 知识蒸馏与噪声教师
知识蒸馏与噪声教师





 本文探讨了DeepModelCompression技术,通过向教师模型输出引入基于噪声的正则化,提高了学生模型的鲁棒性和性能。这种方法模拟了多教师的知识蒸馏过程,通过对教师和学生的logit输出计算带有噪声的L2损失,以增强模型训练。实验表明,此方法在简单分类任务上显著提升了基准性能。
本文探讨了DeepModelCompression技术,通过向教师模型输出引入基于噪声的正则化,提高了学生模型的鲁棒性和性能。这种方法模拟了多教师的知识蒸馏过程,通过对教师和学生的logit输出计算带有噪声的L2损失,以增强模型训练。实验表明,此方法在简单分类任务上显著提升了基准性能。
概述
给teacher的输出加入基于噪声的正则化,提高Student Robustness获得更好的performance

很粗糙的一种模拟multi-teacher的方式:

Method
与hinton最开始的KD有两个区别吧:
- 只用了一个logit output作为target,计算了一个新的L2 loss,且student没用hard label
(为什么这样用作者居然也没阐述,不过作者不是第一个这么用的,引用的是‘ Do deep nets really need to be deep?’,可能这篇论文说过,但是这篇论文是2014的,在KD之前就有了,以后可以看看吧) - 在logit output加入了noise扰动,以模拟multi-teacher
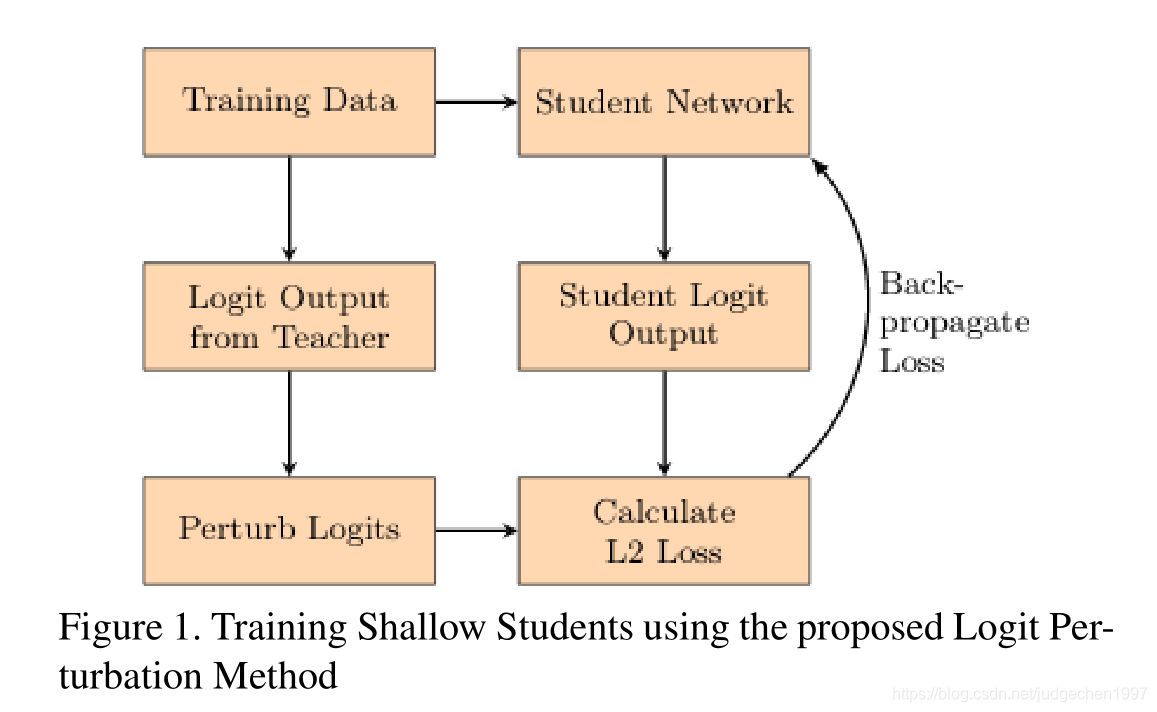

作者采用对teacher and student’s logit output计算L2 loss:

加入了噪声到teacher的logit输出,所以新的L2 loss:

另外,只是对其中一部分sample进行噪声扰动:

实验
teacher:

student:

结果:
(实验是和不在logit加噪声对比,看github别人复现,和KD效果差不多)
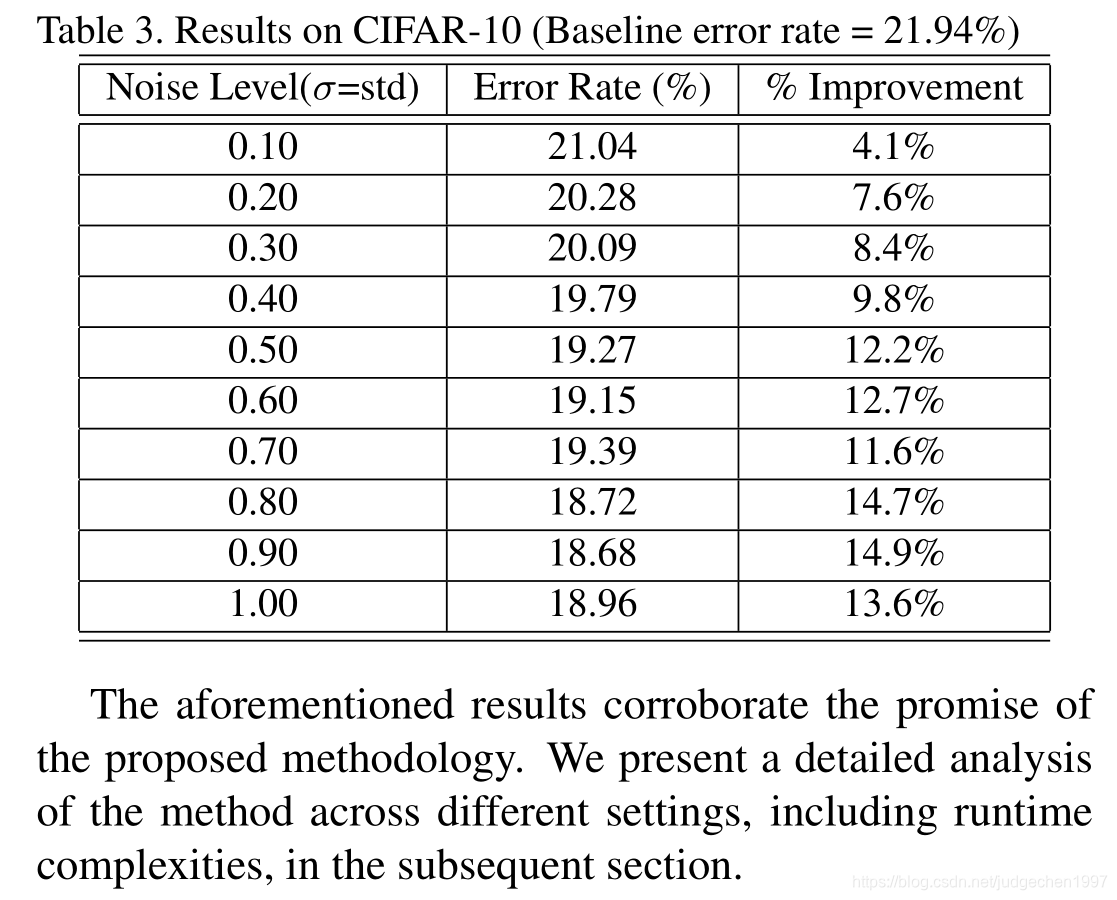
对于一个简单的分类网络,最好的从baseline21.94提升到了18.68
不过我怎么看着像个数据增强的trick一样。。。
毕竟同样的数据,在不同的epoch,经过teacher输出后,加入的random噪声不同,也有一定概率没有加入,这不和数据增强差不多嘛。。

















 1758
1758

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









