 YOLOv5口罩检测实战
YOLOv5口罩检测实战





一、 创建虚拟环境
下载口罩算法: yolov5-mask-42-master
- 进入项目文件夹,cmd 进入目录
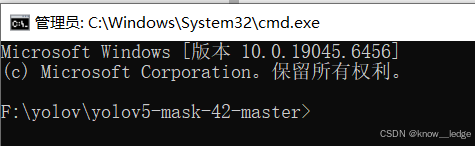
- 输入代码,创建 py20251110 虚拟环境
conda create -n py20251110 python==3.10
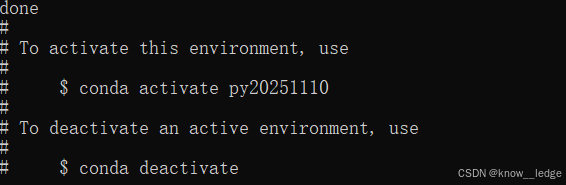
- 激活虚拟环境 py20251110
conda activate py20251110

补充:如何找练习的项目
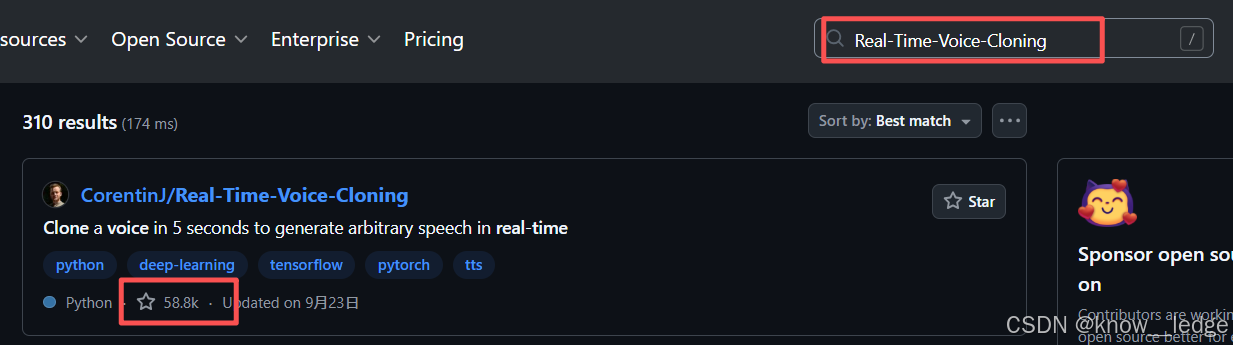
使用 github 进行查找 https://github.com/
- 搜索框搜索想练习的算法,查看其收藏数选择高质量算法进行练习
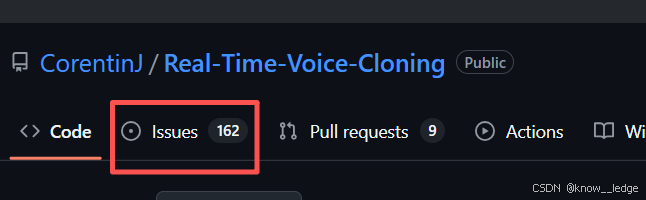
- issues数 决定了算法的稳定度
二、安装相关依赖
- 安装 pytorch
- 安装 ultralytics
pip install -U ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple/
- 安装依赖 requirements.txt
可使用 dir 查看文件目录
dir
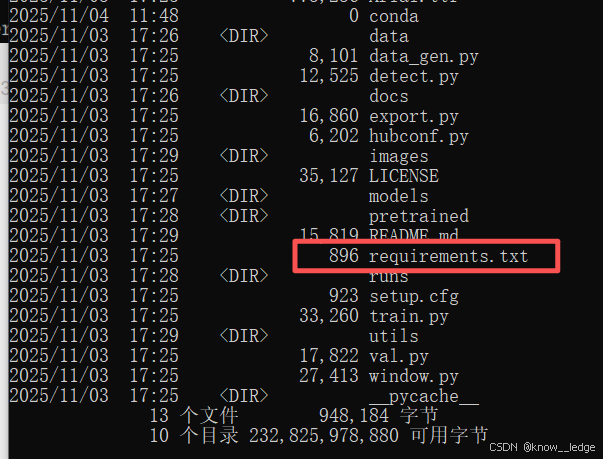
- requirements.txt 文件里包含了所有该项目需要下载的依赖
pip install -r requirements.txt
- 安装过程遇到警告:某些版本过低

pip install --upgrade torch torchvision numpy
pip install --upgrade numpy
- 安装计算目标检测精度
pip install pycocotools
- 图形化界面依赖
conda install pyqt5
不要在一个环境里混用 conda 和 pip 装同名包
补充:用 Python 内置工具实现 Conda 功能(有些公司域控)
- 使用 Python 自带的 venv + pip 代替 Conda 功能
Conda 的核心价值是:创建隔离环境 + 安装科学计算包。Python 自带的 venv + pip 完全可以替代
以下步骤均在 PyCharm 中执行,仍是使用 YOLO5 口罩算法
- 步骤 1:创建虚拟环境(等效于 conda create)
# 创建名为 yolov5-env 的环境
python -m venv yolov5-env
这个命令不需要管理员权限,也不会被域控拦截(因为是 Python 标准库)

- 步骤 2:激活环境(等效于 conda activate)
# Windows CMD (我用的这个)
yolov5-env\Scripts\activate
# PowerShell(如果报错,先运行:Set-ExecutionPolicy -Scope CurrentUser RemoteSigned)
yolov5-env\Scripts\Activate.ps1

激活后,命令行前缀会变成:

- 步骤3:安装 Pytorch (等效于 conda install)
Pytorch cuda版本( GPU 版本通常在 2.4GB 左右)
# 使用 官方 + 国内镜像组合 安装 CUDA 12.1 版本
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://pypi.tuna.tsinghua.edu.cn/simple --extra-index-url https://mirror.sjtu.edu.cn/pytorch-wheels/cu121
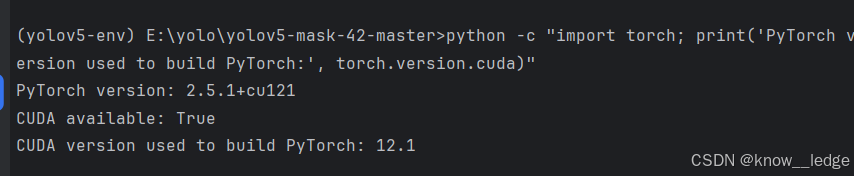
安装后执行命令检查安装情况
python -c "import torch; print('PyTorch version:', torch.__version__); print('CUDA available:', torch.cuda.is_available()); print('CUDA version used to build PyTorch:', torch.version.cuda)"
正确显示
- 步骤4:安装项目依赖 requirements.txt
pip install -r requirements.txt
-
步骤5:运行检测代码缺什么安什么
-
检测代码
python detect.py --source data/images/bus.jpg --weights pretrained/yolov5s.pt --conf 0.25
- 安装以下内容
ultralytics
pip install -U ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple/
安装计算目标检测精度
pip install pycocotools
图形化界面依赖
pip install pyqt5
- 步骤6:添加解释器
三、测试代码
1. Anaconda Prompt 测试
在 yolov5-mask-42-master 文件夹内 Anaconda Prompt 执行测试代码
使用到以下文件:
输入测试代码
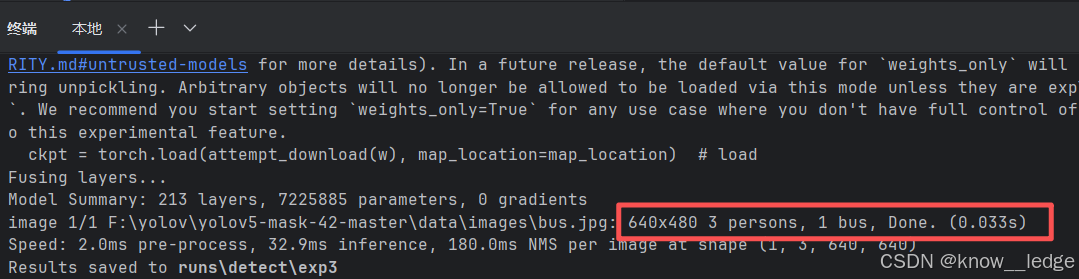
python detect.py --source data/images/bus.jpg --weights pretrained/yolov5s.pt
- 代码含义解读
使用的 --weights 权重文件是: pretrained / yolov5s.pt 模型
需要检测 --source 的图片是:data/images/bus.jpg

- 检测结果解读
图片结果存放在:runs \ detect \ exp2 文件处
2. PyCharm 测试
PyCharm 解释器设置
- PyCharm打开该项目,右下角设置解释器
- 添加解释器
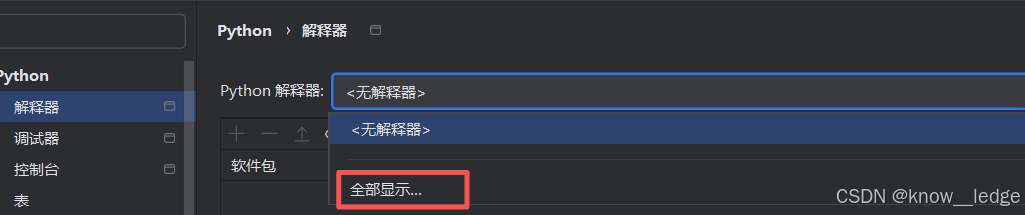
- 添加 conda 会自动带出相关虚拟环境
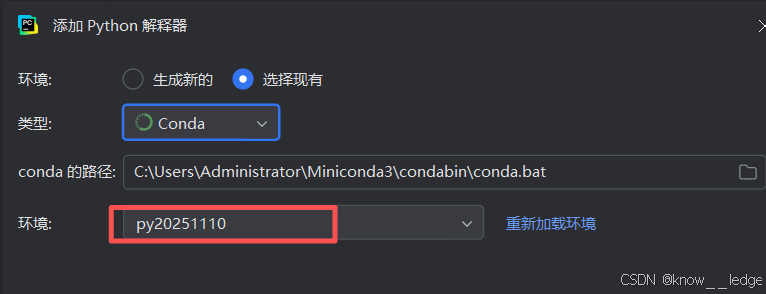
- 关联项目

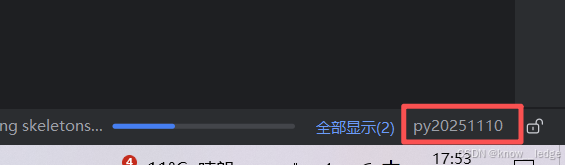
- 配置成功后主界面右下角显示该虚拟环境,打开终端自动进入该虚拟环境
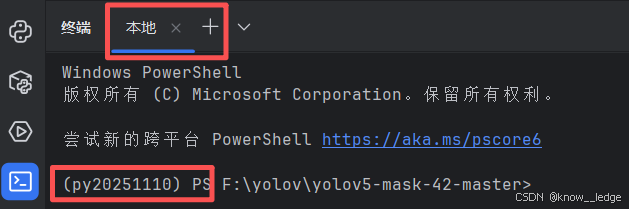
- 输入测试代码
python detect.py --source data/images/bus.jpg --weights pretrained/yolov5s.pt
四、数据标注
1. 安装软件
虚拟环境安装数据标注软件
1)进入算法文件F:\yolov\yolov5-mask-42-master cmd

2)进入虚拟环境
conda activate py20251110
3)下载数据标注软件
pip install labelimg
4)下载成功输入,打开软件
pip install --upgrade PyQt5==5.15.9


若软件总闪退建议直接下载 labelImg.exe

2. 配置软件
修改为YOLO(标注结果 YOLO:txt 格式; CreateML:json 格式;PasclVOC:xml 格式)
3. 使用软件
1)Open Dir 选择要导入的图片文件夹
右侧的 File List 会显示当前文件夹内所有图片文件

2)选择标注好要存入的文件夹
3)标注数据
注意:无论图片格式是否不同,图片名称必须不同。确保标签文件顺利生成
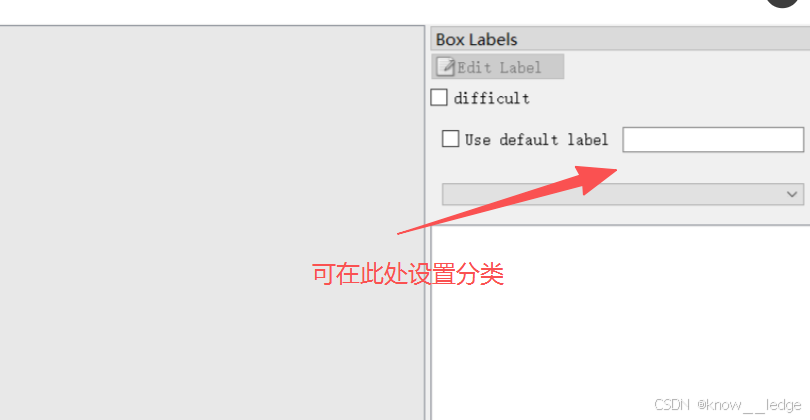
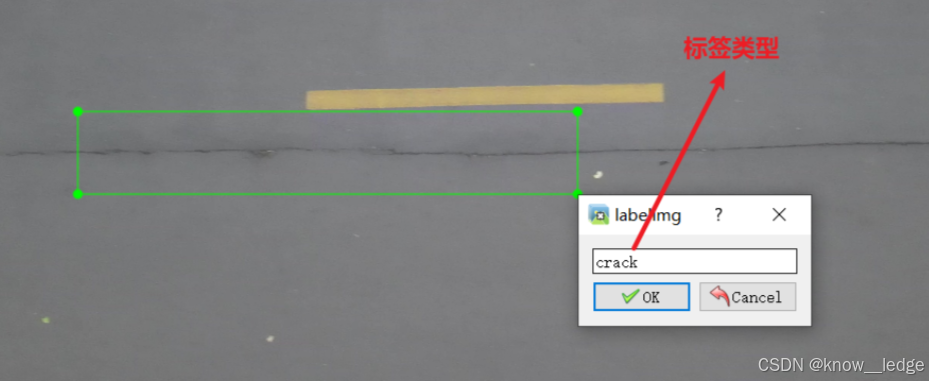
- 可在 Use default labtel 处设置想要的分类,点击键盘 W 按钮对图片进行标注
LabelImg 核心快捷键
| 按键 | 功能 |
|---|---|
| A | 上一张图(Previous Image) |
| D | 下一张图(Next Image) |
| W | 创建一个新的 bounding box(Create a new bounding box) |
LabelImg其他常用快捷键
| 按键 | 功能 |
|---|---|
| Ctrl + s | 保存当前标注(Save) |
| Del 或 Delete | 删除选中的 bounding box |
| Ctrl + u | 打开图像文件夹(Load Dir) |
| Ctrl + r | 更改保存路径(Change Save Dir) |
| ↑ / ↓ / ← / → | 微调选中的 bounding box 位置(每次移动 1 像素) |
| Shift + ↑ / ↓ / ← / → | 快速调整 bounding box 大小(每次缩放 10 像素) |
4)标注完成
标注结果:( YOLO:txt 格式; CreateML:json 格式;PasclVOC:xml 格式)
- YOLO标注后生成的标签文件在 labels 文件里
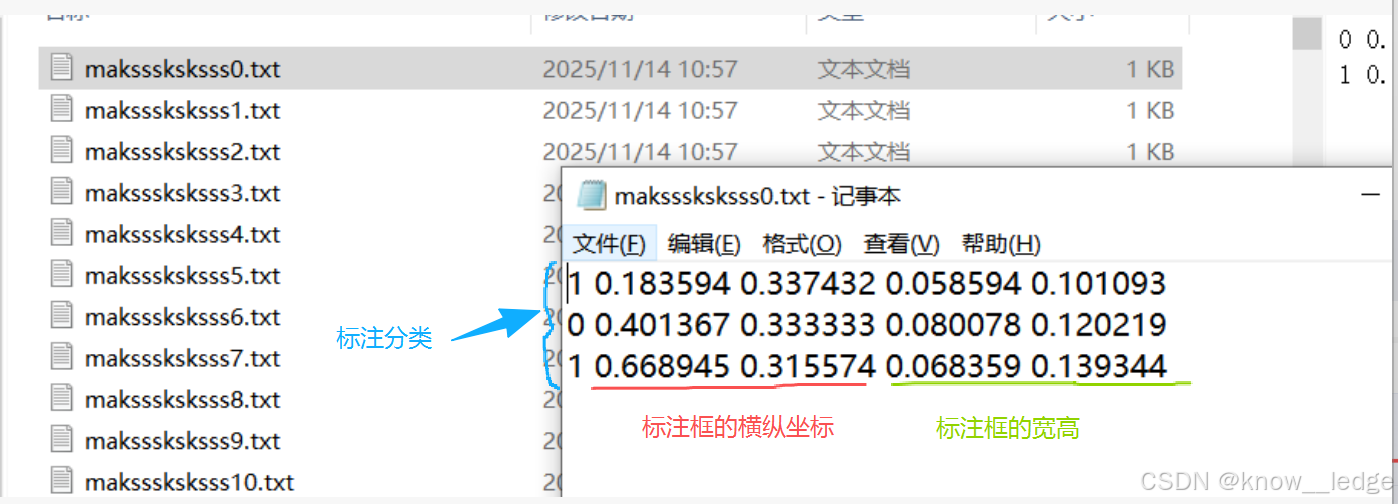
- 生成的 TXT 文件名和 images中的图片名一 一对应

- 每个 TXT 内容的含义,标注了几个选框就有几行
五、数据集
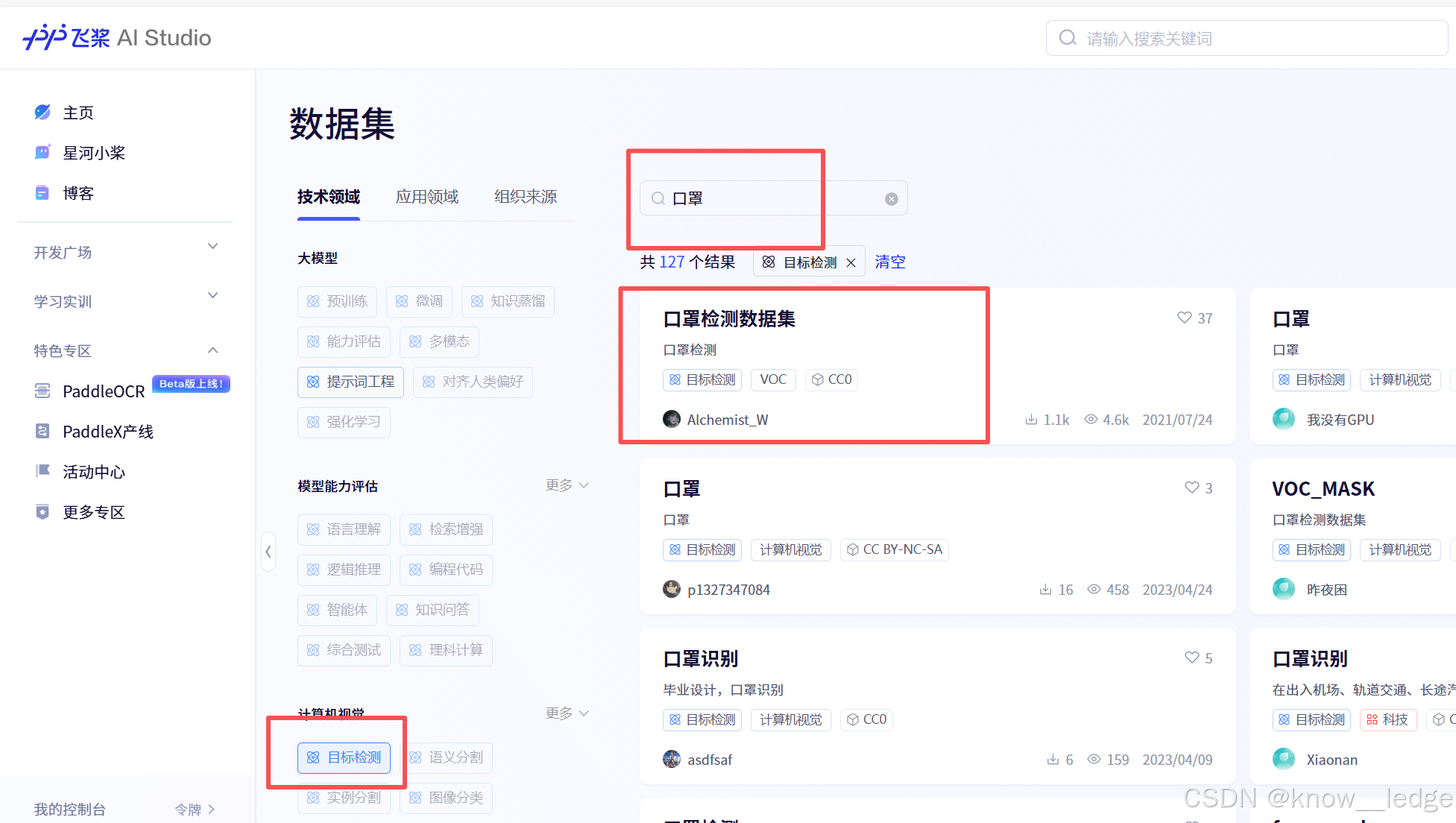
1. 数据集的获取
可进入 飞桨AI - -开放数据集,按需求查找所需的数据集
注意:数据集有两种格式 VOC 和 YOLO,按需求进行转换
VOC 数据集转换为 YOLO 数据集
具体内容请查看:
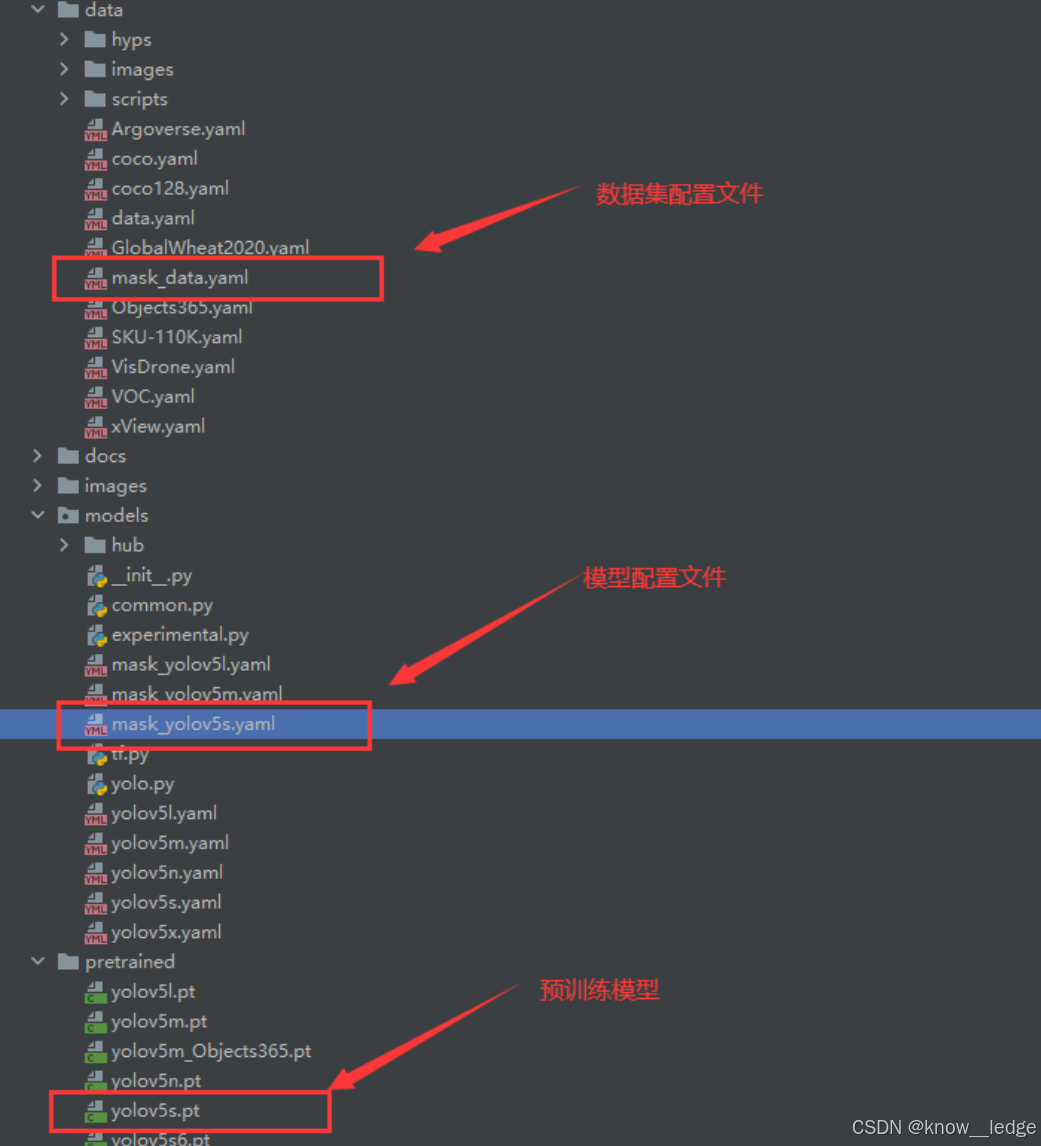
2. 修改数据集配置文件
- 在 data 目录下创建一个 mask_data.yaml 的文件
内容如下:
注意训练集、验证集为反斜杠 ‘/’ (Windows)
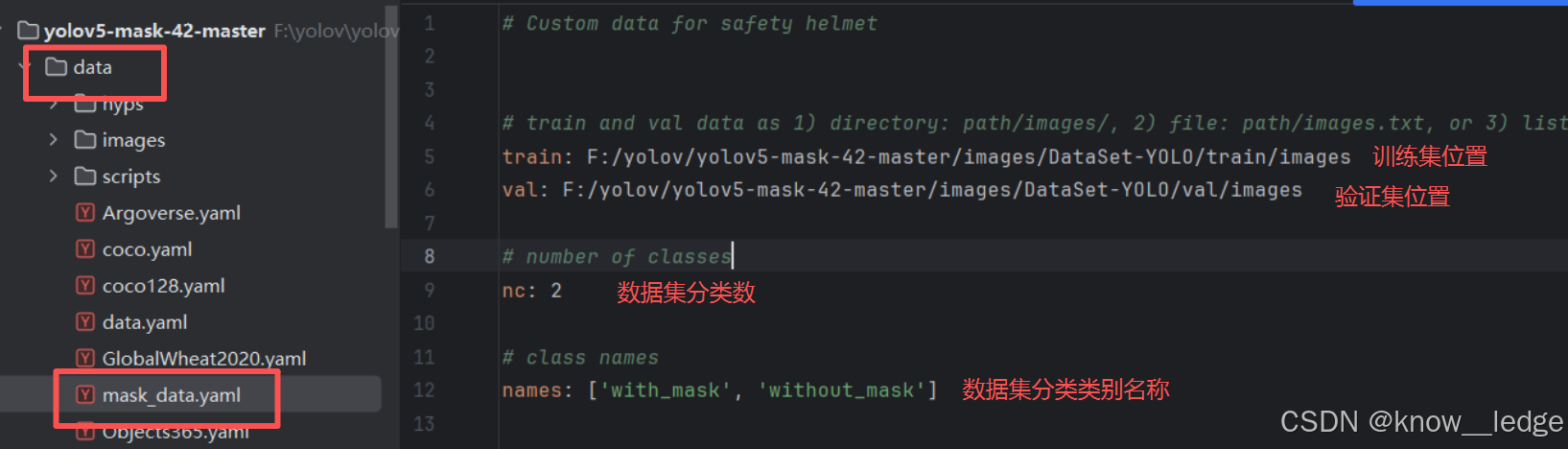
YOLO 训练时,train(训练集) 和 val (验证集)路径必须指向 images 文件夹
- labels 标签路径是 自动匹配 的(要求文件名一致,目录结构对称)
格式满足:
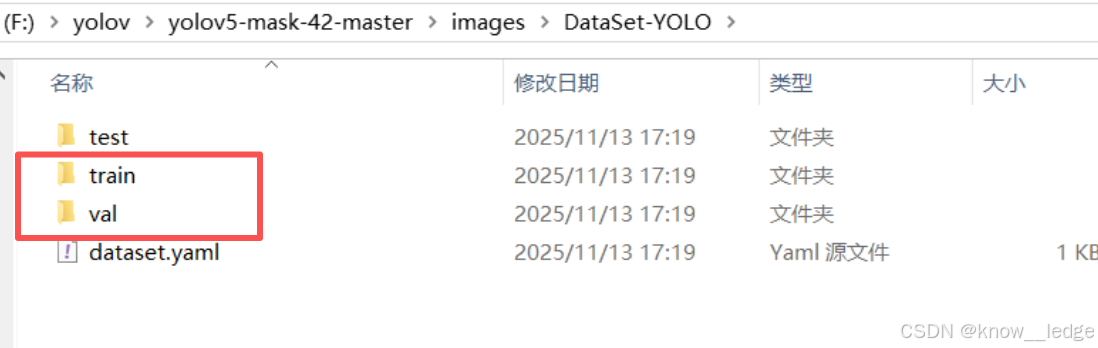
DataSet-YOLO/
├── train/
│ ├── images/ ← 提供给 YAML 的训练集路径
│ │ └── abc.png
│ └── labels/ ← YOLO 自动去找这里
│ └── abc.txt
└── val/
├── images/ ← 提供给 YAML 的验证集路径
│ └── xyz.png
└── labels/ ← YOLO 自动去找这里
└── xyz.txt

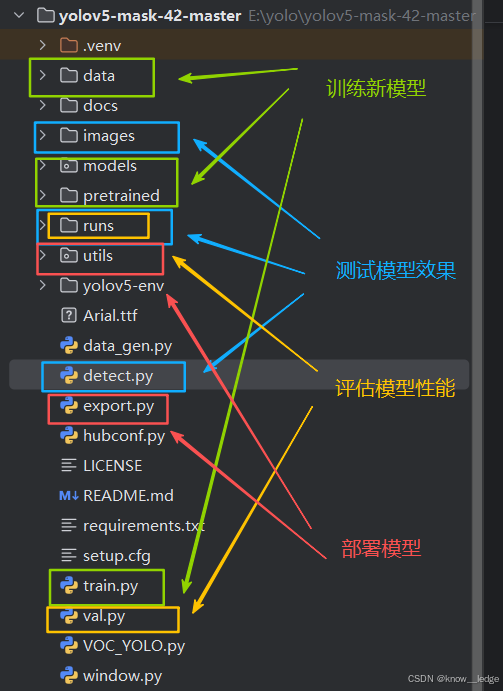
六、YOLOv5 项目结构详解(以 yolov5-master 为例)
yolov5/
├── data/ # 数据集配置
├── docs/ # 文档说明
├── images/ # 数据集图片
├── models/ # 模型结构定义
├── pretrained/ # 预训练权重
├── runs/ # 训练/验证结果输出
├── utils/ # 工具函数库
├── yolov5-env/ # 环境相关(可忽略)
├── data_gen.py # 数据生成脚本
├── detect.py # 推理检测主程序
├── export.py # 导出模型(ONNX/TensorRT等)
├── hubconf.py # HuggingFace Hub 支持
├── train.py # 训练主程序
├── val.py # 验证主程序
├── VOC_YOLO.py # VOC格式转换工具
└── window.py # GUI界面(Windows专用)
| 目录 | 功能 | 作用 | 补充 |
|---|---|---|---|
| data/ 目录 | 数据集配置中心 | 存放数据集的配置文件(.yaml) | |
| docs/ 目录 | 官方文档 | 提供使用说明、API文档、示例、常见问题解答 | 建议阅读:README.md 和 docs/ 下的 index.html 是入门必看 |
| images/ 目录 | 数据集图片 | 存放用于演示的测试图片及数据集 | |
| models/ 目录 | 模型结构定义 | 定义网络架构(YOLOv5s/yolov5m/yolov5l/yolov5x) | 告诉模型“怎么搭建”——卷积层、瓶颈块、SPP、检测头等 |
| pretrained/ 目录 | 预训练权重 | 存放官方预训练模型权重(.pt 文件) | 训练时通常从这些权重开始微调(fine-tune) |
| runs/ 目录 | 输出结果存储区 | 存放训练、验证、检测的结果 | |
| utils/ 目录 | 工具函数库 | 封装各种通用功能 | 很多评估指标(如 mAP)就在这个目录里实现。 |
| detect.py | 推理主程序 | 运行模型进行图像/视频检测 | AI 测试的核心入口之一 |
| export.py | 模型导出工具 | 将 PyTorch 模型导出为其他格式 | |
| train.py | 训练主程序 | 训练阶段核心脚本 | |
| val.py | 验证主程序 | 评估模型性能(计算 mAP) |
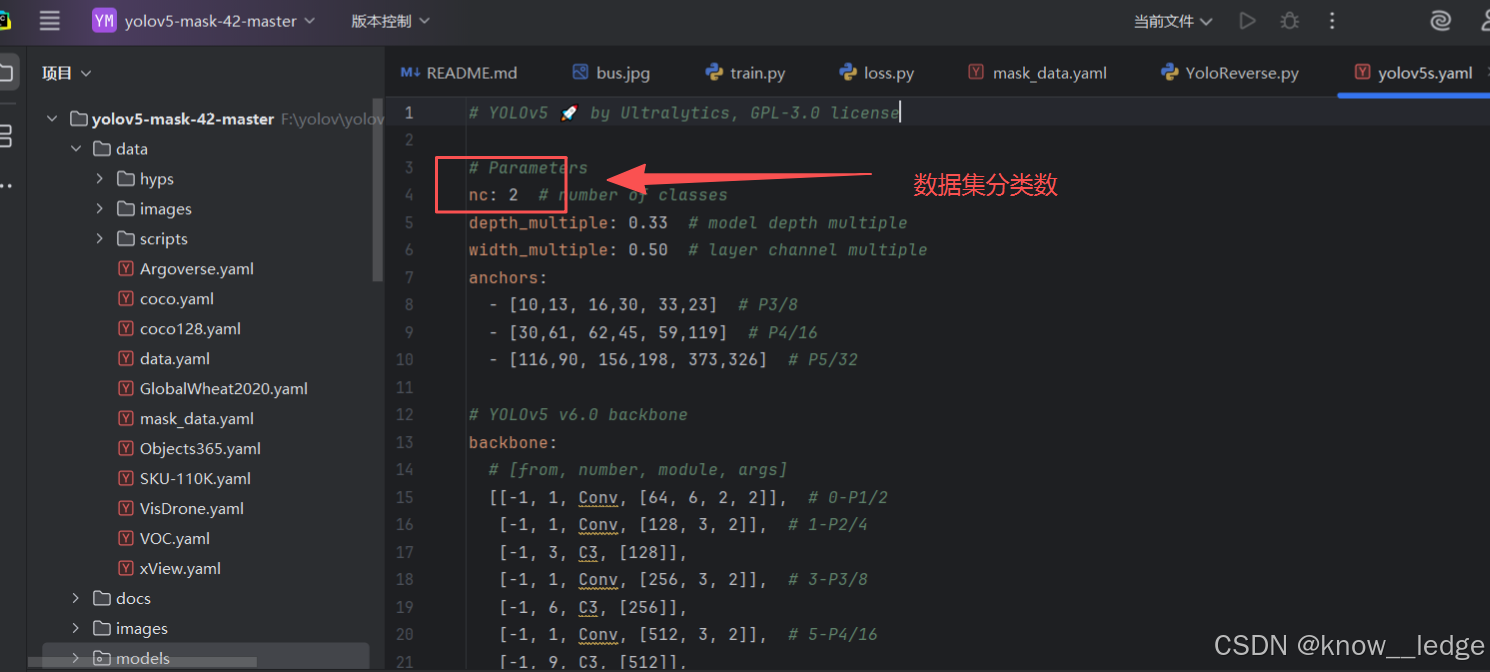
七、模型训练
1. 模型的基本训练
- 修改 models 的 mask_yolov5s.yaml 的模型配置文件,uc = 2(数据集分类数):
- 训练前请确保代码目录下有以下文件:
- 执行 train.py 中代码运行程序即可:
python train.py --data mask_data.yaml --cfg mask_yolov5s.yaml --weights pretrained/yolov5s.pt --epochs 100 --batch-size 2
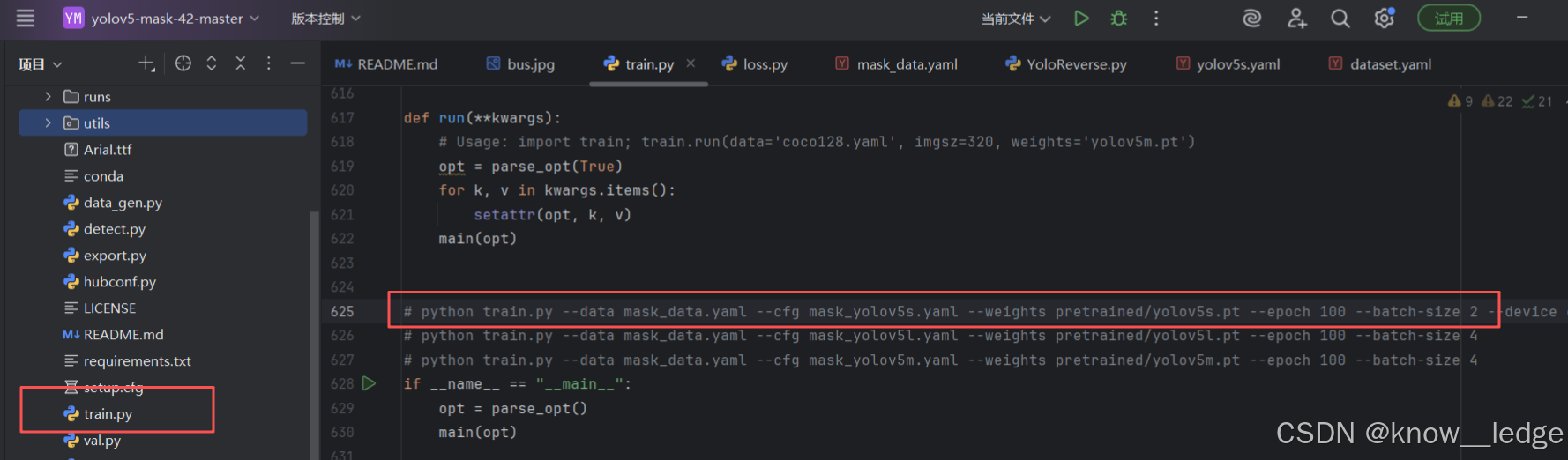
(-- batch-size 一般为16,按显卡来)执行该代码后先扫描数据集,扫描完成进行训练
- 可通过 nvidia-smi 查看显存大小
- 我的显卡:Memory-Usage: 1366MiB / 4096MiB 仅有4 GB ,最大 batch-size 得设为 2
| 代码 | 代码解析 |
|---|---|
| python train.py | 启动 YOLOv5 训练脚本 |
| –data mask_data.yaml | 使用自定义口罩数据集配置(含类别:如 with_mask, without_mask) |
| –cfg mask_yolov5s.yaml | 使用定制的 YOLOv5s 模型结构(适配口罩检测) |
| –weights pretrained/yolov5s.pt | 加载官方预训练权重,进行迁移学习(需提前下载并放在 pretrained/ 目录下) |
| –epochs 100 | 训练 100 轮(默认 300 轮) |
| –batch-size 2 | 每次输入 2 张图像(适合显存较小的 GPU) |
常用训练参数表
| 参数 | 默认值 | 说明 |
|---|---|---|
| –data | - | 数据集配置文件(YAML),指定训练/验证路径和类别名 |
| –cfg | - | 模型结构文件(YAML),定义网络层数、通道等 |
| –weights | ‘yolov5s.pt’ | 预训练权重路径,可加速收敛或迁移学习 |
| –epochs | 300 | 训练总轮数,1 epoch = 遍历全部训练数据一次 |
| –batch-size | 16 | 每卡批次大小,越大显存占用越高,训练越稳定 |
- 根据数据集的大小和设备的性能,经过漫长的等待之后模型就训练完了,输出如下:

2. 训练结果查看
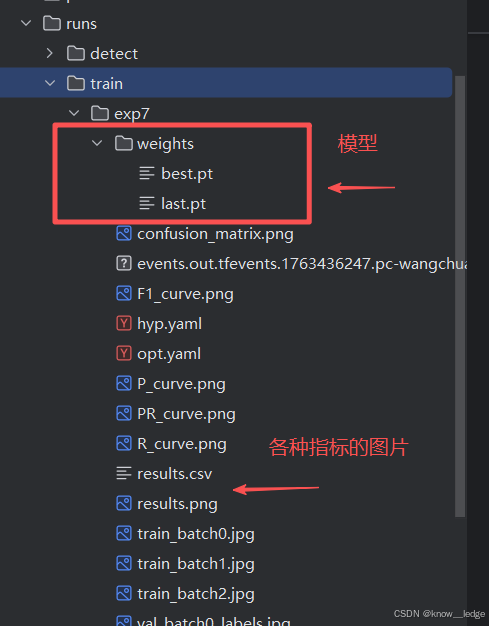
- 在 train / runs / exp 的目录下可以找到训练得到的模型和日志文件
weights(保留两个文件一个best,一个last。表现最好和最后)
3. 模型评估
- 训练完成后,通常会输出三张图,分别展示模型在验证集上的 Precision、Recall 和 mAP
目标检测模型的性能通常用 均值平均密度mAP(mean Average Precision) 评估。mAP 介于 0 到 1 之间,越接近 1 表示模型越好
- mAP 基于 精度(Precision) 和 召回率(Recall) 计算
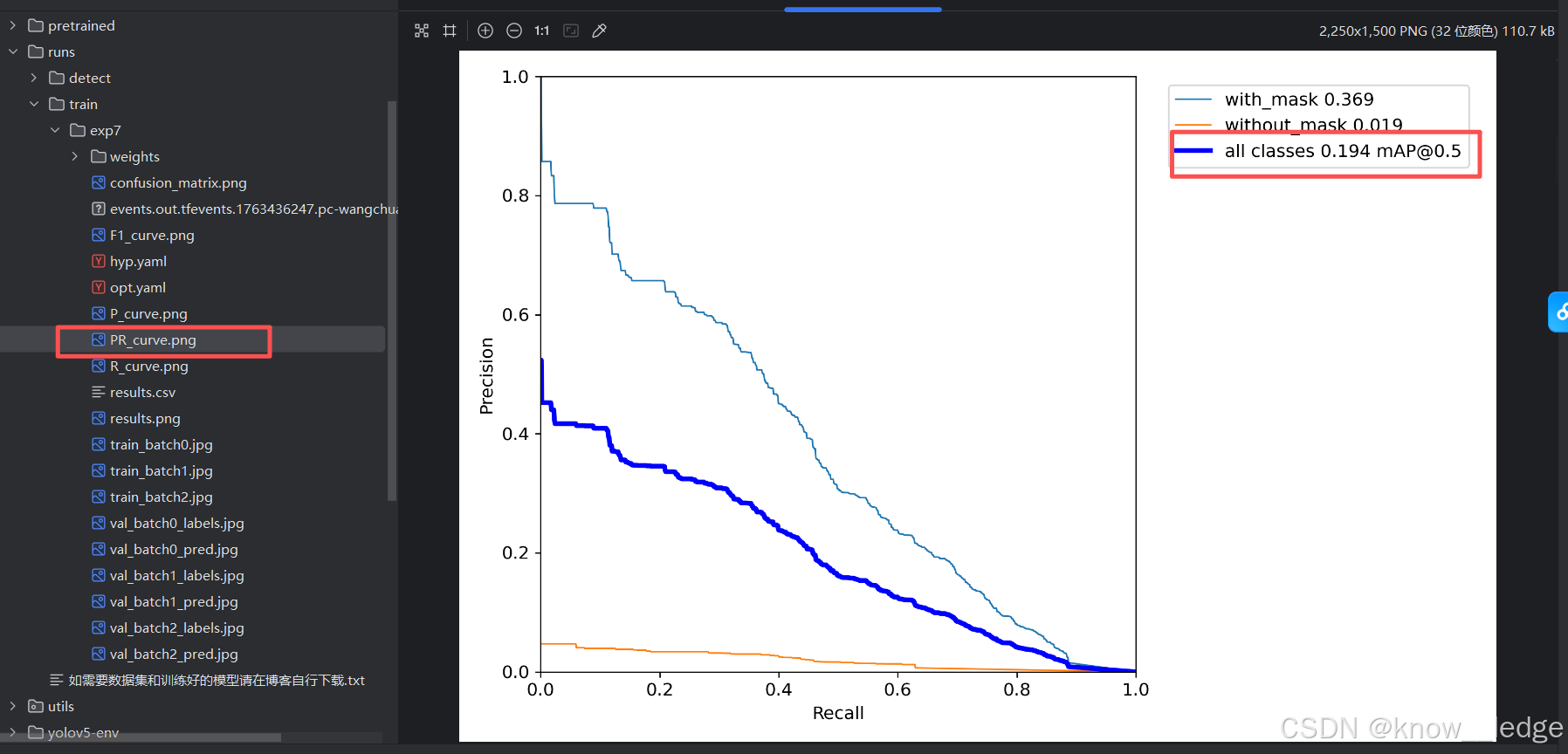
以PR-curve为例,可以看到我们的模型在验证集上的均值平均密度为0.194
- 如果你的目录下没有这样的曲线,可能是因为你的模型训练一半就停止了,没有执行验证的过程,你可以通过下面的命令来生成这些图片:
python val.py --data data/mask_data.yaml --weights runs/train/exp_yolov5s/weights/best.pt --img 640
实际应用评估指标
| 场景 | 应关注哪个指标? |
|---|---|
| 模型整体性能对比 | mAP@0.5:0.95(COCO 官方标准) |
| 是否能准确定位 | AP@IoU=0.75(IoU 越高,预测框越准) |
| 是否会漏检小目标 | APsmall 和 ARsmall |
| 多目标场景表现 | ARmax=10 或 ARmax=100 |
4. 模型使用
模型的使用全部集成在了detect.py目录下,按照下面的指令执行要检测的内容即可
# 检测摄像头
python detect.py --weights runs/train/exp_yolov5s/weights/best.pt --source 0 # webcam
# 检测图片文件
python detect.py --weights runs/train/exp_yolov5s/weights/best.pt --source file.jpg # image
# 检测视频文件
python detect.py --weights runs/train/exp_yolov5s/weights/best.pt --source file.mp4 # video
# 检测一个目录下的文件
python detect.py --weights runs/train/exp_yolov5s/weights/best.pt path/ # directory
# 检测网络视频
python detect.py --weights runs/train/exp_yolov5s/weights/best.pt 'https://youtu.be/NUsoVlDFqZg' # YouTube video
# 检测流媒体
python detect.py --weights runs/train/exp_yolov5s/weights/best.pt 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream


















 1264
1264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









