




如果这一系列博客之前的都有看了,且有了解过pose领域的hourglass,
这篇文章的idea就很清晰了:
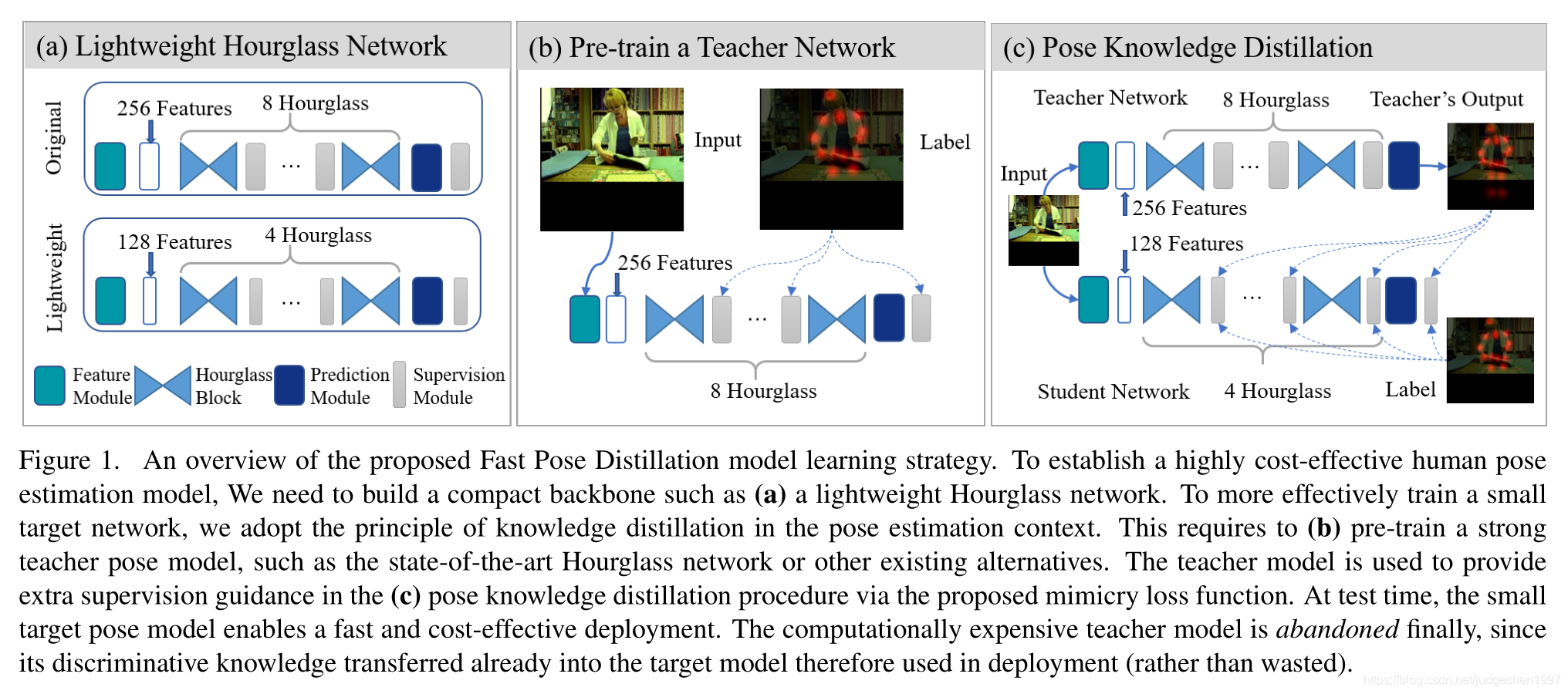
对每个hourglass module的中继监督,同时加入hard label&teacher’s soft output

关于文章的一些思考,一些别人的博客翻译总结的很好:


 本文探讨了在pose估计领域中,如何通过中继监督改进Hourglass模块的表现,并引入硬标签与教师软输出的结合,以提升模型训练效果。文章深入分析了这一创新思路,并总结了前人的研究与见解。
本文探讨了在pose估计领域中,如何通过中继监督改进Hourglass模块的表现,并引入硬标签与教师软输出的结合,以提升模型训练效果。文章深入分析了这一创新思路,并总结了前人的研究与见解。
如果这一系列博客之前的都有看了,且有了解过pose领域的hourglass,
这篇文章的idea就很清晰了:
对每个hourglass module的中继监督,同时加入hard label&teacher’s soft output
关于文章的一些思考,一些别人的博客翻译总结的很好:

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





















 2524
2524





