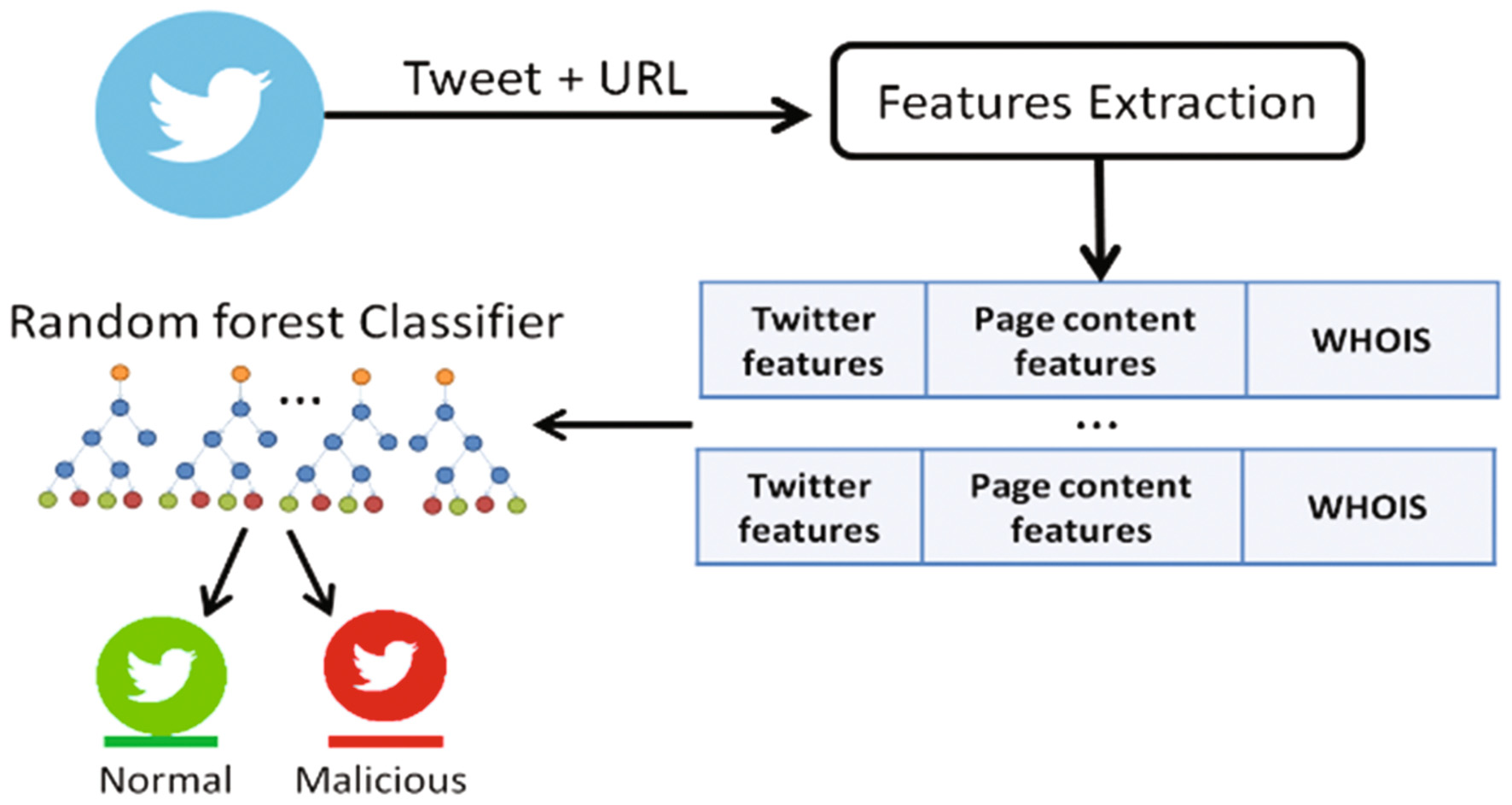
5 系统性分析
尽管随机森林分类被广泛用于在线社交网络中垃圾信息/恶意内容的检测,但关于该方法在参数设置方面具体如何使用的详细信息仍然缺乏[19]。这限制了所报告结果的可重复性以及对其的独立验证。这种做法也使得理解参数对随机森林分类在在线社交网络垃圾信息检测应用中的性能影响变得困难。
我们将随机森林分类的参数考虑如下:树的数量、树的最大深度以及叶节点的最小大小(即与这些节点相关联的数据子集)。数据特征的数量(即数据维度)保持不变。对于每种参数设置,我们使用随机选择的训练和测试数据集进行了20次实验。为了分析参数设置对分类性能的影响,我们计算了20次实验中性能指标的平均性能和标准差。分类器的性能通过召回率、精确率和F值来衡量。使用t检验比较性能结果,以判断在显著性水平p = 0.05下,平均性能的差异是否具有统计显著性。对于标准差(实际上是方差)的比较,我们在显著性水平p = 0.05下使用了F检验。
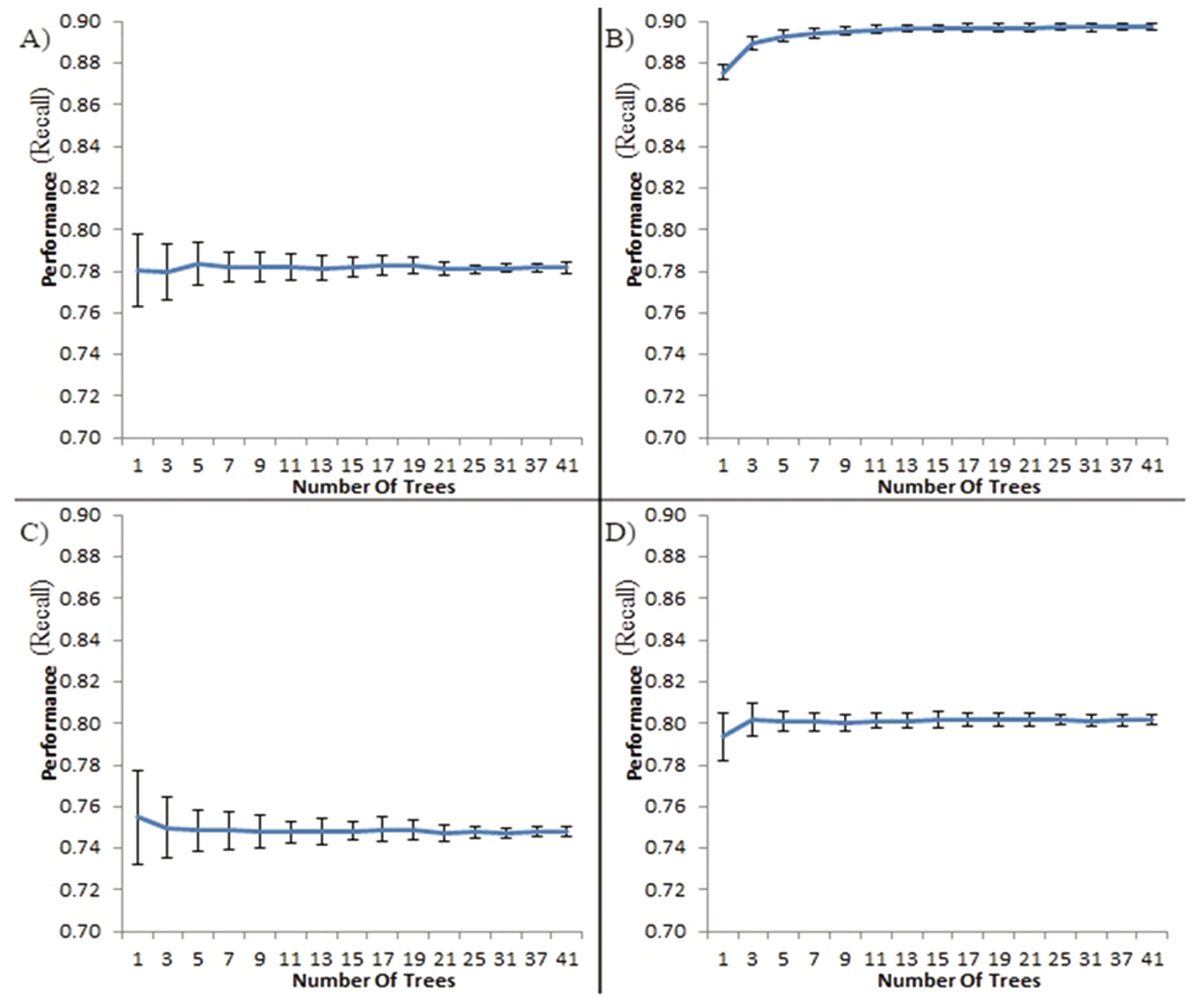
5.1 树的数量
通常,树的数量越多,性能越好[20]。我们的结果证实了这一点(见图2)。我们的结果还表明,随着树的数量增加,性能值的标准差也减小。这些结果适用于所有最大树深度和叶节点大小的设置。
增加树的数量对具有较大大树深度的随机森林在平均性能方面的影响最为显著。对于较小的最大树深度,向随机森林中添加更多的树可以在降低标准差方面提高性能,但在平均性能方面没有太多改善。在所有考虑的情况下,当随机森林中的树的数量超过9棵树时,平均性能不再有统计显著的进一步提升。
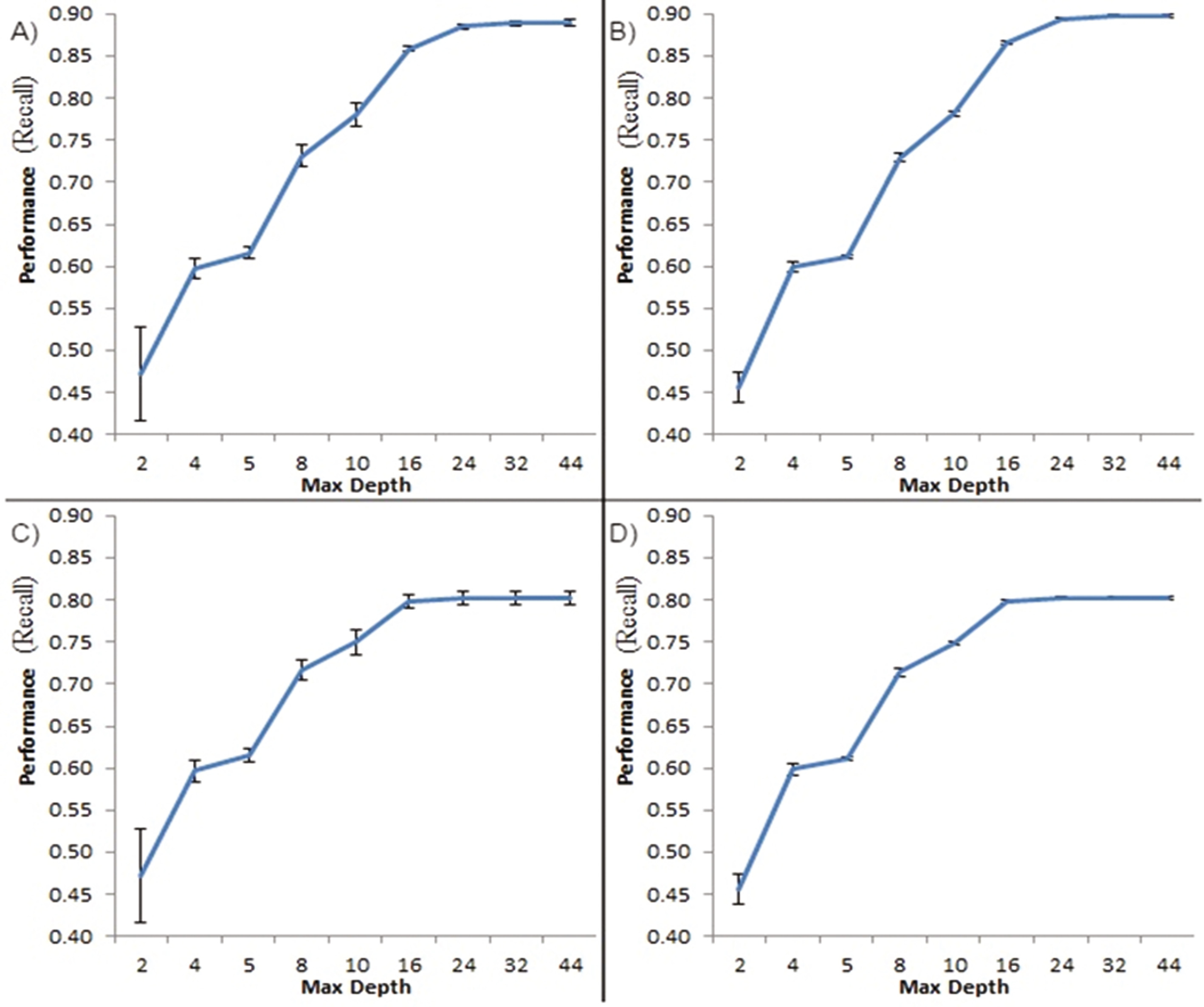
5.2 最大树深度
最大树深度是决定随机森林分类器复杂度的变量之一。树可以不受任何深度限制地构建,但通常建议控制树的深度以避免过拟合[16]。本文在考虑树的数量和最小叶大小的一系列固定组合的情况下,分析了改变最大树深度的影响。
我们的结果表明,在考虑所有树的数量和最小叶大小组合的情况下,树的最大深度对垃圾信息检测问题的分类性能有重大影响(见图3)。我们发现,随着树的最大深度增加,分类器的平均性能也随之提升。对于具有较大最小叶大小的随机森林,这一提升在最大深度达到16之前具有统计学显著性;而对于具有较小最小叶大小的随机森林,该显著性则持续至最大深度24。我们还发现,随着最大深度的增加,性能的标准差逐渐减小,这一效应在具有较大最小叶大小且树的数量较少的随机森林分类器中最为明显。
这些结果表明,无论最小叶大小和树的数量如何,将最大树深度设置得过低都会导致分类性能低下(参见图3中四个子图中最大树深度低于8的情况)。虽然由于最小叶大小的限制,将最大树深度设置得较高可能并不会生成达到该深度的树,但潜在地可能导致树过于深且复杂,从而无法提升分类性能。
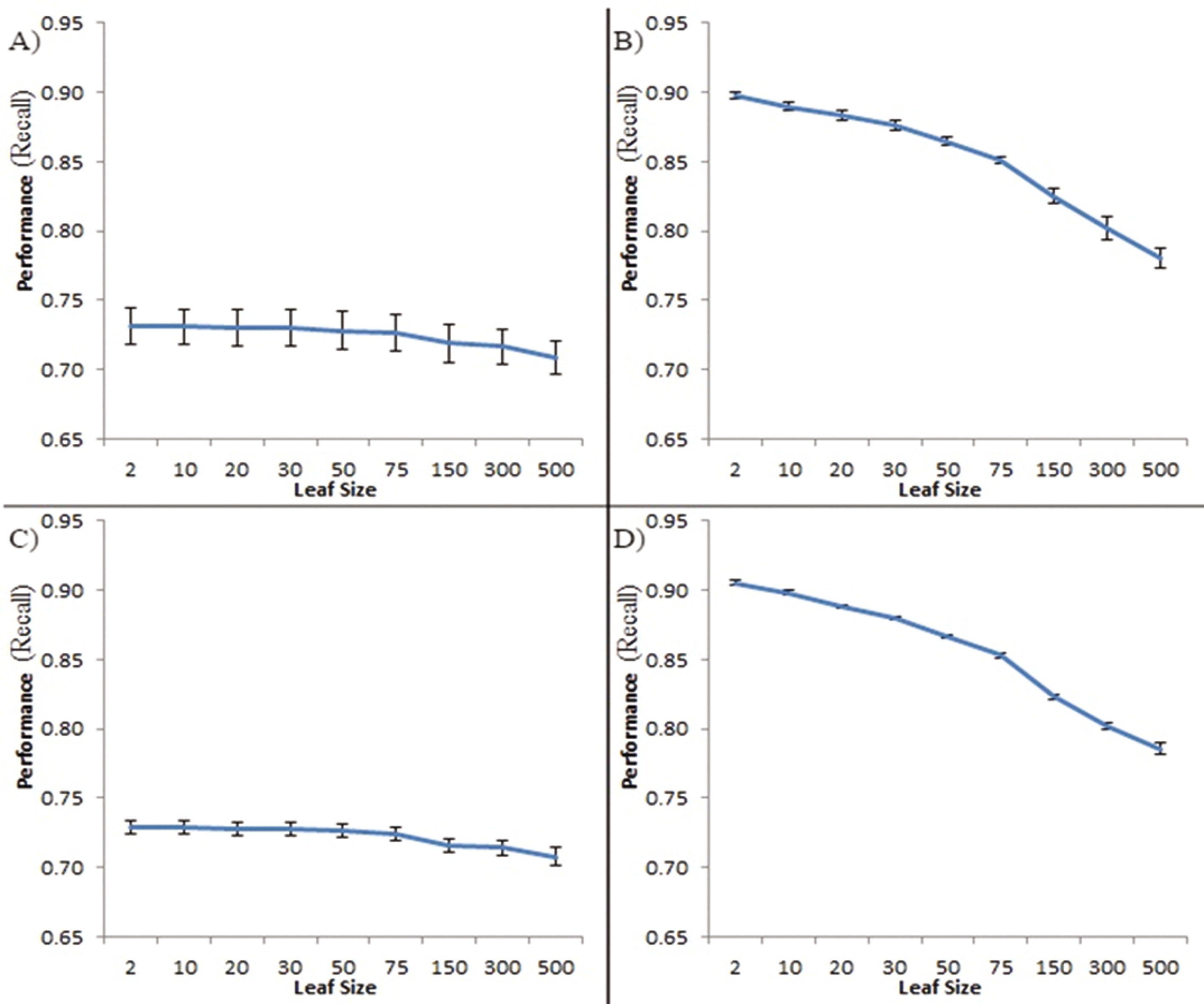
5.3 最小叶大小
最小叶大小通过为与叶节点相关联的数据子集设置大小限制来控制决策树的复杂度,从而防止在达到此限制的节点之后向树中添加更多的决策节点。我们研究了在保持树的数量和最大树深度不变的情况下,改变随机森林分类器用于垃圾信息检测任务时的最小叶节点大小的影响。
结果表明,在所有情况下,最小叶大小的增加都会降低分类器的性能(见图4)。这种效应在具有较大树深度的分类器中比在具有较小树深度的分类器中更为明显。对于分类器中树的数量不同的情况,该效应是相似的,唯一的区别在于,树的数量较多时,性能的标准差低于树的数量较少的情况。
对于具有较低最大树深度的随机森林分类器,当最小叶大小大于30(树的数量较多)或50(树的数量较少)时,其对性能具有统计显著影响。这表明,在这些情况下,树的深度受限意味着在较小的最小叶大小下分类器的性能受限。
相比之下,对于具有较高最大树深度的分类器,叶大小的影响在所有取值下均具有统计显著性(即较大的最小叶大小意味着性能显著降低)。
5.4 总结
我们的分析表明,随机森林分类器的参数,即树的数量、最大树深度和最小叶大小,是这些分类器性能的重要决定因素。在我们的垃圾邮件检测任务中,如果我们构建的分类器具有足够大的树的数量、足够高的最大树深度以及足够低的最小叶大小,则其性能表现非常出色。
结果表明,树的数量对性能影响相对较小,超过9棵树后,性能没有显著变化。叶子节点的最小大小影响更大,特别是对于具有较大树深度的分类器,即使叶子节点最小大小的微小变化也会对性能产生显著影响。最后,最大树深度在该参数取值较低时对性能有显著影响,而对于小和大的叶子节点最小大小,当深度值分别超过16或24后,其影响减弱至不再显著。
这意味着,为了在不过度增加计算负担的情况下实现良好的性能,树的数量和最大树深度应设置为适中的值。过小的最小叶大小与过大的最大树深度相结合可能导致过拟合(注意:过拟合是由于树本身引起的,而不是由于树的森林结构[21, 22])。因此,控制最小叶大小非常重要,同样应将其设置为适中值,以避免过拟合和不必要的过度计算。
6 讨论与结论
过拟合是决策树学习的一个潜在问题,因此对于随机森林分类器也同样存在(注意,树的数量本身不会导致过拟合)。处理这一问题非常重要,因为由过拟合的决策树解决方案在分类问题中产生的过度理想化结果具有误导性。特别是在在线社交网络垃圾信息分类的背景下,这个问题尤为重要,因为在该应用领域中随机森林分类被广泛使用,且社交媒体消息的错误分类可能带来重大影响。
我们的结果证实了预期,即对决策树的最大深度以及与树的叶节点相关联的数据子集的最小尺寸施加限制,可以降低过拟合的可能性。我们的结果量化了这些限制,以及在我们特定的非垃圾信息和垃圾推文数据集背景下超出这些限制的影响。
随机森林分类器中的树的数量主要影响分类结果的标准差。树的数量还会影响训练分类器所需的时间(所需时间与树的数量成正比)。这意味着,通过增加随机森林中的树的数量,可以以牺牲计算时间为代价来提高分类结果的鲁棒性。然而,我们的结果也表明,当树的数量超过一定数值后,分类性能标准差的降低收益变得微不足道。
我们的研究表明,通常在将随机森林分类应用于在线社交网络(OSN)垃圾信息检测时,应评估最大树深度、叶节点大小和树的数量的影响,以确定这些参数的充分取值,从而避免过拟合并实现性能提升。这也意味着此类应用的结果应附有充足的元数据信息,包括树的数量、最大树深度、最小叶大小,以及任何其他对所报告的随机森林分类器性能有影响的参数。
我们的结果在随机森林分类参数针对所使用的推文数据集得出的具体数值方面存在一定的局限性。然而,我们研究结果所得到的原则性结论(即确定和报告随机森林参数的重要性)对于随机森林分类在在线社交网络垃圾信息检测中的任何应用,以及该方法在任何分类应用中均具有普遍有效性。
为了便于我们工作和结果的可重复性,我们提供了所使用的Python代码以及创建的垃圾检测任务数据集的访问权限。这些资源可通过以下网址获取:https://github.com/mohfadhil/NSS17。

















 1617
1617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









