




Learning Efficient Object Detection Models with Knowledge Distillation
之前博客整理的论文都是knowledge distillation及其变体,作为机器学习的一种方法的研究发展历程。从这篇博客开始,我将介绍其在CV领域的一些具体的用法。
本文是knowledge distillation在detection上成功应用的一个例子。
概述
knowledge distillation和hint learning在classification已经很成功了。然而对于detection,soft target不再是单一的类别概率输出,regression、proposal、less voluminous labels(较少的标签)都是在detection种使用distillation的挑战:

本文应该是最先在detection种成功使用distillation的,主要idea有:
- end-to-end 使用distillation方式训练
- loss定义,a) weighted cross entropy loss for classification b) teacher bounded regression loss for knowledge distillation c) adaptation layers for hint learning

Method
整体框架:
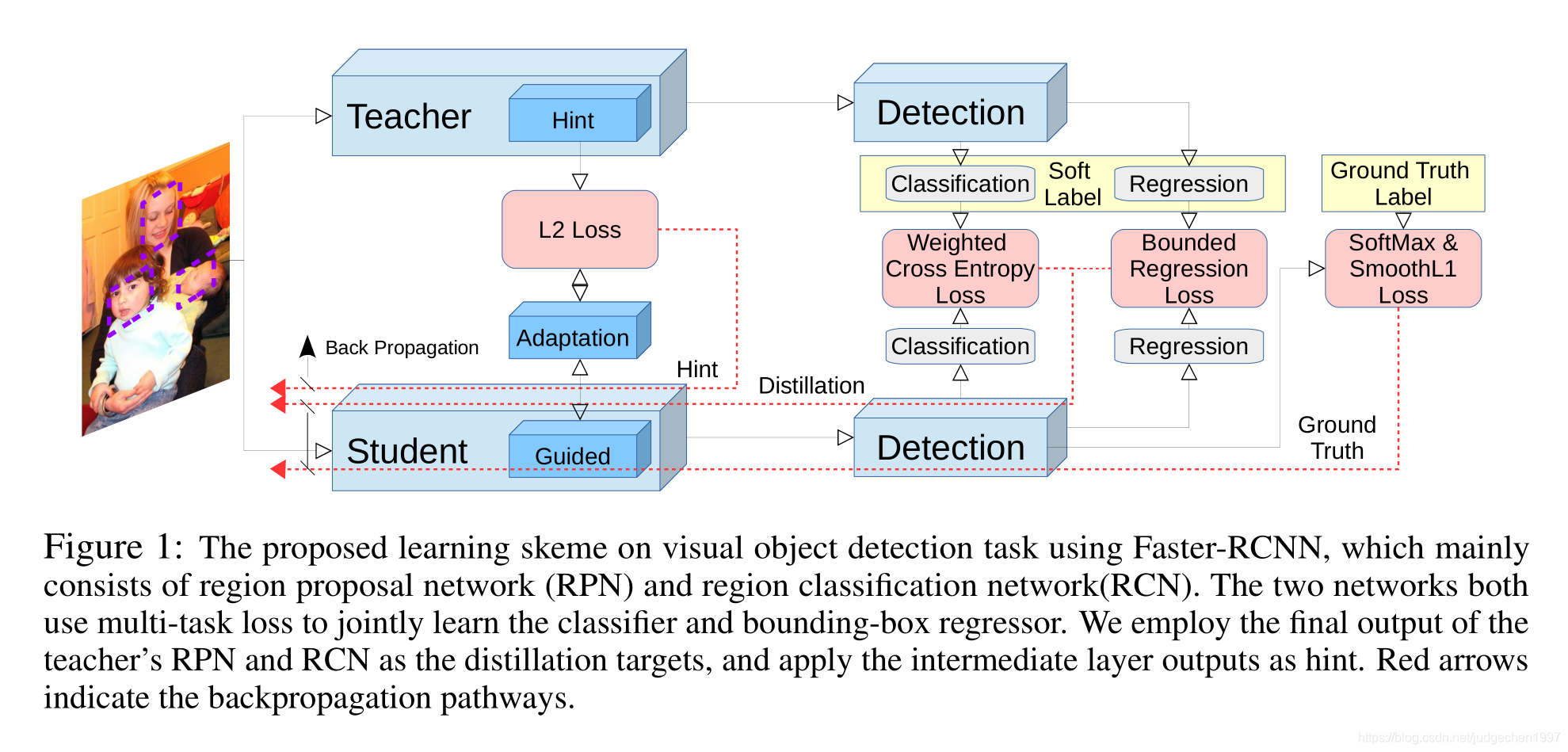
总的loss有三大部分。 L H i n t L_{Hint} LHint
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4829
4829

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









